大数据文摘出品
7月份,纽约大学(NYU)博士后Naomi Saphra撰写了一篇题为“Interpretability Creationism”,从进化论的角度解释了随机梯度下降(SGD)与深度学习之间的关系,解读视角发人深思。
例如:“就像人类尾骨一样,有些现象在模型训练过程中可能已经失去了原来的作用,变成了类似退化器官的存在。”
“无论是在研究寄生育雏行为还是神经网络的内部表现,如果不考虑系统是如何发展的,就很难分辨哪些是有价值信息。”
以下是原文,文摘菌做了不改变原意的编译,请欣赏。

几个世纪前,欧洲人布谷鸟蛋出现在鸟巢中是筑巢鸟的荣誉。因为,筑巢鸟热情地喂养她的“神圣客人”,甚至比喂养自己的(被驱逐的)雏鸟还要卖力,筑巢鸟的这种行为符合基督教热情好客的精神。
1859年,查尔斯·达尔文研究了另一种偶尔寄生的雀科鸟类——雀鸟,从而质疑了鸟类行为的乐观、合作观念。

如果不从进化论角度考虑布谷鸟的角色,人们很难认识到筑巢鸟不是布谷鸟幼鸟的慷慨主人,而是一个不幸的受害者。
正如进化生物学家Theodosius Dobzhansky所言:“没有进化的光辉,生物学中的一切都无法理解。”
虽然随机梯度下降并不是生物进化的真正形式,但机器学习中的事后分析与生物学的科学方法有很多相似之处,这通常需要理解模型行为的起源。
无论是在研究寄生育雏行为还是神经网络的内部表现,如果不考虑系统是如何发展的,就很难分辨哪些是有价值信息。
因此,在分析模型时,不仅要关注训练结束时的状态,还要关注训练过程中的多个中间检查点。这样的实验开销很小,但可能带来有意义的发现,有助于更好地理解和解释模型的行为。
恰到好处的故事
人类是因果思考者,喜欢寻找事物之间的因果关系,即使可能缺乏科学依据。
在NLP领域,研究者们也倾向于为观察到的行为提供一种可解释的因果解释,但这种解释可能并没有真正揭示模型的内部工作原理。例如,人们可能会高度关注句法注意力分布或选择性神经元等可解释性工件,但实际上我们并不能确定模型是否真的在使用这些行为模式。
为了解决这个问题,因果建模可以提供帮助。当我们尝试通过干预(修改或操作)模型的某些特征和模式来测试它们对模型行为的影响时,这种干预可能只针对某些明显的、特定类型的行为。换句话说,在尝试理解模型如何使用特定特征和模式时,我们可能只能观察到其中一部分行为,而忽略了其他潜在的、不太明显的行为。
因此,在实践中,我们可能只能对表示中的特定单元进行某些类型的轻微干预,无法正确反映特征之间的相互作用。
在尝试通过干预(修改或操作)模型的某些特征和模式来测试它们对模型行为的影响时,我们可能会引入分布偏移。显著的分布偏移可能导致不稳定的行为,那么为什么不会导致伪造的可解释性工件呢?
译者注:分布偏移指的是模型在训练数据上建立的统计规律与干预后数据之间的差异。这种差异可能导致模型无法适应新的数据分布,从而表现出不稳定的行为。
幸运的是,研究生物进化的方法可以帮助我们理解模型中产生的一些现象。就像人类尾骨一样,有些现象在模型训练过程中可能已经失去了原来的作用,变成了类似退化器官的存在。有些现象可能存在相互依赖的关系,例如,在训练早期出现的某些特征可能影响了后续其他特征的发展,就像动物在发展复杂的眼睛之前,需要先有基本的光感应能力。
还有一些现象可能是由于特征之间的竞争导致的,例如,具有很强嗅觉能力的动物可能不太依赖视觉,因此视觉方面的能力可能会减弱。另外,一些现象可能只是训练过程中的副作用,类似于我们基因组中的垃圾DNA,它们占据了基因组的很大一部分,但并不直接影响我们的外观和功能。
在训练模型的过程中,有些未使用的现象可能会出现,我们有很多理论来解释这种现象。例如,信息瓶颈假说预测,在训练早期,输入信息会被记忆下来,然后在模型中进行压缩,只保留与输出相关的信息。这些早期记忆在处理未见过的数据时可能并不总是有用,但它们对于最终学习到特定输出表示是非常重要的。
我们还可以考虑到退化特征的可能性,因为训练模型的早期和后期行为是很不一样的。早期的模型更简单。以语言模型为例,早期的模型类似于简单的n-gram模型,而后期模型则能表现出更复杂的语言模式。这种训练过程中的混合可能会产生一些副作用,而这些副作用很容易被误认为是训练模型的关键部分。
进化观点
仅根据训练结束后的特征来理解模型的学习倾向是非常困难的。根据Lovering等人的研究成果,观察训练开始时特征提取的容易程度以及对微调数据的分析,对于理解微调性能的影响比仅仅在训练结束时进行的分析要深入得多。
语言分层行为是一个典型的基于分析静态模型的解释。有人认为在句子结构中位置靠近的单词在模型中的表示会更接近,而与结构上较远的单词表示相距较远。那么,我们如何知道模型是通过按照句子结构上的接近程度来对单词进行分组呢?
实际上,我们可以更有把握地说,某些语言模型是分层的,因为早期模型在长短时记忆网络(LSTM)和Transformer中编码了更多的局部信息,并且当这些依赖关系可以分层地堆叠在熟悉的短成分上时,它们更容易学习更远距离的依赖关系。
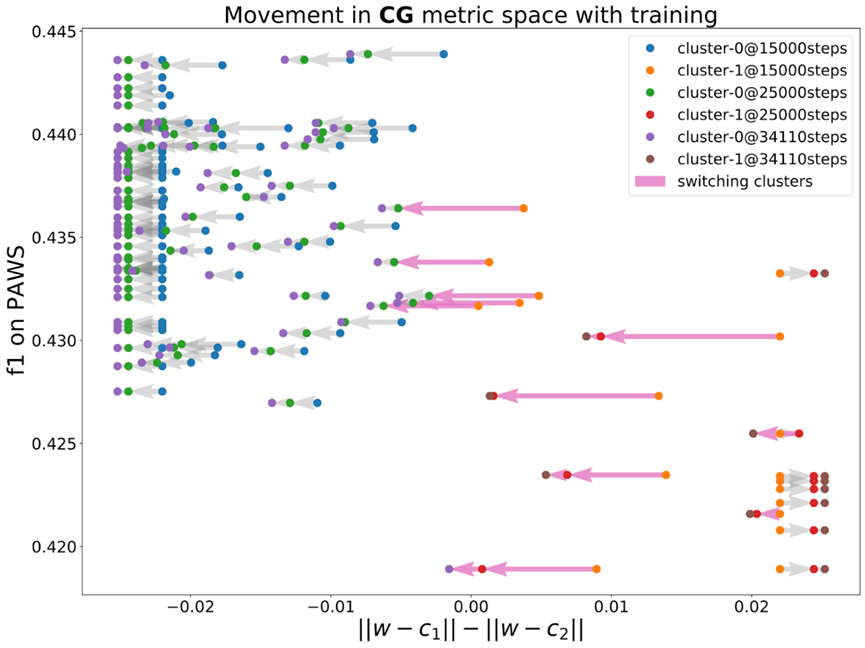
处理解释性创造主义问题时遇到了一个实际案例。使用不同的随机种子多次训练文本分类器时,可以观察到模型分布在多个不同的簇中。还发现,可以通过观察模型在损失表面上与其他模型的连接情况来预测模型的泛化行为。换句话说,根据损失表面上的位置,模型的泛化性能可能会有所不同。这种现象可能与训练过程中使用的随机种子有关。
但是真的可以这么说吗?如果一个簇实际上对应于模型的早期阶段呢?如果一个簇实际上只是表示了模型的早期阶段,那么最终这些模型可能会转向具有更好泛化性能的簇。因此,在这种情况下,观察到的现象只表示一些微调过程比其他过程慢。
需要证明训练轨迹可能会陷入损失表面上的一个盆地(basin),从而解释训练模型中泛化行为的多样性。实际上,在检查了训练过程中的几个检查点后,发现位于簇中心的模型会在训练过程中与其簇中的其他模型建立更强的联系。然而,有些模型还是能够成功地转向一个更好的簇。
一个建议
对于研究问题的回答,仅观察训练过程是不够的。在寻求因果关系时,需要进行干预。以生物学中关于抗生素耐药性的研究为例,研究人员需要故意将细菌暴露于抗生素,而不能依赖自然实验。因此,基于训练动态的观察所做的声明(statement),需要实验证实。
并非所有声明都需要观察训练过程。在古代人类看来,许多器官都有明显的功能,如眼睛用于看东西,心脏用于泵血等。在自然语言处理(NLP)领域中,通过分析静态模型,我们可以做出简单的解读,例如特定神经元在特定属性存在时会激活,或某些类型的信息在模型中仍然可获取。
然而,训练过程的观察仍然可以弄明白许多在静态模型中进行的观察的含义。这意味着,尽管不是所有问题都需要观察训练过程,但在许多情况下,了解训练过程对于理解观察结果是有帮助的。
建议很简单:在研究和分析训练模型时,不要仅关注训练过程中的最终结果。相反,应该将分析应用于训练过程中的多个中间检查点;在微调模型时,要检查训练早期和晚期的几个点。在训练过程中观察模型行为的变化非常重要,这可以帮助研究人员更好地理解模型策略是否合理,并在观察到训练早期发生的情况后对模型策略进行评估。
参考链接:https://thegradient.pub/interpretability-creationism/