2020年发布的N-BEATS、2022年发布的N-HiTS和2023年3月发布的PatchTST开始。N-BEATS和N-HiTS依赖于多层感知器架构,而PatchTST利用了Transformer架构。
2023年4月发表了一个新的模型,它在时间序列分析的多个任务中实现了最先进的结果,如预测、imputation、分类和异常检测:TimesNet。
TimesNet由Wu、Hu、Liu等人在他们的论文《TimesNet: Temporal 2D-Variation Modeling For General Time Series Analysis》中提出。
与以前的模型不同,它使用基于cnn的架构来跨不同的任务获得最先进的结果,使其成为时间序列分析的基础模型的绝佳候选。
在本文中,我们将探讨TimesNet的架构和内部工作原理。然后将该模型应用于预测任务,与N-BEATS和N-HiTS进行对比。
TimesNet
TimesNet背后的动机来自于许多现实生活中的时间序列表现出多周期性的认识。这意味着变化发生在不同的时期。
例如,室外温度有日周期和年周期。通常,白天比晚上热,夏天比冬天热。这些多个时期相互重叠和相互作用,使得很难单独分离和建模。
周期内变化是指温度在一天内的变化,周期间变化是指温度每天或每年的变化。所以TimesNet的作者提出在二维空间中重塑序列,以模拟周期内和周期间的变化。
TimesNet的架构
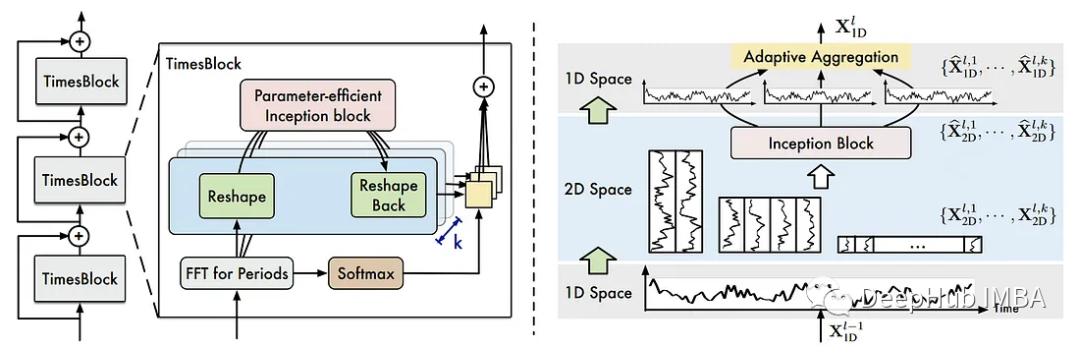
从上图中,我们可以看到TimesNet是多个带有跳过连接的TimesBlock的堆栈。
在每个TimesBlock中,首先通过快速傅立叶变换(FTT)来找到数据中的不同周期。然后被重塑为一个2D向量,并发送到一个Inception块中,在那里它学习并预测该系列的2D表示。然后使用自适应聚合将该深度表示重塑回一维向量。
捕捉多周期性
为了捕获时间序列中多个时期的变化,作者建议将一维序列转换为二维空间,同时模拟周期内和周期间的变化。
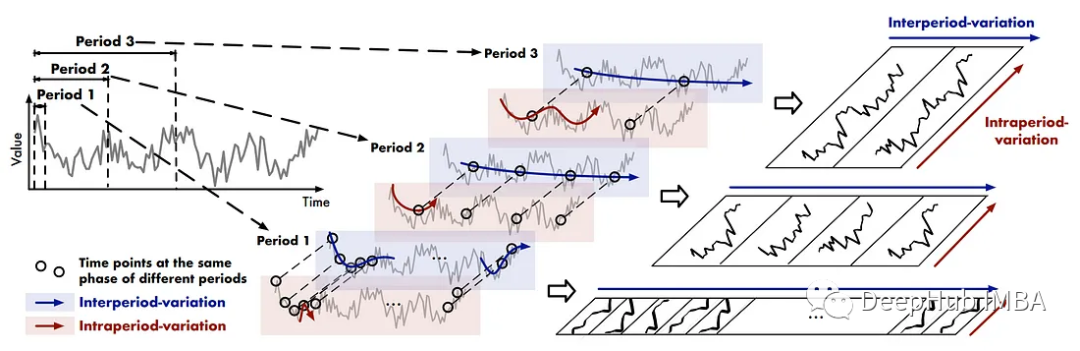
在上图中,我们可以看到模型是如何表示二维空间中的变化的。在红色矩形内可以看到周期内的变化,也就是数据在一个周期内的变化。然后蓝色矩形包含周期间变化,这是数据如何从一个时期到另一个时期的变化。
为了更好地理解这一点,假设我们有以周为周期的每日数据。周期间变化是指数据在周一、周二、周三等期间的变化情况。
那么,周期间变化就是数据从第1周的星期一到第2周的星期一,从第1周的星期二到第2周的星期二的变化。换句话说,它是同一阶段的数据在不同时期的变化。
然后,这些变化在二维空间中表示,其中周期间变化是垂直的,周期内变化是水平的。这使得模型能够更好地学习数据变化的表示。
一维矢量表示的是相邻点之间的变化,而二维矢量表示的是相邻点和相邻周期之间的变化,给出了一个更完整的图像。
原理看着很简单,但是还有一个最重要的问题:如何找到周期?
确定周期性
为了识别时间序列中的多个周期,该模型应用了快速傅里叶变换(FTT)。
这是一个数学运算,将信号转换成频率和幅度的函数。
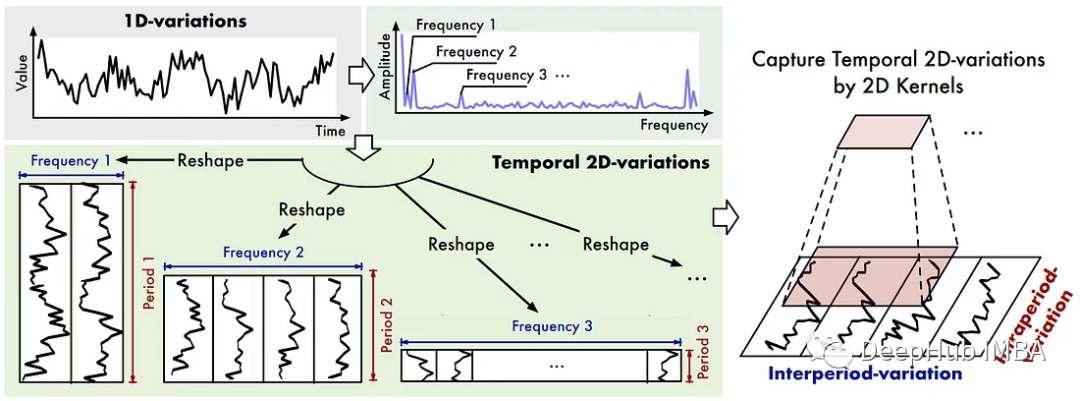
在上图中,作者说明了金融交易税是如何应用的。一旦我们有了每个周期的频率和幅度,幅度最大的就被认为是最相关的。
例如,下面是对eth1数据集执行FTT的结果。
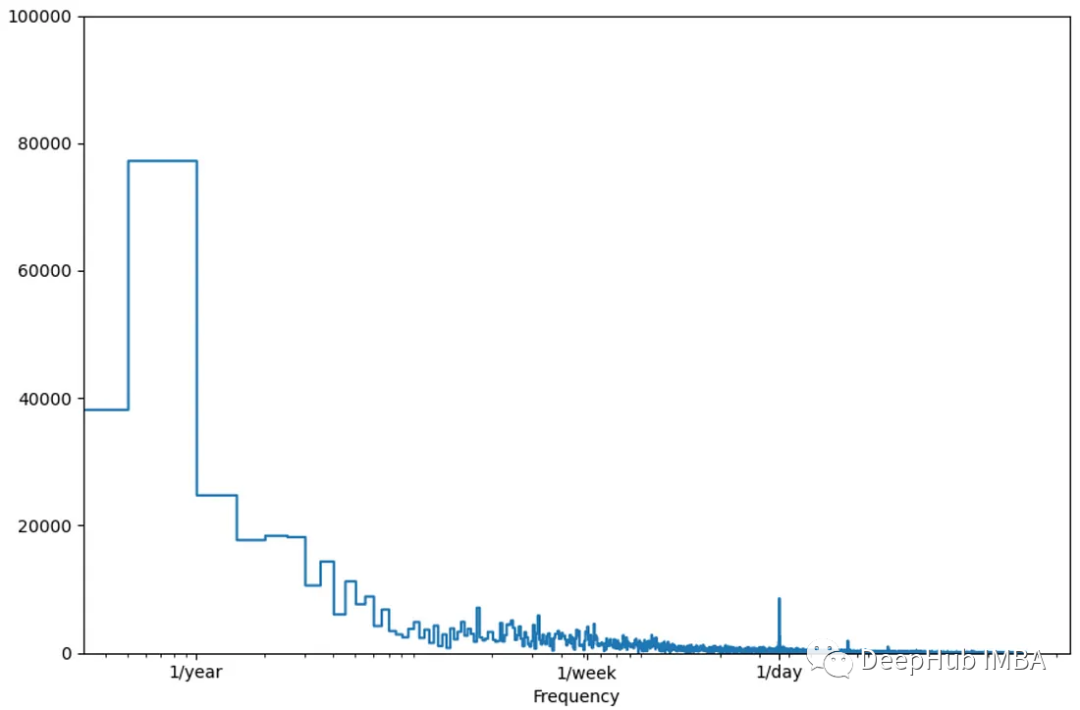
在上图中,快速傅里叶变换能够快速识别数据中的日周期和年周期,因为我们在这些周期中看到更高的振幅峰值。
一旦应用了FTT,用户可以设置一个参数k来选择top-k最重要的周期,这些周期是振幅最大的周期。
然后,TimesNet为每个周期创建2D向量,并将这些向量发送到2D内核以捕获时间变化。
TimesBlock
一旦序列进行了傅里叶变换,并为前k个周期创建了二维张量,数据就被发送到Inception 块,如下图所示。
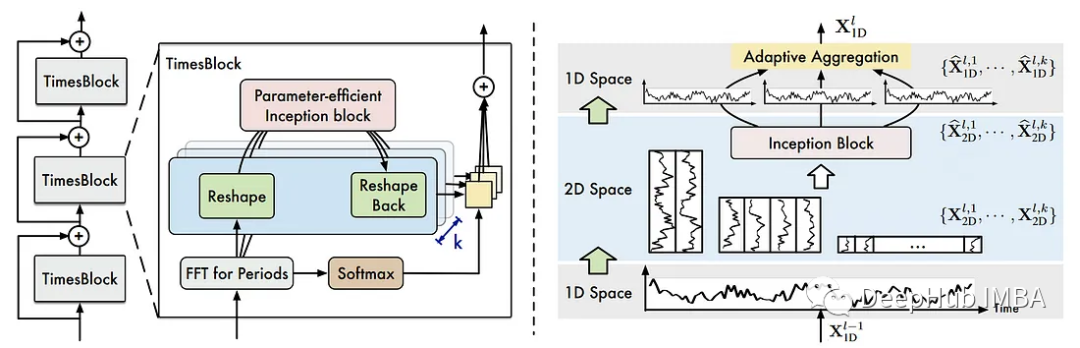
TimesBlock是最主要的模型组件:Inception模块是2015年发布的计算机视觉模型GoogLeNet的构建块。
Inception模块的主要思想是通过保持数据稀疏来有效地表示数据。这样就可以在技术上增加神经网络的大小,同时保持其计算效率。
这是通过执行各种卷积和池化操作来实现的,然后将所有内容连接起来。在TimesNet的上下文中,这就是Inception模块的样子。
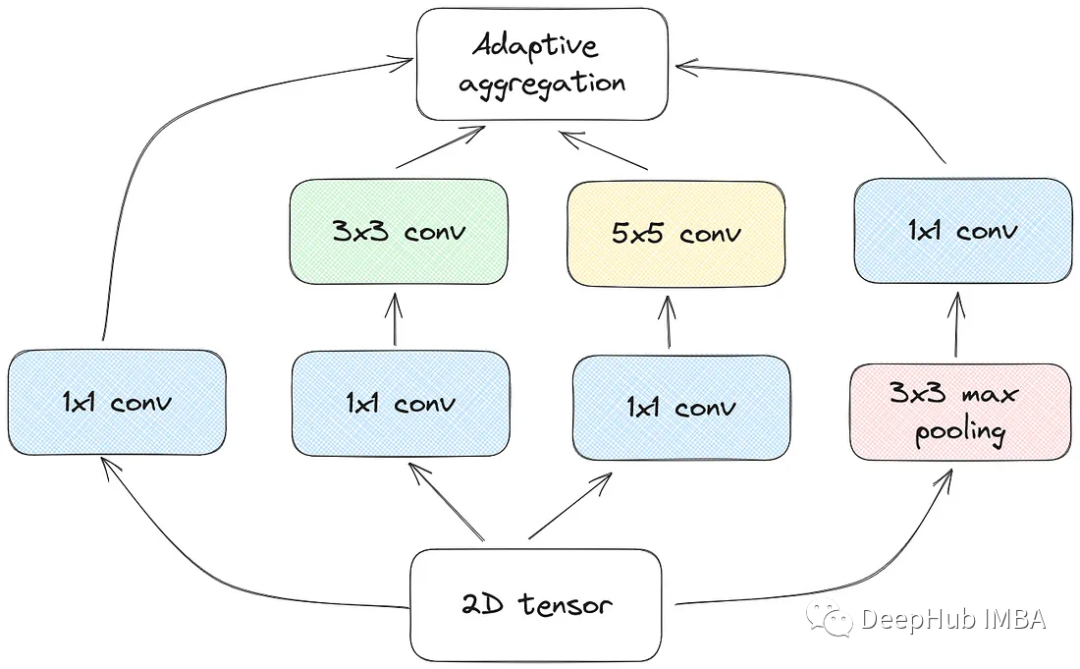
什么作者选择视觉模型来处理时间序列数据。
一个简单的答案是,视觉模型特别擅长解析2D数据,比如图像。另一个好处是可以在TimesNet可以更其他的视觉主干。
自适应聚合
要执行聚合,必须首先将2D表示重塑为1D向量。
使用自适应聚合的原因是不同的周期有不同的振幅,这表明了它们的重要性。
这就是为什么FTT的输出也被发送到softmax层,这样可以使用每个周期的相对重要性进行聚合。
聚合的数据是单个TimesBlock的输出。然后将多个TimesBlock与残差连接叠加创建TimesNet模型。
TimesNet预测
现在让我们将TimesNet模型应用于预测任务,并将其性能与N-BEATS和N-HiTS进行比较。
我们使用了知识共享署名许可下发布的Etth1数据集。这是文献中广泛使用的时间序列预测基准。它跟踪每小时的变压器油温,这反映了设备的状况。
导入库并读取数据,这里我们使用Nixtla提供的NeuralForecast实现。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from neuralforecast.core import NeuralForecast
from neuralforecast.models import NHITS, NBEATS, TimesNet
from neuralforecast.losses.numpy import mae, mse读取CSV文件。
df = pd.read_csv('data/etth1.csv')
df['ds'] = pd.to_datetime(df['ds'])
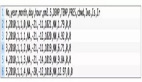
df.head()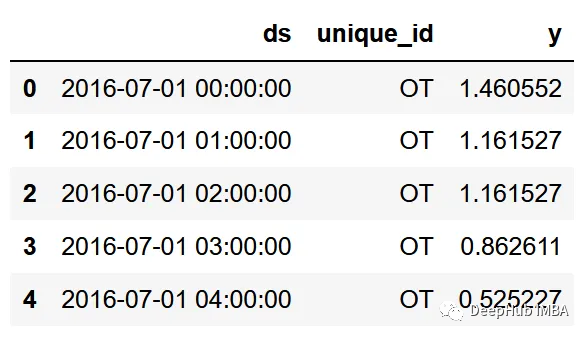
在上图中,请注意数据集已经具有NeuralForecast所期望的格式。包需要三列:
- ds:日期列
- id列:unique_id
- y值列
然后,我们先看看数据
fig, ax = plt.subplots()
ax.plot(df['y'])
ax.set_xlabel('Time')
ax.set_ylabel('Oil temperature')
fig.autofmt_xdate()
plt.tight_layout()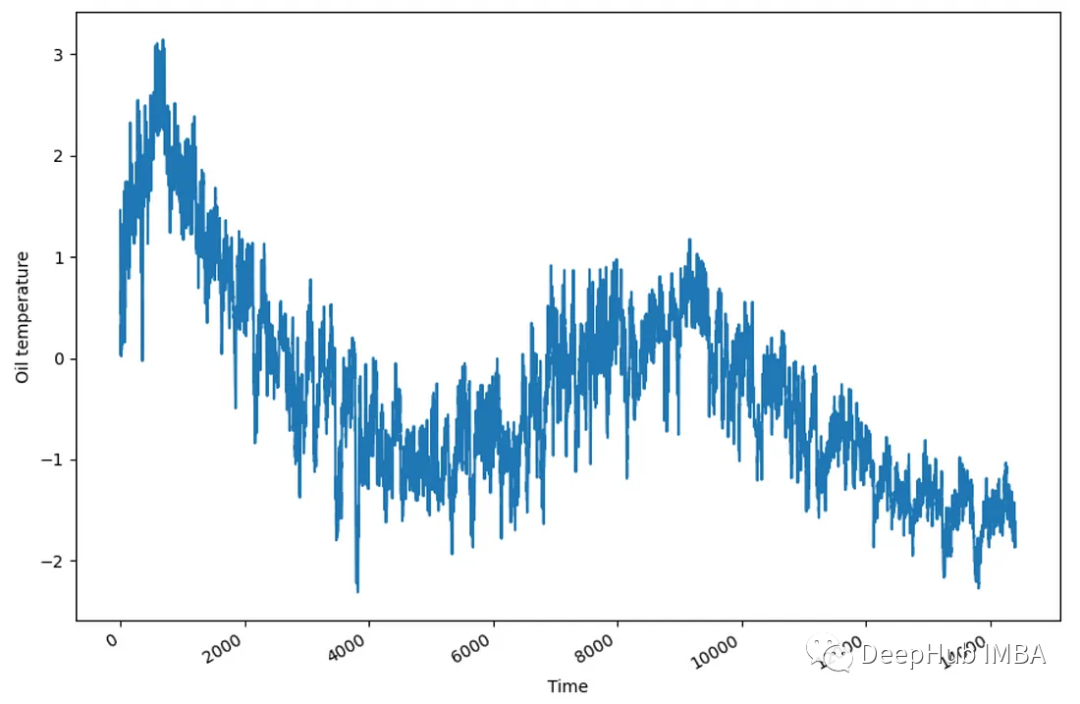
现在我们开始预测,使用96小时的预测长度,这是文献中长期预测的常见长度。
我们还保留了两个96个时间步长的窗口来评估我们的模型。
我们定义一个我们想要用来执行预测任务的模型列表。这里将使用N-BEATS, N-HiTS和TimesNet。
保留所有模型的默认参数,并将最大epoch数限制为50。请注意,默认情况下,TimesNet将选择数据中最重要的前5个轮次。
horizon = 96
models = [NHITS(h=horizon,
input_size=2*horizon,
max_steps=50),
NBEATS(h=horizon,
input_size=2*horizon,
max_steps=50),
TimesNet(h=horizon,
input_size=2*horizon,
max_steps=50)]下一步是用模型列表和数据频率(每小时一次)实例化NeuralForecasts对象。
nf = NeuralForecast(models=models, freq='H')然后运行交叉验证,这样就有了数据集的预测值和实际值。可以评估每个模型的性能。
preds_df = nf.cross_validation(df=df, step_size=horizon, n_windows=2)
我们可以看到实际值,以及来自我们指定的每个模型的预测。这样可以很容易地将预测与实际值相比较。
fig, ax = plt.subplots()
ax.plot(preds_df['y'], label='actual')
ax.plot(preds_df['NHITS'], label='N-HITS', ls='--')
ax.plot(preds_df['NBEATS'], label='N-BEATS', ls=':')
ax.plot(preds_df['TimesNet'], label='TimesNet', ls='-.')
ax.legend(loc='best')
ax.set_xlabel('Time steps')
ax.set_ylabel('Oil temperature')
fig.autofmt_xdate()
plt.tight_layout()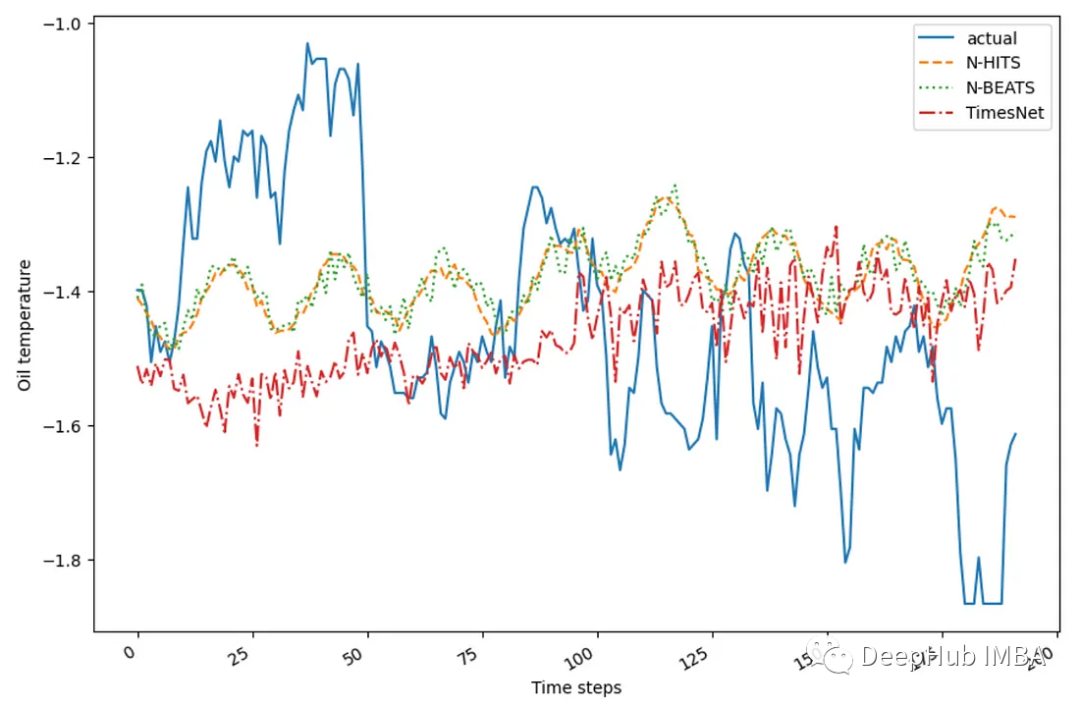
在上图中,似乎所有的模型都无法预测测试集中观察到的油温下降。但是可以看到N-BEATS和N-HiTS已经捕捉到了一些在TimesNet的预测中没有观察到的周期性模式。
但是最终还需要通过计算MSE和MAE来评估模型,以确定哪个模型是最好的。
data = {'N-HiTS': [mae(preds_df['NHITS'], preds_df['y']), mse(preds_df['NHITS'], preds_df['y'])],
'N-BEATS': [mae(preds_df['NBEATS'], preds_df['y']), mse(preds_df['NBEATS'], preds_df['y'])],
'TimesNet': [mae(preds_df['TimesNet'], preds_df['y']), mse(preds_df['TimesNet'], preds_df['y'])]}
metrics_df = pd.DataFrame(data=data)
metrics_df.index = ['mae', 'mse']
metrics_df.style.highlight_min(color='lightgreen', axis=1)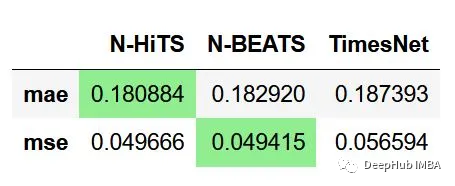
从上图可以看出,N-HiTS获得最低的MAE,而N-BEATS获得最低的MSE。MAE的差异为0.002,MSE的差异为0.00025。由于MSE的差异非常小,特别是考虑到误差是平方的,所以我认为N-HiTS是这项任务的首选模型。
总结
本文并不是要证明TimesNet有多好,因为不同的模型可能适应不同的任务,并且我们也没有进行超参数优化,我们介绍TimesNet的主要目的是他的思路,它不仅将cnn的架构引入了时间序列预测,并且还提供了一种周期性判别的新的思路,这些都是值得我们学习的。
一如既往,每个预测问题都需要一个独特的方法和一个特定的模型,所以你可以在你的模型列表中增加一个TimesNet了。
本文代码:https://github.com/marcopeix/time-series-analysis
TimesNet,论文地址:https://browse.arxiv.org/pdf/2210.02186.pdf