本文介绍了一篇由国防科技大学刘煜教授团队和浙江大学 - 商汤联合实验室周晓巍教授团队联合撰写的论文《Deep Active Contours for Real-time 6-DoF Object Tracking》,该论文已被计算机视觉与人工智能顶尖国际会议 ICCV 2023 录用。仅需要提供 CAD 框架模型,就可以在多种光照条件和局部遮挡情况下实现对立体物体的实时跟踪。传统的基于优化的方法根据手工特征将物体 CAD 模型的投影与查询图像对齐来求解位姿,容易陷入局部最优解;最近的基于学习的方法使用深度网络来预测位姿,但其要么预测精度有限,要么需要提供 CAD 纹理模型。
为此,研究员王龙和博士生颜深创新性地提出一种解决方案 DeepAC。DeepAC 结合了传统方法和深度学习方法的优势,提出了一个深度主动轮廓模型,以解决六自由度物体跟踪的问题。给定初始位姿,首先物体 CAD 模型会投影到图像平面上以获得初始轮廓,然后一个轻量级网络用于预测该轮廓应如何移动,以匹配图像中物体的真实边界,从而为物体位姿优化提供梯度。最后,提出了一种可微的优化算法,可以使用物体位姿真值端到端监督训练所提模型。在半合成和真实六自由度物体跟踪数据集上的实验结果表明,所提模型在定位精度方面大幅超过了当前最先进方法,并在移动端达到了实时性能。

- 论文地址:https://openaccess.thecvf.com/content/ICCV2023/papers/Wang_Deep_Active_Contours_for_Real-time_6-DoF_Object_Tracking_ICCV_2023_paper.pdf
- 项目主页:https://zju3dv.github.io/deep_ac/
背景
目前主流的六自由度物体跟踪方法分为基于关键点、基于边缘和基于区域三类。基于关键点的方法通过在二维图像和三维物体模型之间匹配关键点特征,来求解物体位姿;基于边缘的方法利用边缘信息 (显式或隐式) 计算两幅连续图像之间的相对位姿;基于区域的方法利用物体区域与背景区域在颜色统计上的区别,来求解物体位姿。然而,上述基于优化的方法存在一个共同缺点:它们需要手工设计特征和细致调整超参数,使其不能稳健地应用于各类真实场景。
近年来,一些端到端学习方法被提出以增强六自由度物体定位的鲁棒性,包括:直接回归几何参数;采用渲染 - 比对来迭代地优化位姿。尽管基于学习的方法具有潜力,但是直接回归法精度有限、泛化能力差;而渲染 - 比对法计算量大、不适用于实时应用,且需要提供带纹理的 CAD 模型。如何结合了传统优化方法和基于学习方法的优势,能够仅在 CAD 网格模型引导下,准确、鲁棒、实时地求解物体位姿,是一个亟待解决的问题。
六自由度物体跟踪的相关工作
1 基于优化的六自由度物体跟踪方法
基于优化的方法常用于解决六自由度物体跟踪问题,具体可以分为三种不同的类别:基于关键点 (Keypoint)、基于边缘 (Edge) 和基于区域 (Region)。基于关键点的方法利用局部特征匹配或光流技术建立 2D-3D 对应关系。虽然这种方法表现出了出色的性能,但它需要提供物体的纹理模型。为了解决这个问题,研究人员提出了基于边缘的方法,通过隐式或显示地分析物体边缘位移,判断物体六自由度位姿变化。例如,RAPiD 通过在投影边缘的正交方向上搜索最大梯度,来估计连续帧之间的相对位姿。然而,基于边缘的方法处理不好背景有杂物和运动模糊的情况。
这几年,基于区域的方法在复杂环境的跟踪任务中取得了显著进展。该研究最早可以追溯到 PWP3D 的工作,其有效地结合了前背景分割的统计模型和物体投影的边界距离场来优化物体位姿。近年来,RBGT 引入了多视角预计算的稀疏对应线 (Correspondence lines),建立符合了高斯分布的概率模型,并使用牛顿法快速收敛到物体位姿。SRT3D 引入了平滑的阶跃函数,考虑到全局和局部不确定性,相较于现有方法有明显改进。然而,基于区域的物体连续位姿估计算法会受到人工定义的特征和超参数限制。
2 基于学习的六自由度物体跟踪方法
近年来,深度学习方法在六自由度物体姿态估计领域取得了显著进展。其中一种方法是直接预测旋转和平移参数。另一种方法则是通过检测或回归物体坐标生成 2D-3D 对应关系,进而使用 PnP 求解器估计六自由度位姿。然而,仅通过单个网络预测物体位姿,其输出往往不准确。
为了克服这个问题,一些研究采用迭代优化的技术以取得更精确的结果。这类方法的关键是迭代的 “渲染 - 比对” 思想。在每次迭代中,利用当前估计的物体位姿渲染三维纹理模型,然后将渲染图像与实际图像进行比较,并用神经网络更新位姿,从而使两者逐渐对齐。目前,基于学习的方法的主要不足是需要使用 GPU,这使得它们不适合在移动应用程序中部署,例如虚拟现实、增强现实应用。此外,这类方法需要提供物体的纹理模型,但在实际任务中,用户预先获取的往往是一个三维扫描或者人工设计的 CAD 网格模型。
方法
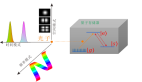
针对上述背景和相关工作,论文提出了提出了一种传统方法和学习方法结合的方案。给定一个视频序列 和初始时刻的物体位姿,所提方法使用当前帧的单个 RGB 图像
和初始时刻的物体位姿,所提方法使用当前帧的单个 RGB 图像 和前一帧该物体位姿
和前一帧该物体位姿 来求解当前帧的物体位姿
来求解当前帧的物体位姿 。
。

1 轮廓特征图提取
利用上一帧的物体位姿,在 RGB 图像上裁剪出一个包含目标物体的矩阵区域 ,并使用以 MobileNetV2 为基础的 FPN-Lite 网络,对图像
,并使用以 MobileNetV2 为基础的 FPN-Lite 网络,对图像 提取多层特征。提取的多尺度特征图表示为
提取多层特征。提取的多尺度特征图表示为 ,包含一系列由粗到细的特征信息。其中,
,包含一系列由粗到细的特征信息。其中, ,
, ,
, ,
, 分别表示尺度为 s 的特征图宽度、高度和维度,
分别表示尺度为 s 的特征图宽度、高度和维度, 为提取特征的层数。这种由粗到细的网络设计可以使得神经网络编码到更广的空间信息,从而提高在物体大幅度运动情况下的定位精度。下图可视化了一组 FPN-Lite 网络提取的多层次特征图,先用 PCA 对特征图
为提取特征的层数。这种由粗到细的网络设计可以使得神经网络编码到更广的空间信息,从而提高在物体大幅度运动情况下的定位精度。下图可视化了一组 FPN-Lite 网络提取的多层次特征图,先用 PCA 对特征图 进行降维,再表示成 RGB 图像。
进行降维,再表示成 RGB 图像。

受到 RBGT 的启发,论文使用对应线模型 (Correspondence Line Model) 描述二维轮廓的局部区域。具体来说,对应线模型在二维轮廓上均匀采样若干个二维点,并建立相应的对应线 。每条对应线由一个中心点
。每条对应线由一个中心点 和一个单位法向量
和一个单位法向量 组成,它们通过三维轮廓点
组成,它们通过三维轮廓点 及其相关的三维法向量
及其相关的三维法向量 投影到二维图像平面上得到。通过在特征图
投影到二维图像平面上得到。通过在特征图 上插值采样这些二维点集 (使用 PyTorch 的 grid_sample 函数),可生成轮廓特征图
上插值采样这些二维点集 (使用 PyTorch 的 grid_sample 函数),可生成轮廓特征图 ,
, 是采样的二维轮廓点的数量。
是采样的二维轮廓点的数量。
2 边界图预测
论文设计了一个轻量化网络,用于预测边界概率图 ,
, 动态设定,以移除图像边缘外的区域。在边界概率图
动态设定,以移除图像边缘外的区域。在边界概率图 中,位于
中,位于 坐标处的值表示二维点
坐标处的值表示二维点 作为第
作为第 条对应线边界的概率。为了提高网络的泛化能力,论文将基于传统统计方法所得到的前景概率图
条对应线边界的概率。为了提高网络的泛化能力,论文将基于传统统计方法所得到的前景概率图 和边界概率图
和边界概率图 与轮廓特征图
与轮廓特征图 融合,作为轻量化网络的输入。
融合,作为轻量化网络的输入。

上图详细介绍了边界预测模块的前向传播过程。其使用了三种不同的输入,分别是前景概率图 和边界概率图
和边界概率图 与轮廓特征图
与轮廓特征图 。通过在不同阶段使用拼接 (Concat) 操作,将这些信息融入到神经网络中,来预测边界概率图
。通过在不同阶段使用拼接 (Concat) 操作,将这些信息融入到神经网络中,来预测边界概率图 。实验表明,将传统统计信息和深度特征进行融合并作为网络的输入,能够显著的提高定位算法的性能指标。
。实验表明,将传统统计信息和深度特征进行融合并作为网络的输入,能够显著的提高定位算法的性能指标。
3 位姿优化
本小节基于轻量化网络学习得到的边界概率图 ,采用迭代优化方法恢复当前帧物体的位姿
,采用迭代优化方法恢复当前帧物体的位姿 。在位姿
。在位姿 每一轮迭代更新时,二维轮廓点
每一轮迭代更新时,二维轮廓点 和三维轮廓点
和三维轮廓点 之间重投影误差
之间重投影误差 计算如下:
计算如下:

其中, 为投影轮廓法向向量,
为投影轮廓法向向量, 和
和 分别为物体在第 k 帧的旋转和平移,π 表示针孔相机模型的投影函数:
分别为物体在第 k 帧的旋转和平移,π 表示针孔相机模型的投影函数:

其中, 分别为x,y图像空间方向焦距及光心。给定位姿
分别为x,y图像空间方向焦距及光心。给定位姿 后,重投影
后,重投影 距离刻画了三维轮廓点
距离刻画了三维轮廓点 的投影在第i条的对应线上的位置。该位置作为边界点的似然估计是:
的投影在第i条的对应线上的位置。该位置作为边界点的似然估计是:

每条对应线上边界点似然估计相互独立,则所有对应线整体似然估计为:

本小节的目标为寻找使得似然估计最大化的位姿 。
。
为了最大化该似然估计,本小节采用了迭代牛顿法和 Tikhonov 正则化来优化位姿求解。具体的位姿更新方式如下:

式中H为海森矩阵,g是梯度向量, 为 3×3 的单位矩阵。
为 3×3 的单位矩阵。 和
和 分别表示三维旋转和三维平移的正则化参数。由于三维旋转R属于一个李群,所以它可用一个李代数的指数映射表示:
分别表示三维旋转和三维平移的正则化参数。由于三维旋转R属于一个李群,所以它可用一个李代数的指数映射表示:

式中,三维向量 是李代数空间 so (3) 的元素,
是李代数空间 so (3) 的元素, 为
为 的斜对称矩阵。因此一个位姿
的斜对称矩阵。因此一个位姿 能够被一个六自由度的变量表示
能够被一个六自由度的变量表示 ,
, 。根据链式求导法则,海森矩阵H和梯度向量g的计算如下:
。根据链式求导法则,海森矩阵H和梯度向量g的计算如下:

式中 为三维轮廓点
为三维轮廓点 在相机坐标空间的位置。
在相机坐标空间的位置。 为重投影误差相对于相机坐标空间点
为重投影误差相对于相机坐标空间点 的一阶偏导数,它的计算公式如下:
的一阶偏导数,它的计算公式如下:

对于相机坐标空间下的三维点相对于六自由度位姿的一阶偏导数 的计算,本小节采用经典的扰动模型推导得到如下公式:
的计算,本小节采用经典的扰动模型推导得到如下公式:

为了端到端训练之前所提出的网络模型,本小节采用两种近似方法来估计 关于
关于 的一阶导数。第一种近似方法直接使用每条对应线的均值
的一阶导数。第一种近似方法直接使用每条对应线的均值 和方差
和方差 计算导数,具体计算方式如下:
计算导数,具体计算方式如下:

第二种近似方法利用了三维轮廓投影点附近区域的边界概率,具体计算公式如下:

这两种近似方法具有不同的特性:第一种近似用于直接学习每条对应线上的边界位置 ,从而实现快速收敛。第二种近似用于学习局部边界概率,从而细致优化位姿。此外,方差
,从而实现快速收敛。第二种近似用于学习局部边界概率,从而细致优化位姿。此外,方差 用于刻画每条对应线的不确定性,在位姿求解过程中起到了增强鲁棒性的作用。为了分析边界不确定性对于物体姿态预测的影响,论文采用了一种基于颜色渐变的可视化方法,使用用较暖 (红色) 的颜色来表示边界不确 定性值 (即
用于刻画每条对应线的不确定性,在位姿求解过程中起到了增强鲁棒性的作用。为了分析边界不确定性对于物体姿态预测的影响,论文采用了一种基于颜色渐变的可视化方法,使用用较暖 (红色) 的颜色来表示边界不确 定性值 (即 ) 较小的区域。从下图中可以看出,物体没有被遮挡的边界对于位姿预测更有帮助,而被遮挡的边界则相对无关紧要。
) 较小的区域。从下图中可以看出,物体没有被遮挡的边界对于位姿预测更有帮助,而被遮挡的边界则相对无关紧要。

4 网络监督
论文提出的方法以每次迭代优化后所得的位姿 与真实位姿
与真实位姿 间的差异为依据:
间的差异为依据:

其中,P是 Huber 鲁棒核函数。为了避免困难样例对模型训练产生不利影响,论文采用了条件损失函数:只有在前一次迭代优化后所得的位姿在真实解附近时,才将其纳入损失函数的计算中;如果某次迭代优化后所得的位姿偏离真实解过大,则忽略其对应的损失项。这样可以保证模型只使用可信度高的训练样本。
结果
1 与基于优化的方法比较
(1)RBOT 数据集
在 RBOT 数据集上,论文采用 5cm−5◦召回率,来评估定位的精度。具体而言,每一帧图像是否被成功定位取决于其平移误差是否小于 5cm 且旋转误差是否小于 5◦。
实验结果表明,在常规、动态光照和场景遮挡下,现有的基于优化的方法已经非常接近性能上限,SRT3D 和 LDT3D 的 5cm−5◦召回率已接近或超过 95%。在这三种情况下,DeepAC 表现出了相似的性能,在常规和动态光照情况下小幅领先,在场景遮挡情况下略微落后。但是,在噪声情况下,所提方法显著优于其他基于优化的方法,5cm−5◦召回率从 83.2% 提高到 88.0%,这一结果证明了 DeepAC 对图像噪声具有较强的鲁棒性。

(2)BCOT 数据集
论文在 BCOT 数据集上对所提方法进行了实验验证,并采用 ADD-(s) d 和厘米 - 度召回率来评估位姿估计的精度。与在 RBOT 数据集上进行的实验不同,在 BCOT 数据集上,增加了一些更严格的评价指标,即 ADD-0.02d、ADD-0.05d、 ADD-0.1d 以及 2cm−2◦召回率,以评估算法的高精度定位能力。其中,d 表示物体模型 3D 包围盒的最大长度。
实验结果表明,DeepAC 在所有阈值下的 ADD-(s) d 和厘米 - 度召回率均优于其他基于优化的基线方法。特别是,在非常严格的 ADD-(s) d 标准下,所提方法表现出显著的优势,相比于排名第二的 LDT3D,在 ADD-0.02d、ADD-0.05d 和 ADD-0.1d 上分别提高了 9.1 个百分点、14.1 个百分点和 9.6 个百分点。这些结果充分表明了 DeepAC 具有高精度定位的能力。

(3) OPT 数据集
在 OPT 数据集上,论文先计算不同误差阈值 s 下的 ADD-(s) d 得分,再通过计算曲线下面积 (AUC) 得分来衡量视频序列中物体位姿估计的质量。其中,误差阈值 s 的范围设定为 [0, 0.2]。
下表显示了 DeepAC 在六个物体上均优于当前最先进的基于优化的方法,在 AUC 分数上取得了明显提升。在平均 AUC 分数方面,DeepAC 达到 16.69,比排名第二的方法 SRT3D 高出 6.10%。这些结果表明 DeepAC 在真实场景下具有优异的跟踪能力。

2 与基于学习的方法比较
为了验证 DeepAC 模型在不同数据集上具有很好的泛化能力,论文在 RBOT 数据集上与当前最先进的基于学习的方法进行了对比实验。论文选取了除 “Clown” 物体外 (因为其纹理图有误) 所有序列作为测试集,并使用平均 ADD-(s) d 和厘米 - 度召回率作为评估指标。为了与其他基于学习的方法公平比较,所提方法 DeepAC 使用相同的训练数据和方式,并记作 DeepAC−。

实验结果显示,其他典型的基于学习的方法定位精度远低于 DeepAC,这充分说明了 DeepAC 在不同数据集上具有很强大且稳定的泛化能力。
3 消融分析
论文通过消融实验分析 DeepAC 中三个主要的设计对物体六自由度定位性能的影响,分别是:1) 统计信息融入;2) 多层特征提取;3) 边界不确定性估计。实验在 RBOT 和 BCOT 数据集上进行,并将结果展示在下表。

应用前景
该研究成果在民用和军事领域都有广泛的应用。在民用领域,该研究可用于强现实、机器人操作和人机交互等众多应用。在军事领域,该研究可用于支持空中无人装备与巡飞弹在复杂光照条件下对目标的多角度实时跟踪与打击。