












今天,我们来探讨一个很多人都很关心的问题:“为什么单线程的 Redis 能那么快?”
首先,我要和你厘清一个事实,我们通常说,Redis 是单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
所以,严格来说,Redis 并不是单线程,但是我们一般把 Redis 称为单线程高性能,这样显得“酷”些。接下来,我也会把 Redis 称为单线程模式。而且,这也会促使你紧接着提问:“为什么用单线程?为什么单线程能这么快?”
要弄明白这个问题,我们就要深入地学习下 Redis 的单线程设计机制以及多路复用机制。之后你在调优 Redis 性能时,也能更有针对性地避免会导致 Redis 单线程阻塞的操作,例如执行复杂度高的命令。
好了,话不多说,接下来,我们就先来学习下 Redis 采用单线程的原因。

Redis 为什么用单线程?
要更好地理解 Redis 为什么用单线程,我们就要先了解多线程的开销。
多线程的开销
多线程可以增加系统吞吐率,多线程机制可以将一个程序分为多个独立运行的线程,每个线程可以同时执行不同任务,避免了任务之间的互相等待,提高了系统的响应速度。通过合理管理和调度这些线程,可以更好地利用计算机的处理能力,在较短时间内处理更多的请求。
多线程还有助于提高系统的扩展性。通过将任务拆分为多个子任务,每个线程负责执行其中一部分,可以更容易地将工作负载分配到多个处理单元上。这样,在需要扩展系统处理能力时,只需增加更多的线程,而不需要修改整体架构或重新设计系统。这种可伸缩性使得系统在应对不断增长的需求时更具竞争力。
下面的左图是我们采用多线程时所期待的结果。
但是,请你注意,通常情况下,在我们采用多线程后,如果没有良好的系统设计,实际得到的结果,其实是右图所展示的那样。我们刚开始增加线程数时,系统吞吐率会增加,但是,再进一步增加线程时,系统吞吐率就增长迟缓了,有时甚至还会出现下降的情况。
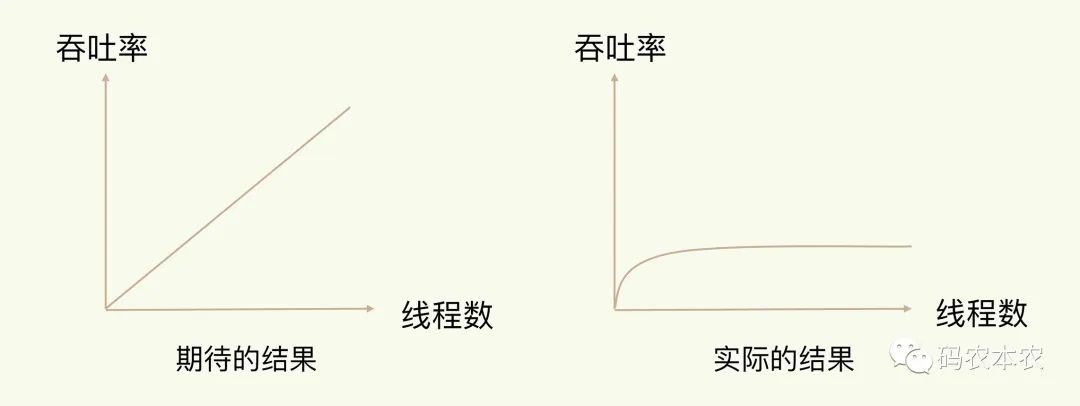
线程数与系统吞吐率
为什么会出现这种情况呢?一个关键的瓶颈在于,系统中通常会存在被多线程同时访问的共享资源,比如一个共享的数据结构。当有多个线程要修改这个共享资源时,为了保证共享资源的正确性,就需要有额外的机制进行保证,而这个额外的机制,就会带来额外的开销。
拿 Redis 来说,在上节课中,我提到过,Redis 有 List 的数据类型,并提供出队(LPOP)和入队(LPUSH)操作。假设 Redis 采用多线程设计,如下图所示,现在有两个线程 A 和 B,线程 A 对一个 List 做 LPUSH 操作,并对队列长度加 1。同时,线程 B 对该 List 执行 LPOP 操作,并对队列长度减 1。为了保证队列长度的正确性,Redis 需要让线程 A 和 B 的 LPUSH 和 LPOP 串行执行,这样一来,Redis 可以无误地记录它们对 List 长度的修改。否则,我们可能就会得到错误的长度结果。这就是多线程编程模式面临的共享资源的并发访问控制问题。
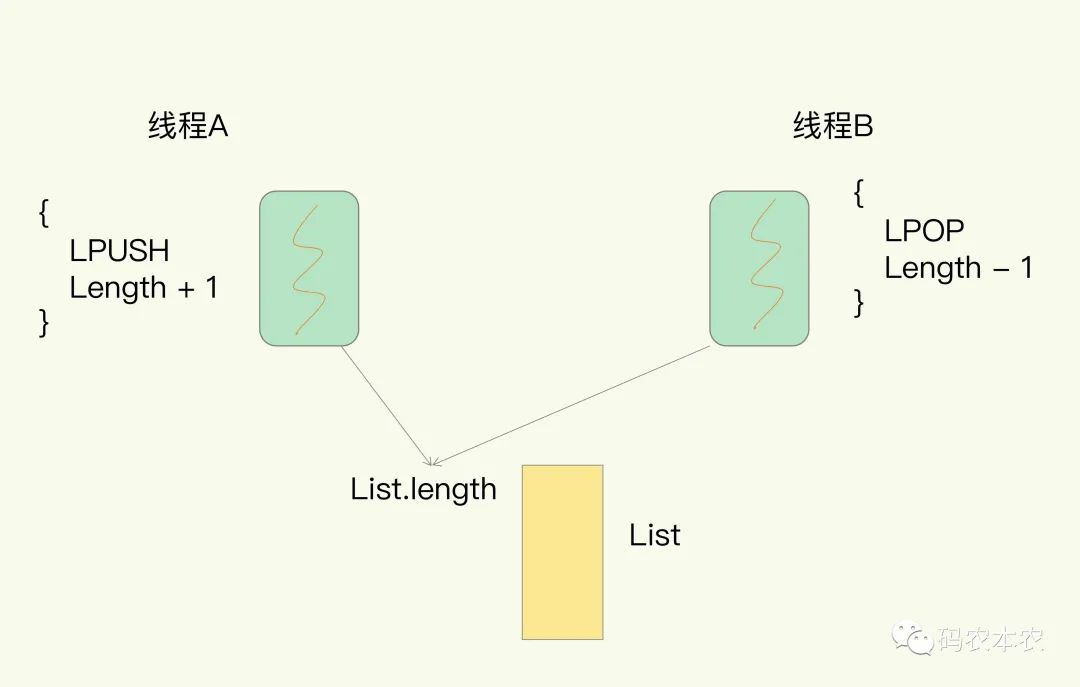
多线程并发访问Redis
并发访问控制一直是多线程开发中的一个难点问题,如果没有精细的设计,比如说,只是简单地采用一个粗粒度互斥锁,就会出现不理想的结果:即使增加了线程,大部分线程也在等待获取访问共享资源的互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加。
而且,采用多线程开发一般会引入同步原语来保护共享资源的并发访问,这也会降低系统代码的易调试性和可维护性。为了避免这些问题,Redis 直接采用了单线程模式。
讲到这里,你应该已经明白了“Redis 为什么用单线程”,那么,接下来,我们就来看看,为什么单线程 Redis 能获得高性能。
单线程 Redis 为什么那么快?
通常来说,单线程的处理能力要比多线程差很多,但是 Redis 却能使用单线程模型达到每秒数十万级别的处理能力,这是为什么呢?其实,这是 Redis 多方面设计选择的一个综合结果。
一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。另一方面,就是 Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。接下来,我们就重点学习下多路复用机制。
首先,我们要弄明白网络操作的基本 IO 模型和潜在的阻塞点。毕竟,Redis 采用单线程进行 IO,如果线程被阻塞了,就无法进行多路复用了。
1.基本 IO 模型与阻塞点
(1) 阻塞模式
其实下面所说的Socket 网络模型在早期的时候是没有非阻塞设置的,因此会造成一直等待,也就阻塞了。
这也就是我们所说的BIO网络模型,关于BIO这个最基本的IO模型,具体是怎么阻塞的想必大家都比较清楚,这里不再过多解释,本号其他文章有关于io模型的介绍。
(2) 非阻塞模式
Socket 网络模型的非阻塞模式设置,主要体现在三个关键的函数调用上,如果想要使用 socket 非阻塞模式,就必须要了解这三个函数的调用返回类型和设置模式。接下来,我们就重点学习下它们。
在 socket 模型中,不同操作调用后会返回不同的套接字类型。socket() 方法会返回主动套接字,然后调用 listen() 方法,将主动套接字转化为监听套接字,此时,可以监听来自客户端的连接请求。最后,调用 accept() 方法接收到达的客户端连接,并返回已连接套接字。
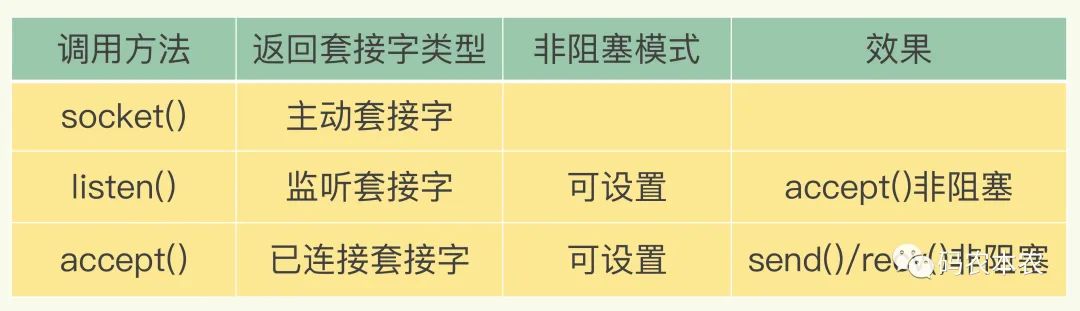
Redis套接字类型与非阻塞设置
针对监听套接字,我们可以设置非阻塞模式:当 Redis 调用 accept() 但一直未有连接请求到达时,Redis 线程可以返回处理其他操作,而不用一直等待。但是,你要注意的是,调用 accept() 时,已经存在监听套接字了。
虽然 Redis 线程可以不用继续等待,但是总得有机制继续在监听套接字上等待后续连接请求,并在有请求时通知 Redis。
类似的,我们也可以针对已连接套接字设置非阻塞模式:Redis 调用 recv() 后,如果已连接套接字上一直没有数据到达,Redis 线程同样可以返回处理其他操作。我们也需要有机制继续监听该已连接套接字,并在有数据达到时通知 Redis。
这样才能保证 Redis 线程,既不会像基本 IO 模型中一直在阻塞点等待,也不会导致 Redis 无法处理实际到达的连接请求或数据。
到此,Linux 中的 IO 多路复用机制就要登场了。
2.基于多路复用的高性能 I/O 模型
Linux 中的 IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
下图就是基于多路复用的 Redis IO 模型。图中的多个 FD 就是刚才所说的多个套接字。Redis 网络框架调用 epoll 机制,让内核监听这些套接字。此时,Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。
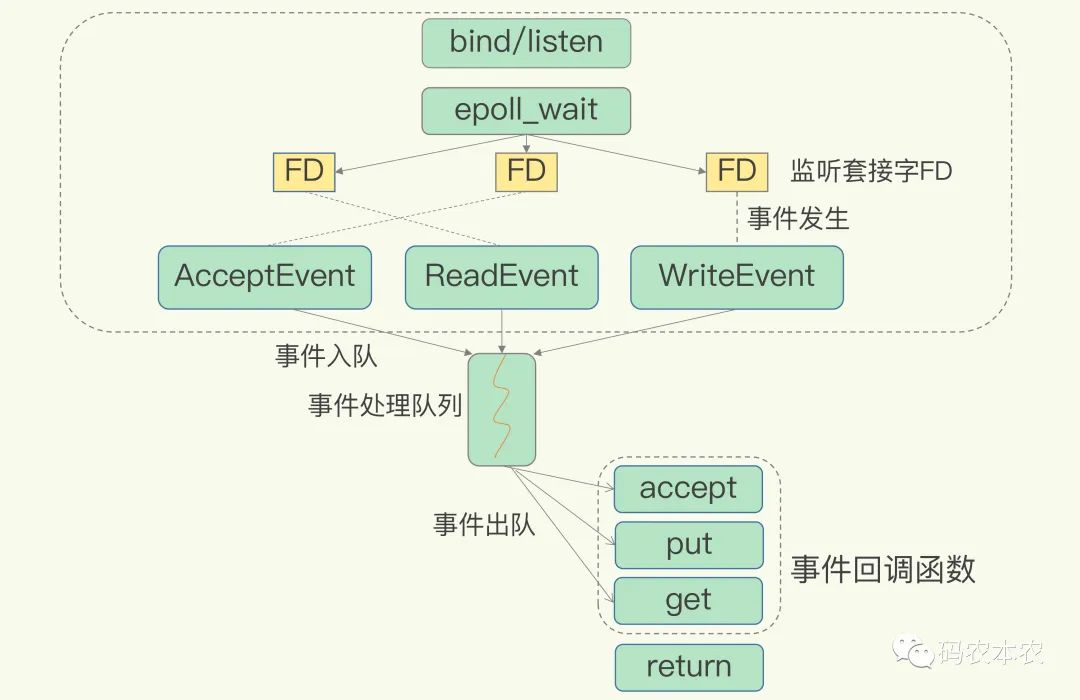
基于多路复用的Redis高性能IO模型
为了在请求到达时能通知到 Redis 线程,select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
那么,回调机制是怎么工作的呢?其实,select/epoll 一旦监测到 FD 上有请求到达时,就会触发相应的事件。
这些事件会被存放在一个事件队列中,Redis 单线程会不断地处理这个事件队列。这种方法使得 Redis 不必持续轮询是否有请求发生,有效地减少了对 CPU 资源的浪费。同时,Redis 在处理事件队列中的事件时,会触发相应的处理函数,从而实现了基于事件的回调机制。由于 Redis 不断地处理事件队列,因此能够迅速响应客户端请求,提高了 Redis 的响应性能。
为了更好地理解,我以连接请求和读数据请求为例,进一步解释这个过程。
这两个请求对应着 Accept 事件和 Read 事件,Redis 分别注册了 accept 和 get 回调函数来处理这两类事件。当 Linux 内核检测到连接请求或读取数据请求时,就会触发 Accept 事件和 Read 事件,此时内核会回调 Redis 的相应 accept 和 get 函数来处理这些事件。
这就好比病人前往医院就医。在医生实际进行诊断之前,每位病人(类似于请求)都需要经历分诊、测量体温、填写登记表等过程。如果所有这些工作都由医生亲自完成,那医生的效率将会很低。因此,医院通常设置了分诊台,分诊台会专门处理这些在诊断之前的任务(类似于 Linux 内核监听请求),然后再将病人交给医生进行实际诊断。这种方式,即使只有一个医生(相当于 Redis 单线程),效率也能够显著提高。
需要注意的是,多路复用机制是适用于各种操作系统的,即使你的应用在不同操作系统上运行,多路复用机制依然有效。这是因为多路复用机制的具体实现方式有多种,包括基于 Linux 系统的 select 和 epoll 实现、基于 FreeBSD 的 kqueue 实现,以及基于 Solaris 的 evport 实现,因此你可以根据 Redis 运行的实际操作系统,选择合适的多路复用实现方式。
小结
在前面的学习中,我们重点探讨了 Redis 线程背后的三个关键问题,即“Redis是否真的只使用单线程?”、“为什么坚持使用单线程?”以及“为何Redis的单线程如此高效?”
现在,我们已经理解,Redis的单线程指的是它采用单一线程来处理网络I/O和数据读写操作,而采用单线程的核心原因之一是为了避免多线程开发中的复杂并发控制问题。Redis的单线程性能卓越,与其采用的多路复用I/O模型密切相关,因为这有助于规避accept()和send()/recv()等潜在的网络I/O操作阻塞问题。
通过深入理解这些问题,您已经走在了许多人的前沿。如果您的朋友或同事还对这些问题感到困惑,不妨与他们分享这些见解,帮助他们消除疑虑。
此外,我来透露一下,您可能已经注意到,于2020年5月,Redis 6.0发布了其稳定版本,其中引入了多线程模型。那么,这个多线程模型与我们在本课程中讨论的I/O模型是否有关系?它是否会引入复杂的并发控制问题?又是否将如何提升Redis 6.0的性能表现?关于这些问题,我将在接下来的课程中为您详细介绍。





















