












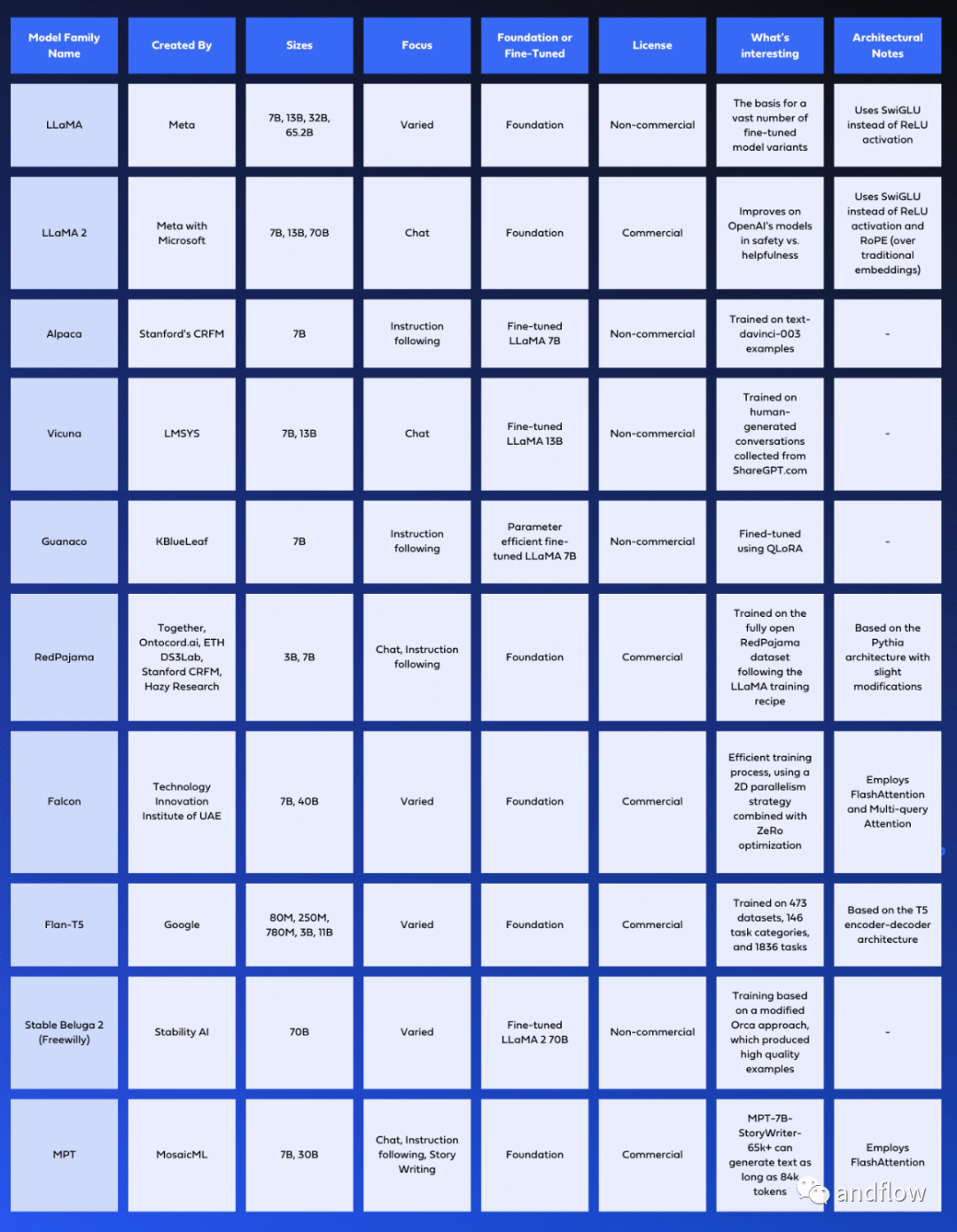
由于大型语言模型(LLM)的崛起,2023年被认为是开源领域的关键一年。下面精心挑选了一些在2023年上半年掀起波澜的最有影响力的模型。这些模型几乎可以与band、GPT-3.5、GPT4、Claude、文心一言等商业大模型竞争。

本文仅针对当前开源大语言模型中一些比较有影响力的项目进行信息收集与分析,但由于2023年大模型的快速发展,有些信息可能已经滞后,读者可进一步跟踪官方网站或者开源社区了解相关进展。
- LLaMA
- LLaMA 2
- Alpaca
- Vicuna
- Guanaco
- RedPajama
- Falcon
- FLAN-T5
- Stable Beluga (formerly ‘FreeWilly’)
- MPT
对于这些模型,下面表格列出了关键信息,例如:架构设计、训练所用的数据库、训练过程、许可协议信息和特征等。
1.LLaMA
LLaMA不仅仅是一个单一的模型;它是一个包含多个大小不一的大型语言模型的集合,参数从70亿到650亿不等。可用的尺寸包括6.7B、13.0B、32.5B和65.2B参数,每种参数在不同的任务中表现出色,而较大的型号通常在更复杂的任务中表现更好。
LLaMA由Meta开发,基于Transformer架构,自2018年以来一直是语言建模的标准架构。它与GPT-3有相似之处,但也有一些架构差异。LLaMA使用SwiGLU激活函数代替ReLU激活函数,使用旋转位置嵌入代替绝对位置嵌入,并且均方根层归一化代替标准层归一化。
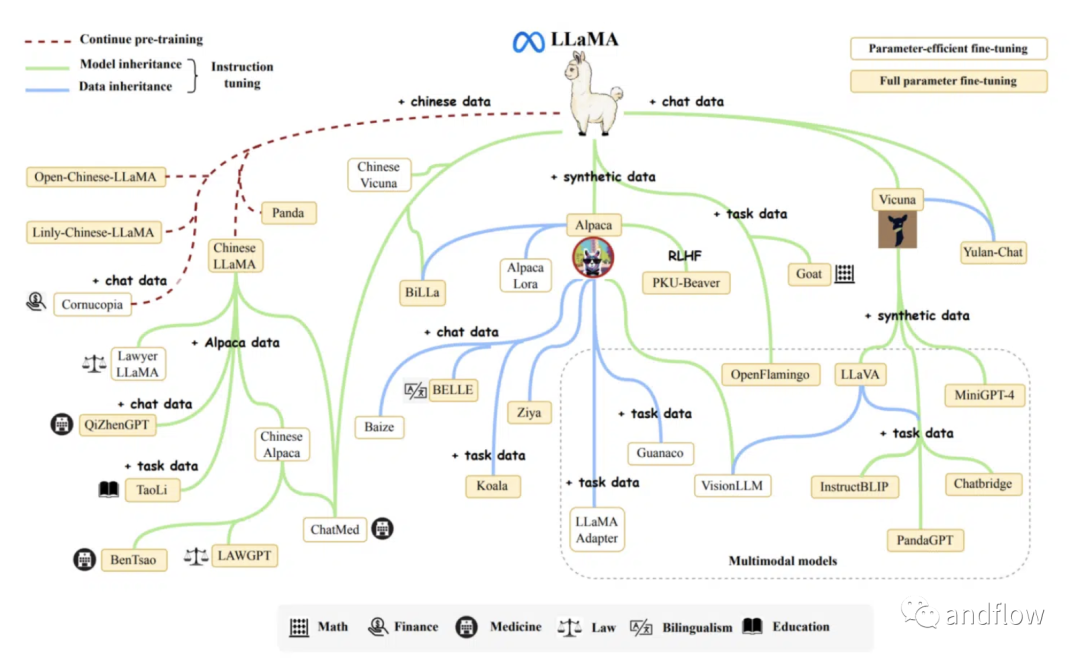
这些模型是在不同的领域训练出来并被开源。研发人员可以将其用于各种应用,包括翻译、问答、文本生成等。LLaMA的多功能性使其能够针对众多任务进行微调,使其成为各种AI项目的理想基础模型。
LLaMA的训练数据非常广泛,模型是在来自公开数据源的1.4万亿个令牌上训练的。这些来源包括CommonCrawl抓取的网页、GitHub的开源代码库、多种语言的维基百科、Gutenberg项目中公共领域书籍以及Stack Exchange网站上的问题和答案。这些模型的研发通过增加训练数据量来提高模型性能。
至于许可协议,Meta在非商业许可下向研究社区发布了LLaMA的模型权重。
为了训练LLaMA模型,开发人员使用了带有余弦学习速率计划的AdamW优化器。最终学习率为最大学习率的10%。此外,模型使用0.1的权重衰减和1.0的梯度剪裁。学习速率和批量大小是根据每个模型的大小定制的,进一步优化其在训练期间的性能。
2.LLaMA 2
LLaMA 2是Meta的LLaMA模型的第二次迭代,专门为对话场景设计.它经过了深度微调,使其与ChatGPT等模型相媲美。LLaMA 2模型有三种大小:70亿、130亿和700亿参数。
LLaMA 2比其前身LLama 1有了重大的进步和改进。它是在一个新的公开可用数据的混合上训练的,预训练语料库增大40%。该模型的上下文长度增加了一倍,并利用了分组查询注意机制。
Llama 2-Chat是一个针对基于聊天的交互而优化的微调版本。LLaMA 2和Llama 2-Chat的开发旨在确保其输出的内容对人类有益且安全。这些自回归模型基于输入生成文本,非常适合助理式聊天和各种自然语言生成任务。 根据基准评估,它比大多数其他模型(包括ChatGPT)更有优秀。
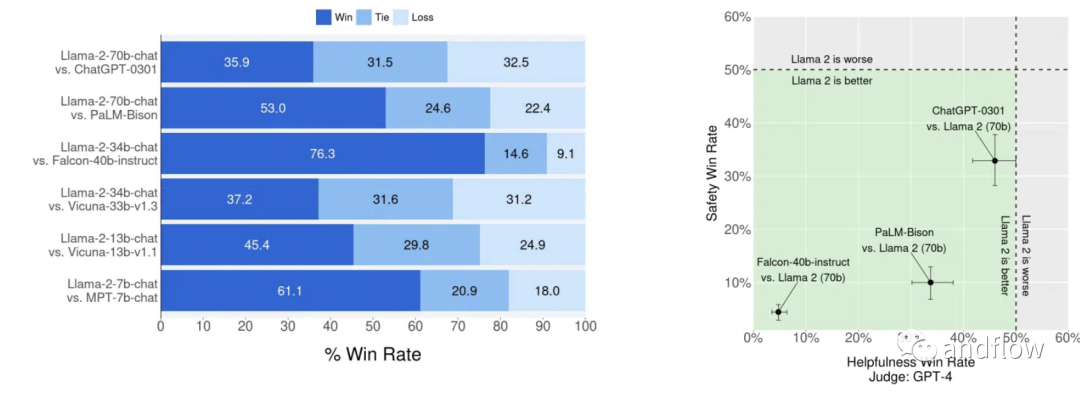
LLaMA 2被授权给研究人员和商业实体,坚持开放的原则。这使得无论是研究、商业应用还是项目开发都能够使用LLaMA 2。
LLaMA 2的训练数据非常广泛,包括来自公开来源的2万亿个代币。微调数据包括公开可用的指令数据集和超过一百万个新的人类注释示例。值得注意的是,预训练数据集和微调数据集都不包括Meta用户数据,从而确保了用户隐私和数据安全。
LLaMA 2采用Llama 1模型的修改版本来增强性能,并使用带有标准Transformer架构的AdamW优化器。它使用与Llama 1相同的标记器,采用字节对编码(BPE)算法,词汇量为32 k个标记。Llama 2-Chat的发展经历了两个阶段。第一个阶段,LLaMA 2使用公开的在线数据。然后,通过监督微调创建了Llama 2-Chat的初始版本。在第二阶段,Llama 2-Chat使用来自人类反馈的强化学习(RLHF)进行了改进。这个过程涉及拒绝采样和邻近策略优化(PPO),以提高其在基于对话的应用程序的性能。
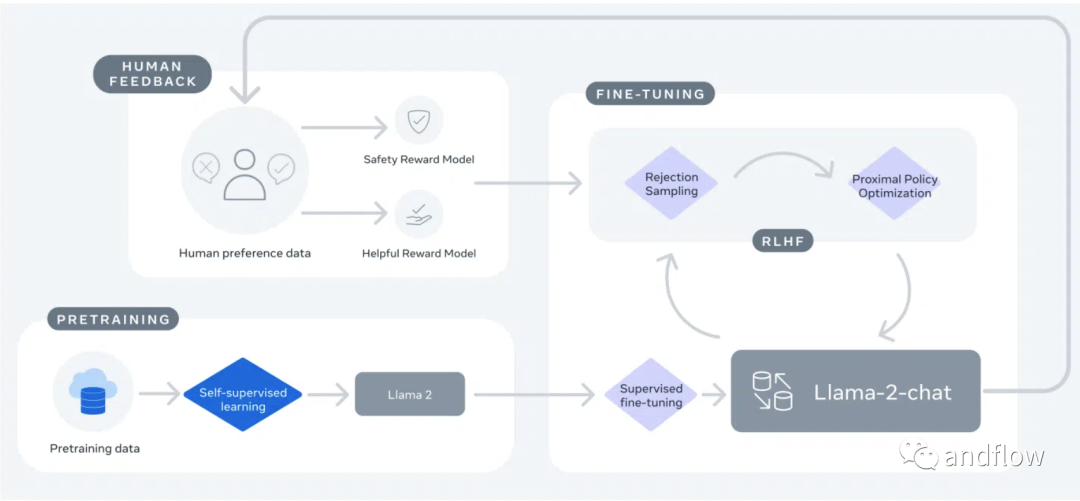
总之,LLaMA 2代表了语言建模方面的重大进步,提供了透明度,可访问性和性能改进,可能会被研究和商业社区广泛接受。
3.Alpaca
Alpaca是由斯坦福大学基础模型研究中心(CRFM)的研究人员开发的它是从Meta的LLaMA 7 B模型中微调的,并使用OpenAI的text-davinci-003作为参考,在52000个指导遵循演示中进行了训练。尽管表现出与OpenAI的text-davinci-003相似的行为,但Alpaca模型更小。
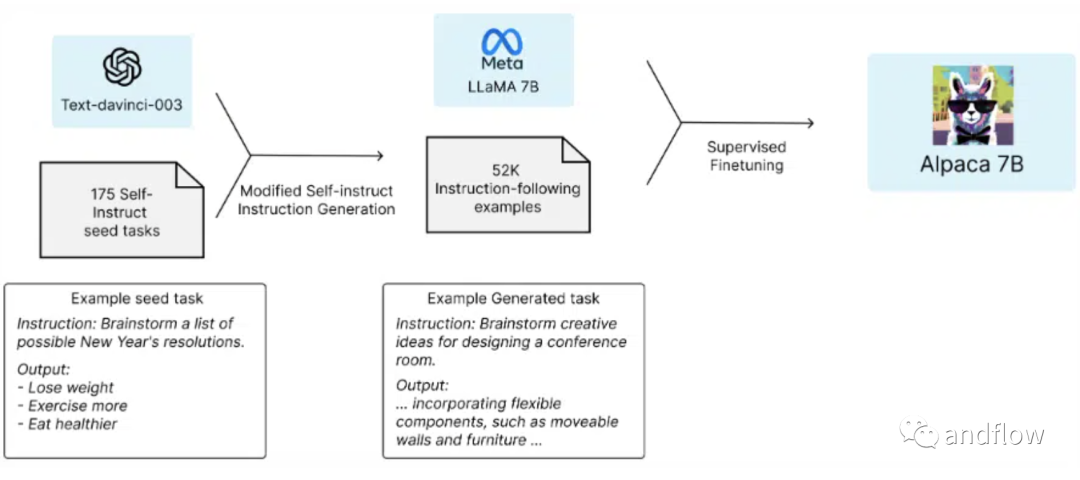
Alpaca模型的突出特点是其强大的指令遵循能力。凭借其微调的设计和许多指令遵循演示的培训,它为需要精确遵守指令的任务提供了可靠和有效的选择。
该模型主要用于学术研究。然而,由于安全措施不足,它还没有准备好用于一般用途。它不可用于商业用途,因为用于训练Alpaca的指令数据基于OpenAI的text-davinci-003,其使用条款禁止开发与OpenAI竞争的模型。
采用Hugging Face的训练框架对Alpaca进行微调,充分利用完全分片数据并行和混合精度训练。使用8台80GB A100对7B LLaMA模型进行微调大约需要3个小时,展示了其效率和快速开发的潜力。
总之,Alpaca是一种专门的、高效的语言模型,适用于需要准确和精确执行的任务。它的开发和使用面向研究和学术探索,重点是维护安全和遵守许可证限制。
4.Vicuna
由LMSYS开发的Vicuna系列大型语言模型以其生成类人文本的能力而闻名。这些模型在理解和提供基于用户提示的响应方面表现出色,使它们对聊天机器人和内容生成等各种应用非常有用。
Vicuna有两种大小的模型:Vicuna-7B和Vicuna-13B。使用GPT-4作为对比参考的初步评估表明,Vicuna-13B的质量达到OpenAI ChatGPT和Google Bard的90%以上。此外,与LLaMA和斯坦福大学Alpaca等其他型号相比,它在90%以上的情况下表现出更强的性能。
Vicuna模型的一个重要方面是它依赖于人类生成的数据。这使它成为第一个使用此类数据训练的开源大语言模型之一,生成连贯并且具有创造性的文本。Vicuna是Alpaca模型的改进版本,它基于Transformer架构,但采用人类生成的对话数据集进行了微调。
Vicuna的主要用途是用于研究,特别是自然语言处理、机器学习和人工智能方面的研究人员和爱好者。Vicuna仅供非商业用途的用户使用,用户必须遵守LLaMA制定的使用模型的规则,尊重OpenAI使用其生成的数据的条款,并遵守ShareGPT的隐私规则。
这两款Vicuna模型都是在LLaMA-13B模型的基础上构建的,并从ShareGPT.com公开API收集的约70000个用户共享对话进行了微调。HTML被转换回markdown以确保数据质量,不合适或低质量的样本被过滤掉。冗长的对话也被分成较小的片段,以适应模型的最大上下文长度2048个令牌。
在训练过程中,Vicuna基于斯坦福大学的Alpaca模型进行了几项关键改进:
- 多轮对话:调整训练损失,以解释多轮对话,使模型更好地理解和响应复杂的,多轮对话。
- 内存优化:最大上下文长度从512扩展到2048,使维库纳能够理解更长的上下文。梯度检查点和Flash Attention用于内存优化,以管理增加的GPU内存需求。
- 通过Spot实例降低成本:为了减轻由更大的数据集和增加的序列长度导致的显著训练费用,使用了SkyPilot管理的点实例。这些实例更便宜,并具有自动恢复、抢占和自动区域切换功能,显著降低了培训成本。
凭借其更加类似人类的文本生成功能,开放性和多功能性,Vicuna代表了大型语言模型领域的一个突破。
5.Guanaco
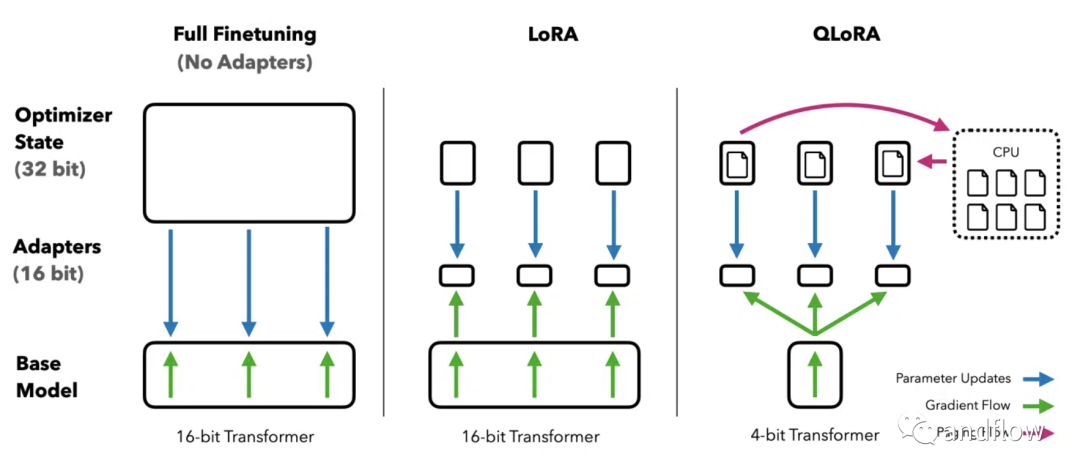
Guanaco是一个基于Meta的LLaMA模型的高级语言模型系列,用于在多语言环境中出色地完成指令。Guanaco是建立在LLaMA-7B的基础上,使用创新的QLoRA(量化低秩适配器)方法进行了重大改进和微调的结果。这种方法允许在单个GPU上对大型语言模型进行微调。
Guanaco系列模型包括具有不同数量参数的各种变体,参数从70亿到650亿不等。根据研究人员的说法,最大的Guanaco模型能够达到了Chat GPT 99.3%的性能,展示了其在基准测试中的卓越性能。
Guanaco使用QLoRA方法进行训练,该方法有效地将模型量化到4位精度,并结合了低秩自适应权重(LoRA),在保持高性能的同时显著降低了内存需求。这种方法允许最大的650亿参数Guanaco模型在GPU内存不足48千兆字节的情况下有效运行,在不影响性能的情况下可以减少超过780千兆字节大小。
Guanaco的一个显著特点是它对扩展对话的适应性。它可以根据用户的要求继续回答问题或讨论话题,非常适合聊天机器人应用程序。该模型还支持视觉问答(VQA),使其能够解释和响应文本和视觉输入。
Guanaco最初是基于Alpaca模型的52000个数据集的基础上进行扩展,之后加入了超过534530个额外条目,涵盖了各种语言、语言任务和语法任务。这种广泛的训练有助于其有效执行多语言和多模式任务。
虽然,Guanaco模型未获得商业应用许可。其主要用途是学术研究和非商业应用。但它在多功能性和强大的性能等方面的自然语言处理任务能力具有较高价值。
总之,Guanaco将高效的微调、多语言功能和适应性会话技能相结合,使其在语言模型领域取得了重大进步,在聊天机器人、内容生成和终端硬件应用、私有模型等方面具有潜在应用价值。
6.RedPajama
RedPajama is a collaborative project involving Together, Ontocord.ai, ETH DS3Lab, Stanford CRFM, and Hazy Research, with the mission to create a set of leading, fully open-source language models. The project’s primary objective is to bridge the quality gap between open and closed models, as many powerful foundation models are currently locked behind commercial APIs, limiting research, customization, and usage with sensitive data.
RedPajama是一个由Together、Ontocord.ai、ETH DS 3Lab、斯坦福大学CRFM和Hazy Research等多机构合作的项目,其使命是创建一套领先的、完全开源的语言模型。该项目的主要目标是弥合开放模型和封闭模型之间的质量差距,因为许多强大的基础模型目前被锁定在商业API的后面,限制了敏感数据的研究、定制和使用。
RedPajama项目由三个关键组件组成:
- RedPajama数据集:RedPajama数据集是一个拥有1.2万亿令牌完全开放数据集,它是按照LLaMA论文中描述的方法创建的。这个庞大的数据集包括来自不同来源的七个数据切片,包括CommonCrawl、C4、GitHub、arXiv、Books、Wikipedia和StackExchange。每个数据切片都经过精心的预处理和过滤,确保数据质量和令牌计数与Meta在LLaMA论文中报告的数字一致。
- RedPajama基础模型:由30亿个参数和70亿个参数构成了RedPajama模型的基础。它们是基于Pythia架构开发的,在不同的任务中表现出色。两个变体是RedPajama-INCITE-Chat-3B-v1和RedPajama-INCITE-Instruct-3B-v1,两者都具有30亿个参数。RedPajama-INCITE-Chat-3B-v1模型针对会话AI任务进行了优化,擅长在会话环境中生成类人文本。另一方面,RedPajama-INCITE-Instruct-3B-v1模型旨在有效地执行指令,使其非常适合理解和执行复杂指令。
- RedPajama微调模型:此组件侧重于微调基本模型,使其在特定任务中表现出色。该项目提供了RedPajama-INCITE-Base模型的变体,每个模型都具有不同的特性和应用。例如,RedPajama-INCITE-Chat模型使用Dolly 2.0和Open Assistant数据进行微调。相比之下,RedPajama-INCITE-Instruct模型设计用于少量提示词,减少与HELM基准测试数据集的重叠。
RedPajama模型和数据集是在Apache 2.0许可下发布的,允许在研究和商业应用中使用。
7.Falcon
Falcon模型系列由技术创新研究所开发,包括一系列的大型语言模型。它们经过优化,可以在各种应用程序中实现包括文本生成、摘要和聊天机器人等功能。

Falcon系列模型包括多种型号,例如:Falcon-40B、Falcon-7B、Falcon-180B,每一个都根据特定的要求和场景量身定制。Falcon-40B模型有400亿个参数,并在RefinedWeb数据集上训练。该数据集包含15000亿个Token,是一个具备高质量、过滤和消除重复数据的Web数据。Falcon-7B模型是一个较小的变体,有70亿个参数,也在RefinedWeb数据集上训练,但进一步补充了精心整理的语料库,以增强其能力。Falcon-180B拥有1800亿参数,是Falcon在3.5万亿token完成训练,目前直接登顶HuggingFace排行榜,性能直接碾压LLaMA 2。基准测试中,Falcon 180B在推理、编码、熟练度和知识测试各种任务中,一举击败LLaMA 2。
作为因果解码器专用模型,Falcon模型可以基于前面的Token预测序列中预测下一个令牌,使其特别适合文本生成任务,包括摘要和聊天机器人等功能。他们的架构建立在GPT-3模型的基础上,并进行了一些调整,以实现更好的优化和增强性能。例如,它们使用FlashAttention和多查询注意力机制。
Falcon-40B在25000亿个RefinedWeb数据Token上进行训练,训练时间为两周,使用384个A100 40GB GPU。Falcon-7B模型在RefinedWeb数据集的15000亿个Token上进行训练,也使用相同的384 A100 40GB GPU设置进行了为期两周的训练。高效的训练过程是通过2D并行策略(PP=2,DP=192)与ZeRO优化相结合来实现的,从而使模型在使用更少的训练计算资源的情况下,性能不亚于其他开源模型。
关于Falcon 180B,它是40B的升级版本。据官方介绍,Falcon 180B 是当前最好的开源大模型。在 MMLU上 的表现超过了 Llama 2 70B 和 OpenAI 的 GPT-3.5。在 HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC 及 ReCoRD 上与谷歌的 PaLM 2-Large 不相上下。
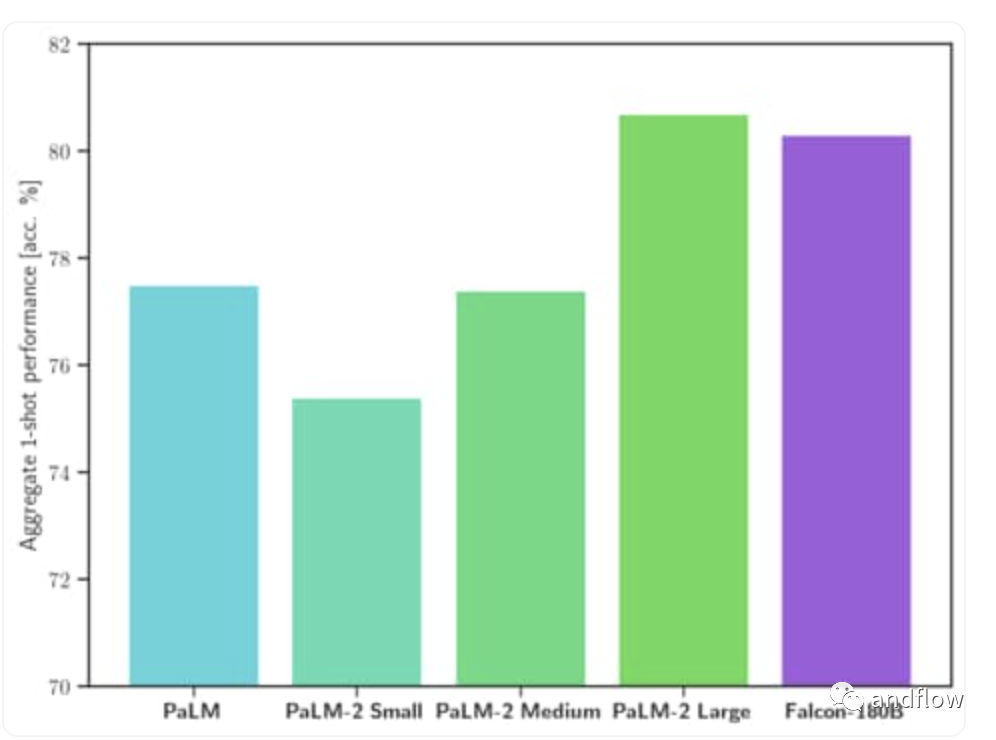
它在 Hugging Face 开源大模型榜单上以 68.74 的成绩被认为是当前评分最高的开放式大模型,评分超过了 Meta 的 LlaMA 2 (67.35)。

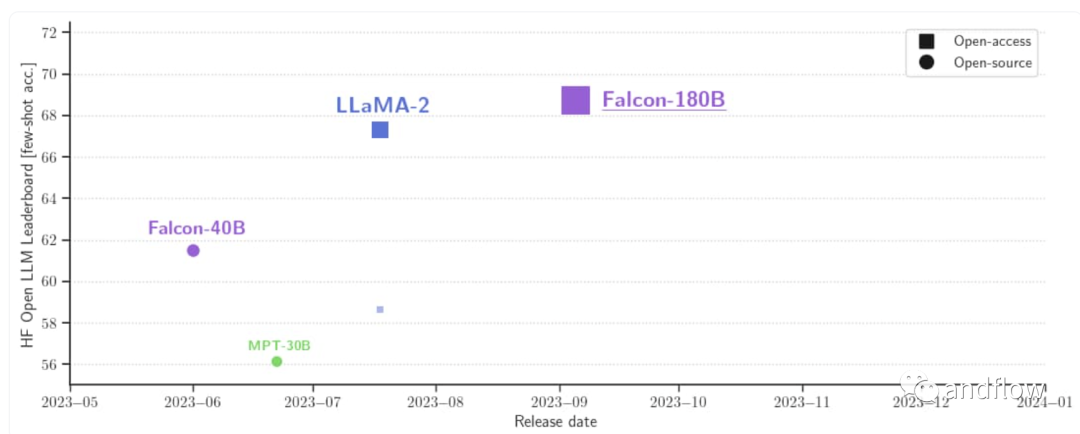
对于训练过程,Falcon 180B基于亚马逊云机器学习平台Amazon SageMaker,在多达4096个GPU上完成了对3.5万亿token的训练。总GPU计算时,大约7,000,000个。Falcon 180B的参数规模是Llama 2(70B)的2.5倍,而训练所需的计算量是Llama 2的4倍。具体训练数据中,Falcon 180B主要是RefinedWe数据集(大约占85%) 。此外,它还在对话、技术论文,以及一小部分代码等经过整理的混合数据的基础上进行了训练。这个预训练数据集足够大,即使是3.5万亿个token也只占不到一个epoch。
硬件要求:

Falcon模型是在Apache 2.0许可证下发布,允许在商业场合使用,没有版税或其他限制。但Falcon-180b 在商业用途的使用条件非常严格,不包括任何“托管用途”。建议您查看开源许可证并咨询您的法律团队。
总之,Falcon模型的多功能性和有效性使其适用于广泛的场景。它们可以用于大型语言模型的研究,并作为进一步专业化和微调打下坚实基础,以满足特定场合应用,如摘要,文本生成和聊天机器人功能。
8.FLAN-T5
FLAN-T5系列包括几种不同参数的模型:
- Flan-T5 small (80M)
- Flan-T5 base (250M)
- Flan-T5 large (780M)
- Flan-T5 XL (3B)
- Flan-T5 XXL (11B)
FLAN-T5的架构基于T5编码解码器架构,其中编码器和解码器都是transformers。这个基于transformers的语言模型由12个transformers层和一个用于并行处理文本的前馈神经网络组成。
FLAN-T5在多任务语言理解和跨语言问答等方面表现出色。它在文本生成、常识推理、问答、情感分类、翻译、代词解析等方面十分优秀。它为研究零镜头NLP任务和上下文少镜头学习NLP任务(如推理和问答)提供了宝贵资源。此外,它理解当前大型语言模型的局限性,有助于推进公平性和安全性的研究。
Google于2022年底在Apache许可下开源FLAN-T5。
Flan-T5在训练过程中,有两个阶段的过程中使用了大量的文本数据:预训练和微调。预训练阶段使用T5架构,模型在给定的Token序列中预测中的下一Token。在指令微调阶段,FLAN-T5的功能通过特定指令进行了细化,以增强其在各种任务和语言上的性能。
FLAN-T5的微调数据类型非常广泛,包括473个数据集、146个任务类别和1836个任务。微调过程中混合四种任务:Muffin、T0-SF、NIV 2和CoT。这些混合包括各种任务,例如:对话数据、程序合成数据、算术推理、多跳推理(multi-hop reasoning)、自然语言推理等等。
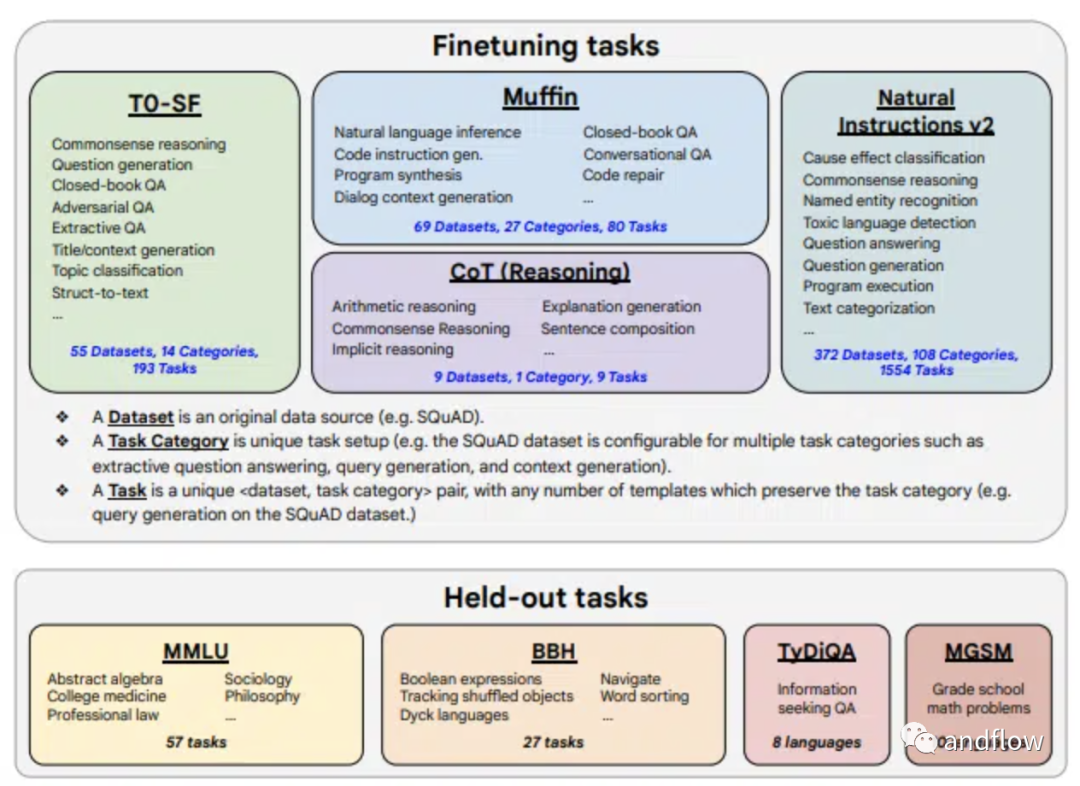
Flan-T5模型不限于特定的任务或语言,为研究人员和开发人员提供了一个强大的工具,推动了自然语言理解和文本生成的发展。
9.Stable Beluga (Formerly Free Willy)
Stable AI以及CarperAI实验室的Stable Beluga项目产生了两个模型,Stable Beluga 1和Stable Beluga 2。这些模型建立在Meta的Llama模型之上,并使用标准Alpaca格式的合成生成的新数据集进行微调。该项目旨在弥合开放模型和封闭模型之间的质量差距,允许研究人员和开发人员探索和定制这些模型,以满足各种自然语言处理任务。
Stable Beluga 1和Stable Beluga 2分别采用LLaMA-65B和LLaMA 2-70B基础模型。这两种模型在各种基准测试中都表现良好。Stable Beluga 2 甚至在某些基准测试中超过了Llama 2。
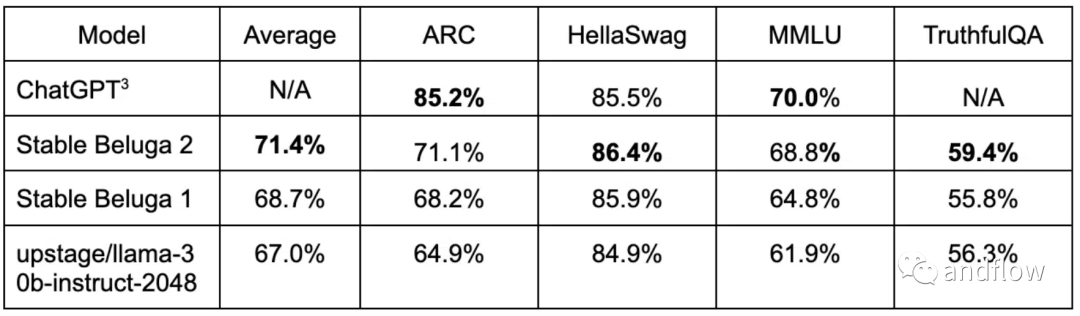
Stable Beluga大语言模型擅长解决类似法律、数学等专业领域的复杂问题,并专注于微妙的语言细节。
Stable Beluga模型目前作为一项研究实验,提供了非商业许可(non-commercial license),强调致力于促进AI社区的开放研究和可访问性。该许可证确保模型可免费用于学术和非商业目的,鼓励自然语言处理领域的合作和创新。
Stable Beluga模型的训练过程基于Orca方法,类似于微软的渐进式学习方法。然而,Stable Beluga项目中使用的数据集与Orca论文不同。该团队使用Enrico Shippole的数据集,包括COT Submix Original、NIV2 Submix Original、FLAN 2021 Submix Original和T0 Submix Original,来作为提示词语言模型。数据集包含60万个高质量的样本,约为Orca数据集大小的10%。Stable Beluga使用了删除测试数据并过滤后的数据集进行了微调,以实现其卓越的性能。
10.MPT
由MosaicML开发的MPT模型是一系列基于transformers的语言模型。这些模型专为商业用途而设计,是开源的,并建立在GPT-3模型的基础上,旨在在各种自然语言处理任务中更加高效和灵活。
MPT系列由多个版本组成,其中MPT-7B、MPT-7B-StoryWriter、 MPT-30B是几个个重要的模型。MPT-7B 是一个只有解码器的Transformer模型,它在MosaicML数据团队策划的1万亿个文本和代码标记的大型语料库上训练出来,具有67亿个参数。模型主要使用了FlashAttention算法,为了处理大上下文,它还使用了ALiBi算法。而MPT-30B,拥有 300 亿参数,其功能明显比前一代 MPT-7B 语言模型更强大,并且性能优于 GPT-3。
MPT-7B的开源许可是Apache-2.0。但是,需要注意的是,不推荐在没有微调的情况下使用基础模型。
MPT-7B-StoryWriter-65k+是MPT-7B的一个变体,专为阅读和写作等具有极长上下文长度的场景而定制。这是在books3数据集的小说子集上进行微调的结果,上下文长度为65k Token。MPT-7B-StoryWriter-65k+可以在A100-80GB GPU的单个节点上生成多达84k个Token的内容。与MPT-7B一样,它的开源许可也是Apache-2.0。
MPT-7B-Chat 是个类似聊天机器人的对话生成模型,它是在包括ShareGPT-Vicuna、HC 3、Alpaca、Helpful and Harmless和Evol-Instruct等多个数据集上进行微调的结果。其开源许可为CC-By-NC-SA-4.0,意味着它只能在非商业用途使用。
MPT-7B-Instruct是一个专门为短格式指令而量身定制的模型,基于MosaicML发布的MPT-7B数据集进行微调创建的结果,该数据集的来源是Databricks Dolly-15k和Anthropic的Helpful和Harmless数据集。它的开源许可是CC-By-SA-3.0。
MPT 7B的训练过程使用了8个A100-80GB的GPU,具有分片数据并行性、LION优化器和完全分片数据并行性(FSDP)技术。梯度检查点用于优化训练期间的内存。该模型由67亿个参数、32个Transformer层(每个层的隐藏大小为4096)、16个关注点以及50432个单词的词汇表组成,序列长度为65536。
MPT-30B 是由MosaicML用2个月的时间训练的新一代产品,MPT-30B通过数据混合进行预训练,从10个不同的开源文本语料库中收集了1T个预训练数据的token,并使用 EleutherAI GPT-NeoX-20B分词器对文本进行分词,并根据一定比例进行采样。
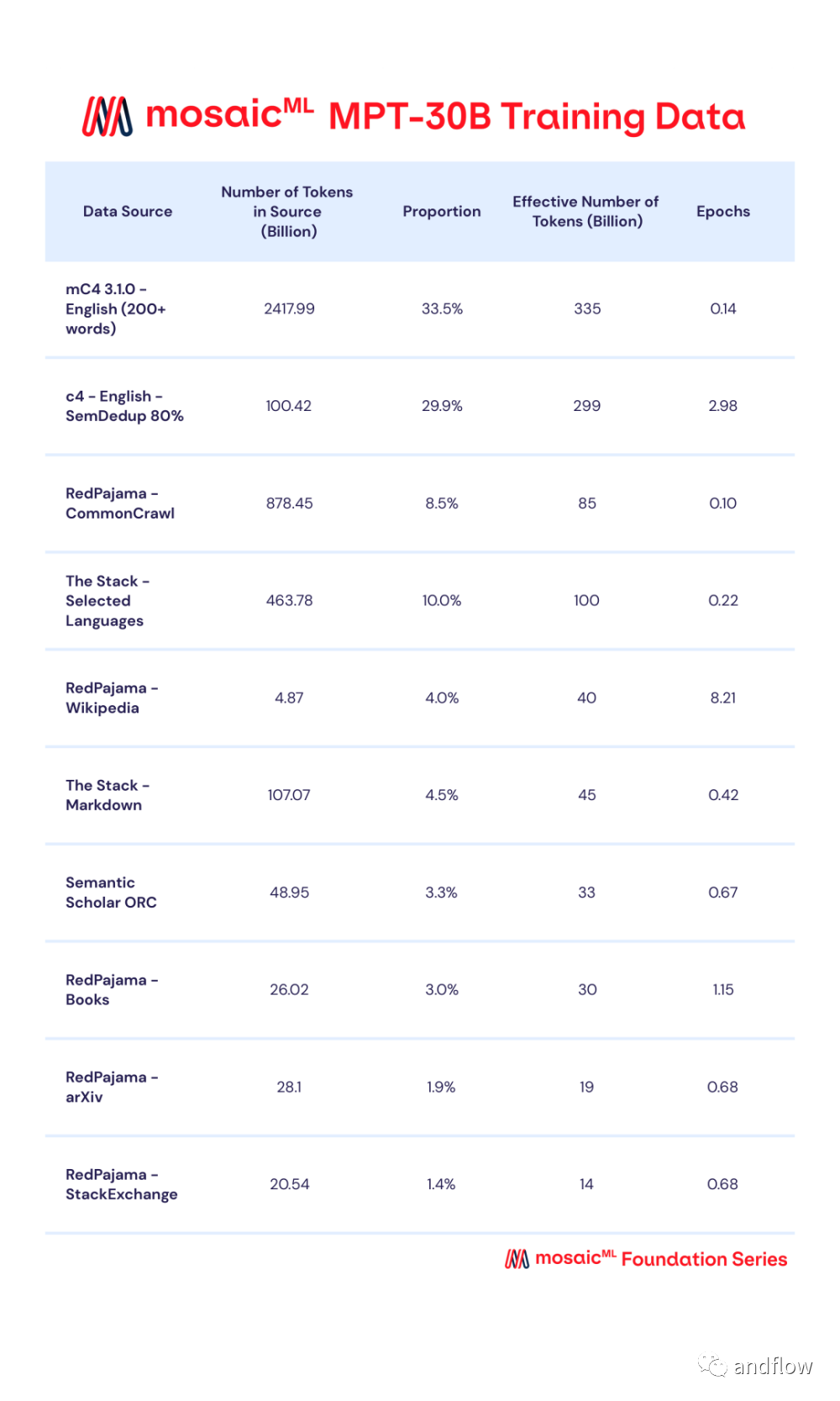
MPT-30B使用英伟达的H100 GPU 集群进行训练。采用Apache 2.0开源许可协议,性能强于原始的 GPT-3,并且与LLaMa-30B和 Falcon-40B 等其他开源模型具有竞争力。
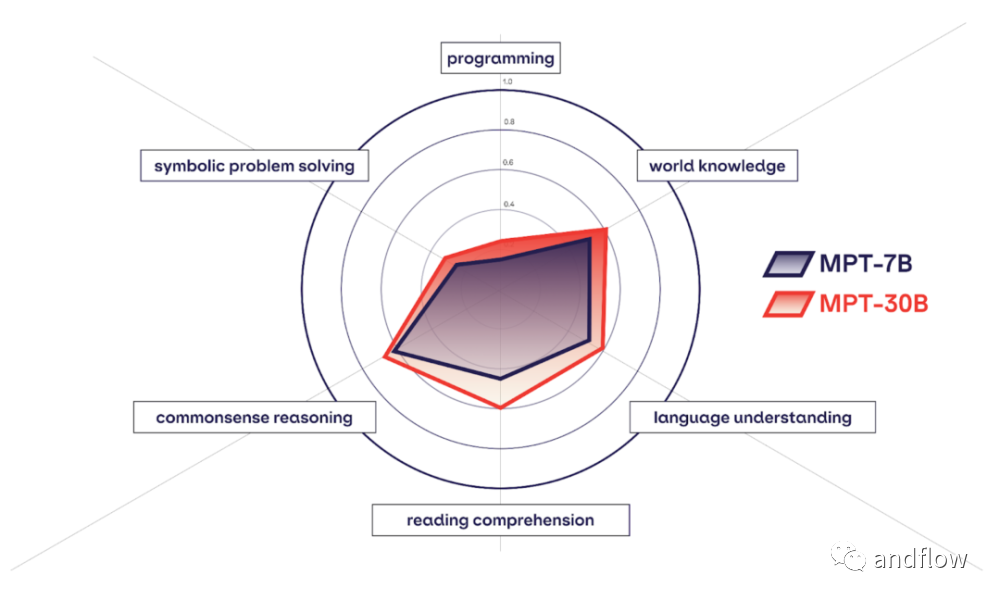
总之,MPT是自然语言处理方面一个有价值的开源模型。它们专注于处理长上下文的处理效率、灵活性和令人印象深刻的性能,使它们适合于各种语言相关的任务和应用场景。


















