













这篇文章讨论了关系型数据库内部的索引和事务是如何工作的,而不深入研究特定数据库的怪癖。我将涵盖您应该了解的关于RDBMS索引的一切。我将简要涉及事务和隔离级别,以及它们如何影响对特定事务的推理。
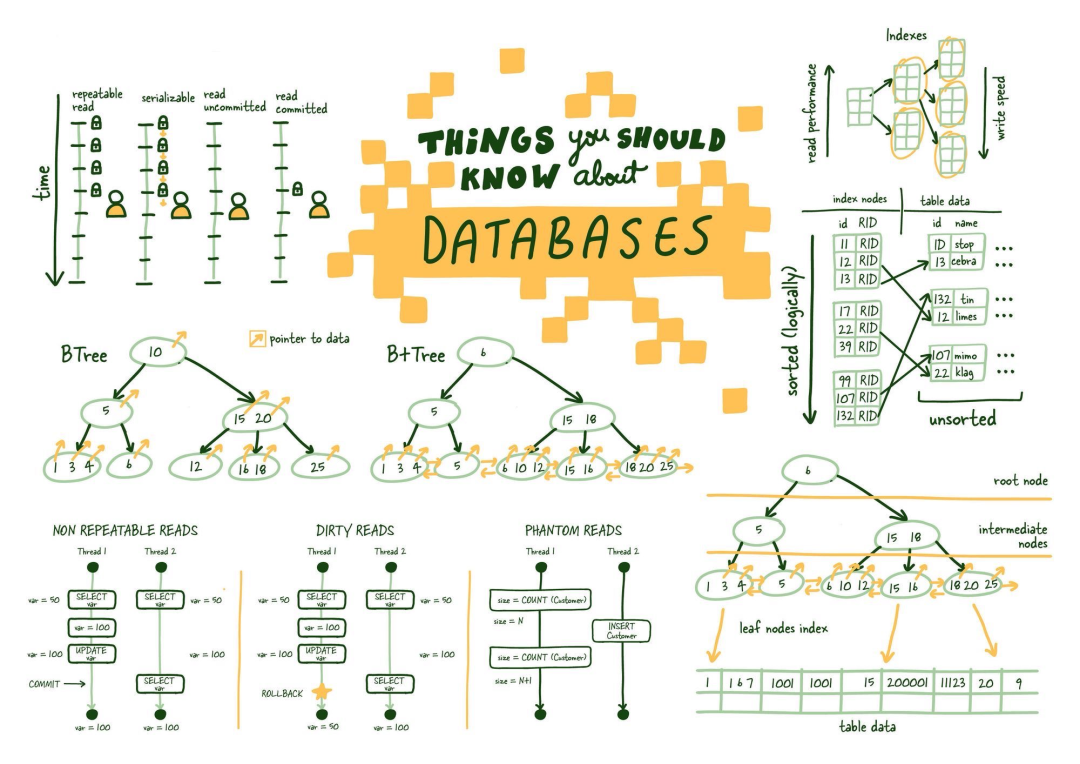
图1.0 关系型数据库解释信息图
1.什么是RDBMS?
关系型数据库管理系统(RDBMS)是一种用于管理结构化数据的软件。它使用表格来存储数据,并支持SQL(Structured Query Language)进行数据检索和操作。RDBMS是一种常见的数据库类型,包括MySQL、PostgreSQL、Oracle、SQL Server等。
2.什么是索引?
索引是一种数据结构,用于降低请求数据的查找时间。索引通过额外的存储、内存和维护成本(写入速度较慢)来实现这一点,使我们能够跳过检查每个表行的繁琐任务。
就像教科书后面的索引一样,它可以帮助你找到正确的页。我不是书的爱好者,但当我们深入研究数据库索引时,它是一个很好的引入主题的方式。
3.为什么我们需要索引?
小量的数据是可以管理的,但是当它们变得更大时(比如大城市的出生登记簿),事情就变得不那么简单了。一切原来快速的东西变得更慢,太慢。
想象一下,如果您不得不在1页上查找某些内容,与在千页的名单上查找相比,您的策略会发生什么变化。不,认真地,请花一秒钟思考一下。
不管您想出什么好策略,某个数据库几乎在某个时候都实现了您能想到的所有好策略。随着它们的增长,系统会收集和存储更多的数据,最终导致上述问题。
我们需要索引来帮助我们尽快获取我们需要的相关数据。
4.索引是如何工作的?
随着数据的索引化,读取性能会提高,但这会以写入性能为代价,因为您需要保持索引的最新。因此,经常会提出的一个解决方案问题是按照您希望搜索的方式对数据进行逻辑排序。这意味着如果要按名称搜索列表,您会按名字对列表进行排序。这种策略有一些问题。我主要将其作为读者的问题提出:
- 如果要以多种方式搜索数据怎么办?
- 如何处理将新数据添加到列表中?这是否很快?
- 如何处理更新?
- 这些任务的O标记是多少?
不管您的原始策略如何,我们绝对需要一种方法来维护顺序,以便我们可以快速获取相关的无序数据(很快就会谈到这一点)。
5.链表
我们希望在互联网上建立最大的系统设计社区!我们希望您加入我们。您可以在Twitter上找到我们。您也可以在此处联系作者,提供反馈。
让我们来看看下面的图1.1。
图1.1 可以快速从磁盘读取的小表格
底层数据在存储中分散,没有顺序,似乎是随机分配的。如今,大多数生产服务器都配备了SSD,但有些情况下,您可能需要使用(HDD)传统硬盘,但老实说,这样的情况越来越少,因为SSD的价格大幅下降。
6.SSD与HDD
现在,将这么多数据读入内存非常快,相对来说也很容易进行扫描。那么,如果我们正在搜索的数据无法完全缓存在内存中,或者从磁盘读取所有数据所需的时间太长呢?
图1.2 大表格,无法完全放入内存,分布在磁盘上
这就是大多数开发人员会遇到的问题 - 我以前遇到过这个问题;我们需要一些字典(哈希映射)以及一种无需扫描缓慢的磁盘、读取大量块的方式来查找我们需要的数据是否存在。
这些被称为索引叶节点,它们会指定一个要索引的特定列,它们可以存储匹配行的位置。
这些索引叶节点是索引列和相应行位于磁盘上的位置之间的映射。这使我们能够快速找到特定行,如果您引用它,就是索引列。扫描索引可以更快,因为它是要搜索的列的紧凑表示(字节更少),它可以节省您读取大量块以查找请求的数据所需的时间,并且更方便缓存,进一步加速整个过程。
数据规模常常适得其反,平衡树是应对之的第一工具。
这些索引叶节点大小均匀,我们试图尽可能多地存储这些叶节点。由于这种结构要求事物在逻辑上进行排序(不是在物理上排列在磁盘上),我们需要解决快速添加和删除数据的问题;好的老式双向链表管理这一点,更具体地说,是双向链表。
7.数据块
这里的好处有两方面:它允许我们前向和后向读取索引叶节点,以及当我们删除或添加新行时,快速重建索引结构,因为我们只是修改指针 - 强大的东西。
8.链接列表
由于这些叶节点在磁盘上物理上未按顺序排列(请记住,指针维护双向链表的排序),我们需要一种方法来获取正确的索引叶节点。
(1) 平衡树(B-Tree)
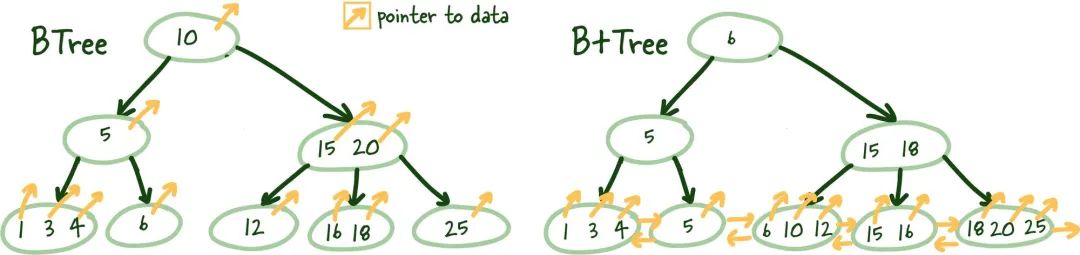
图1.3 结构差异:B树与B+树
这使您可能会想知道,您在学校讨厌的B树中犯了什么大错误。我明白这些东西很无聊,但它们很强大,值得理解。
B+树允许我们构建一个树结构,其中每个中间节点指向其各自叶节点的最高节点值。这为我们提供了一种找到将指向所需数据的索引叶节点的明确路径的方法。
这个结构是从底层开始构建的,以便中间节点覆盖所有叶节点,直到达到顶部的根节点。这个树结构之所以被称为“平衡”,是因为整个树的深度是统一的。
(2) B-树与B+树
9.对数可扩展性
我想在这里简要提一下这个结构的威力。当然,大多数开发人员都意识到数据的指数增长以及理想情况下,您公司的估值。但不幸的是,数据规模常常与您作对,而平衡树是应对之的第一工具。
根据中间节点可以引用的项目数(M)以及整个树(N)的深度,我们可以引用M到N个对象。
下表以M值为5来说明了这个概念。
因此,随着索引叶节点数量呈指数增长,树的高度相对于索引叶节点数量的增长速度非常慢(对数增长),再加上平衡树的高度,几乎可以立即找到指向实际磁盘上的相关索引叶节点。这与数据库相比是一个非常快的速度。
不是美丽的景象吗?
10.什么是事务?
事务是您希望将其视为单个单位的工作。因此,它必须完全发生或完全不发生。我认为大多数系统不需要手动管理事务,但也有一些情况下,增加的灵活性对于实现所需的效果非常重要。事务主要涉及ACID中的I,即隔离。
11.什么是ACID?
这些可以自动为您执行,以便您甚至不知道它们正在发生,或者您可以像下面这样手动创建它们:
图1.3 如何创建手动事务
我们将重点关注BEGIN和COMMIT或ROLLBACK之间的时间,以及对相同数据进行操作的其他各种事务发生了什么。
(1) 提交/回滚
(2) 读现象
在这些隔离级别中可能会发生多种读取现象,了解它们对于调试系统并诚实地帮助理解系统可以容忍什么样的不一致非常重要。
(3) 不可重复读
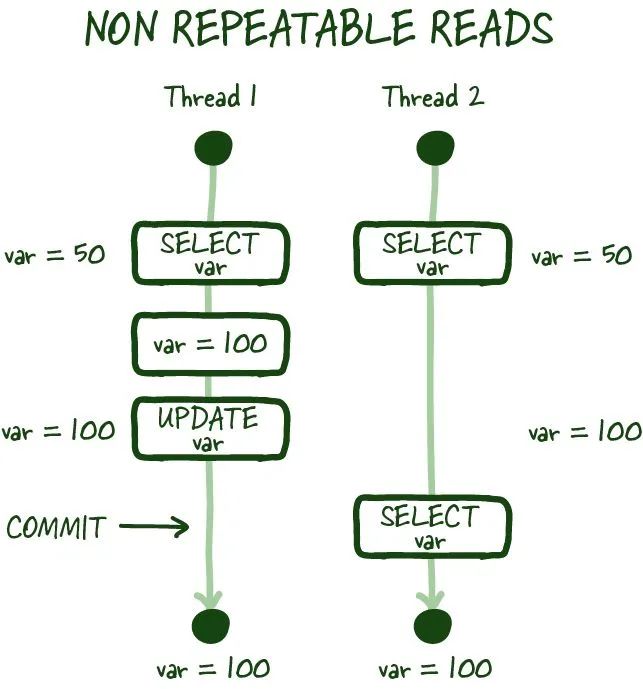
Databases-08.jpeg
就像上图所示,不可重复读取是指在事务期间连续两次读取数据时,您无法获取一致的数据视图。在特定模式下,可以进行并发数据库修改,并且可能会发生您刚刚读取的值被修改的情况,从而导致不可重复读取。
(4) 脏读
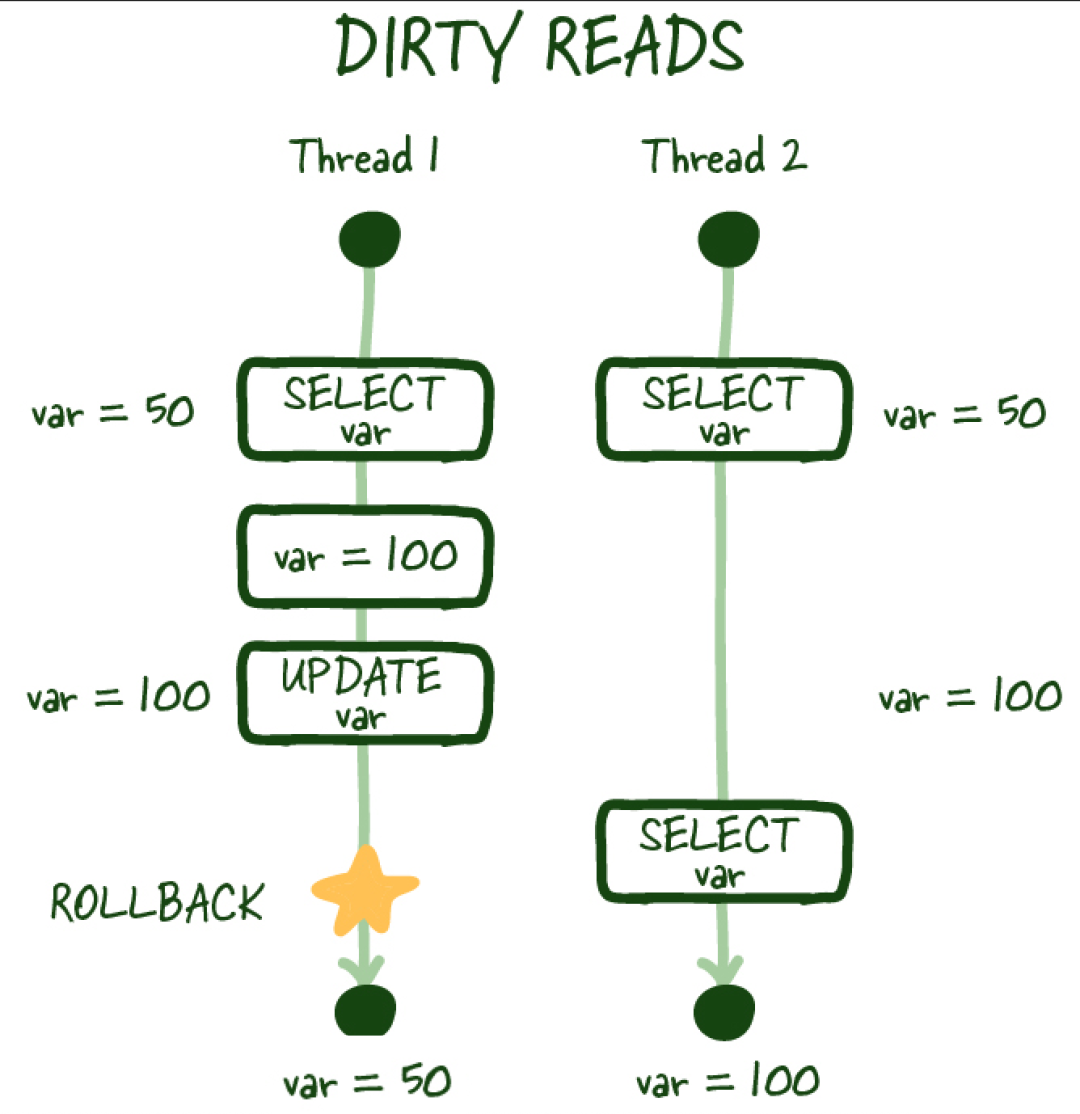
Image.png
类似地,脏读取是指您执行读取,另一个事务更新相同行但没有提交工作,然后执行另一次读取,您可以访问未提交(脏)值,这不是持久的状态更改,也与数据库的状态不一致。
(5) 幽灵读
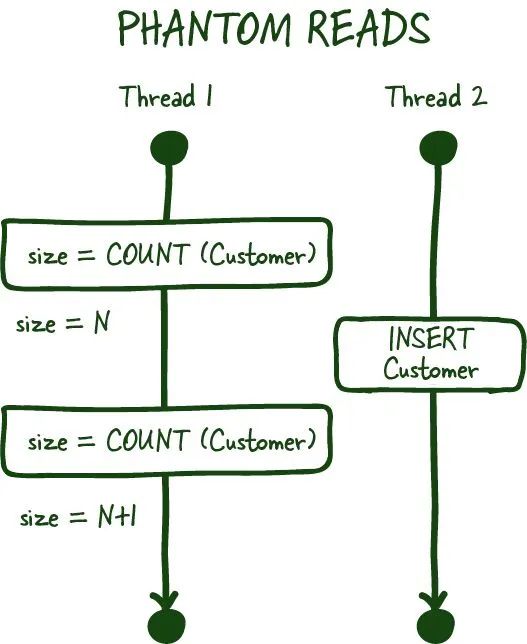
Databases-10.jpeg
幽灵读取是另一种已提交的读取现象,它发生在您主要处理聚合时。例如,您要求特定事务中的客户数量。在连续两次读取之间,另一位客户注册或删除他们的帐户(已提交),这会导致您获取到两个不同的值,如果您的数据库不支持这些事务的范围锁,则可能会发生这种情况。
(6) 范围锁
(7) 隔离级别
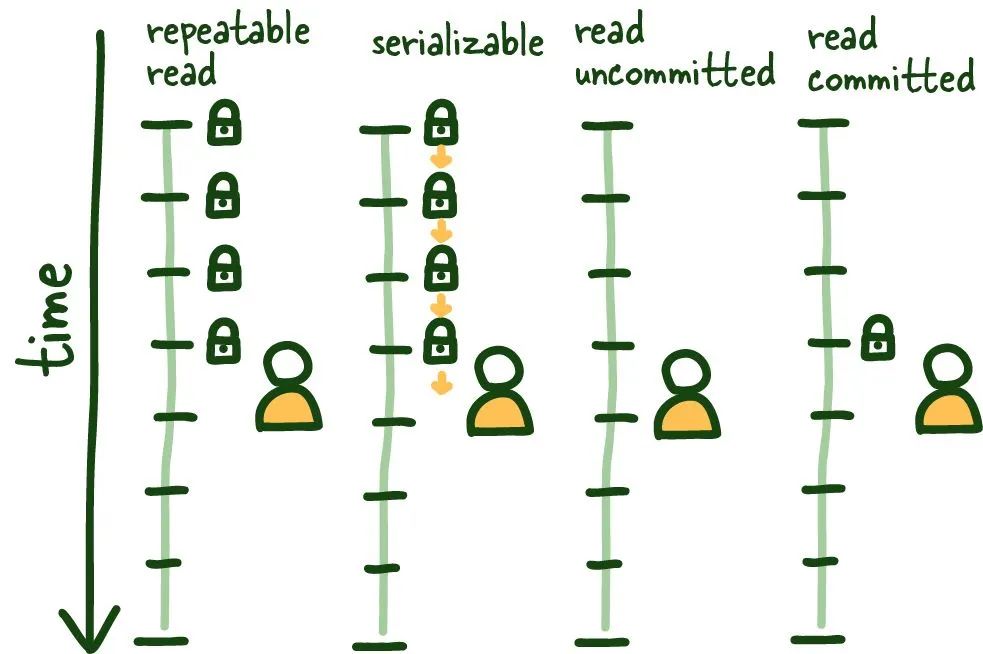
Databases-05-2.jpeg
SQL标准定义了4种标准隔离级别,这些级别可以并且应该在全局配置(如果不能可靠地推断隔离级别,可能会发生潜在问题)。
(8) 可重复读
让我们从可重复读开始。这很容易理解,并为其他隔离级别奠定了基础。此隔离级别确保在第一次读取建立的事务内进行一致读取。此视图以多种方式维护;某些方式会影响整个系统的性能,而其他方式不会,但不在本文的范围内。
请参考上面的图形;一旦我们进行了第一次读取,该视图将在事务持续期间被锁定,因此在此事务的上下文之外发生的任何事情都无关紧要,无论是已提交还是未提交。
这种隔离级别保护我们免受多种已知的隔离问题的影响,主要是不可重复读和脏读。它确实有一些轻微的数据不一致,因为它被锁定在特定数据库视图,因此在此锁定期间的数据不相关;在此期间,保持事务尽可能短是有益的。
(9) 可串行化
这种操作模式可以是最受限制和一致的,因为它只允许一次运行一个查询。
由于数据库依次运行查询,从一个稳定状态过渡到下一个,因此不再可能发生所有类型的读取现象。当然,这里还有更多细节,但大致如此。
重要的是要注意,在这种模式下需要一些重试机制,因为由于并发问题,查询可能会失败。
较新的分布式数据库利用此隔离级别以实现一致性保证。 CockroachDB 就是这样的数据库的一个例子。值得一看。
(10) 读已提交
这种隔离模式不同于可重复读,因为每次读取都会创建自己的一致(已提交)时间快照。因此,如果我们在同一事务中执行多次读取,这种隔离级别容易受到幽灵读的影响。
(11) 读未提交
另一种是读未提交隔离级别,它不维护任何事务锁定,并可以看到正在发生的未提交数据,从而导致脏读。在某些系统中,这是噩梦中的东西。
这就是关于数据库的你应该了解的事情。















