Part 01传统Hadoop生态方案介绍及其缺点
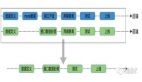
从Hadoop生态出现以来,人们尝到了大数据技术的甜头,随着Hadoop生态的不断发展,它的大数据处理能力已经被业界充分认可。用户可以根据自己的业务需要选择合适的Hadoop生态组件组成自己的大数据处理框架,这里我们以大数据Lambda架构为例对Hadoop生态方案进行说明,其架构图如下所示。

大数据Lambda架构分为三层,下面分别进行描述。
批处理层(Batch Layer):对不可变数据进行批量处理。因为如果在业务需要查询时对全量数据集进行在线查询计算代价会很高,所以可以对查询事先进行预计算,生成对应的Views,这样查询的速度会提高很多。批处理层采用不可变模型对所有数据进行了存储,并根据不同的业务需求对数据进行了不同的预查询,生成对应的Batch Views,这些Batch Views提供给上层的Serving Layer进行进一步的查询。
实时流处理层(Speed Layer):因为批处理层是对全量数据集进行查询,花费的时间会比较长(通常以小时甚至是天为单位)。新进入系统的数据就无法及时被用户查询,导致用户得到的结果不正确。因此需要实时流处理层来处理增量的实时数据。
服务层(Serving Layer):用于响应用户的查询请求,它将批处理层和实时流处理层的结果进行合并,把得到的最终结果返回给用户。
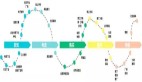
大数据Lambda不同的层可以根据实际业务选择合适的Hadoop生态组件,可能的选择如下图粗体文字所示:
 图2 Lambda架构选择组件
图2 Lambda架构选择组件
通过上面我们对传统Hadoop生态方案的介绍我们可以看到,传统方案使用的生态组件多,这就会导致所需硬件资源多、维护困难、使用门槛高等各种问题,而ClickHouse方案就没有上述的各种问题,让我们接着往下看。
Part 02ClickHouse介绍
ClickHouse是俄罗斯的Yandex于2016年开源的用于在线分析处理查询(OLAP :Online Analytical Processing)MPP架构的列式存储数据库(DBMS:Database Management System),能够使用 SQL 查询实时生成分析数据报告。ClickHouse可以做用户行为分析,流批一体。线性扩展和可靠性保障能够原生支持 shard + replication。ClickHouse没有走Hadoop生态,采用Local attached storage作为存储。
ClickHouse通过向量化执行以及对CPU底层指令集(SIMD)的使用,它可以对海量数据进行并行处理,从而加快数据的处理速度。
2.1 ClickHouse和其他常用数据库性能对比
 图片
图片
 图片来源https://benchmark.clickhouse.com/
图片来源https://benchmark.clickhouse.com/
上图是ClickHouse官方发布的,ClickHouse和MongoDB、MySQL的部分性能评测对比图。我们可以看到ClickHouse的性能在几乎所有场景都优于MongoDB和MySQL。
2.2 ClickHouse的特点
那么ClickHouse为什么这么快?这源于它的设计和特点。ClickHouse使用C++开发,可以利用硬件优势,摒弃了Hadoop生态,数据底层以列式存储。它利用单节点的多核并行处理,为数据建立索引一级、二级、稀疏索引,使用大量的算法处理数据,并支持向量化处理,分布式处理数据。
2.2.1 ClickHouse为什么采用列式存储?
行式存储的好处:想查找某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以;但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
列式存储的好处:对于列的聚合、计数、求和等统计操作优于行式存储。由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间。
2.2.2 DBMS功能
ClickHouse几乎覆盖了标准 SQL 的大部分语法,包括 DDL 和 DML,以及配套的各种函数;用户管理及权限管理、数据的备份与恢复。
2.2.3 多样化引擎
ClickHouse目前提供包括合并树、日志、接口和其他四大类20多种引擎。
2.2.4 高吞吐写入能力
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台Compaction。通过类 LSM tree的结构, ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力。
2.2.5 数据分区与线程及并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(索引粒度),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条Query就能利用整机所有CPU。强大的并行处理能力,极大的降低了查询延时。
所以,ClickHouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多CPU,就不利于同时并发多条查询。所以对于高QPS的查询业务并不是强项。
ClickHouse像很多OLAP数据库一样,单表查询速度优于关联查询,而且ClickHouse的两者差距更为明显。在执行关联查询时,ClickHouse会将右表加载到内存。
Part 03ClickHouse方案

各种数据源通过Kafka接入到数据平台层,数据平台讲明细数据存入数据存储层的ClickHouse中,明细数据的存活时间可以根据业务需求设置。同时可以根据业务报表查询的不同维度,利用ClickHouse的物化视图形成预聚合数据,提高数据查询效率。由数据服务层的定时任务周期性地从ClickHouse的预聚合数据中查询业务所需的展示数据,把展示数据存入MySQL。由数据服务层的报表服务向数据展示层提供查询服务,报表服务直接查询MySQL中的结果数据,保证了查询效率和并发性。
Part 04 总结
传统的Hadoop生态方案使用的生态组件多,这就会导致所需硬件资源多、维护困难、使用门槛高等各种问题。而ClickHouse方案不依赖Hadoop生态,根据业务需要使用简单的几种组件就可以完成数据接入、数据存储和数据查询等功能,节省了系统服务器资源,也降低了使用人员的门槛。