基于互联网数据训练的生成模型彻底改变了文本、图像和视频内容的创建方式。有研究者预测,也许生成模型的下一个里程碑是能够模拟人类体验世界的方方面面,比如在公路上如何驾驶汽车,又比如如何准备饭菜。
现如今,借助非常全面的真实世界模拟器(real-world simulator),人类可以与不同场景和物体进行交互,机器人也可以从模拟经验中进行学习,从而避免出现物理损坏的风险。
然而,构建这样一个真实世界模拟器的主要障碍之一在于可用的数据集。虽然互联网上有数十亿的文本、图像和视频片段,但不同的数据集涵盖不同的信息轴,必须将这些数据集中在一起才能模拟出对世界的真实体验。例如,成对的文本图像数据包含丰富的场景和对象,但很少有动作,视频字幕和问答数据包含丰富的高级活动描述,但很少有低级运动细节, 人类活动数据包含丰富的人类动作但很少有机械运动,而机器人数据包含丰富的机器人动作但数量有限。
以上列举的信息差异是自然的且难以克服,这给构建一个旨在捕捉现实世界真实体验的真实世界模拟器带来了困难。
本文中,来自 UC 伯克利、Google DeepMind、MIT 等机构的研究者探索了通过生成模型学习真实世界交互的通用模拟器 UniSim,迈出了构建通用模拟器的第一步。例如 UniSim 可以通过模拟「打开抽屉」等高级指令和低级指令的视觉结果来模拟人类和智能体如何与世界交互。

- 论文地址:https://arxiv.org/pdf/2310.06114.pdf
- 论文主页:https://universal-simulator.github.io/unisim/
本文将大量数据(包括互联网文本 - 图像对,来自导航、人类活动、机器人动作等的丰富数据,以及来自模拟和渲染的数据)结合到一个条件视频生成框架中。然后通过仔细编排沿不同轴的丰富数据,本文表明 UniSim 可以成功地合并不同轴数据的经验并泛化到数据之外,通过对静态场景和对象的细粒度运动控制来实现丰富的交互。
下面视频演示了 UniSim 如何模拟具有长交互视界的示例,视频显示 UniSim 一口气模拟了机器人八个动作指令:
UniSim 对人类动作的模拟:
UniSim 对 RL 策略的模拟部署如下所示:

对于这项研究,Meta 首席 AI 科学家 Yann LeCun、英伟达高级研究科学家 Jim Fan 等业界人士进行了转发。LeCun 给出一个「Cool」字的评价。
Jim Fan 表示,这项工作非常有趣,视频扩散模型被用作了数据驱动物理模拟,其中智能体可以规划、探索和学习最优行动,并且无需接触机器人硬件也不会造成损害。可以说 LLM 不仅是一个 OS,还化身为完整的现实模拟器。

论文一作、UC 伯克利博士生 Sherry Yang 表示,「学习现实世界模型正在成为现实」。

模拟现实世界的交互
如下图 3 所示,UniSim 能够模拟一系列丰富动作,例如厨房场景中洗手、拿碗、切胡萝卜、擦干手这一系列动作;图 3 右上是按下不同的开关;图 3 下是两个导航场景。

对应上图 3 右下的导航场景

对应上图3右下的导航场景
在长程模拟方面,下图 4 是一个 UniSim 自回归地顺序模拟 8 个交互的例子:

除了支持丰富动作和长程交互,UniSim 还支持高度多样化和随机的环境变换,例如移除顶部毛巾后显示的对象具有多样性(下图 5 左)。

UniSim 在真实世界迁移的结果。UniSim 的真正价值在于模拟现实世界,图 7 显示了 VLM 生成的语言规划,UniSim 根据语言规划生成的视频,以及在真实机器人上的执行情况。

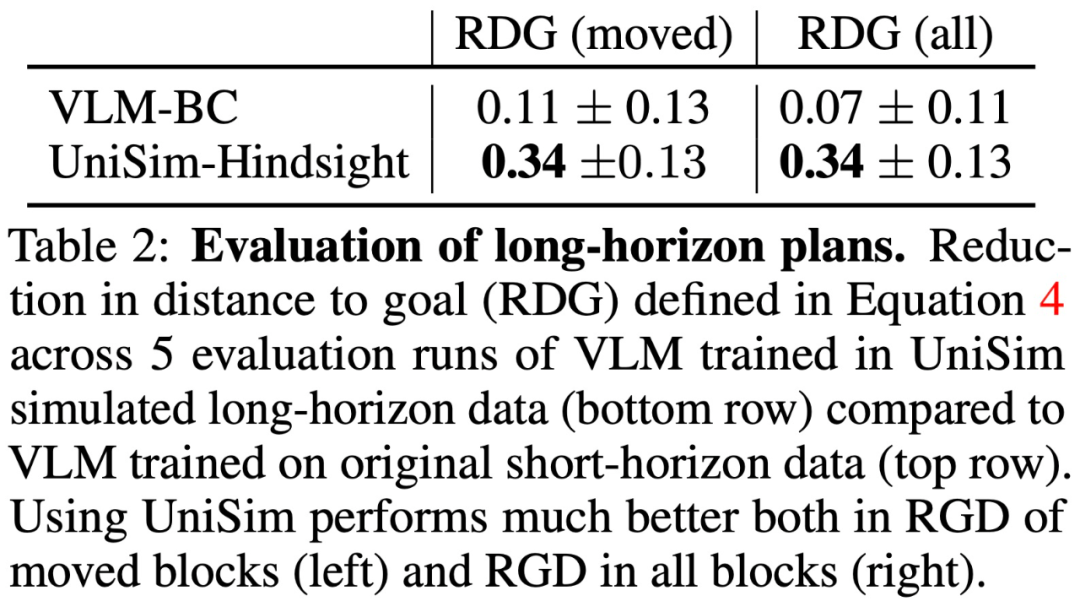
除了测试 UniSim 在真实世界的迁移能力之外,本文还进行了基于模拟器的评估,结果如表 2 所示:
用于强化学习的真实世界模拟器
实验还评估了 UniSim 在模拟真实机器人执行各种动作方面的质量如何,机器人通过重复执行低级控制操作约 20-30 个步骤来左、右、下、上移动端点 。表 3 显示,RL 训练显着提高了 VLA 策略在各种任务中的性能,尤其是在指向蓝色块等任务中。然后,本文直接将在 UniSim 中训练的 RL 策略零样本部署到真实机器人上,如图 8(底行)所示。