导读
传统客服领域,具有大量依赖人工,数据密集等特点。面对大量的用户提问,人工客服需要根据用户的问题,从大量数据中找出与用户问题相关的数据,再组织语言进行回答。响应时间受限于人工客服的工作经验和业务场景的复杂程度,耗时较长时会严重影响用户的购物体验。
智能客服,是指借助Large Language Model(LLM)拥有的出色的自然语言处理与理解能力,融合私有数据构建特定场景的智能客服系统,为人工客服提供有力支持,提高人工客服的服务效率与服务质量。
1.应用场景与系统框图
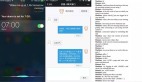
用户看到的商品展示界面有详细的商品参数和质检报告,商品参数包含商品的基本信息,质检报告为转转质检部门出具的权威检测报告,方便用户了解二手商品的真实状况。
 商品详情页
商品详情页
用户在转转App上与客服的谈话内容大致可分成:商品参数咨询,质检报告咨询,优惠活动咨询,平台政策咨询,售后咨询,闲聊问候六大类。人工客服在遇到用户咨询商品参数和质检报告时,需要从种类繁多的商品详情和质检项中找到客户问题相关的项,再给出用户相应的解答。从用户点击商品的全部数据中搜索答案是比较耗时的,需要人工客服对用户咨询的商品参数较为了解,以便快速响应用户的问题。
让我们利用ChatGPT的自然语言处理与理解能力,辅助人工客服实现从大段的商品详情和质检报告中找出用户感兴趣的项,并解答用户的问题吧。
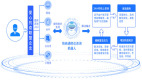
整个智能客服系统的框图如下图所示:用户发起人工咨询对话,首先分配客服,用户的点击商品信息同步给客服,然后智能客服系统给出辅助信息,客服决定采纳与否,给用户提供解答,一次会话结束。
 系统框图
系统框图
智能客服系统分为三个模块:用户问题分类模块,知识筛选模块和ChatGPT智能客服模块。一期系统只有ChatGPT智能客服模块,二期和三期优化增加了用户问题分类模块和知识筛选模块。让我们一起来看看它的创建流程吧。
2.搭建基于ChatGPT的智能客服助手
2.1 ChatGPT原理
ChatGPT为Open AI开发的LLM,GPT的全称是Generative Pre-Trained Transformer。ChatGPT属于GPT系列的预训练语言模型,GPT系列模型包括GPT-1,GPT-2和GPT-3,GPT系列模型的参数量见下表。
模型 | 发布时间 | 层数 | 参数量 |
GPT-1 | 2018-06 | 12 | 1.17亿 |
Bert | 2018-10 | 12 | 1.15亿 |
GPT-2 | 2019-02 | 48 | 15亿 |
GPT-3 | 2020-05 | 96 | 1750亿 |
模型规模的指数级扩张,带来了模型理解能力质的跃升。但是模型的理解并没有与用户的意图做对齐。ChatGPT以GPT-3为基础,训练网络采用了提示学习(Prompt Learning)和人类反馈的强化学习来训练网络,使模型可以听从指令,输出对人类有用,可信和无害的回答[1-2]。提示学习属于元学习的一种,通过将任务信息告诉模型,训练网络学会学习(learn to learn)。这种方式将NLP各种任务都归一为文本生成任务。提示学习挖掘模型本身已经学到的知识,指令(Prompt)可以激发模型的补全能力。而基于人类反馈的强化学习,根据人类对预测内容的偏好,训练了一个奖励函数,将这个反应人类偏好的奖励函数作为强化学习的奖励,通过最近策略优化(proximal policy optimization)训练网络策略使奖励最大。
2.2 Prompt设计
ChatGPT好比一个知识库,想要从这个知识库获取我们需要的知识,需要清晰的指令。通过清晰指令告诉ChatGPT它要完成的工作是什么,以及要完成工作需要的详细步骤,同时给出一些简单的示例,可以帮助ChatGPT更好地理解并执行我们的指令。一个标准的指令由以下五部分组成:
(1)任务描述
(2)背景知识注入
(3)输出格式地约定
(4)举例说明,包括样例输入,样例输出
(5)给出输入数据
这里以转转智能客服为例,设计这个场景的Prompt:
现在你的身份是一个电商客服,请根据下面给出的商品信息和质检信息,回答用户的问题,回答问题时要根据商品信息和质检信息相关项给出精简的答案。商品参数:{$product_info},质检信息:{$quality_info}。
AI:请问您有什么问题要咨询的吗?
user:电池有维修更换吗?
AI:根据质检报告电池检测项,该电池由平台更换,更换电池品牌为全新海斯电池。
User:电池容量是多大?
整个Prompt可划分为四部分,第一部分介绍任务,第二部分做知识注入,变量product_info和quality_info分别对应商品详情和质检报告,第三部分做任务举例,第四部分给出用户问题。LLM具有few-shot学习能力,通过几个简单的例子告诉模型期待的答案是什么,可以引导LLM按照我们预期的方式完成任务。此时我们得到的ChatGPT的答复是电池容量为2815mAh。
这里以人工客服采纳智能客服建议的接纳度来衡量智能客服的服务质量。商品参数咨询问题的采纳度为20%,质检项咨询的采纳度为6.4%,而闲聊问候和优惠活动这种类型的咨询更偏好人工客服。基于ChatGPT的智能客服,用户问题的响应耗时在5-10s,人工客服的响应耗时在30s左右,智能客服的响应速度更快。ChatGPT API的调用按token收费。目前智能客服运行成本0.12元/会话。
3.智能客服系统二期优化之用户问题分类
不同类型的用户咨询,智能客服给出建议的采纳度也有较大差异。在商品参数咨询和质检项咨询问题上,智能客服意见的采纳度较高,帮助人工客服提高用户问题的响应速度。而对于闲聊问题等问题,智能客服给出的建议采纳度较低。
在ChatGPT智能客服模块前置一个用户问题分类模型,将分类结果为商品参数咨询和质检报告咨询的问题送至基于ChatGPT的智能客服系统,进一步降本增效。用户问题分类模型采用 Bert做文本分类任务。接下来简要介绍Bert分类在该场景的应用。
3.1 Bert简介
Bert为2018年谷歌提出的预训练语言模型[3],模型采用了Transformer的Encode端,基于多头自注意力机制捕获句子中的上下文信息。预训练阶段采用完形填空任务和上下句判断任务训练网络。应用于下游任务时,可采用CLS位的特征向量作为句向量,在网络后接入Linear层进行句子的分类。
 Bert结构图
Bert结构图
Bert模型在预训练阶段采用了33亿文本语料进行训练,网络对自然语言已有基本认知。基于Bert预训练模型,去微调下游任务,在很多领域都取得了很好的效果。
3.2 用户问题分类网络训练数据
人工标注用户问题分类的数据耗时较长,这里采用ChatGPT给出用户问题的分类,作为Bert 微调阶段的训练数据。
设计分类任务的Prompt:
请对用户问题进行文本分类,需要按照要求将用户的问题分类到:[ '商品参数咨询', '质检报告咨询','售后咨询', '平台政策', '活动优惠', '闲聊问候']类别中。
User:这个手机内存是多大?
AI:商品参数咨询
User:电池有拆修吗?
AI:质检报告咨询
User:下单后从哪里发货?
AI:售后咨询
User:支持7天无理由退货吗?
AI:平台政策
User:你好
AI:闲聊问题
User:谢谢!
AI:闲聊问候
User:待机时长是多久?
3.3训练分类模型
训练数据集准备好后,开始微调Bert。网络的输入为句子,文本经过分词器进行分词后,得到切分好的token序列。Bert输入token的最大长度不得超过512,对于超长的序列,进行截断操作。在文本的头尾加入”[cls]”和”[sep]”后,会进行padding操作,方便网络进行批量化训练。根据Bert的字典将处理好的序列映射为对应的id,就可以送入网络进行训练。由于自注意力无法捕捉位置信息,Bert在token embedding上叠加了位置embedding。
 Bert输入组成
Bert输入组成
接下来定义模型的结构,代码如下:
Import torch.nn as nn
from transformers import BertModel
class Classifier(nn.Module):
def __init__(self,bert_model_path,num_classes):
super(Classifier,self).__init__()
self.bert = BertModel.from_pretrained(bert_model_path)
self.dropout = nn.Dropout(0.1)
self.fc = nn.Linear(768, num_classes)
def forward(self,tokens,masks):
_, pooled_output = self.bert(tokens, attention_mask=masks,return_dict=False)
x = self.dropout(pooled_output)
x = self.fc(x)
return xBert模型产出的特征维度为768,经过Dropout层随机mask一定比例的权重,送至Linear层,将特征向量映射到Label空间,num_classes对应了Label空间的维度,这里我们要分类的种类有6类。训练采用AdamW优化器,学习率为1e-5,训练了10轮。测试集上准确率76.6%,f1 0.754。商品参数咨询的f1 0.791,质检报告咨询的f1 0.841。
 图片
图片
训练loss与准确率
通过前置的用户问题分类模型,帮助智能客服系统筛选掉了一些采纳度低,适合人工客服回答的问题,智能客服系统响应用户会话的成本降到了0.033元/会话,运行费用降低了72.5%。
4.智能客服系统三期优化之商详和质检项相关知识筛选
搭建智能客服时Prompt包含了商品的全部商品详情和质检项信息,并未考虑这些项与用户问题的相关性。比如用户问题是电池相关的,做商品详情和质检项的知识注入时,可以只注入电池相关的知识。token数量越长,ChatGPT处理所需时间也会越长。通过筛选与用户问题相关的商详和质检项做知识注入,可以进一步压缩完成一次会话所需token的数量,降低智能客服的运行成本的同时,也提升智能客服的响应速度。
Bert计算两个句子相似度时,把两个句子同时输入Bert,进行信息交互,计算速度是比较慢的,无法事先计算好句向量,语义搜索时比较慢。Sentence-Bert借鉴了孪生网络的框架,将两个句子送入两个Bert模型中,这两个模型的参数是共享的,网络结构[4]如下图所示。Bert网络输出每个token的embedding向量,通过pooling策略生成句向量的表征。论文中分别用"[CLS]"位,平均池化,最大池化生成句向量的表征,实验表明pooling策略采用平均方式效果最好。得到的句向量计算两者的余弦相似性,用来衡量这两个句子的相似度。
 SBert结构图
SBert结构图
假设用户问客服“电池具体多少?”,客服拿到的用户点击商品的详情:95新 iPhone 12 128G 紫色 移动5G 联通5G 电信5G 国行;网络制式:全网通;购买渠道:国行;保修情况:过保或小于30天;电池健康值:85%-90%;系统版本:iOS 16.5.1;充电次数:562;SIM卡:支持双卡;来源:二手优品;IMEI:352***833;履约服务信息:真的官方验、7天无理由、一年平台质保、顺丰包邮、手机服务权益卡、寄存于长沙流转中心,现在下单预计8月17日送达;CPU型号:苹果 A14;电池容量:2815mAh;CPU主频:3.0GHz;解锁方式:面部识别;是否支持快充:支持;充电峰值功率:20W;分辨率:2532*1170;屏幕尺寸:6.1英寸;主屏材质:OLED;上市时间:2020-10;操作系统:iOS;屏幕类型:全面屏;后置摄像头:1200万像素+1200万像素;前置摄像头:1200万像素;摄像头总数:三摄像头(后二);机身重量:162g;机身尺寸:146.7*71.5*7.4mm;机身类型:直板。
客服拿到的用户点击商品的质检报告样例(省略部分质检项):外壳外观的情况-碎裂:无;外壳外观的情况-划痕:无;外壳外观的情况-磨损:无;外壳外观的情况-变形:无;外壳外观的情况-脱胶/缝隙:无;外壳外观的情况-外壳/其他:正常;外壳外观的情况-刻字/图:无;外壳外观的情况-磕碰/掉漆:无;摄像头外观的情况-闪光灯:正常;摄像头外观的情况-前置摄像头:正常;拆修浸液的情况-主板:无维修;拆修浸液的情况-机身:无维修更换;拆修浸液的情况-零件维修/更换:无维修更换;拆修浸液的情况-零件缺失:无缺失;拆修浸液的情况-浸液痕迹:无浸液痕迹;充电的情况-无线充电:正常;充电的情况-有线充电:正常;电池检测的情况-电池:无维修更换;包装及配件的情况-包装盒:1;包装及配件的情况-数据线:无;包装及配件的情况-充电器:无。
可以看到商品详情和质检项里只有少数项与用户问题相关,全部商详和质检项做知识注入会浪费很多token,导致ChatGPT需要在很长的序列里找相关信息回答用户问题,响应速度较慢,效率不高。这里通过Sentence-Bert计算用户问题和商详、质检项的句向量,根据余弦相似性挑选出最相关的top5商详和质检项做知识的注入,ChatGPT基于该商品电池相关的知识给出用户响应。Top5商详如下:电池容量:2815mAh,电池健康值:85%-90%,充电次数:562,充电峰值功率:20W,机身尺寸:146.771.57.4mm,top5质检项如下:充电的情况-有线充电:正常,电池检测的情况-电池:无维修更换,充电的情况-无线充电:正常,按键的情况-电源键:正常,包装及配件的情况-充电器:无。此时ChatGPT智能客服给出的响应为“电池容量为2815mAh”。原始知识注入token数为1228,经过相关知识筛选,token数降为132,token数下降了89%。
 知识筛选
知识筛选
5.总结
LLM具有的出色自然语言理解能力可以为各行各业赋能。传统人工客服领域具有高度依赖人工,数据密集等特点,大量未被充分处理的数据为LLM在这个场景落地提供了沃土。这里基于ChatGPT搭建的智能客服系统已上线,助力客服提高服务质量与服务效能。
6.参考文献
[1] Ouyang L , Wu J , Jiang X ,et al.Training language models to follow instructions with human feedback[J].arXiv e-prints, 2022.DOI:10.48550/arXiv.2203.02155.
[2] Brown T B , Mann B , Ryder N ,et al.Language Models are Few-Shot Learners[J]. 2020.DOI:10.48550/arXiv.2005.14165.
[3] Devlin J , Chang M W , Lee K ,et al.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.DOI:10.48550/arXiv.1810.04805.
[4] Reimers N , Gurevych I .Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks[J]. 2019.DOI:10.18653/v1/D19-1410.
关于作者
王安,资深NLP算法专家,负责搜索场景的用户意图理解,基于ChatGPT的智能客服的落地,在文本分类,实体识别,关系配对,问答场景有丰富落地经验。微信号:tiantian_375699720,欢迎建设性交流。