大家好,我是Echa。
今天小编给大家介绍一个跟生活息息相关的而且经常使用的好东西。物理世界和数字世界的信息转换是数字化发展的一个技术内容。
专业术语叫:光学字符识别——OCR(Optical Character Recognition)。
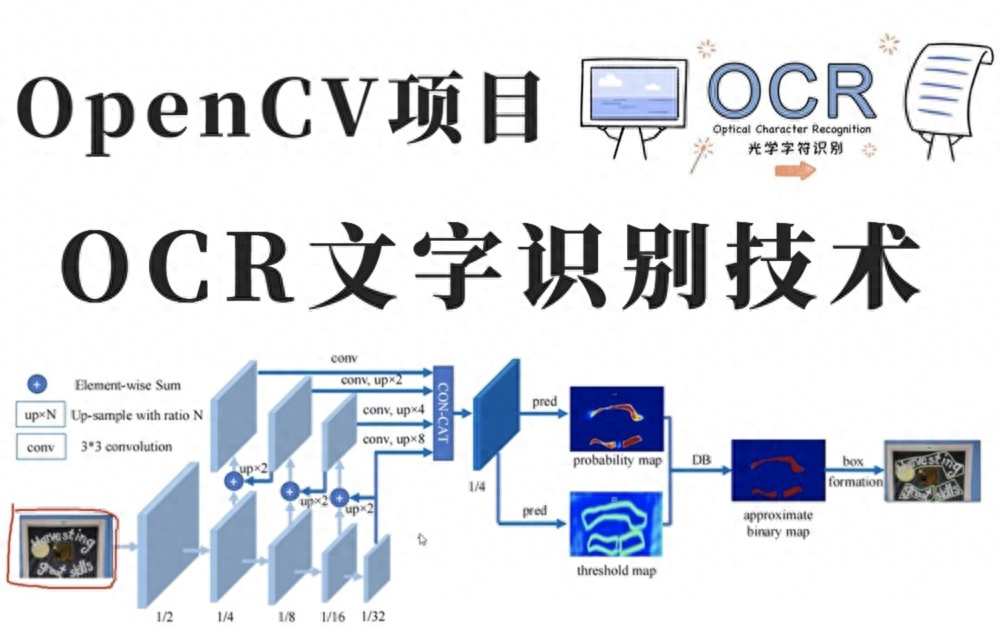 基于目标检测类的OCR识别技术
基于目标检测类的OCR识别技术
OCR是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。这样描述估计还是一头雾水,下面直接说应用场景就会更清晰明了。
OCR应用场景如下:
卡片证件识别类:大陆、港澳台身份证、通行证、护照识别,卡类识别,车辆类驾驶证识别、行驶证识别,执照识类识别,企业证件类识别
文字信息结构化视频类识别:字幕识别和文字检测,表格;
票据类识别:增值税发票识别、全电发票识别、银行支票识别、承兑汇票识别、银行票据识别、物流快递识别;
其他识别:二维码识别、一维码识别、车牌识别、数学公式识别、物理化学符号识别、音乐符号识别、工程图识别、流程图识别、古迹文献识别、手写输入识别;
除了以上列举的之外,还有自然场景下的文字识别、菜单识别、横幅检测识别、图章检测识别、广告类图文识别等围绕审核相关的业务应用。
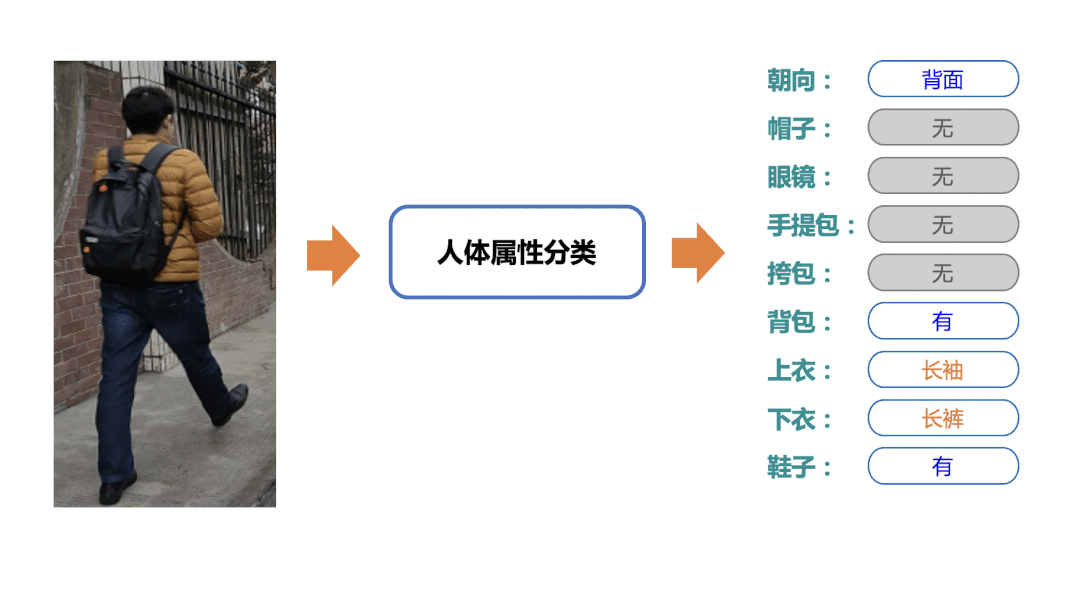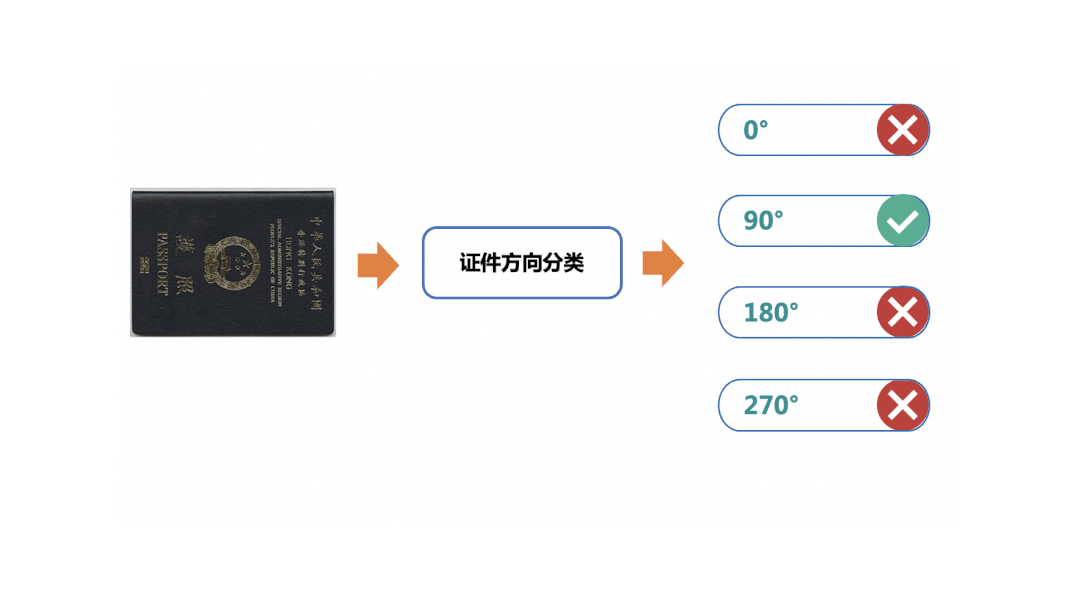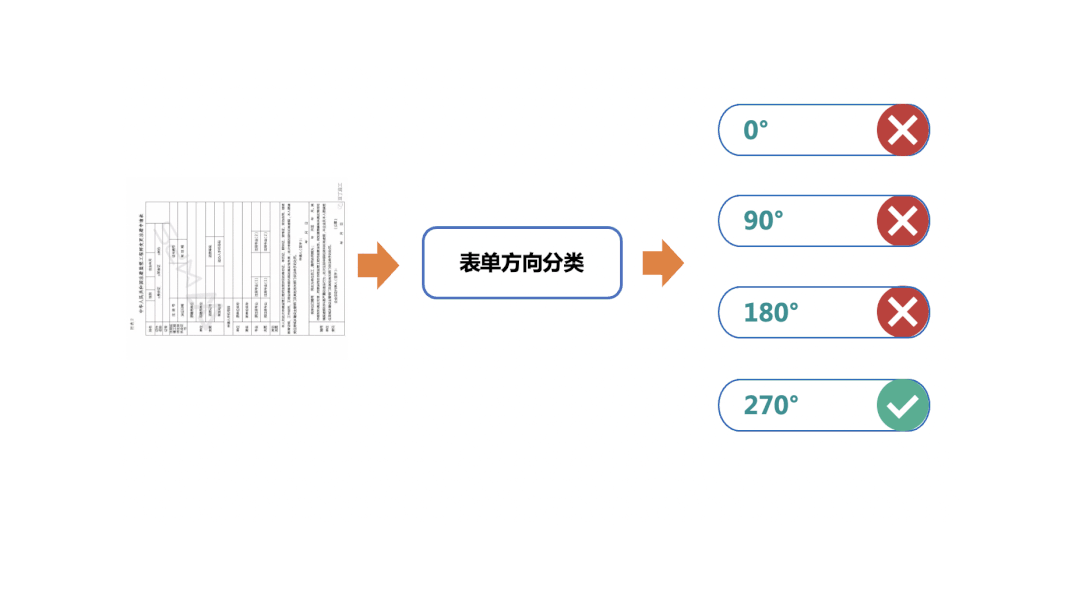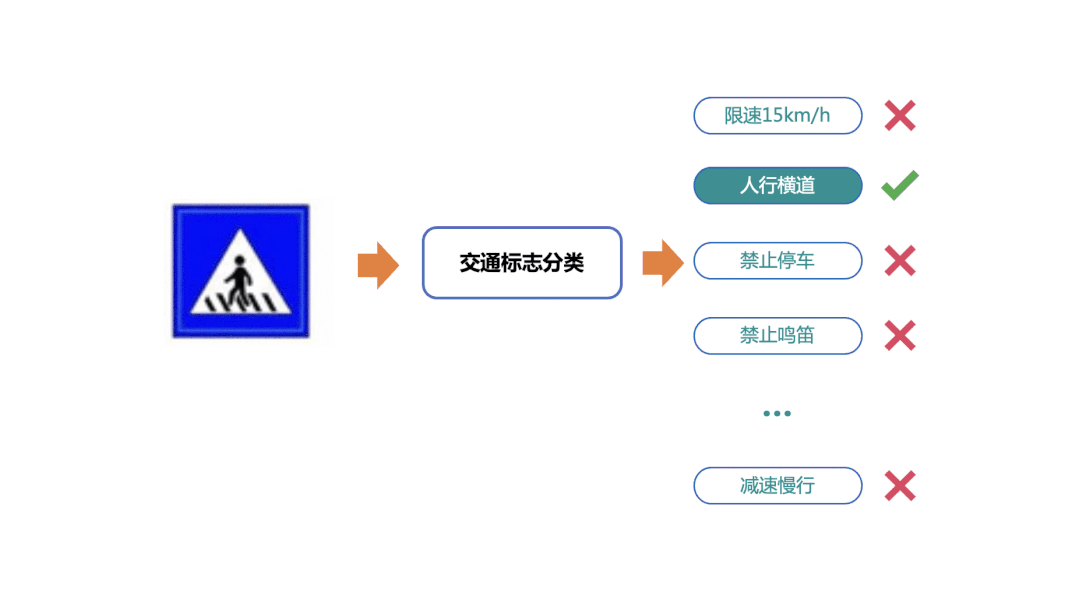 简单的OCR应用场景
简单的OCR应用场景
随着科技的发展,OCR场景随处可见。人脸、车辆、人体属性、卡证、交通标识等经典图像识别能力,在我们当前数字化工作及生活中发挥着极其重要的作用。业内也不乏顶尖公司提供的可直接调用的API、SDK,但这些往往面临着定制化场景泛化效果不好、价格昂贵、黑盒可控性低、技术壁垒难以形成多诸多痛点。
 9大场景模型效果示意图
9大场景模型效果示意图
而今天小编要给大家好物分享12个完全开源免费的OCR开源项目、覆盖人、车、OCR等9大经典识别场景、在CPU上可3毫秒实现急速识别、一行代码就可实现迭代训练的项目!希望对大家有所帮助。可以借助一些主流开源框架来快速应用项目中,达到我们的目的。
全文大纲
- Tesseract.js - 是一个基于TesseractOCR的Web浏览器OCR软件。
- OCRopus - 是由Google开发的OCR相关工具集合。
- Tesseract OCR - 是一个非常经典的开源OCR引擎。
- Ocrad - 一个轻量级的OCR解决方案,主要以识别印刷文本而闻名。
- GOCR- 是在GNU通用公共许可证下开发的开源OCR引擎。
- Ocrad.js - 是一个基于Ocrad的浏览器的OCR软件。
- Capture2Text- 是一个基于命令行的Windows OCR软件。
- GImage Reader- 它能够识别多种语言以及各种图像文件格式的文本。
- OCRmyPDF-是一个专门用于PDF的OCR识别软件。
- PaddleClas - 是飞桨为工业界和学术界所准备的一个图像识别和图像分类任务的工具集。
- kraken - 一个由Python开发的OCR软件,主要用于非拉丁字符的识别。
- EasyOCR- 基于机器学习(CRNN)实现OCR功能。
Tesseract.js - 是一个基于TesseractOCR的Web浏览器OCR软件。
Github:https://github.com/naptha/tesseract.js#tesseractjs
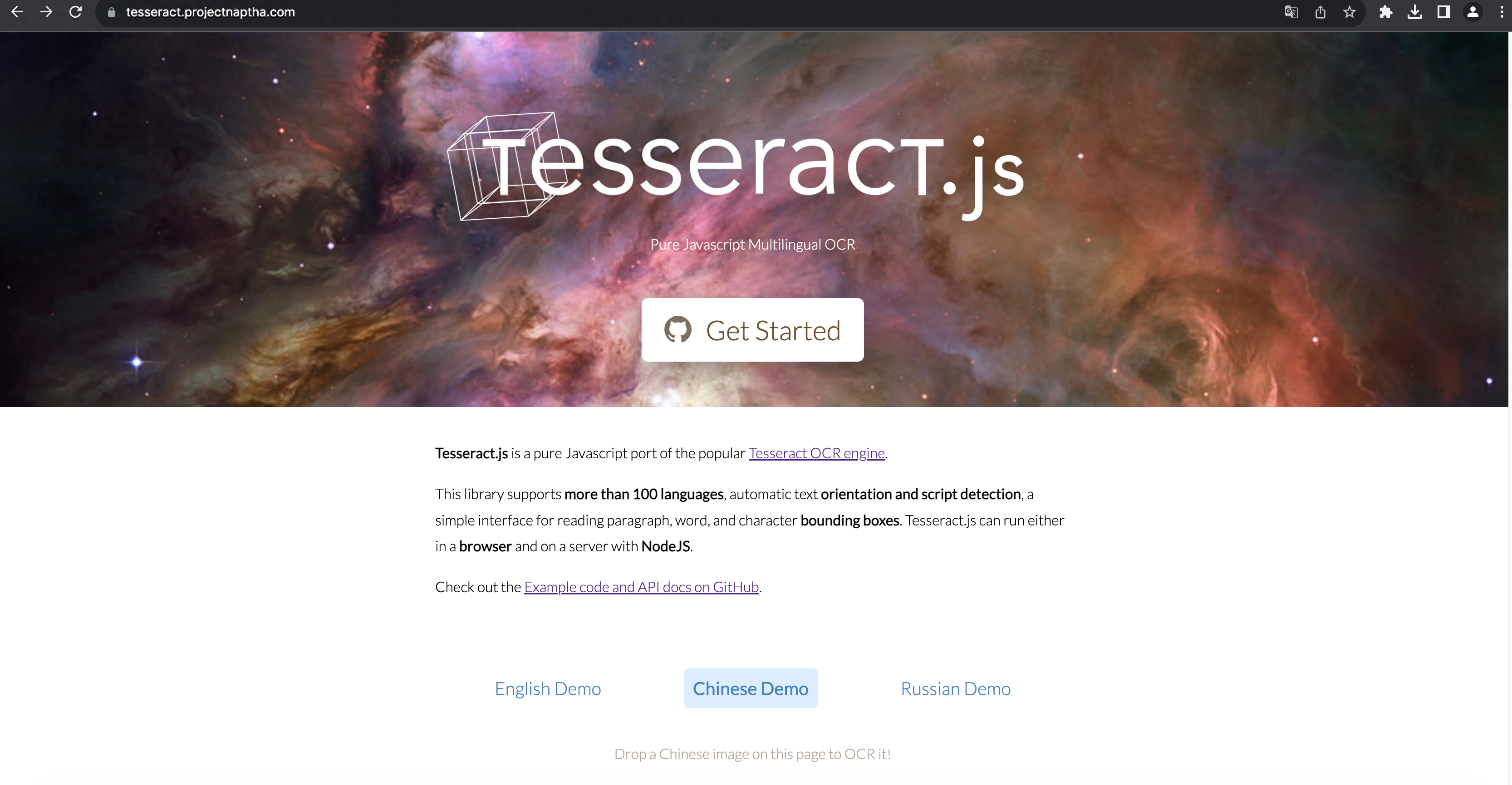 Tesseract.js 官网
Tesseract.js 官网
Tesseract.js是一个基于TesseractOCR的Web浏览器OCR软件。你可以在浏览器中使用它,并且非常易用。与Tesseract OCR一样,它也支持多种语言,包括中文。
Tesseract.js 网站上所说,它支持 100 多种语言,自动文本定位和脚本检测,用于阅读段落、单词和字符边界框的简单界面。
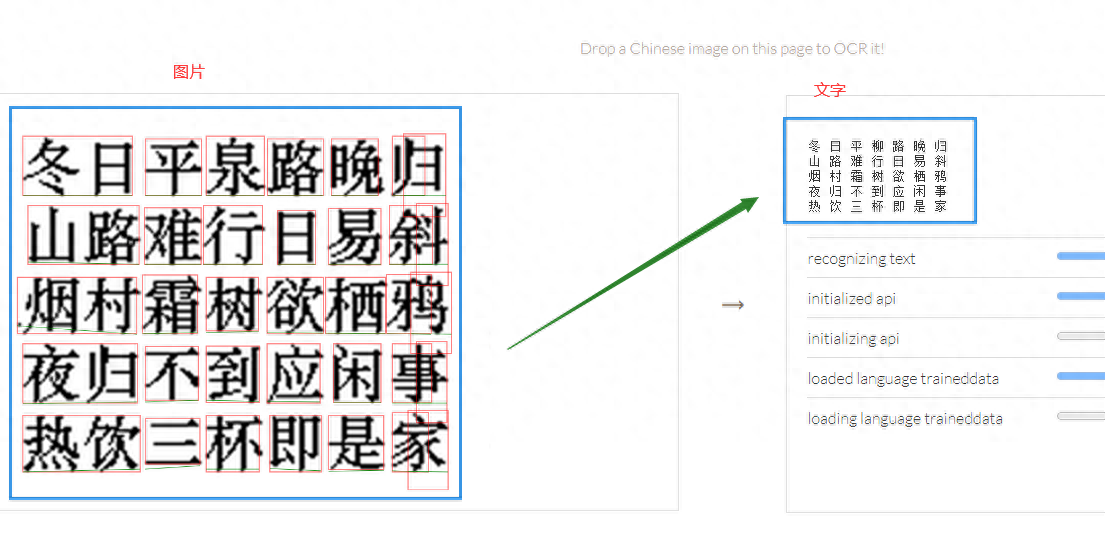
Tesseract.js 演示截图
 Tesseract.js 案例演示
Tesseract.js 案例演示
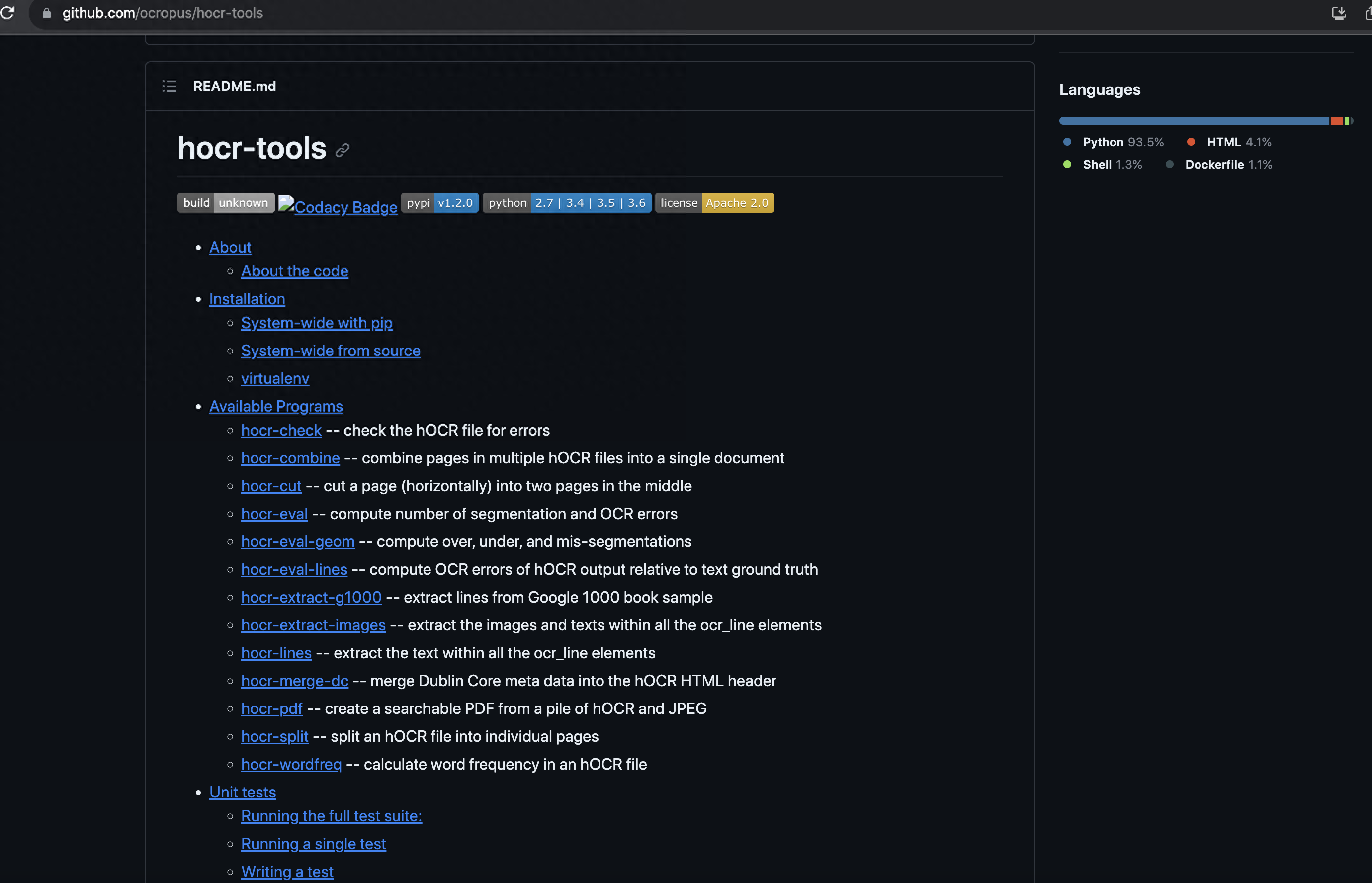
OCRopus - 是由Google开发的OCR相关工具集合。
Github:https://github.com/ocropus
OCRopus是由Google开发的OCR相关工具集合,它扩展了Tesseract OCR引擎的功能。它提供了布局分析、文本识别和样本数据生成的高级功能。
另外,OCRopus可以从命令行通过指定输入的图像来执行它。它会将识别的文本直接输出到标准输出,或者将其作为hOCR(基于HTML)代码写入文件,然后可以将其转换为可搜索的PDF。如果需要更精确的控制,可以在命令行上指定选项来执行特定操作。
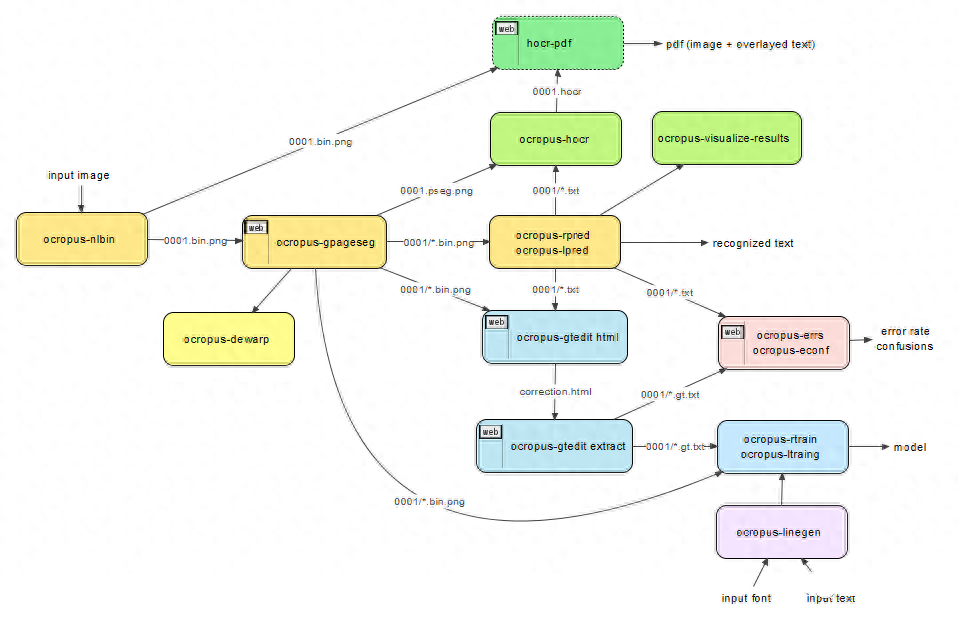
优势:
- 布局分析:OCRopus在布局分析方面非常精确,使其成为具有复杂布局或多列结构文档识别的理想选择。
- 文本识别准确性:OCRopus通过利用Tesseract的精确OCR引擎和其他组件,能够提高识别的准确性。
- 可定制性:OCRopus能够生成用于训练的样本数据,用于训练自定义的OCR模型,从而在专业应用中实现更高可定制性和准确性。
缺点
- 学习曲线:与独立的OCR引擎相比,OCRopus由于其工具和组件的范围比较广,因此具有更陡峭的学习曲线。
- 资源密集型:OCRopus的高级功能可能需要更多的计算资源,这个可能需要较高的成本,并且也需要考虑项目对处理时间的要求。
Tesseract OCR - 是一个非常经典的开源OCR引擎。
Github:https://github.com/tesseract-ocr/tesseract
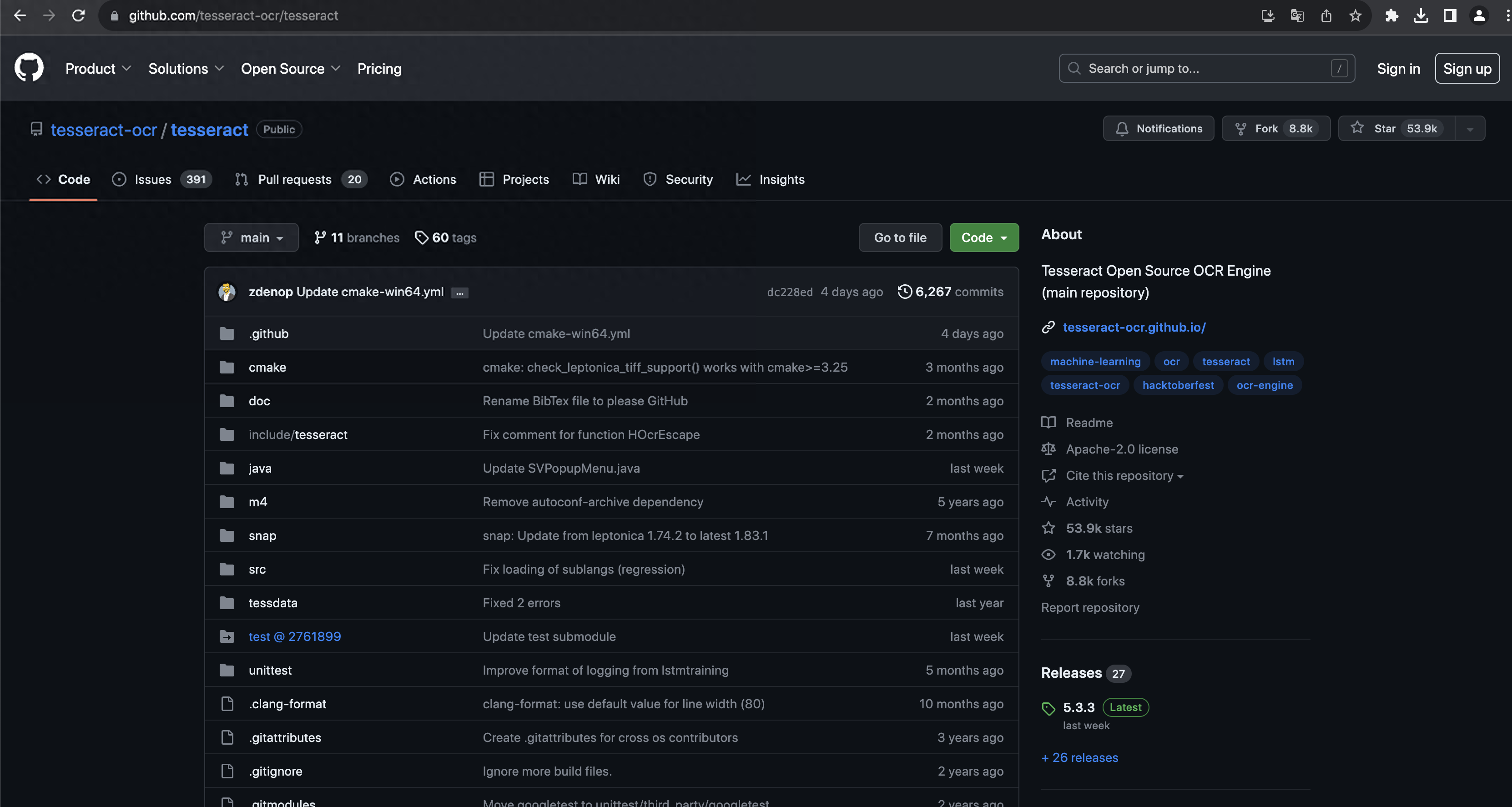 Tesseract OCR Github 官网
Tesseract OCR Github 官网
Tesseract是一个非常经典的开源OCR引擎,最初由Hewlett-Packard开发,现在由Google维护。Tesseract以其准确性和多功能性而闻名,可以提取数据并将扫描的文档、图像和手写文字转换为机器理解的文本。Tesseract支持100多种语言,并兼容多种操作系统,并且提供了非常方便的命令行界面。
优势:
- 准确性:Tesseract提供了非常高OCR准确性,特别是在打印文本和扫描文档方面。
- 语言支持:Tesseract支持广泛的语言,允许识别多种语言的文本,包括一些特殊语种,使其成为多语言应用的理想选择。
- 持续改进:Tesseract的开源社区非常活跃,能够及时地更新升级项目、修复Bug、完善用户反馈的性能需求等。
缺点:
- 复杂布局文档识别:Tesseract在简单布局的文档上表现非常好,但在布局比较复杂的文档上就需要额外的预处理或后续处理步骤。
- 手写识别准确度:Tesseract在识别机器打印文本方面表现出色,但在手写文本上的表现并不尽如人意,有时还不如一些专用手写识别工具准确。
Ocrad - 一个轻量级的OCR解决方案,主要以识别印刷文本而闻名。
传送门:https://www.gnu.org/software/ocrad/
 Ocrad 官网
Ocrad 官网
Ocrad以其简单性和识别速度而闻名,它提供了一个轻量级的OCR解决方案,主要以识别印刷文本而闻名。它旨在提供一个简单高效的OCR解决方案,侧重文本识别提取的速度和易用性。
优势
- 易用性和识别效率:Ocrad简单的设计和轻量级的特性有助于其易用性和识别效率。特别适合用于快速和简单的OCR解决方案需求。
- 打印文本识别:Ocrad擅长从扫描图像中识别打印文本,可以从清晰且格式良好的打印文档中识别提取出可靠的结果。
缺点
- 缺乏高级功能:Ocrad的侧重点在于基础的OCR任务,它可能缺乏高级功能,例如布局分析或手写识别等。
- 复杂文本和低质量图像的准确性:在处理复杂的文本结构或低质量的扫描图像时,Ocrad的准确性可能会降低。
GOCR- 是在GNU通用公共许可证下开发的开源OCR引擎。
传送门:https://jocr.sourceforge.net/
 GOCR 官网
GOCR 官网
GOCR是在GNU通用公共许可证下开发的开源OCR引擎。它能够识别各种图像文件格式中的文本内容,并支持多种语言和操作平台。
虽然它的准确性可能无法超过其他OCR引擎,但GOCR的优势是非常简单易用。
优势
- 简单性:GOCR的主要优势在于它的简单性。该软件提供了一个简单易用的界面,适合那些喜欢简单OCR解决方案而不需要大量配置或复杂设置的用户。
- 多语言支持:GOCR支持多种语言,允许用户从包含不同语言内容的图像中提取文本。
缺点
- 准确性:虽然GOCR提供了基本的OCR功能,但其准确性可能无法与其他更高级的OCR引擎相媲美。
- 高级功能:GOCR专注于简单的OCR任务,可能缺乏布局分析或专业识别算法等高级功能。因此,如果您需要高级功能,这个工具并不是很适合。
Ocrad.js - 是一个基于Ocrad的浏览器的OCR软件。
传送门:https://antimatter15.com/ocrad.js/demo.html
 Ocrad.js 官网
Ocrad.js 官网
Ocrad.js是一个基于Ocrad的浏览器的OCR软件。在JavaScript中使用它。支持的图像格式包括JPEG、PNG、GIF、BMP、SVG、NetBPM等。
它非常简单易用,只需要通过调用OCRAD的函数即可实现对img标签的识别。虽然在识别精度方面比Tesseract.js逊色,但Ocard的优势是它的模型文件比Tesseract小30倍以上。
Capture2Text- 是一个基于命令行的Windows OCR软件。
传送门:https://capture2text.sourceforge.net/
 Capture2Text 官网
Capture2Text 官网
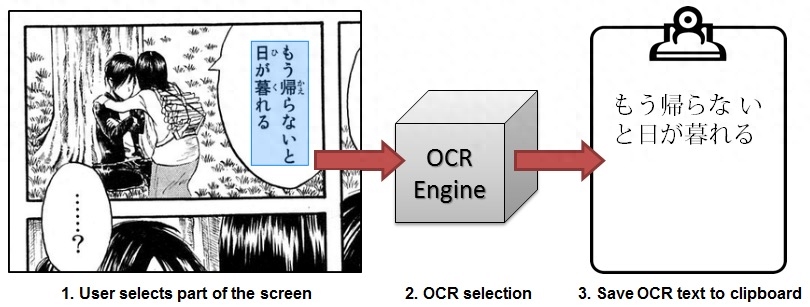
Capture2Text是一个基于命令行的Windows OCR软件。它支持多种语言,包括日语。它不仅能识别水平的字符,还能识别垂直的字符。可以在你需要的时候使用windows命令行调用OCR命令,识别出的文本将被保存进剪贴板。
GImage Reader- 它能够识别多种语言以及各种图像文件格式的文本。
Github:https://github.com/manisandro/gImageReader
 GImage Reader 官网
GImage Reader 官网
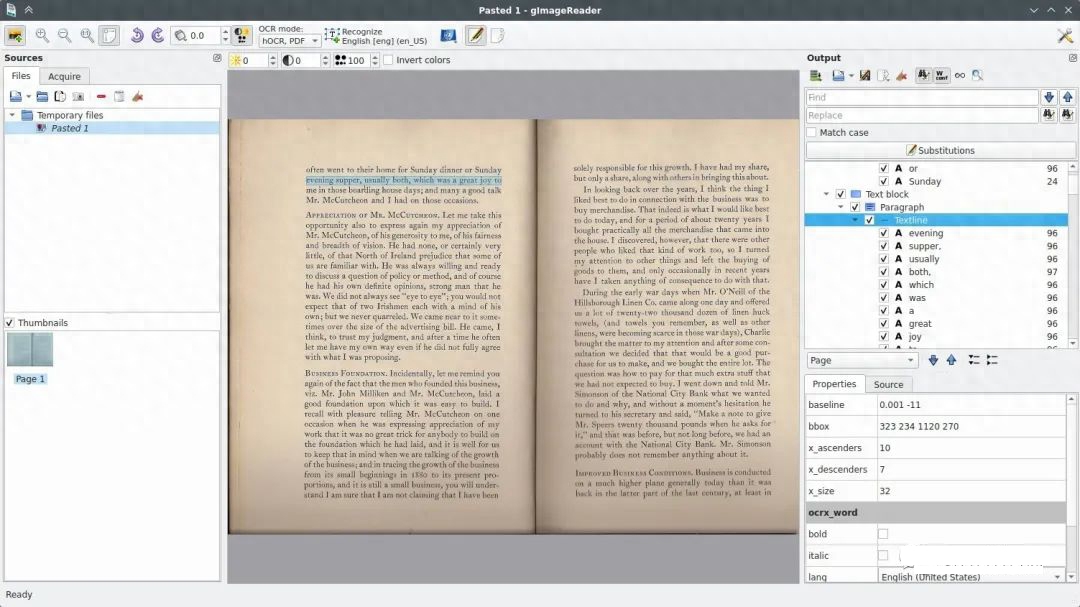
GImage Reader工具它能够识别多种语言以及各种图像文件格式的文本,使其适合从扫描的文档、屏幕截图或者照片中提取文本;并且它提供了一个简单直观的用户界面,允许您快速加载图像并获得文本结果。
优势
- 友好的用户界面:GImage Reader的界面非常直观易用,用户可以轻松访问,能够轻松加载图像并获取结果。
- 多语言支持:GImage Reader支持多种语言,允许您从包含不同语言内容的图像中提取文本。
缺点
- 缺乏高级功能:GImage Reader主要专注于比较基本的OCR任务,如果需要更加专业的内容识别,它就不适合了。
- 准确度和性能:虽然GImage Reader可用于基本的OCR任务,但其准确性和性能可能会受到图像质量和文本复杂性的影响。
OCRmyPDF-是一个专门用于PDF的OCR识别软件。
Github:https://github.com/ocrmypdf/OCRmyPDF
 OCRmyPDF 官网
OCRmyPDF 官网
OCRmyPDF是一个专门用于PDF的OCR识别软件,它能够将识别到的文本信息作为透明的文本添加到PDF中。因此,您可以在PDF中搜索文本。
如果您将其用于没有文本信息的PDF,则可以进行搜索,从而增加了方便性。由于它基于Tesseract OCR引擎进行文本识别,因此也支持中文。
PaddleClas - 是飞桨为工业界和学术界所准备的一个图像识别和图像分类任务的工具集。
Github:https://github.com/PaddlePaddle/PaddleClas
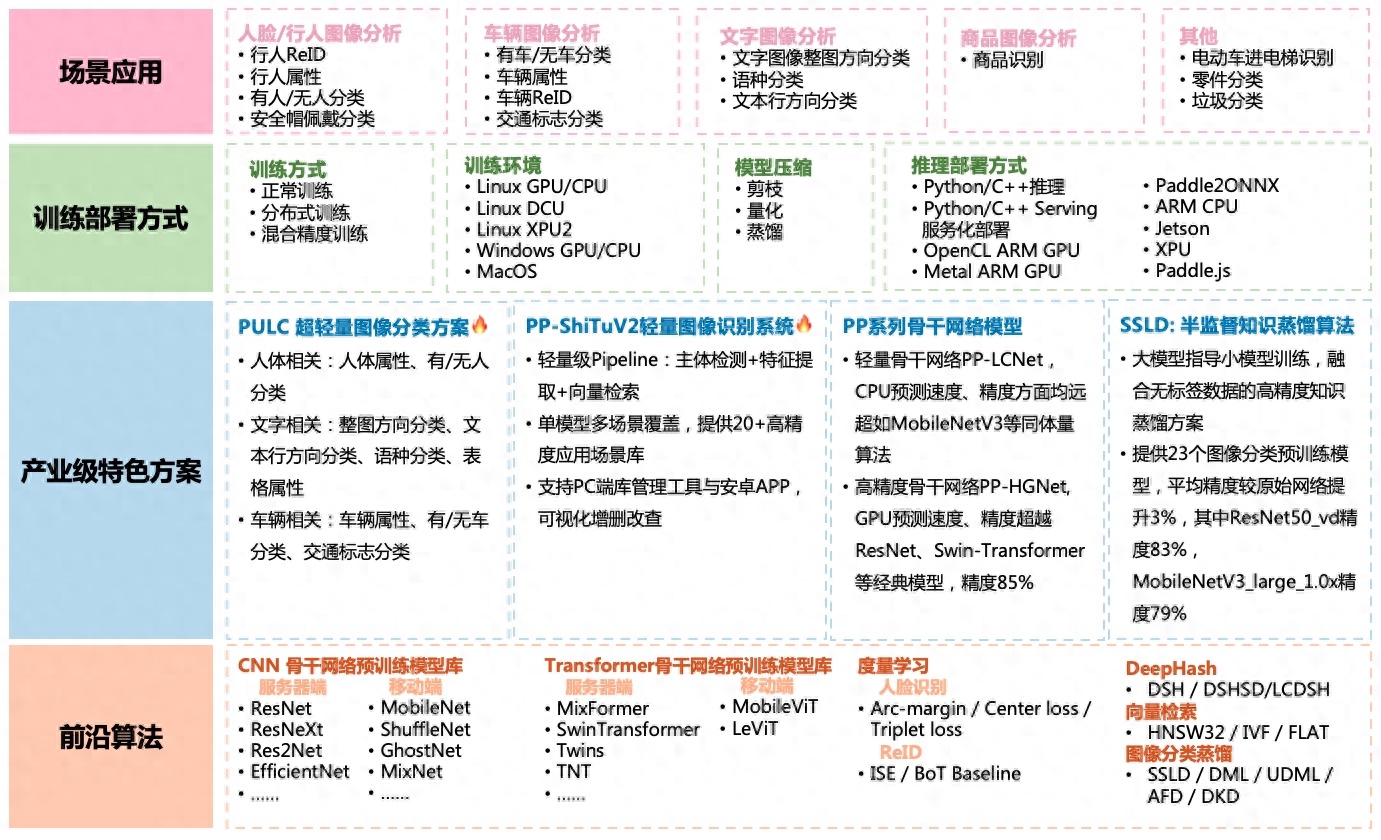
飞桨图像识别套件PaddleClas是飞桨为工业界和学术界所准备的一个图像识别和图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
特性
PaddleClas支持多种前沿图像分类、识别相关算法,发布产业级特色骨干网络PP-HGNet、PP-LCNetv2、 PP-LCNet和SSLD半监督知识蒸馏方案等模型,在此基础上打造PULC超轻量图像分类方案和PP-ShiTu图像识别系统。


kraken - 一个由Python开发的OCR软件,主要用于非拉丁字符的识别。
Github:https://github.com/mittagessen/kraken
kraken 官网
kraken是一个由Python开发的OCR软件,主要用于非拉丁字符的识别。它支持从右到左书写的语言,例如阿拉伯语,也支持从上到下书写的语言,例如日语。可以从命令行运行OCR识别PDF、JPEG和TIFF等格式的文件。
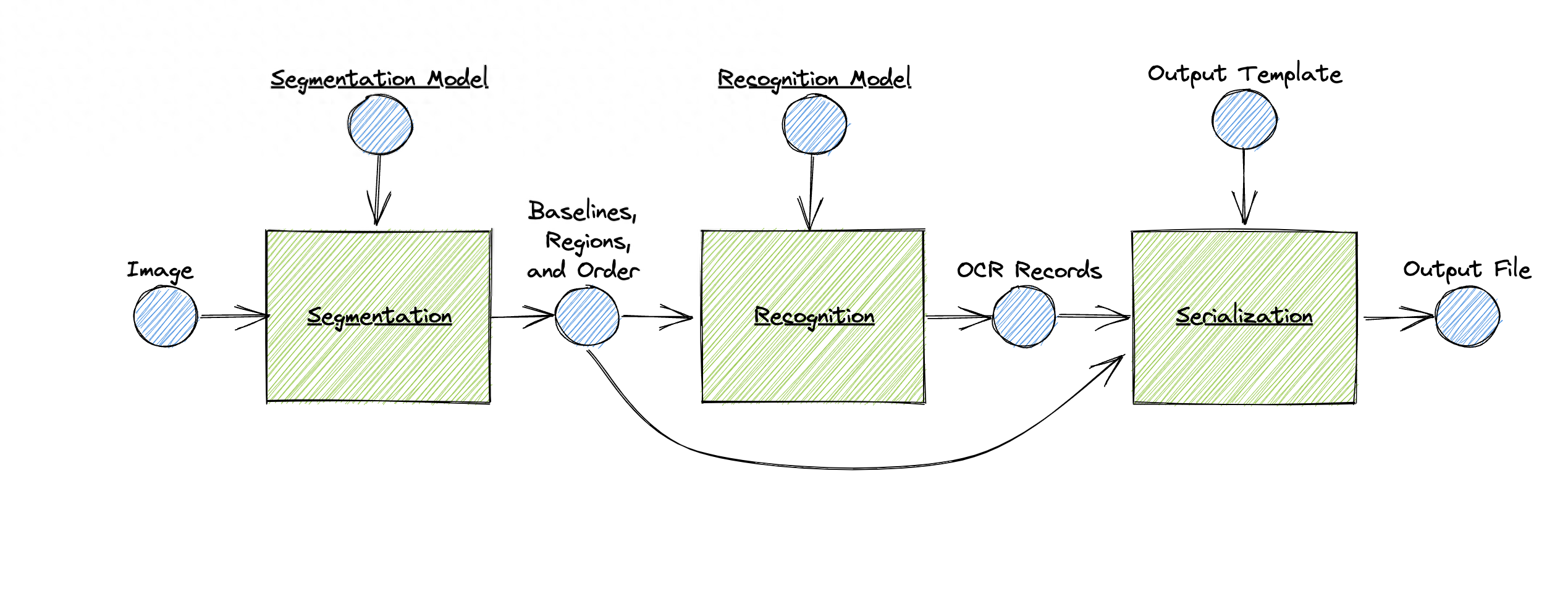
它的特点包括:
- 支持自定义训练的布局分析和字符识别
- 支持从右到左, 自上而下的识别
- 提供ALTO、PageXML、abbyyXML和hOCR 格式输出
- 能够识别单词边界框,支持字符剪切
- 多脚本识别支持
- 模型文件的公共存储库
- 动图识别网络架构
EasyOCR- 基于机器学习(CRNN)实现OCR功能。
Github :https://github.com/JaidedAI/EasyOCR
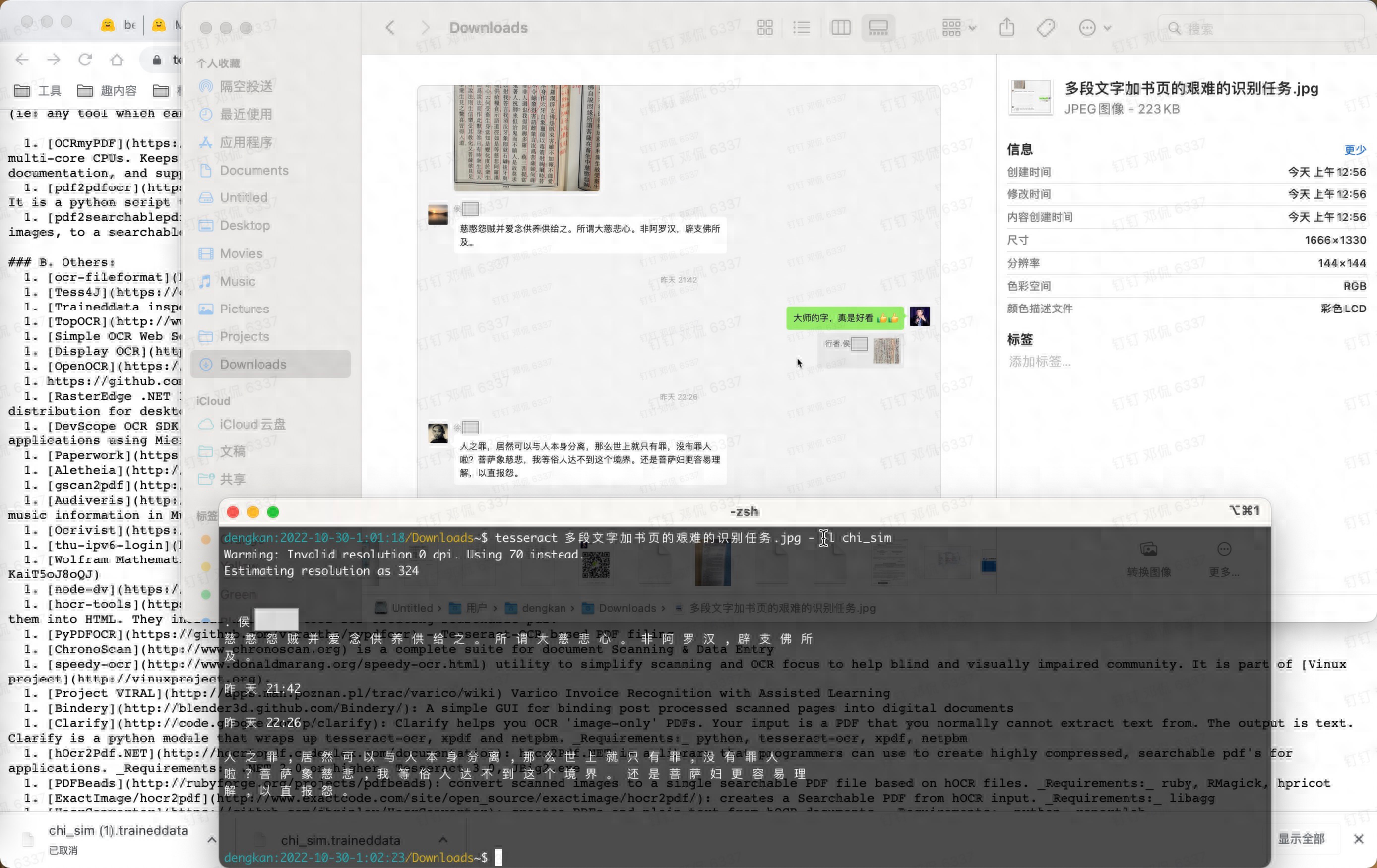
EasyOCR基于机器学习(CRNN)实现OCR功能。它能够识别超过80种语言的文字,包括简体中文和繁体中文。它是使用python开发的,因此使用Python调用也非常简单。例如:
识别包含中文的图片
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # this needs to run only once to load the model into memory
reader.readtext('chinese.jpg', detail = 0)识别结果为:
['愚园路', '西', '东', '315', '309', 'Yuyuan Rd.', 'W', 'E']