大家好,我是Echa。
计算机视觉,与语音识别、自然语言理解,并称为人工智能的三大主要技术领域,也是AI技术落地产业化最广泛的领域。
 百度 Apollo Scape
百度 Apollo Scape
随着科技的发展,要计算机识别现实世界中的物体需要借助传感器硬件设备(摄像头、声纳等),就像人类的眼睛帮助我们看到周围世界并做出反应一样。但计算机想要识别传感器检测到的数据到底是什么物体,就需要事先使用一定的视觉算法对大量的数据进行训练,才能够让计算机能够识别传感器数据中所包含的物体类别并做出响应。
 本田 车内设觉
本田 车内设觉
如今,计算机视觉在身份核验、工业、农业、医学、交通、海洋等许多行业都有广泛的用途。因此,对高质量计算机视觉库的需求也相应增加。计算机视觉库是一个预先编写好的算法代码和一些预训练好的模型或者数据。目前,在开源领域,计算机视觉库数量非常多,包括图像识别库、人脸识别库等。
 NEXET
NEXET
借此机会,小编今天给大家好物分享16个上热搜的黑科技开源项目,希望对大家所有帮助。你们都了解几个呢?接下来小编带着大家一一介绍。
全文大纲
- OpenCV- 迄今为止最古老也是最受欢迎的开源计算机视觉库。
- TorchVision - 拥有计算机视觉中最常见的图像转换功能,还包含计算机视觉神经网络的数据集和模型架构以及常见数据集。
- YOLO - 是最快的计算机视觉工具之一,由Joseph雷德蒙和Ali Farhadi于2016年开发,专门用于实时图像对象检测
- MMCV- 是一个基于PyTorch的图像/视频处理和转换器。
- Scikit-Image - 公认的最方便的Python视觉库,它是Scikit-Learn的一个扩展库。
- Pillow (PIL Fork) - 是一个Python编写的图像处理库。
- TensorFlow - 是由GoogleBrain团队开发并于2015年11月发布的AI框架,旨在促进构建AI模型的过程。
- MATLAB - 是Matrix Laboratory的缩写,但它是一个付费编程平台,适合用于如机器学习、深度学习、图像处理、视频信号处理等方面的应用。
- Keras - 它允许快速构建神经网络模型,是一个模块化的AI工具箱,计算机视觉工程师可以利用它来快速组装应用、训练模型。
- NVIDIA CUDA-X - 是一个GPU加速库和工具的集合,可以开始使用新的应用程序或GPA加速。它包含数学库、并行算法库、图像和视频库、通信库和深度学习库。
- NVIDIA Performance Primitives - CUDA(Compute Unified Device Architecture的缩写)是NVIDIA开发的并行计算平台和应用程序编程接口(API)模型。
- PyTorch - 是一个Python的开源机器学习框架,主要由Facebook的AI研究小组开发。
- OpenVINO- 它是一套非常全面的计算机视觉工具。
- Caffe - 一个易于使用的开源深度学习和计算机视觉框架,由加州大学伯克利分校开发。
- SimpleCV - 是一个开源免费的机器视觉框架。
- Detectron2 - 是由Facebook AI Research(FAIR)开发的基于PyTorch的模对象检测库。
OpenCV- 迄今为止最古老也是最受欢迎的开源计算机视觉库。
Github:https://github.com/opencv/opencv
 OpenCV 官网
OpenCV 官网
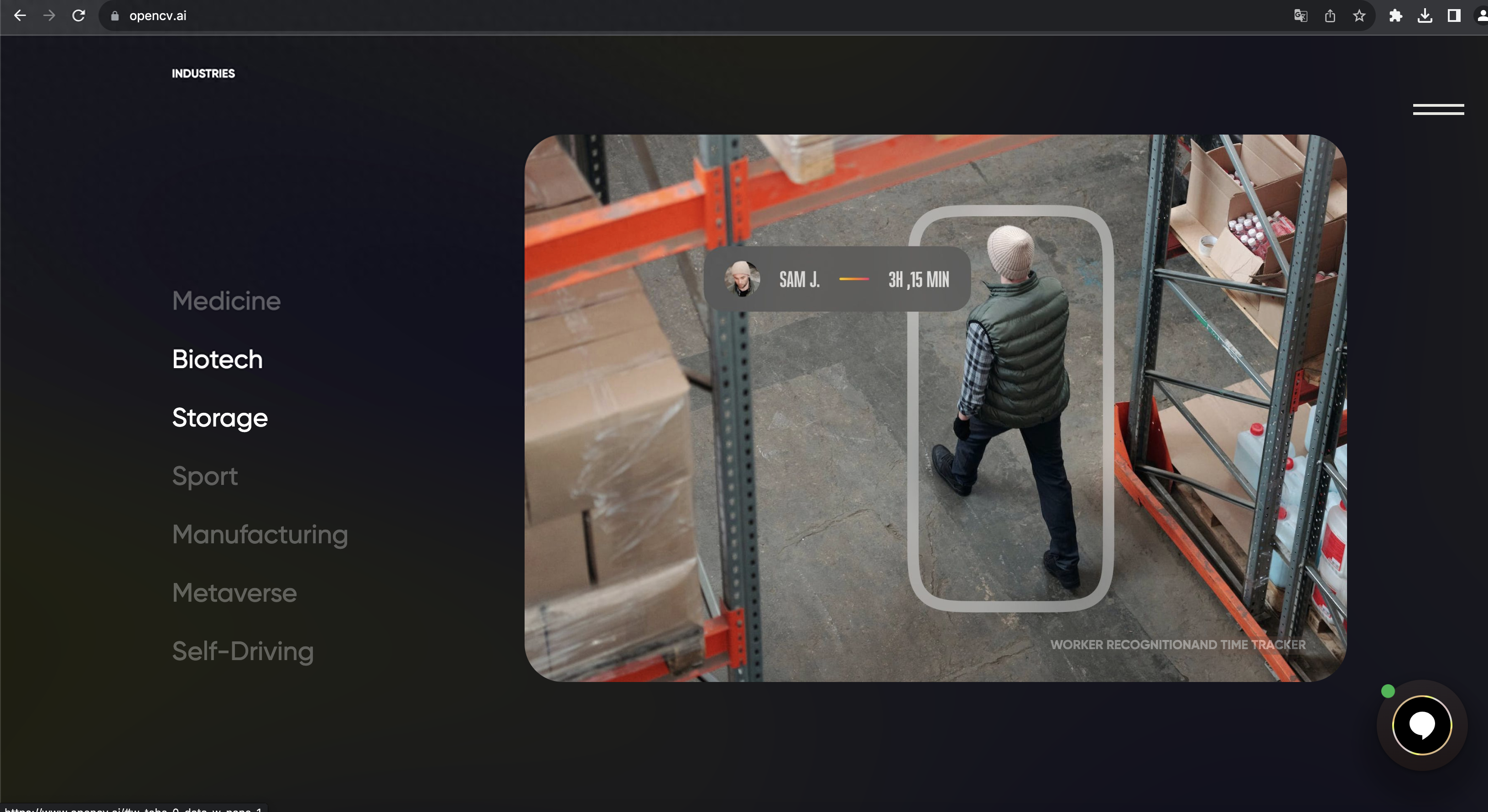
OpenCV是迄今为止最古老也是最受欢迎的开源计算机视觉库,旨在为计算机视觉应用提供通用底层算法。
支持跨平台应用,支持Windows,Linux,Android和macOS。支持各种主流的开发语言,例如:Python,Java,C++等。OpenCV有一个Python Wrapper,支持GPU的CUDA模型。包含一些可以转换为TensorFlow模型的模型。最初由Intel开发,现在可以在开源BSD许可证下免费使用。

OpenCV的主要功能包括:
- 2D和3D图像工具包
- 人脸识别
- 手势识别
- 运动检测
- 人机交互
- 对象检测
- 图像分割和对象识别
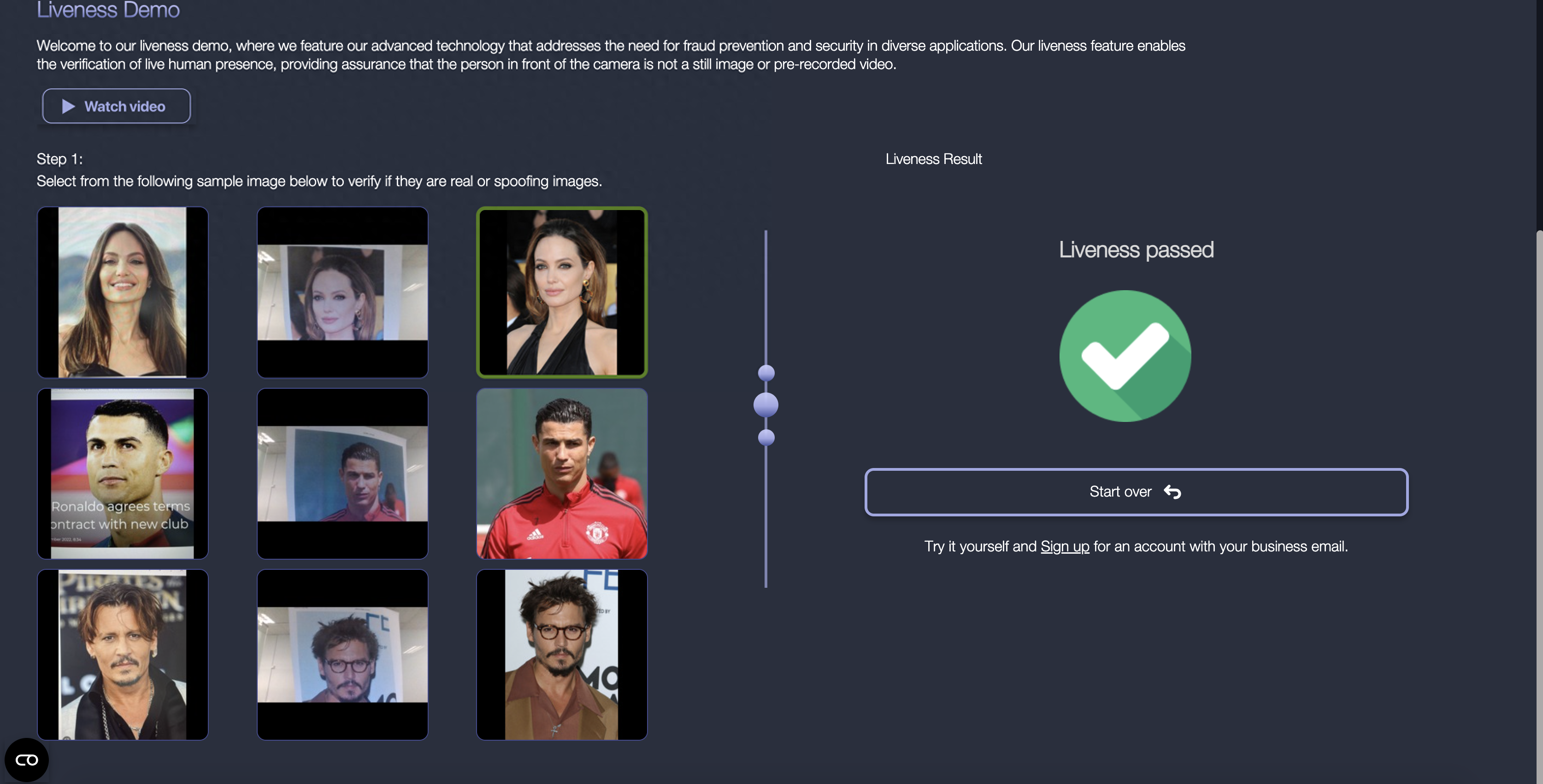 OpenCV Demo
OpenCV Demo
Github:https://github.com/pytorch/pytorch
 PyTorch 官网
PyTorch 官网
TorchVision是PyTorch库的一个扩展库,TorchVision拥有计算机视觉中最常见的图像转换功能,还包含计算机视觉神经网络的数据集和模型架构以及常见数据集。
TorchVision旨在为方便使用PyTorch模型进行计算机视觉图像转换,而无需将图像转换为NumPy数组。TorchVision可以用于Python和C++语言开发环境。可以通过pip install将TorchVision与PyTorch库一起搭配使用。
以下是预训练分割模型的使用例子。

Github:https://github.com/ultralytics/ultralytics
 YOLO 官网
YOLO 官网
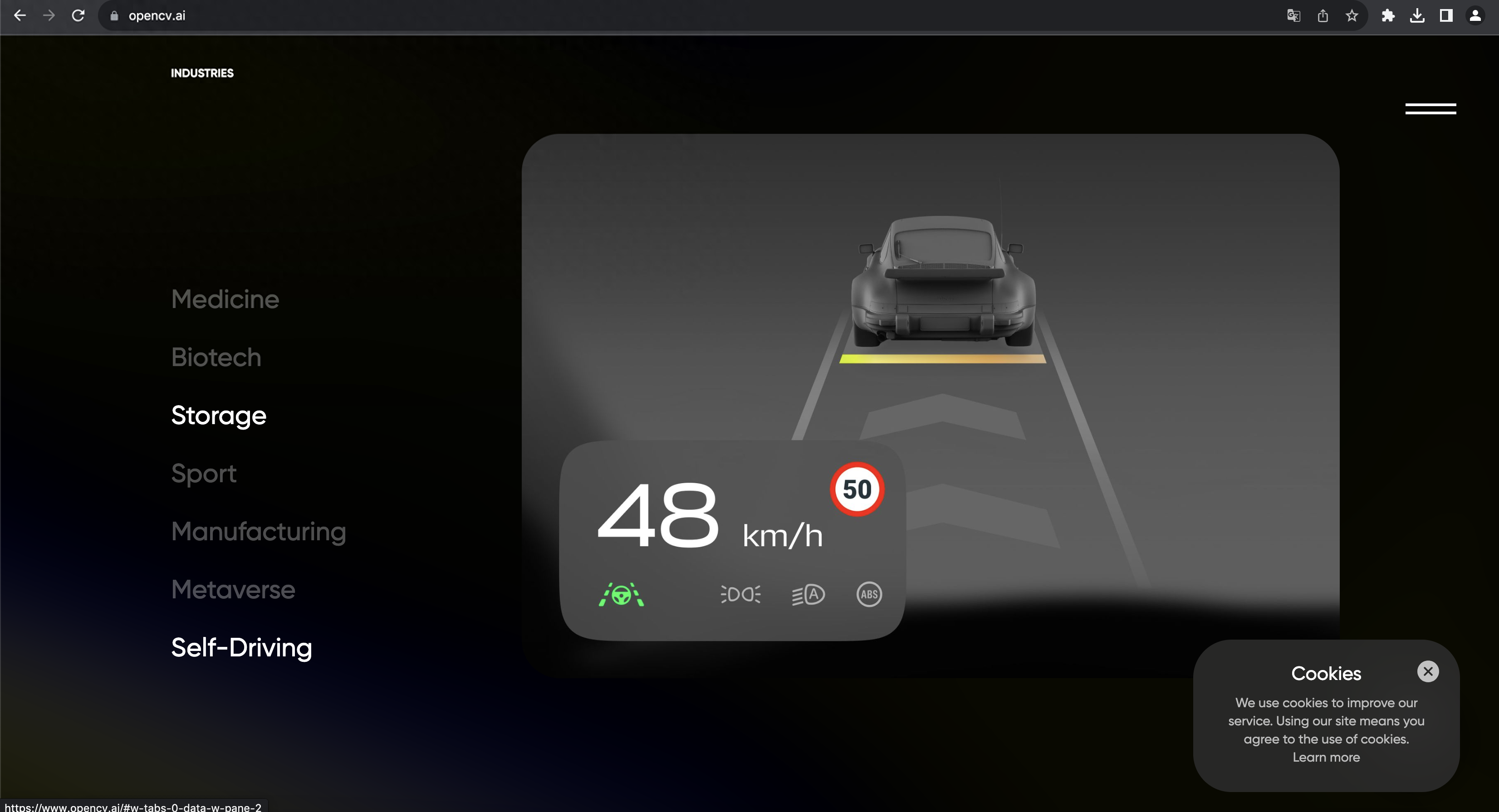
YOLO是最快的计算机视觉工具之一,由Joseph雷德蒙和Ali Farhadi于2016年开发,专门用于实时图像对象检测。YOLO使用将神经网络,将图像划分为网格,然后同时预测每个网格,以提高识别效率。
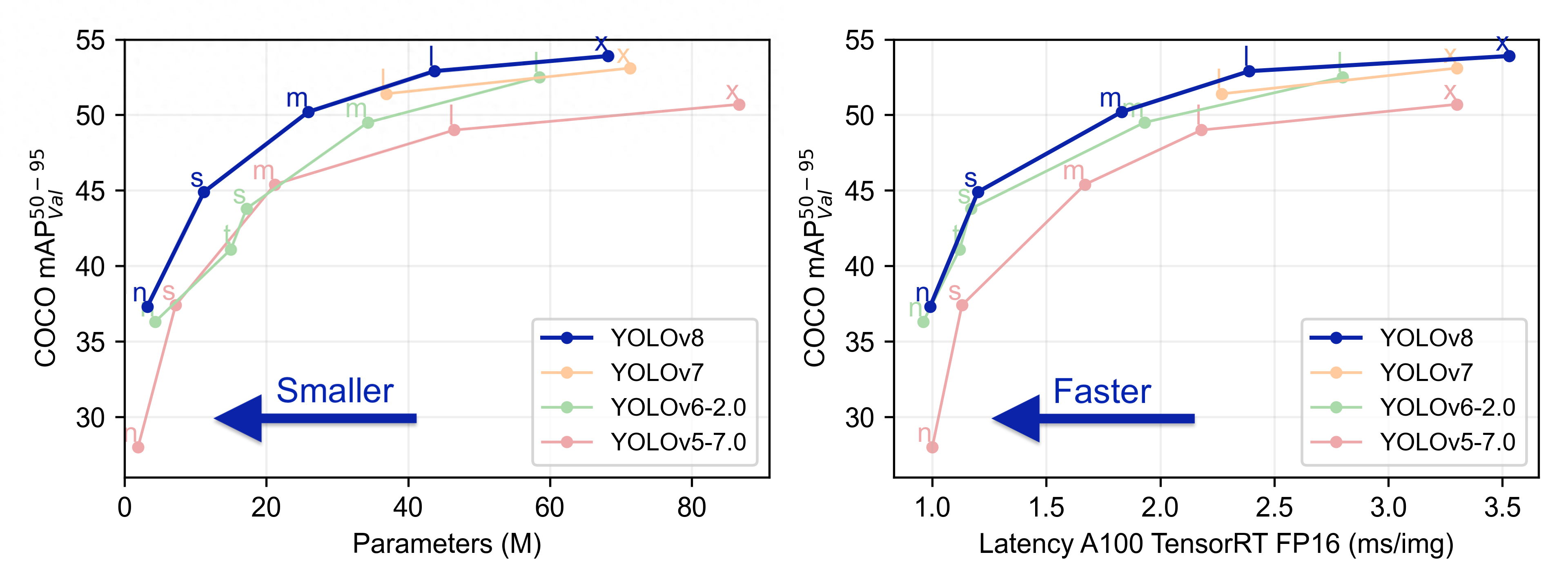
目前YOLO已经发布V8。YOLOv8 是一款前沿、最先进(SOTA)的模型,基于先前 YOLO 版本的成功并引入了新的功能和改进,进一步提升了性能和灵活性。YOLOv8 的快速、准确且易于使用,使其成为各种对象检测与跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。
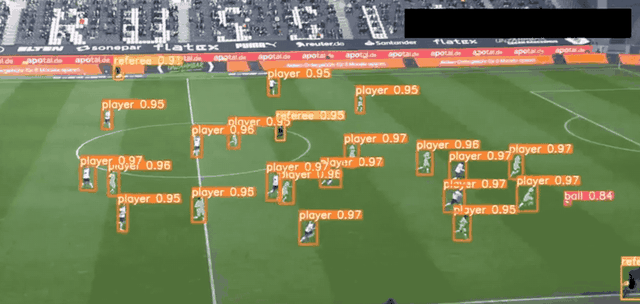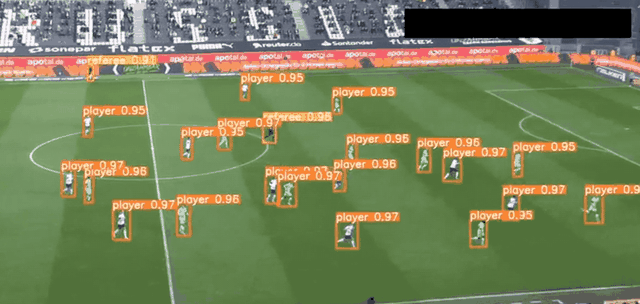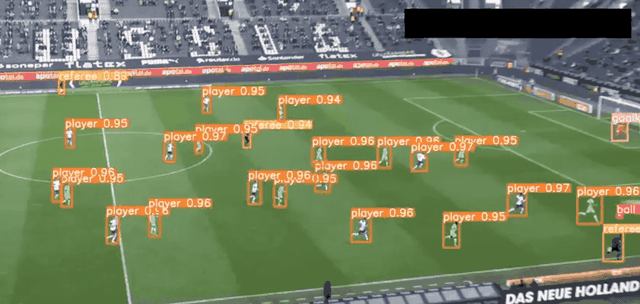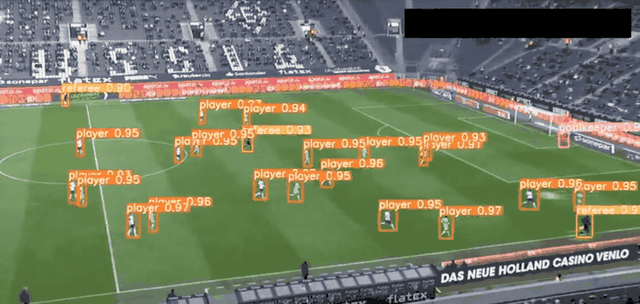 YOLO 应用场景
YOLO 应用场景
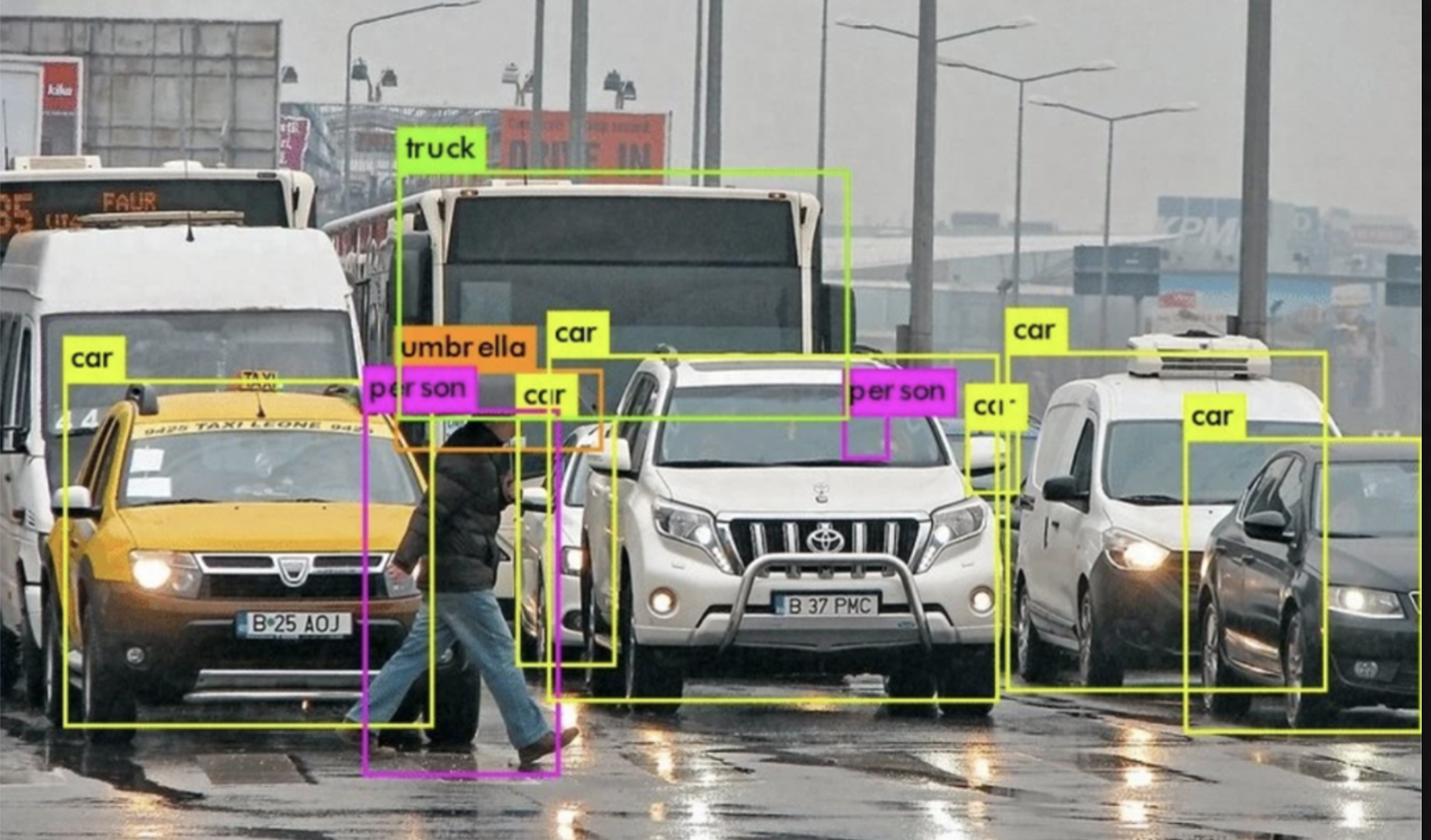
Github:https://github.com/open-mmlab/mmcv
MMCV 中文版官方
OpenMMLab 团队于 2022 年 9 月 1 日在世界人工智能大会发布了新一代训练引擎 MMEngine,它是一个用于训练深度学习模型的基础库。相比于 MMCV,它提供了更高级且通用的训练器、接口更加统一的开放架构以及可定制化程度更高的训练流程。
MMCV v2.0.0 正式版本于 2023 年 4 月 6 日发布。在 2.x 版本中,它删除了和训练流程相关的组件,并新增了数据变换模块。另外,从 2.x 版本开始,重命名包名 mmcv 为 mmcv-lite 以及 mmcv-full 为 mmcv。
MMCV是一个基于PyTorch的图像/视频处理和转换器。它支持Linux、Windows和macOS等系统,是计算机视觉研究人员最常用的包之一。支持Python和C++开发语音。

MMCV 是一个面向计算机视觉的基础库,它提供了以下功能:
- 图像和视频处理
- 图像和标注结果可视化
- 图像变换
- 多种 CNN 网络结构
- 高质量实现的常见 CUDA 算子
MMCV 支持多种平台,包括:
- Linux
- Windows
- macOS
Github:https://github.com/scikit-image/scikit-image
 Scikit-Image 官网
Scikit-Image 官网
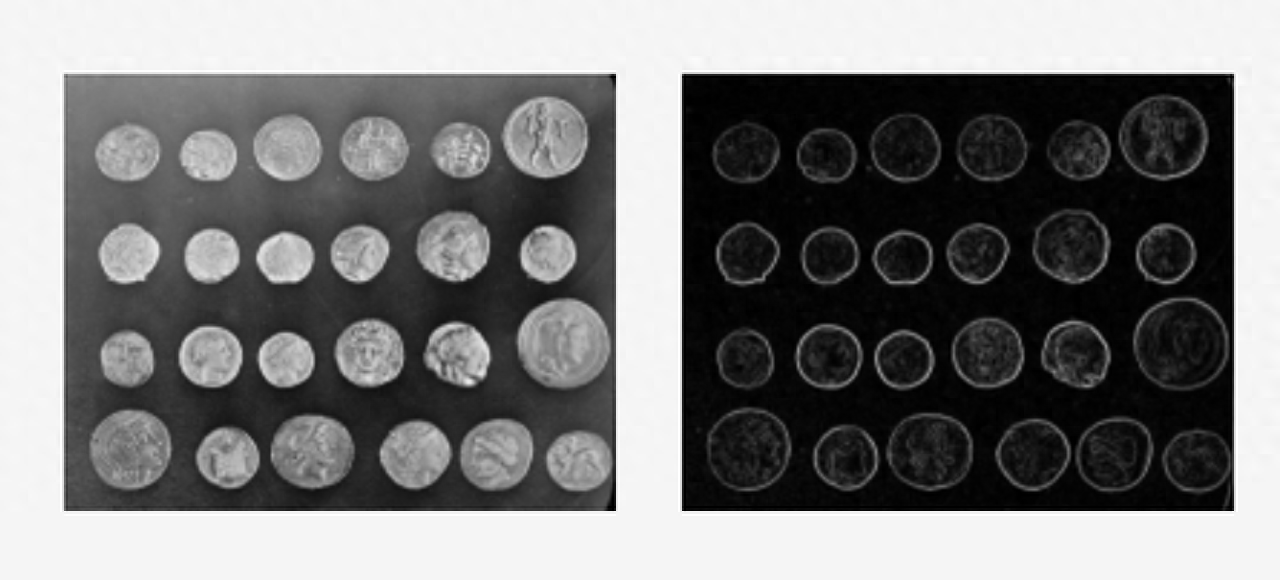
Scikit-Image是公认的最方便的Python视觉库,它是Scikit-Learn的一个扩展库。是监督和无监督机器学习最常用的工具之一。可以用于将NumPy数组作为图像对象进行处理。
以下是使用Scikit-image进行硬币识别的例子。
Github:https://github.com/python-pillow/Pillow
 Pillow (PIL Fork) 官网
Pillow (PIL Fork) 官网
Pillow是一个Python编写的图像处理库。它支持Windows、Mac OS X和Linux平台,可以在C和Python语言中使用Pillow库。主要用于阅读和保存不同格式的图像,Pillow还包括各种基本图像变换功能,例如:旋转、合并、缩放等。
Github:https://github.com/tensorflow/tensorflow
 TensorFlow 官网
TensorFlow 官网
TensorFlow是由GoogleBrain团队开发并于2015年11月发布的AI框架,旨在促进构建AI模型的过程。它有一些扩展解决方案,如针对浏览器和Node.js的TensorFlow.js,以及针对终端设备的TensorFlow Lite。另外,TensorFlow还提供了一个更好的框架TensorFlow Hub。这是一个更易于使用的平台,可以使用TensorFlow Hub实现重复使用BERT和Faster R-CNN训练模型、查找可随时部署的模型、托管模型以供他人使用。
TensorFlow允许用户开发与计算机视觉相关的机器学习模型,例如:人脸识别、图像分类、目标检测等。与OpenCV一样,Tensorflow也支持各种语言,如Python、C、C++、Java或JavaScript。
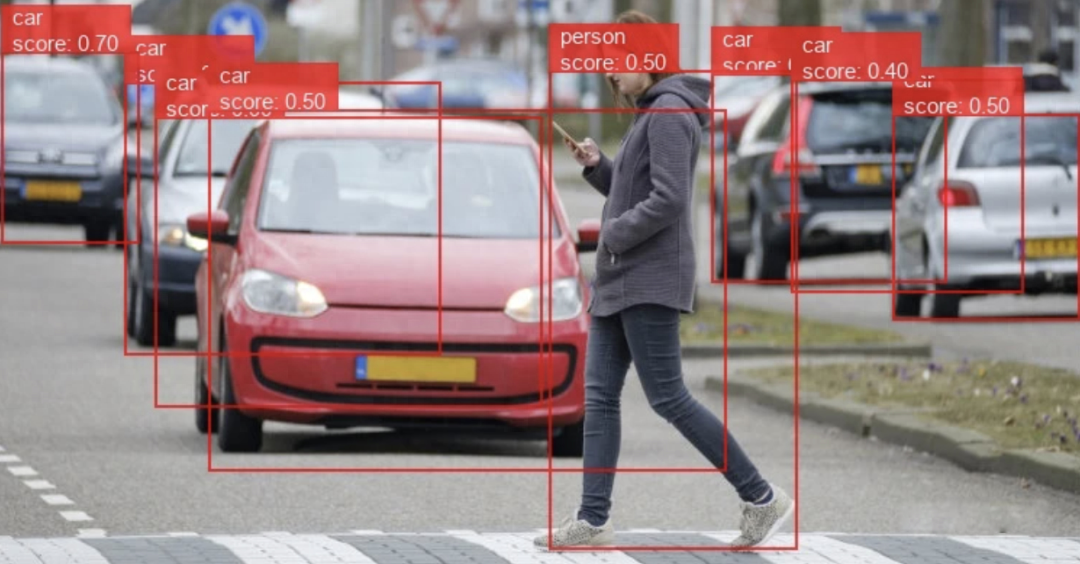
TensorFlow 应用场景
传送门:https://ww2.mathworks.cn/products/matlab.html
 MATLAB 官网
MATLAB 官网
MATLAB是Matrix Laboratory的缩写,但它是一个付费编程平台,适合用于如机器学习、深度学习、图像处理、视频信号处理等方面的应用,是一个受到工程师和科学家喜欢的编程平台。它配备了一个计算机视觉工具箱,包含许多算法能力,如:
- 视频目标检测与目标跟踪
- 物体识别
- 校准摄像机
- 处理三维视觉
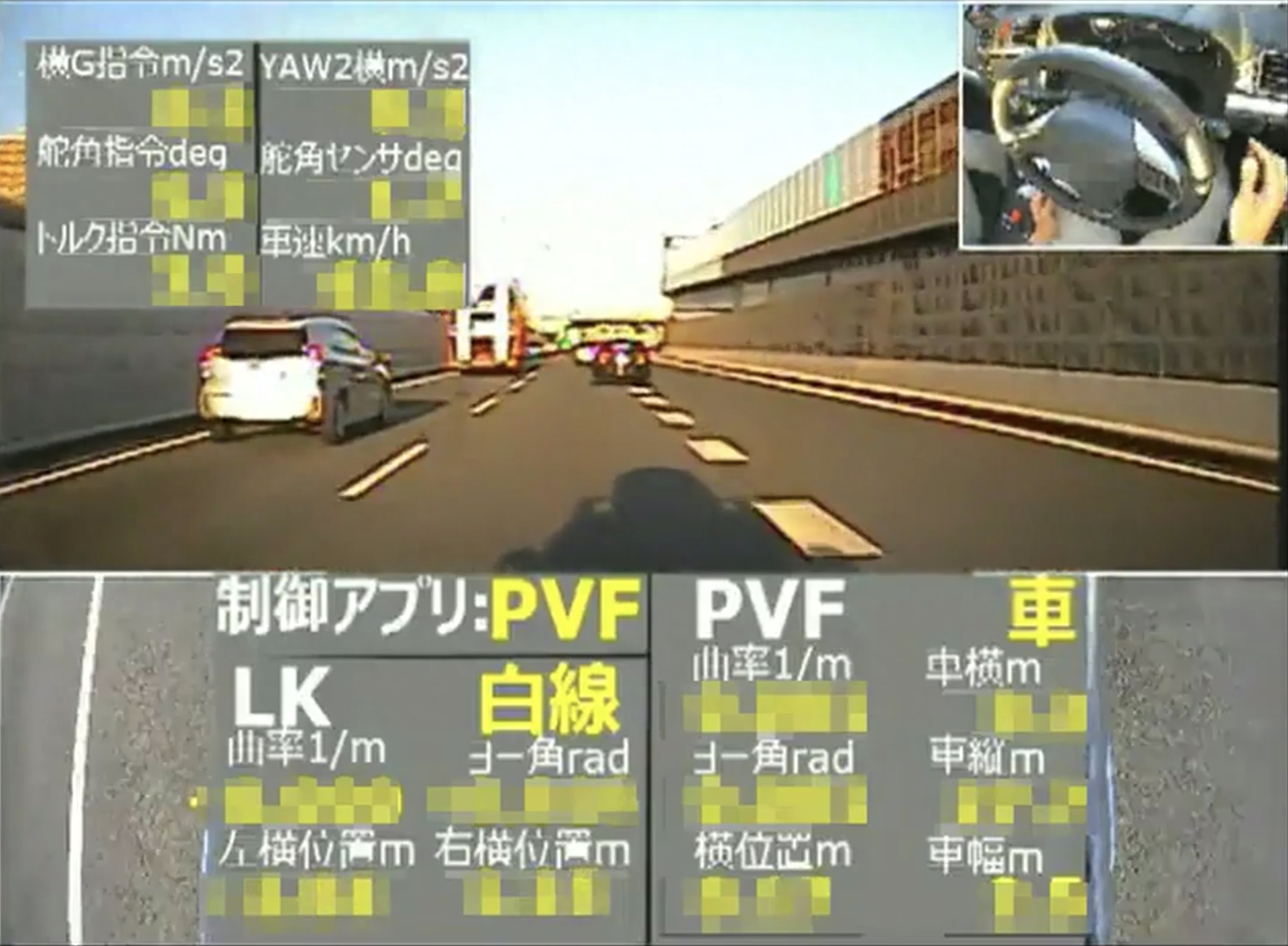
传送门:https://keras.io/

Keras是一个基于Python的开源软件库,对初学者来说特别易用,它允许快速构建神经网络模型,是一个模块化的AI工具箱,计算机视觉工程师可以利用它来快速组装应用、训练模型。Keras的底层框架使用TensorFlow,并且拥有强大的社区支持,因此用户众多。可以使用Keras实现的内容例如:
- 图像分割和分类
- 手写识别
- 三维图像分类
- 语义图像聚类

传送门:https://developer.nvidia.com/
CUDA是计算统一设备架构的首字母缩写,而NVIDIA CUDA-X是CUDA的更新版本。
NVIDIA CUDA-X是一个GPU加速库和工具的集合,可以开始使用新的应用程序或GPA加速。它包含数学库、并行算法库、图像和视频库、通信库和深度学习库,可用于各种任务,例如:人脸识别、图像处理、3D图形渲染等。它兼容大多数操作系统,并且支持许多主流AI编程语言,如:C、C++、Python、Fortran、MATLAB等。
传送门:https://developer.nvidia.com/npp
CUDA(Compute Unified Device Architecture的缩写)是NVIDIA开发的并行计算平台和应用程序编程接口(API)模型。它允许开发人员使用GPU(图形处理单元)的强大功能来加快处理密集型应用程序的速度。
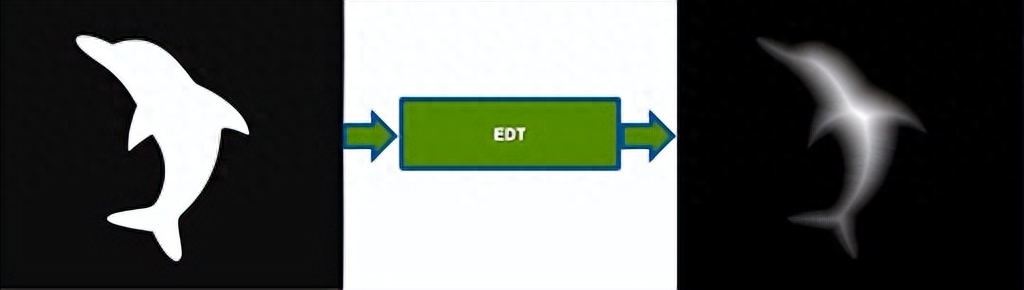
该工具包包含NVIDIA Performance Primitives(NPP)库,可为多个领域(包括计算机视觉)提供GPU加速的图像、视频处理和信号处理功能。此外,CUDA架构可用于各种开发任务,例如:人脸识别、图像处理、3D图形渲染等。它支持各种编程语言,包括C、C++、Python、Fortran或MATLAB,并且还与大多数操作系统兼容。
Github:https://github.com/pytorch/pytorch
 PyTorch 官网
PyTorch 官网
PyTorch是一个Python的开源机器学习框架,主要由Facebook的AI研究小组开发。在构建复杂体系结构时具有很大的灵活性。可以用于机器视觉方面开发图像评估模型、图像分割、图像分类等。
PyTorch是一个基于Torch的使用Python编程语言的开源机器学习框架。Torch 是一个开源的用Lua脚本语言编写的机器学习库,用于创建深度神经网络。
PyTorch 支持多种不同的数学运算,简化了人工神经网络模型的创建。PyTorch 主要应用于数据科学家用于研究和人工智能应用,如计算机视觉和自然语言处理等应用。PyTorch 遵循 modified BSD 许可协议。
2016年,PyTorch 由 Meta AI Research 首次发布,现在已成为Linux基金会的一部分。许多深度学习软件都是在PyTorch基础之上构建的,包括Tesla 的 Autopilot、Uber 的 Pyro、HuggingFace 的 Transformers、PyTorch Lightning、和 Catalyst。
PyTorch提供了两个高级特性:一是类似于NumPy的张量计算,可通过GPU实现强大的加速;二是基于带自动微分系统的深度神经网络。支持ONNX与其他程序库交换模型。
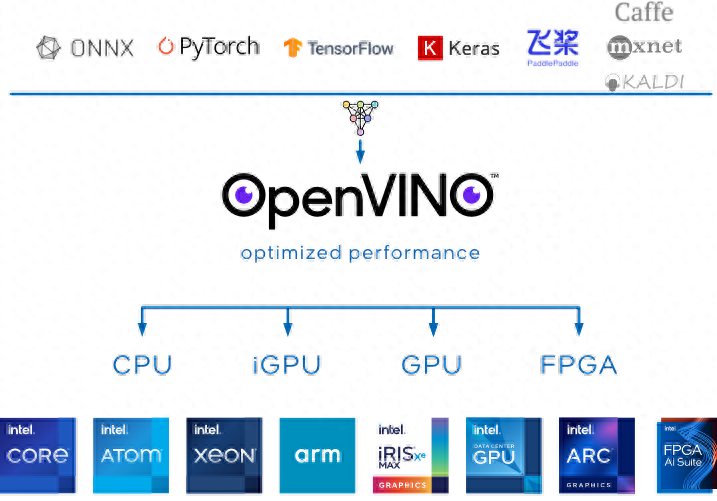
Github:https://github.com/openvinotoolkit/openvino
OpenVINO 官网
OpenVINO是Open Visual Inference and Neural Network Optimization的缩写。它是一套非常全面的计算机视觉工具。它由英特尔开发,是一个可以免费使用的跨平台框架,具有多种视觉处理能力,包括:
- 对象检测
- 人脸识别
- 图像彩色化
- 运动识别
Github:https://github.com/BVLC/caffe
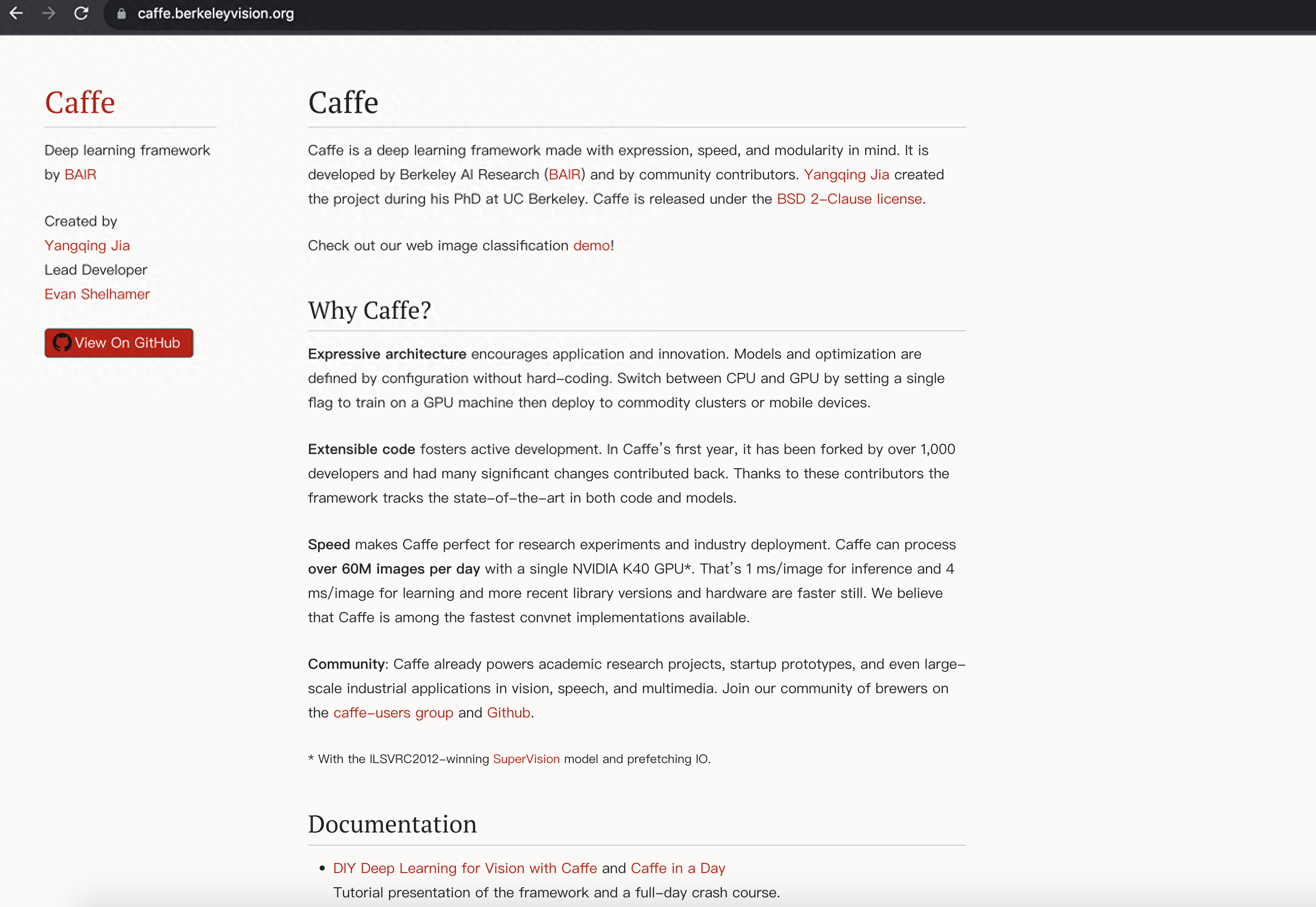
Caffe 官网
CAFFE是Convolutional Architecture for Fast Feature Embedding的缩写。是一个易于使用的开源深度学习和计算机视觉框架,由加州大学伯克利分校开发。
它使用C++编写,支持多种开发语言,支持多种用于实现图像分类和图像分割的深度学习架构。Caffe可以用于视觉、语音和多媒体领域的应用,支持图像分割、分类等模型开发。
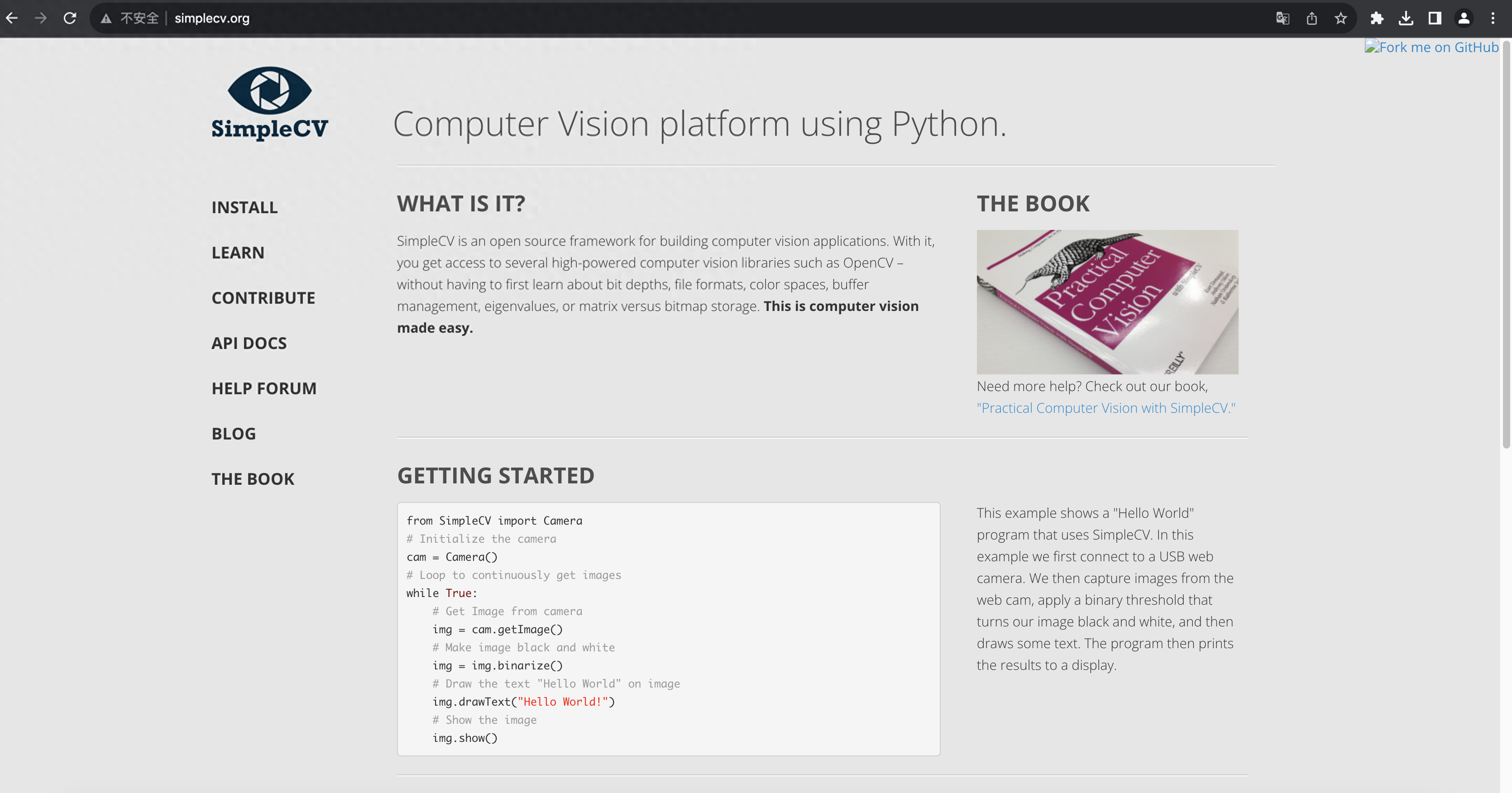 SimpleCV 官网
SimpleCV 官网
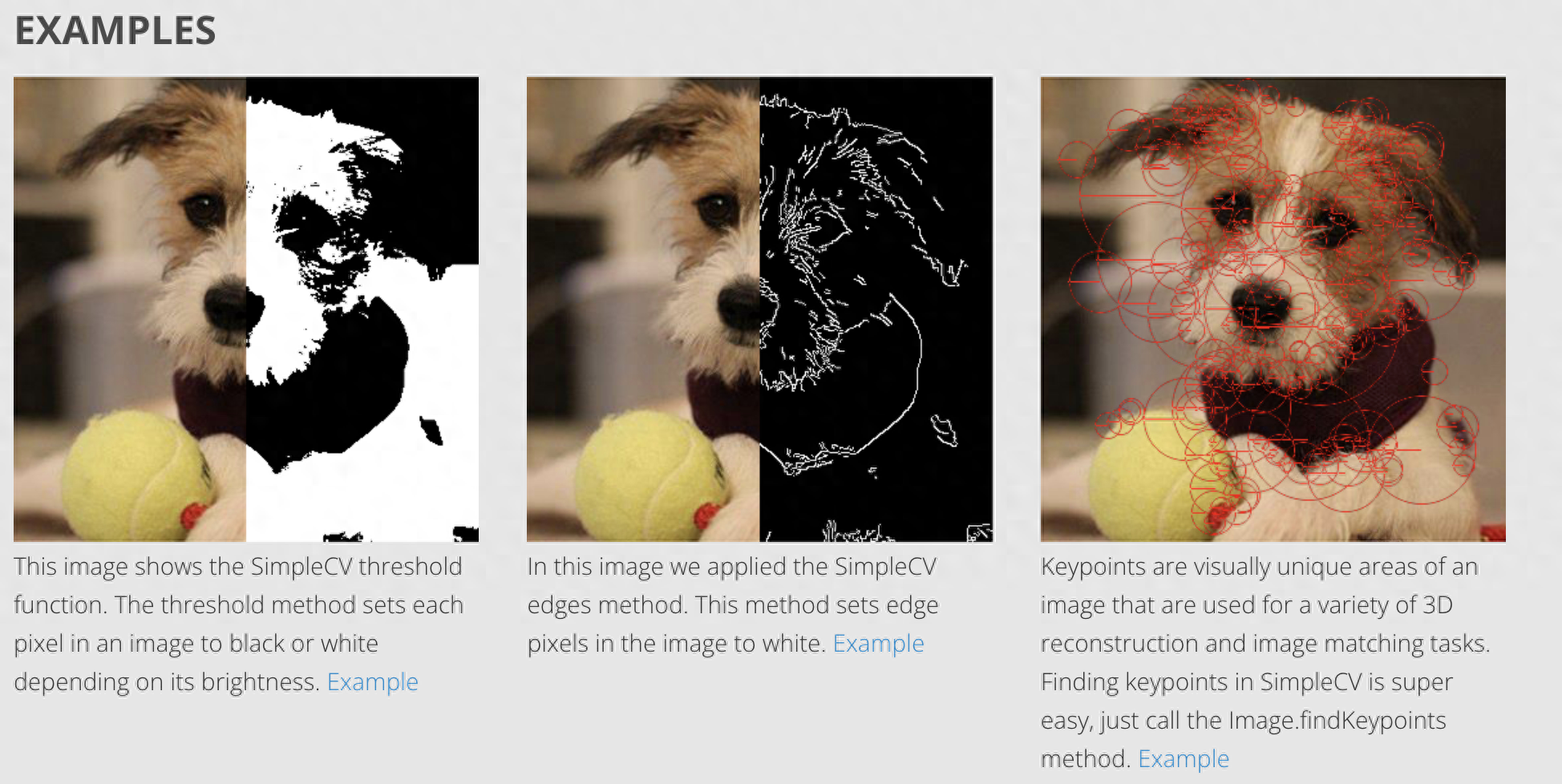
SimpleCV是一个开源免费的机器视觉框架。通这个框架,可以轻松访问OpenCV等几个高性能的计算机视觉库,而无需深入了解位深度、颜色空间、缓冲区管理或文件格式等复杂概念。
Github:https://github.com/facebookresearch/detectron2
 Detectron2 官网
Detectron2 官网
Detecrton 2是由Facebook AI Research(FAIR)开发的基于PyTorch的模对象检测库。
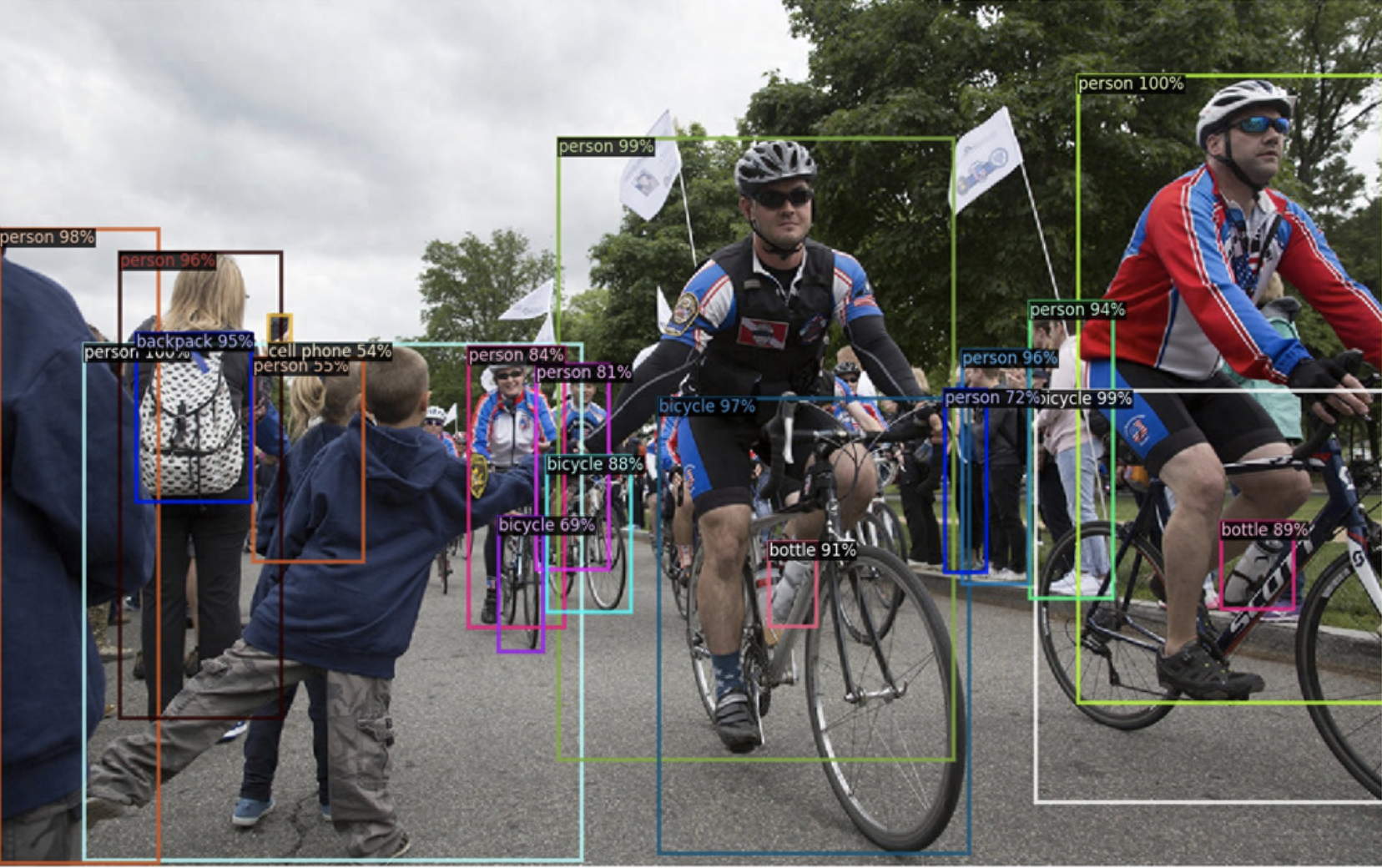
Detectron 2是Detection的升级版;包括:Faster R-CNN、Mask R-CNN、RetinaNet、DensePose、Cascade R-CNN、Panoptic FPN和TensorMask等模型。Detecrton 2的功能包括:密集位姿预测、全景图像分割、联合分割、对象检测等。
 Detectron2 应用场景
Detectron2 应用场景
最后
一台电脑,一个键盘,尽情挥洒智慧的人生;