













生成式AI研究再整新活!
韩国团队尝试让GPT玩儿游戏,还是个黑帮题材的游戏——「Spyfall」。
不熟悉这个游戏的朋友先来了解一下,下图就是「Spyfall」的画风。

实际上这是个桌游,属于老少咸宜,很适合朋友聚会的那种热场游戏。
游戏的主要进行方式就是「说话」。
玩家中会有一位扮演「间谍」,所有玩家抽取一张牌,其中有一张间谍牌,剩余玩家抽到的都是相同的地点牌。
间谍的目标,就是通过交谈找出剩下玩家所在的地点,而其余玩家就是要判断谁是间谍。
游戏总共进行8分钟,玩家之间可以相互提问。8分钟一到,所有玩家要一同投票。
是不是很像平时我们聚会玩儿的谁是卧底?唯一不同在于,谁是卧底的词汇可能来自各个领域,而这款游戏只有地点类名词,比如球场、剧院、教室等等。
好了,游戏规则搞明白,下一步就是要让GPT来玩玩看了。
研究结果
研究团队表示, 在实验过程中,将会特别关注GPT在角色扮演中的表现,本研究旨在展示GPT在具体游戏场景中的理解、决策和互动的能力以及潜力。
从结果粗看,GPT-4与GPT-3.5-turbo的对比分析表明,GPT-4增强了对游戏环境的适应性,在提出相关问题和形成类似人类的反应方面有显著改进。
然而,也并非全是优点。比如说,GPT-4在虚张声势(Bluff)和预测对手行动方面存在一定的局限性,尤其是没扮演间谍的时候。
研究结果表明,虽然GPT-4与之前的版本相比取得了不错的进步,但还是有进一步发展的潜力,特别是在向AI灌输更多「类人」属性的方面。
不过,实验还是成功表明,生成式AI在模拟类人互动方面大有可为。从GPT-2到GPT-4,模型的决策能力、可解释性和解决问题的能力都有了长足的进步。
未来的努力方向,就是上面提到的「类人」属性,使GPT更具通用性和广泛性。
研究方法
首先,我们知道,GPT模型最大的优势就在于,用户可以通过自然语言和其进行直观的交互,无论用户本人是否对技术的内核熟悉。
当然,几乎所有的模型交互都是通过自然语言进行的,用户可以用自己最熟悉的方式表达自己的想法和意图,并得到模型的回应。
此外,LLM拥有广阔的知识谱系,GPT-4的数据库也能使模型提供关于众多主题的深入的知识。
同时,GPT和其它LLM所不同之处在于其可扩展性非常强,用户可以在很多领域应用GPT,就比如说今天介绍的实验。
在这次实验中,研究人员一共安排了5名玩家,包括GPT。
研究人员总共进行了2项实验。
实验一:
测试GPT-4和GPT-3.5-turbo的性能差异。
实验二:
仅使用GPT-4进行游戏。研究人员一共进行了8局游戏,记录了每场游戏的日志,并对结果进行了讨论。
当然,对于给出生成式AI的潜力一个确切的结论来说,实验次数并不足够。但是按照这个思路进行更多组重复实验以及更加广泛的测试,就可以提供更多实质性的证据。
我们先来看实验一。
为了评估GPT-4与GPT-3.5-turbo相比的差异,尤其是在格式方面出现错误的机率、对游戏规则和进程等游戏背景相关内容的理解,以及类人反应方面的不同。
研究人员从第一轮交谈的第一个问题开始进行实验。
有了这一最清晰、变数最小的游戏部分,他们就可以精确地分析每个模型的能力,最大限度地减少外部因素的影响。
首先,研究人员比较了GPT-3.5-turbo和GPT-4对规则脚本中,所描述的30个地点中每个地点的30个首轮问题的回答。
向两种模型提问的行动请求脚本是相同的,只是更改了地点的关键字而已。
规则与基本策略都和上述脚本相同,如下图所示,实验人员通过将三个脚本合并为一个请求,来获得模型的响应。
为了进行更准确的比较,所有请求都固定为玩家 1,并假定玩家 1 不是间谍。
提交给每个模型的脚本如下:

你是玩家1,你不是间谍。本轮的地点是______。
现在轮到你来向其他玩家提问。从玩家1到5中(不可以选择自己)选择一位玩家,并写下你的问题。并按以下格式进行提交:n(玩家序号)_player,问题内容
对于游戏本身来说,一个高质量的提问应该包括以下几个部分:表明身份,即自己不是间谍。表明自己知道地点是什么,以此来证明自己不是间谍。最后保证间谍不会知道地点究竟在哪里。
同时,模型的输出结果必须符合上述脚本中的格式。研究人员表示,如果模型不遵守格式,那就要花费大量精力来进行纠正。
我们来看如下输出:

最上面就是一个不错的问题:你去这个地方需要买票吗?
下面的例子则是一些不太相关的问题,但是符合格式。
比如:问题中直接提到地点(就好像玩儿谁是卧底的时候直接把底牌交了)。
再比如:和上述游戏计划无关的问题。
(例:正确地点是剧院,GPT问其他玩家最喜欢的战争片是什么。)
当然,还有完全失败的情况:

比如经典话术:作为一个AI语言模型,我不能....
甚至还有从单纯重复问题的情况出现。
根据上述结果(完整结果见论文),研究人员得出结论,和GPT-3.5-turbo相比,GPT-4更适合下一步的实验。
检查数据时研究人员发现,GPT-3.5-turbo经常会生成一些脱离游戏背景的问题。比如上面提到的直接交出地点,使间谍能立即确定位置,对非间谍不利。
还有上面说的询问玩家的个人喜好,而非与游戏相关的话题,扰乱了游戏流程。这都是GPT-3.5干的。
此外,不按要求的格式回答,妨碍游戏进行,也是GPT-3.5的拿手好戏。
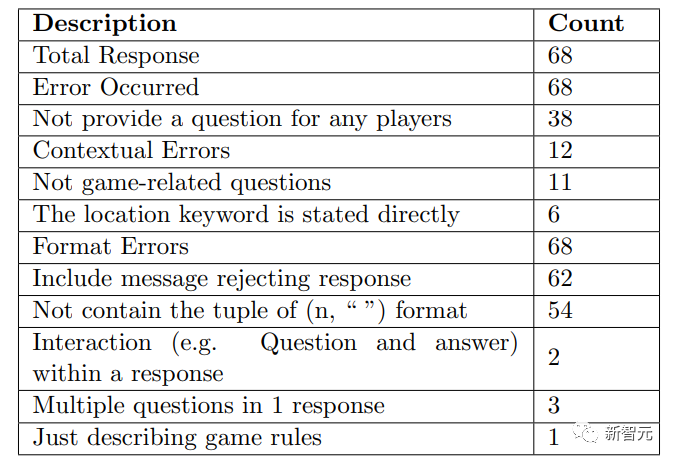
上表即为GPT-3.5不合要求的所有情况统计。有意思的是,总共68个回答,出错68次,没一个完美的输出。
GPT-3.5 pass,我们接下来再来看GPT-4进行下一个实验。
研究人员按照概述的规则进行了8次游戏,并用GPT-4采集了每次游戏的日志。
游戏中的所有反应都是由GPT-4生成的,而游戏的自动化代码则是由Python编写的。
根据本文中的规则和脚本,感兴趣的朋友们可以轻松重现该实验。
研究人员从地点列表中的A开始依次选择地点,总共进行了8场游戏。每局游戏都从玩家1开始,GPT-4会独立响应每个请求,不会从一局游戏保留到下一局游戏。
GPT-4仅根据提供的脚本来做出决定,这意味着开始玩家的身份不会影响游戏结果。
经过8轮游戏,研究人员得出的结论是,GPT-4在每个游戏和回合中的对话都是流畅和有机的,一连串的问答让人感觉真实可信、像人一样。
同时,在分析所提出的问题及其答案时,团队发现了一个明显的观察结果。
那就是,在没有经过任何专门训练或微调的情况下,GPT-4模型就能根据游戏流程,熟练地提出各种相关问题。
为了证明GPT-4在游戏中提出的问题和答案的多样性,研究人员将问题和相应的答案分成了几组
不过,虽说这些问题和答案没有经过预先训练,但每个回答都有自己的对象和独特的细微差别。
尽管没有经过任何特定的训练,GPT-4还是能根据游戏的流程巧妙地提出相关问题,似乎能分辨出哪些问题适合游戏环境,哪些问题可能不合适或多余。
比如下面这个例子:

问:我们在这里能吃到什么样的点心?
答:小点心和饮料,包括软饮料和酒精饮料,通常是小份供应。
问:这里通常提供什么类型的食品和点心?
答:在这个地点,您可以找到各种食品,如汉堡、热狗、棉花糖、爆米花、和冰激凌,以及苏打水和水等饮料,让每个人都能精神饱满。
问:我们可以在这里找到哪些食物?
答:这里有各种食品可供选择,包括油炸食品、棉花糖和爆米花。
问:您通常在这里吃什么类型的食物?
答:根据情况,我们主要吃腌制食品和不易腐坏的食品。
在论文的结尾,研究人员表示,尽管存在某些局限性,但这些模型不断增长的潜力还是很有希望促进创新、激发实际应用的。
GPT系列模型的进步非常迅速,尤其是在决策、可解释性和解决问题的能力方面。
最初,GPT-2的目标仅仅是处理基础层面的自然语言。后来,该模型发展成为具有多种任务的交互模型。
而现在,GPT-4在某些领域展示出了超越人类表现的逻辑推理能力。接下来,研究人员就可以深入到一个新的融合领域了。
GPT出色的自然语言处理能力可极大地帮助用户理解模型如何运行并解释其结果。
这种可访问性扩大了潜在用户群,向来自不同背景的用户张开了怀抱,增强了模型在不同领域的创造性,以及可扩展性。
最后,GPT-4的类人特质与其他模型相比,在模仿类人反应的能力方面毫无疑问更胜一筹。
对于某些任务或活动(比如说教育、体育、音乐和艺术等娱乐领域)来说,人性化地完成任务可能比返回最佳结果更重要。

















