本文经自动驾驶之心公众号授权转载,转载请联系出处。
笔者的个人理解
在过去的十年里,自动驾驶在学术界和工业界都得到了快速发展。然而其有限的可解释性仍然是一个悬而未决的重大问题,严重阻碍了自动驾驶的发展进程。以前使用小语言模型的方法由于缺乏灵活性、泛化能力和鲁棒性而未能解决这个问题。近两年随着ChatGPT的出现,多模态大型语言模型(LLM)因其通过文本处理和推理非文本数据(如图像和视频)的能力而受到研究界的极大关注。因此一些工作开始尝试将自动驾驶和大语言模型结合起来,今天汽车人为大家分享的DriveGPT4就是利用LLM的可解释实现的端到端自动驾驶系统。DriveGPT4能够解释车辆动作并提供相应的推理,以及回答用户提出的各种问题以增强交互。此外,DriveGPT4以端到端的方式预测车辆的运动控制。这些功能源于专门为无人驾驶设计的定制视觉指令调整数据集。DriveGPT4也是世界首个专注于可解释的端到端自动驾驶的工作。当与传统方法和视频理解LLM一起在多个任务上进行评估时,DriveGPT4表现出SOTA的定性和定量性能。
项目主页:https://tonyxuqaq.github.io/projects/DriveGPT4/
总结来说,DriveGPT4的主要贡献如下:
- 为可解释的自动驾驶开发了一个新的视觉指令调整数据集。
- 提出了一个全新的多模态LLM—DriveGPT4。DriveGPT4对创建的数据集进行了微调,可以处理多模态输入数据,并提供文本输出和预测的控制信号。
- 在多个任务上评估所有方法,DriveGPT4的性能优于所有基线。此外,DriveGPT4可以通过零样本泛化处理看不见的场景。
通过ChatGPT生成指令数据
具体来说,DriveGPT4训练使用的视频和标签是从BDD-X数据集中收集的,该数据集包含约20000个样本,包括16803个用于训练的clip和2123个用于测试的clip。每个clip采样8个图像。此外,它还提供每帧的控制信号数据(例如,车辆速度和车辆转弯角度)。BDD-X为每个视频clip提供了关于车辆行动描述和行动理由的文本注释,如图1所示。在以前的工作中,ADAPT训练caption网络来预测描述和理由。但是,提供的描述和标签是固定的和刚性的。如果人类用户希望了解更多关于车辆的信息并询问日常问题,那么过去的工作可能会功亏一篑。因此,仅BDD-X不足以满足可解释自动驾驶的要求。

由ChatGPT/GPT4生成的指令调整数据已被证明在自然语言处理、图像理解和视频理解中对性能增强是有效的。ChatGPT/GPT4可以访问更高级别的信息(例如,图像标记的captions、GT目标边界框),并可以用于提示生成对话、描述和推理。目前,还没有为自动驾驶目的定制的视觉指令跟随数据集。因此,我们在ChatGPT的辅助下,基于BDD-X创建了自己的数据集。
修正问题回答。由于BDD-X为每个视频clip提供了车辆动作描述、动作理由和控制信号序列标签,因此我们直接使用ChatGPT基于这些标签生成一组三轮问答(QA)。首先,我们创建三个问题集:Qa、Qj和Qc。
- Qa包含相当于“这辆车目前的行动是什么?”的问题。
- Qj包含相当于“为什么车辆会有这种行为?”的问题。
- Qc包含相当于“预测下一帧中车辆的速度和转弯角度”的问题。
LLM可以同时学习预测和解释车辆动作。但是如前所述,这些QA具有固定和严格的格式。由于缺乏多样性,仅对这些QA进行训练会降低LLM的推理能力,使其无法回答其他形式的问题。
ChatGPT生成的对话。为了解决上述问题,ChatGPT作为一名教师以生成更多关于自车的对话。提示通常遵循LLaVA中使用的提示设计。为了使ChatGPT能够“看到”视频,YOLOv8用于检测视频每帧中常见的目标(例如,车辆、行人)。所获得的目标框作为更高级别的信息馈送到ChatGPT。除了目标检测结果外,ChatGPT还可以访问视频clip的真实控制信号序列和captions。基于这些特权信息,ChatGPT会被提示生成关于自车、红绿灯、转弯方向、变道、周围物体、物体之间的空间关系等的多轮和类型的对话。详细提示见附录。
最后,我们收集了28K的视频文本指令如下样本,包括由ChatGPT生成的16K固定QA和12K对话。生成的示例如表1所示。

DriveGPT4
模型架构
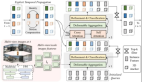
DriveGPT4是一个多功能多模态的LLM,能够处理各种输入类型,包括视频、文本和控制信号。视频被均匀地采样到固定数量的图像中,并使用基于Valley的视频标记器将视频帧转换为文本域标记。从RT-2中汲取灵感,文本和控制信号使用相同的文本标记器,这意味着控制信号可以被解释为一种语言,并被LLM有效地理解和处理。所有生成的令牌都被连接起来并输入到LLM中。本文采用LLaMA 2作为LLM。在生成预测的令牌后,de-tokenizer对其进行解码以恢复人类语言。解码文本包含固定格式的预测信号。DriveGPT4的整体架构如图2所示。
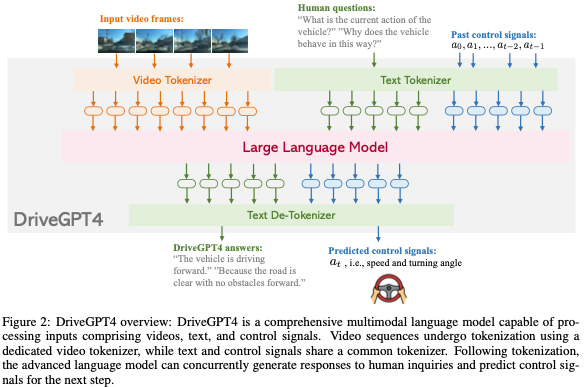
视频标记器。视频标记器基于Valley。对于每个视频帧,使用预训练的CLIP视觉编码器来提取其特征。的第一个通道表示的全局特征,而其他256个通道响应的patch特征。为了简洁地表示,的全局特征被称为,而的局部patch特征被表示为。然后,整个视频的时间视觉特征可以表示为:

同时,整个视频的空间视觉特征由下式给出:
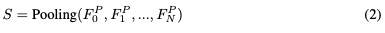
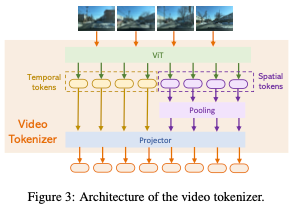
最终,使用projector将视频的时间特征T和空间特征S都投影到文本域中。tokenizer的详细结构如图3所示。
文本和控制信号。受RT-2的启发,控制信号的处理类似于文本,因为它们属于同一域空间。控制信号直接嵌入文本中进行提示,并使用默认的LLaMA标记器。在本研究中,ego车辆的速度v和转向角∆被视为目标控制信号。转向角度表示当前帧和初始帧之间的相对角度。在获得预测的令牌后,LLaMA的tokenizer用于将令牌解码回文本。DriveGPT4预测后续步骤的控制信号,即(vN+1,∆N+1)。预测的控制信号使用固定格式嵌入输出文本中,通过简单的后处理可以轻松提取。表2中给出了DriveGPT4的输入和输出示例。

训练
与以往LLM相关研究一致,DriveGPT4的训练包括两个阶段:(1)预训练阶段,重点是视频文本对齐;以及(2)微调阶段,旨在训练LLM回答与端到端自动驾驶相关的问题。
预训练。与LLaVA和Valley一致,该模型对来自CC3M数据集的593K个图像-文本对和来自WebVid-10M数据集的100K个视频-文本对进行了预训练。预训练图像和视频包含各种主题,并不是专门为自动驾驶应用设计的。在此阶段,CLIP编码器和LLM权重保持固定。只有视频标记器被训练为将视频与文本对齐。
微调。在这个阶段,DriveGPT4中的LLM与可解释的端到端自动驾驶的视觉标记器一起进行训练。为了使DriveGPT4能够理解和处理主要知识,它使用前文中生成的28K视频文本指令进行训练。为了保持DriveGPT4回答日常问题的能力,还使用了LLaVA生成的80K指令跟踪数据。因此,在微调阶段,DriveGPT4使用28K视频文本指令跟随数据以及80K图像文本指令跟随的数据进行训练。前者确保了DriveGPT4可以应用于可互操作的端到端自动驾驶,而后者增强了数据灵活性,有助于保持DriveGPT4的通用问答能力。
实验
可解释的自动驾驶
在本节评估了DriveGPT4及其解释生成的基线,包括车辆行动描述、行动理由和有关车辆状态的其他问题。ADAPT是最先进的基线工作。最近的多模式视频理解LLM也被考虑进行比较。ADAPT采用32帧视频作为输入,而其他方法则采用8帧视频作为输出。
评估指标。为了详细评估这些方法,本文报告了NLP社区中广泛使用的多个指标得分,包括BLEU4、METEOR和CIDEr。然而,这些指标主要衡量单词级别的性能,而没有考虑语义,这可能会导致意想不到的评估结果。鉴于ChatGPT强大的推理能力,它被用来衡量预测质量,并提供更合理的分数。ChatGPT会被提示分配一个介于0和1之间的数字分数,分数越高表示预测精度越高。基于ChatGPT的评估的详细提示见附录。度量比较示例如图4所示。与传统指标相比,Chat-GPT生成的分数为评估提供了更合理、更令人信服的依据。

行动描述和理由。考虑到评估的成本和效率,DriveGPT4在来自BDD-X测试集的500个随机采样的视频clip上进行了测试。目标是尽可能根据给定标签预测车辆行动描述和理由。评估结果显示在表3中。结果表明,与之前最先进的(SOTA)方法ADAPT相比,DriveGPT4实现了卓越的性能,尽管ADAPT使用32帧视频,而DriveGPT4只有8帧视频作为输入。
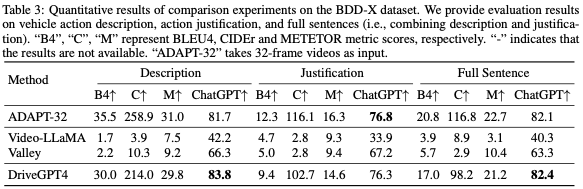
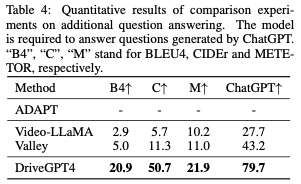
附加问答。上述车辆行动描述和理由具有相对固定的格式。为了进一步评估DriveGPT的可解释能力和灵活性,在第3节中生成了其他问题。BDD-X测试集中的100个随机采样的视频片段用于生成问题。与行动描述和理由相比,这些问题更加多样化和灵活。评价结果如表4所示。ADAPT无法回答除车辆操作说明和理由之外的其他问题。之前的视频了解LLM可以回答这些问题,但他们没有学习到驾驶领域的知识。与所有基线相比,DriveGPT4呈现出优异的结果,展示了其灵活性。
端到端控制
在本节评估了DriveGPT4及其开环控制信号预测的基线,特别关注速度和转向角。所有方法都需要基于顺序输入来预测下一单个帧的控制信号。
评估指标。继之前关于控制信号预测的工作之后,我们使用均方根误差(RMSE)和阈值精度(Aτ)进行评估。τ测量预测误差低于τ的测试样本的比例。为了进行全面比较,我们将τ设置为多个值:{0.1,0.5,1.0,5.0}。
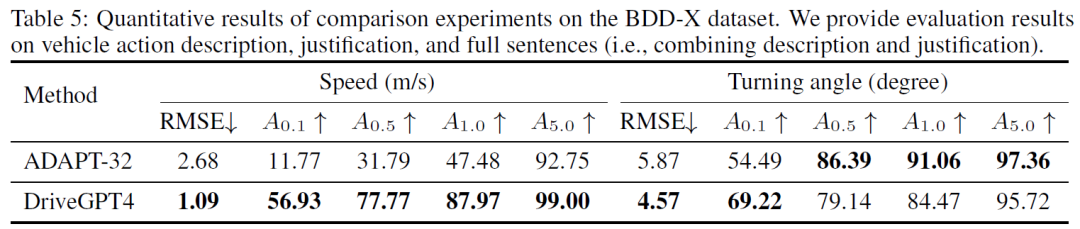
定量结果。在去除带有错误控制信号标签的样本后,BDD-X测试集中的所有其他样本用于控制评估。先前最先进的(SOTA)方法ADAPT和DriveGPT4的定量结果如表5所示。DriveGPT4实现了卓越的控制预测结果。
定性结果
我们进一步提供了多种定性结果,便于直观比较。首先,BDD-X测试集的两个示例如图5所示。然后,为了验证DriveGPT4的泛化能力,我们将DriveGPT4应用于图6中零样本会话生成的NuScenes数据集。最后,我们在视频游戏上尝试DriveGPT4,以进一步测试其泛化能力。一个例子如图7所示。


消融实验
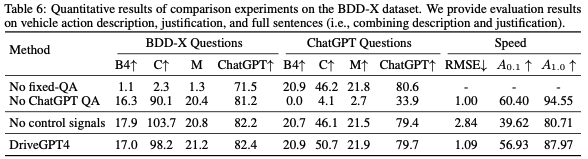
消融实验如表6所示:
结论
本文介绍了DriveGPT4,一个使用多模态LLM的可解释的端到端自动驾驶系统。在ChatGPT的帮助下,开发了一个新的自动驾驶解释数据集,并用于微调DriveGPT4,使其能够响应人类对车辆的提问。DriveGPT4利用输入视频、文本和历史控制信号来生成对问题的文本响应,并预测车辆操作的控制信号。它在各种任务中都优于基线模型,如车辆动作描述、动作论证、一般问题分析和控制信号预测。此外,DriveGPT4通过零样本自适应表现出强大的泛化能力。

原文链接:https://mp.weixin.qq.com/s/tIuMUdTlp1_R-D06kRO8Qg