













随着业务发展壮大,微服务越来越多,调用链路越来越复杂,需要快速建立链路跟踪系统,以及建立系统的可观测性,以便快速了解系统的整体运行情况。此时就非常推荐SkyWalking了,SkyWalking不仅仅是一款链路跟踪工具,还可以作为一个系统监控工具,还具有告警功能。使用简便、上手又快。真可谓快、准、狠。
本文主要介绍如何快速集成使用SkyWalking,从3个方面入手:原理、搭建、使用。

一、原理
1.概括
SkyWalking整体分为4个部分:探针采集层、数据传输和逻辑处理层、数据存储层、数据展示层。
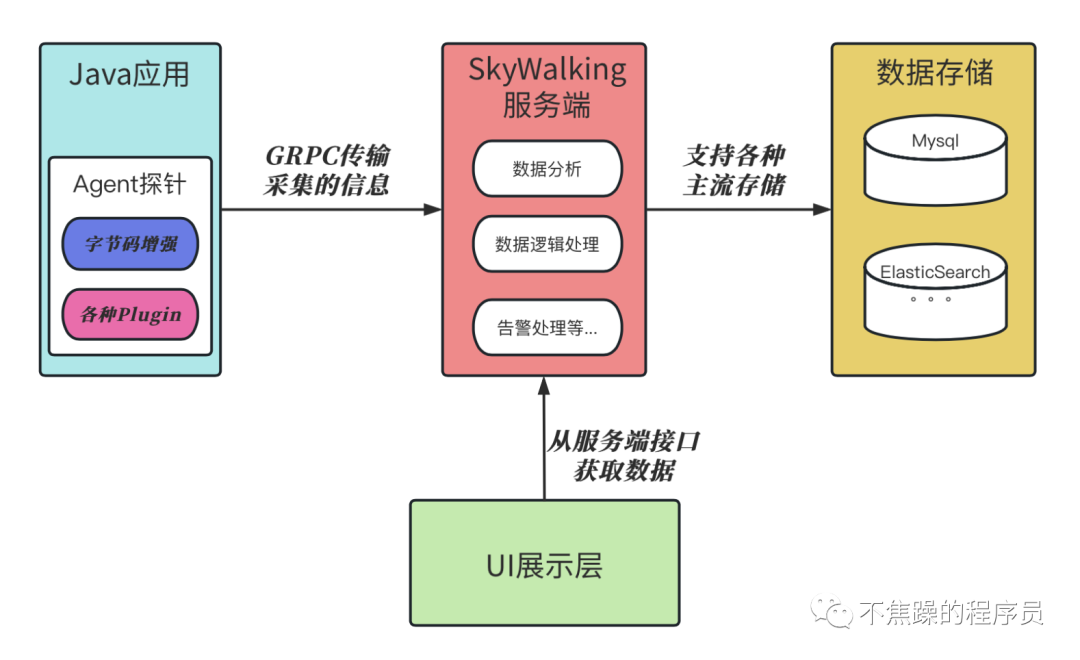
2.探针采集层
所谓探针,实际上是一种动态代理技术,只不过不是我们常用的Java代理类,而是在类加载时,就生成了增强过的代理类的字节码,增强了数据拦截和采集上报的功能。
探针技术是在项目启动时通过字节码技术(比如JavaAgent、ByteBuddy)进行类加载和替换,生成新的增强过的Class文件,对性能的影响是一次性的。
探针技术,因为在类加载时进行转换,增强了部分功能,所以会增加项目启动时间,同时也会增加内存占用量和线程数量。但是对性能影响不大,官方介绍在5% ~ 10%之间。

探针层在类转换时,通过各种插件对原有的类进行增强,之后在运行时拦截请求,然后将拦截的数据上报给Skywalking服务端。同时再加上一些定时任务,去采集应用服务器的基础数据,比如JVM信息等。
3.数据传输和逻辑处理层
SkyWalking探针层使用了GRPC作为数据传输框架,将采集的数据上报到SkyWalking服务端。
SkyWalking服务端接收数据后,利用各种插件来进行数据的分析和逻辑处理。比如:JVM相关插件,主要用于处理上报上来的JVM信息,数据库插件用来分析访问数据库的信息。然后在将数据存入到数据存储层。
4.数据存储层
SkyWalking的数据存储层支持多种主流数据库,可以自行到配置文件里查阅。我推荐使用ElasticSearch,存储量大,搜索性能又好。
5.数据展示层
SkyWalking 通过 Rocketbot 进行页面UI展示。可以在页面的左上角看到这个可爱的Rocketbot。

二、搭建
知道了原理,搭建就很轻松了,使用SkyWalking其实就3个步骤:
- 搭建数据存储部件。
- 搭建SkyWalking服务端。
- 应用通过agent探针技术将数据采集上报给SkyWalking服务端。
1.搭建数据存储部件
SkyWalking支持多种存储方式,此处推荐采用Elasticsearch作为存储组件,存储的数据量较大,搜索响应快。
快速搭建Elasticsearch:
- 安装java:yum install java-1.8.0-openjdk-devel.x86_64
- 下载Elasticsearch安装包:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-17-1
- 修改elasticsearch.yml文件的部分字段:cluster.name,node.name,path.data,path.logs,network.host,http.port,discovery.seed_hosts,cluster.initial_master_nodes。将字段的值改成对应的值。
- 在Elasticsearch的bin目录下执行./elasticsearch启动服务。
- 访问http://es-ip:9200,看到如下界面就代表安装成功。
{
"name": "node-1",
"cluster_name": "my-application",
"cluster_uuid": "GvK7v9HhS4qgCvfvU6lYCQ",
"version": {
"number": "7.17.1",
"build_flavor": "default",
"build_type": "rpm",
"build_hash": "e5acb99f822233d6ad4sdf44ce45a454xxxaasdfas323ab",
"build_date": "2023-02-23T22:20:54.153567231Z",
"build_snapshot": false,
"lucene_version": "8.11.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}2.搭建SkyWalking服务端
搭建SkyWalking服务端只需要4步:
(1)下载并解压skywalking:https://archive.apache.org/dist/skywalking/8.9.0/
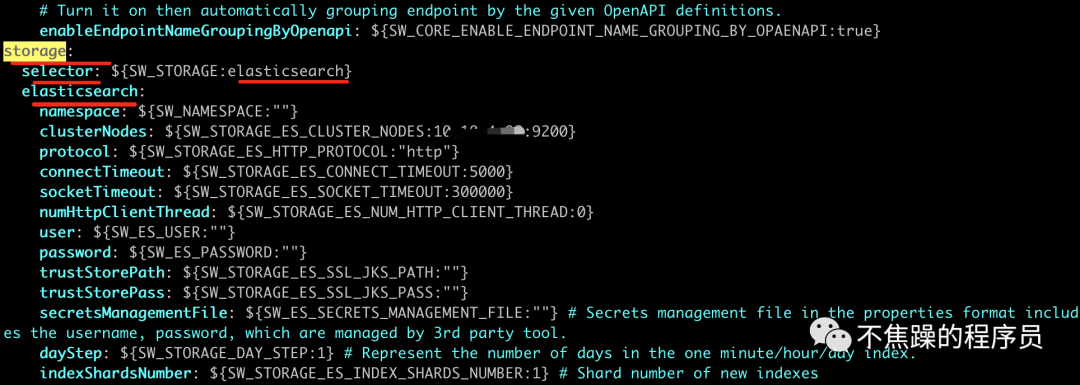
(2) 进入到安装目录下的修改配置文件:config/apllication.yaml。将存储修改为elasticsearch。
(3)进入到安装目录下的bin目录,执行./startup.sh启动SkyWalking服务端。
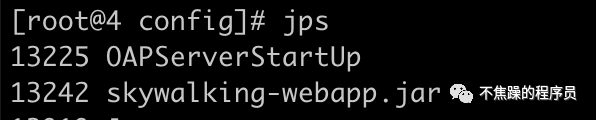
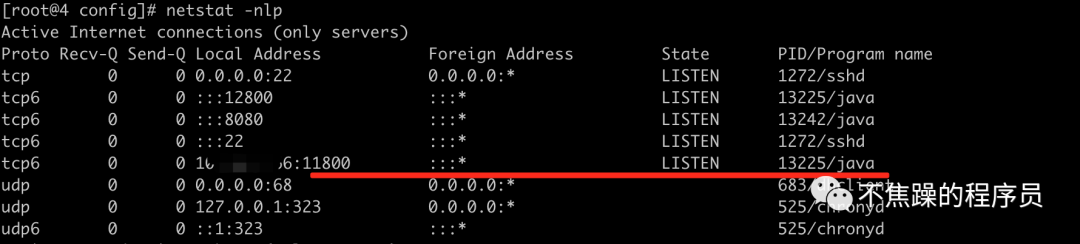
(4)此时使用jps命令,应该可以看到如下2个进程。一个是web页面进程,一个是接受和处理上报数据的进程。如果没有jps命令,那自行查看下是否配置了Java环境变量。同时访问http://ip:8080应该可以看到如下界面。
3.应用采集上报数据
应用采集并且上报数据,直接使用agent探针方式。分为以下3步:
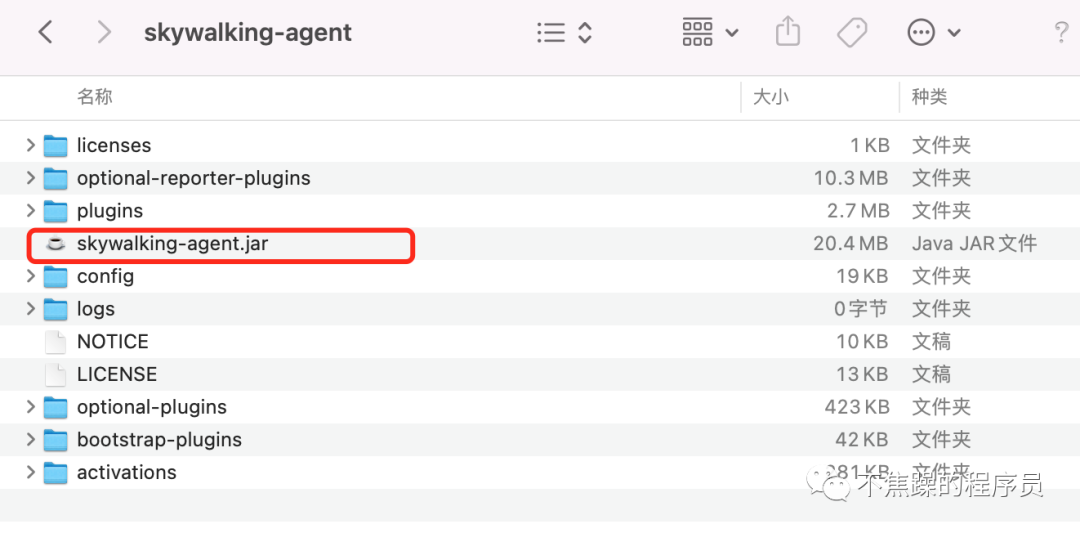
(1)下载解压agent:https://archive.apache.org/dist/skywalking/java-agent/8.9.0/,找到skywalking-agent.jar
(2)添加启动参数
应用如果是jar命令启动,则直接添加启动参数即可:
java -javaagent:/自定义path/skywalking-agent.jar -Dskywalking.collector.backend_service={{agentUrl}} -jar xxxxxx.jar 此处的{{agentUrl}}是SkyWalking服务端安装的地址,再加上11800端口。比如:10.20.0.55:11800。
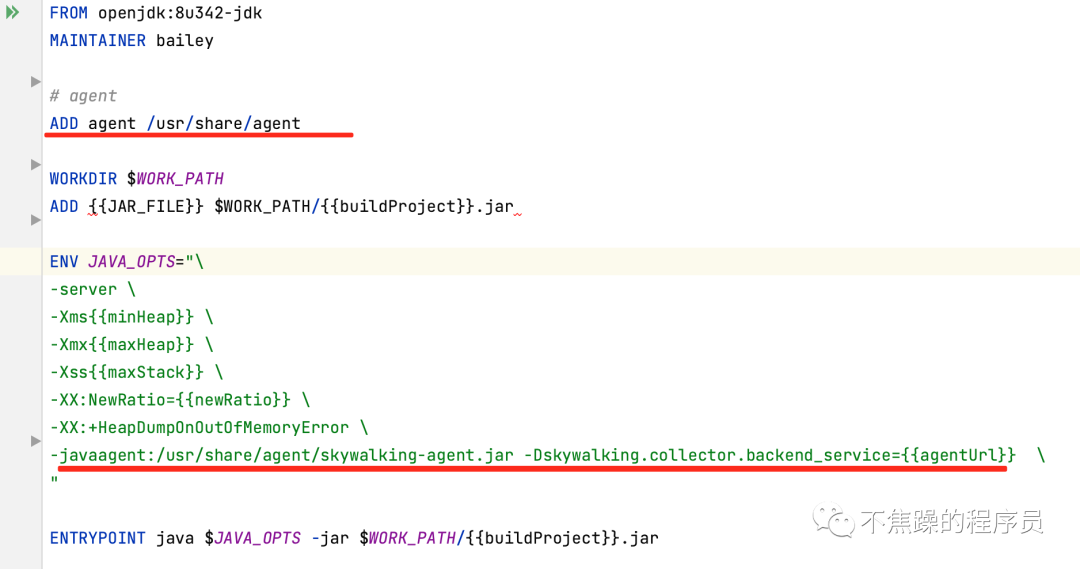
应用如果是Docker镜像的部署方式,则需要将skywalking-agent.jar打到镜像里,类似下图:
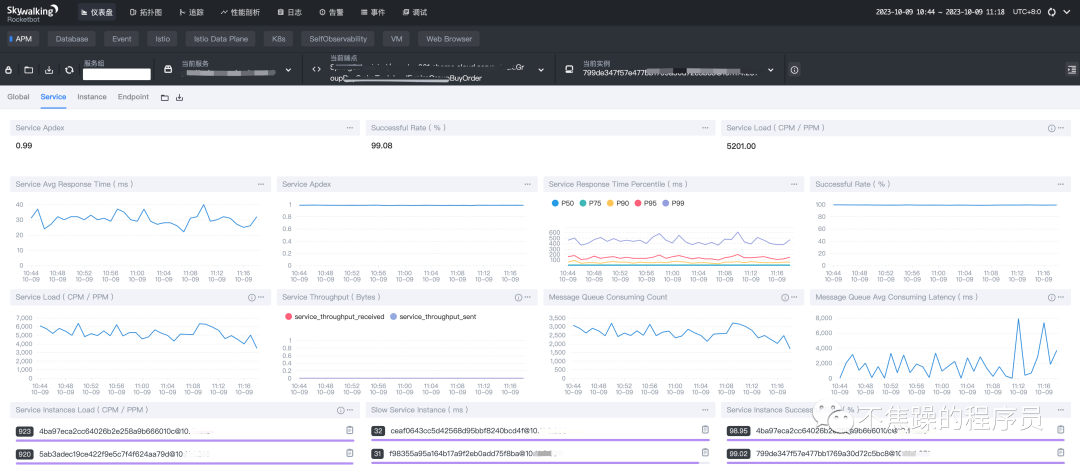
(3)启动项目后,即可看到监控数据,如下图:
三、UI页面使用
原理和搭建已经介绍完毕,接下来快速介绍UI页面的功能。下图标红的部分是重点关注区域:
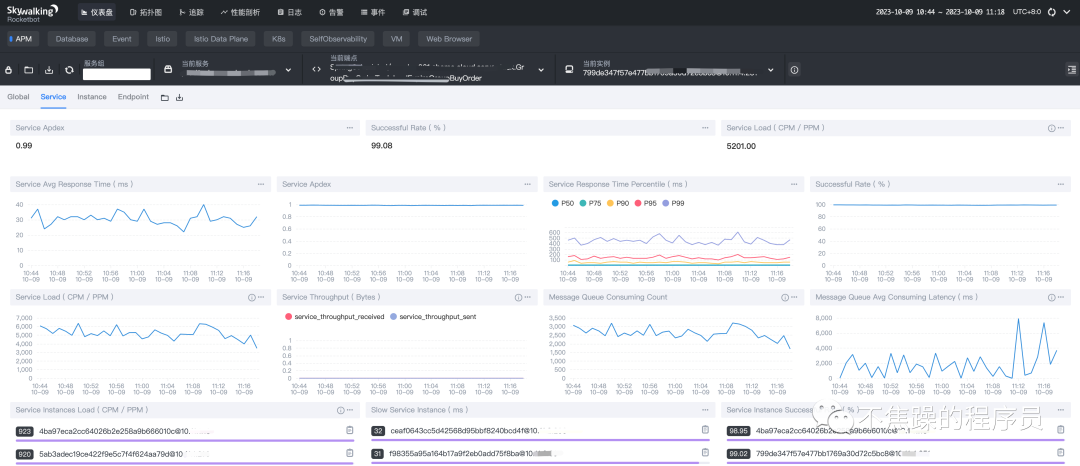
1.仪表盘
- APM:以全局(Global)、服务(Service)、服务实例(Instance)、端点(Endpoint)的维度展示各项指标。
- Database:展示数据库的各项指标。
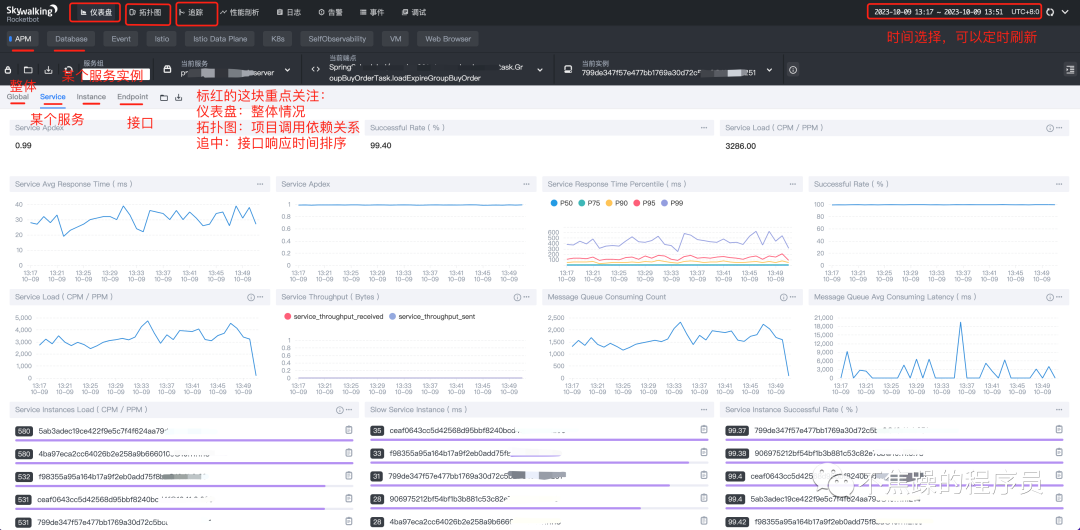
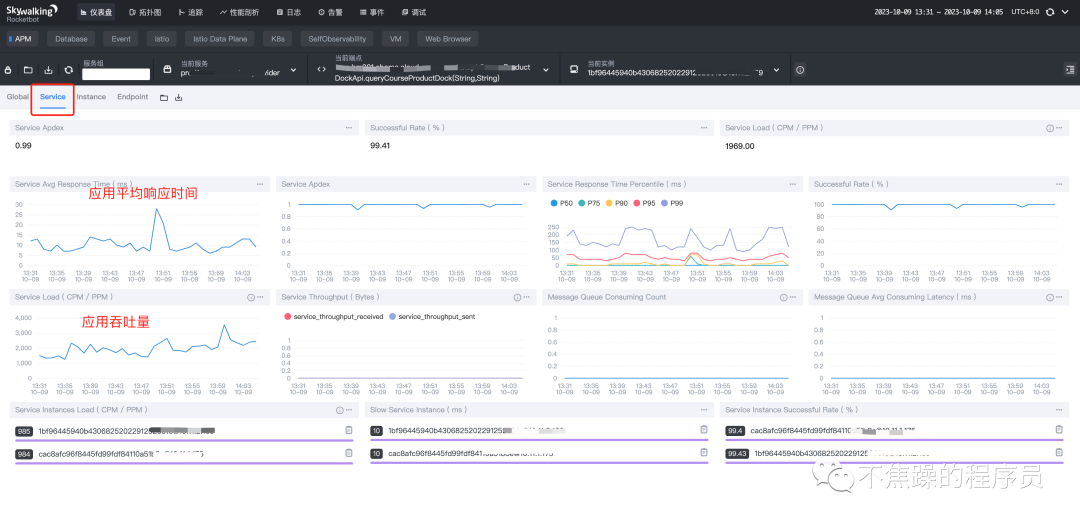
- 服务(Service):某个微服务,或者某个应用。
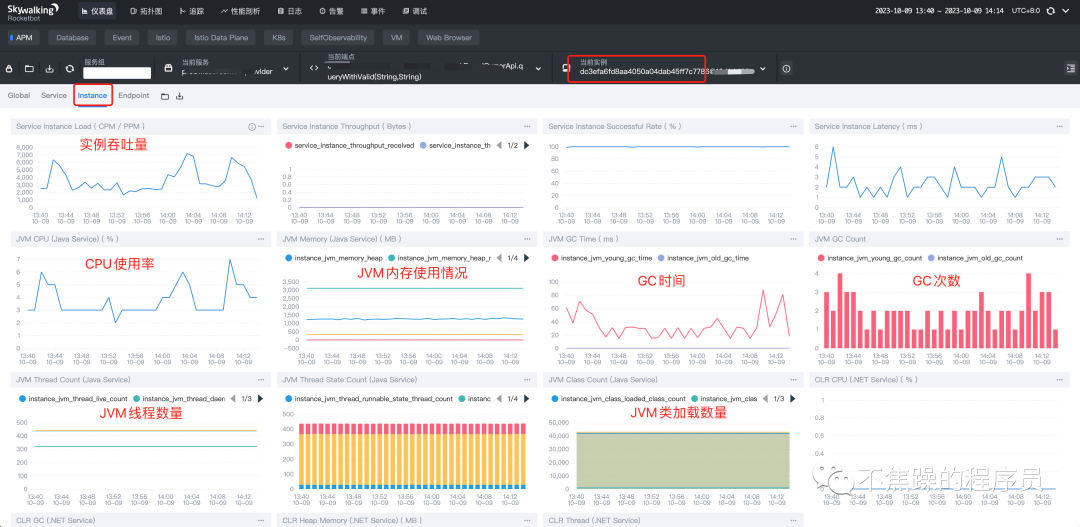
- 服务实例(Instance):某个微服务或者某个应用集群的一台实例或者一台负载。
- 端点(Endpoint):某个Http请求的接口,或者 某个接口名+方法名。
2.拓扑图
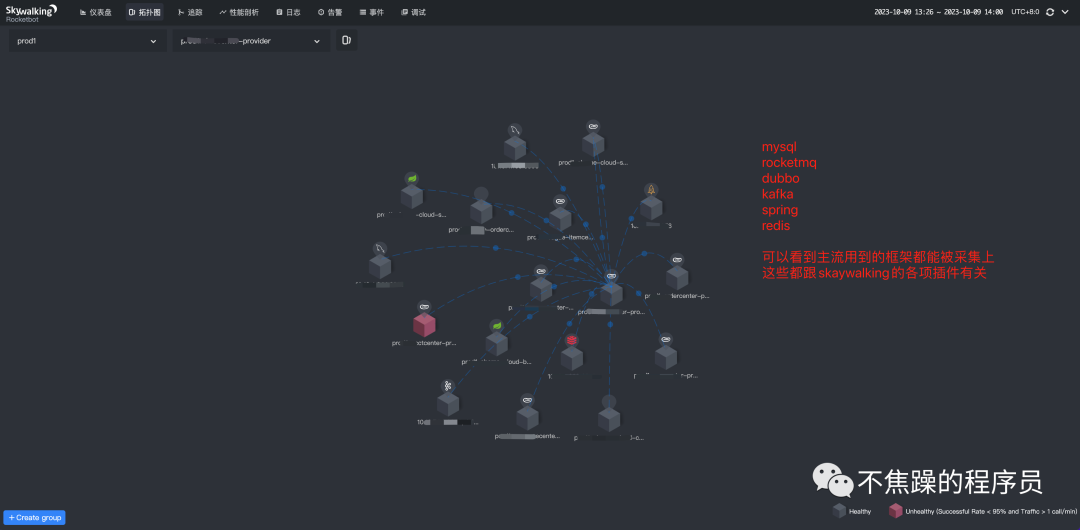
3.追踪
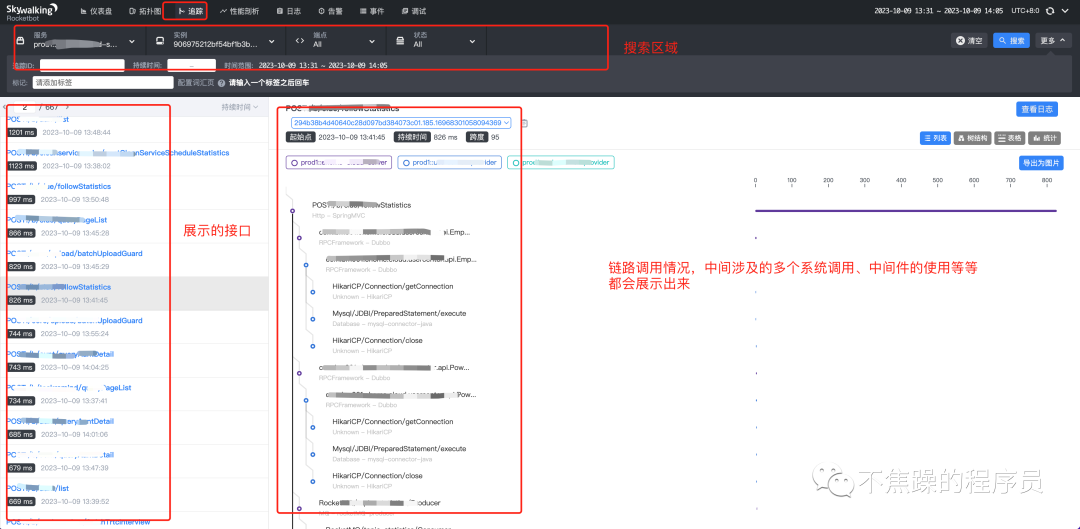
总结
本文主要从3个方面入手:原理、搭建、使用,介绍如何快速集成使用SkyWalking。核心重点:
- SkyWalking其实就4部分组成:探针采集上报、数据分析和逻辑处理、数据存储、数据展示。安装使用简单、易上手。
- 探针技术是SkyWalking的基石,说白了就是:在类加载时进行字节码转换增强,然后去拦截请求,采集上报数据。
- UI页面的使用,多用用就熟悉了。























