大家好,我是Echa。
最近有一部分做前端、后端、甚至还有运维粉丝们私信小编问道,用什么工具可以随时知道服务器资源使用情况怎么样,有时候网络访问加载很慢,应用程序性能如何,能扛住多少用户访问量等等,为了彻底搞清楚这系列的问题,小编百忙之中(白天也要上班),只能晚上在全文搜索资源,希望能一一解决粉丝们的需求。
今天小编给大家盘点了15个免费又实用的监控开源项目,总有一款符合大家的需求,更希望能对大家所有帮助。通过监控系统来跟踪监控服务器的性能、网络流量、应用程序的性能以及用户使用情况,可以帮助我们更好的了解IT环境运行状态,为系统运维,调优提供支撑。
掌握一些好的监控工具可以为我们更好的跟踪服务器状态,持续优化系统提供最佳的解决方案。接下来跟大家一一介绍这15个免费又实用的监控开源系统。
全文大纲
- Zabbix - 一个流行的开源监控解决方案
- Prometheus - 一个基于时间序列数据库的开源监控系统
- Grafana - 一个支持多平台、可分析、可视化的开源平台
- Nagios - 一个强大的开源工具,用于监控系统、网络和基础设施
- Netdata -一个用于实时监控系统和应用程序的性能和运行状况的轻量级开源监控工具
- Icinga - 一个开源的网络监控系统
- ELK Stack - 结合了Elasticsearch、Logstash和Kibana三种开源工具
- OpenNMS - 一个开源网络管理应用程序工具
- Cacti - 一个基于Web的网络监控工具
- Collectd - 一个可执行的守护进程工具
- InfluxDB- 一个能够处理高写入和高查询负载的时间序列数据库
- Sensu - 一个开源的监控事件管道,提供自动化的监控工作流程系统
- Telegraf - 一个用于收集、处理、聚合和编写指标的代理,用于收集和发送各种系统指标工具
- Logstash - 是ELK Stack的一个重要组成部分,充当数据处理的管道。
- Fluentd - 一个数据采集和分析的开源工具,可用于建立统一的日志基础设施
Zabbix - 一个流行的开源监控解决方案
传送门:https://www.zabbix.com/

Zabbix 官网
Zabbix是另一个流行的开源监控解决方案,可以用于监控网络、服务器、应用程序等。该工具功能强大,可以有效地管理复杂网络,让运维人员能够详细了解和控制整个基础设施的性能。虽然Zabbix的整个界面不够简练,但Zabbix强大的模板功能可以用来简化整个监控设置。
Zabbix 全方位监控
Zabbix 是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。
zabbix能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题。
zabbix由2部分构成,zabbix server与可选组件zabbix agent。
zabbix server可以通过SNMP,zabbix agent,ping,端口监视等方法提供对远程服务器/网络状态的监视,数据收集等功能,它可以运行在Linux,Solaris,HP-UX,AIX,Free BSD,Open BSD,OS X等平台上。
Prometheus - 一个基于时间序列数据库的开源监控系统
Github:https://github.com/prometheus
Prometheus 官网
Prometheus 是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
Promethus有以下特点:
- 支持多维数据模型:由度量名和键值对组成的时间序列数据
- 内置时间序列数据库TSDB
- 支持PromQL查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义
- 支持HTTP的Pull方式采集时间序列数据
- 支持PushGateway采集瞬时任务的数据
- 支持服务发现和静态配置两种方式发现目标
- 支持接入Grafana
另外,可以通过集成Grafana,提高Prometheus的可视化能力。
Prometheus 可视化截图
Prometheus 可视化后台
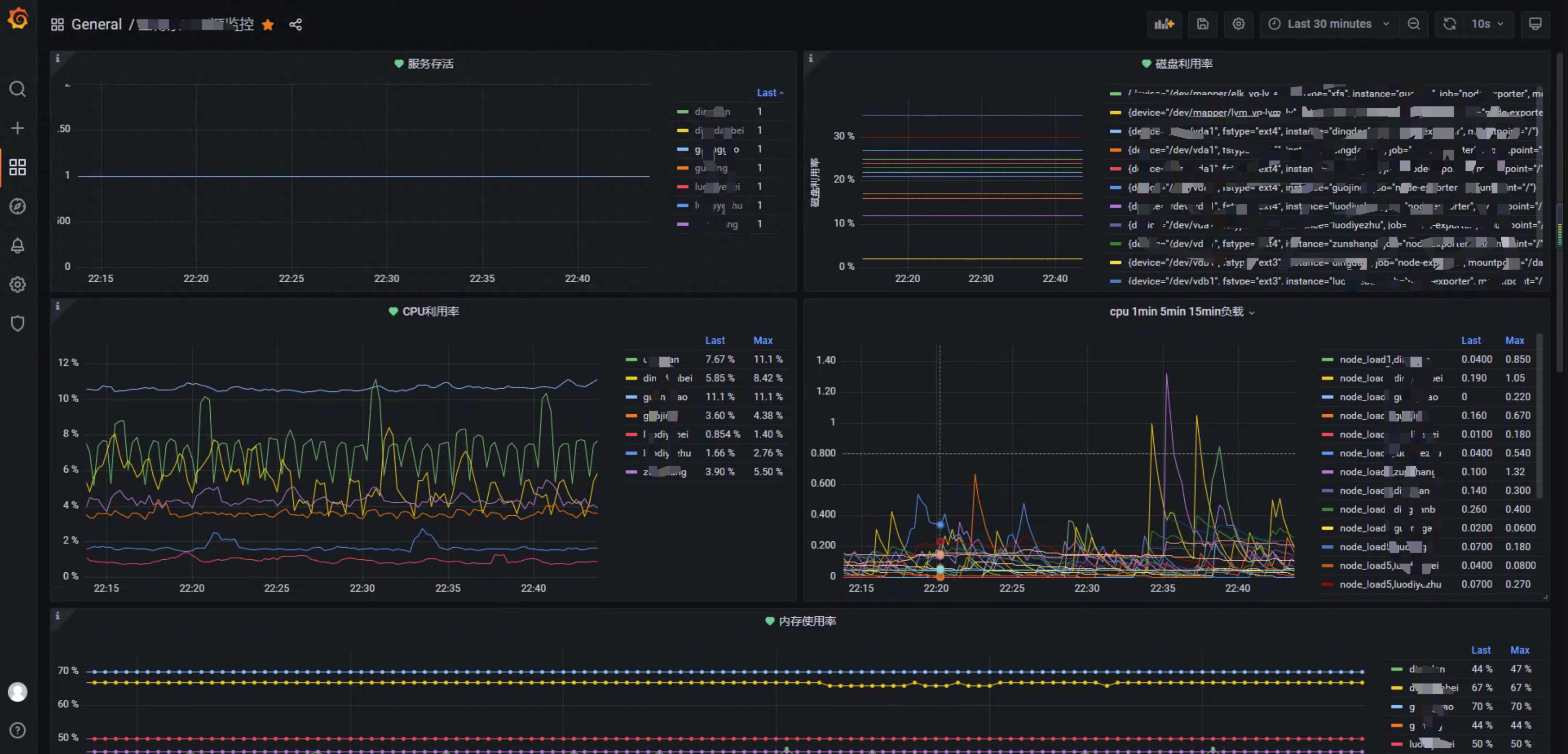
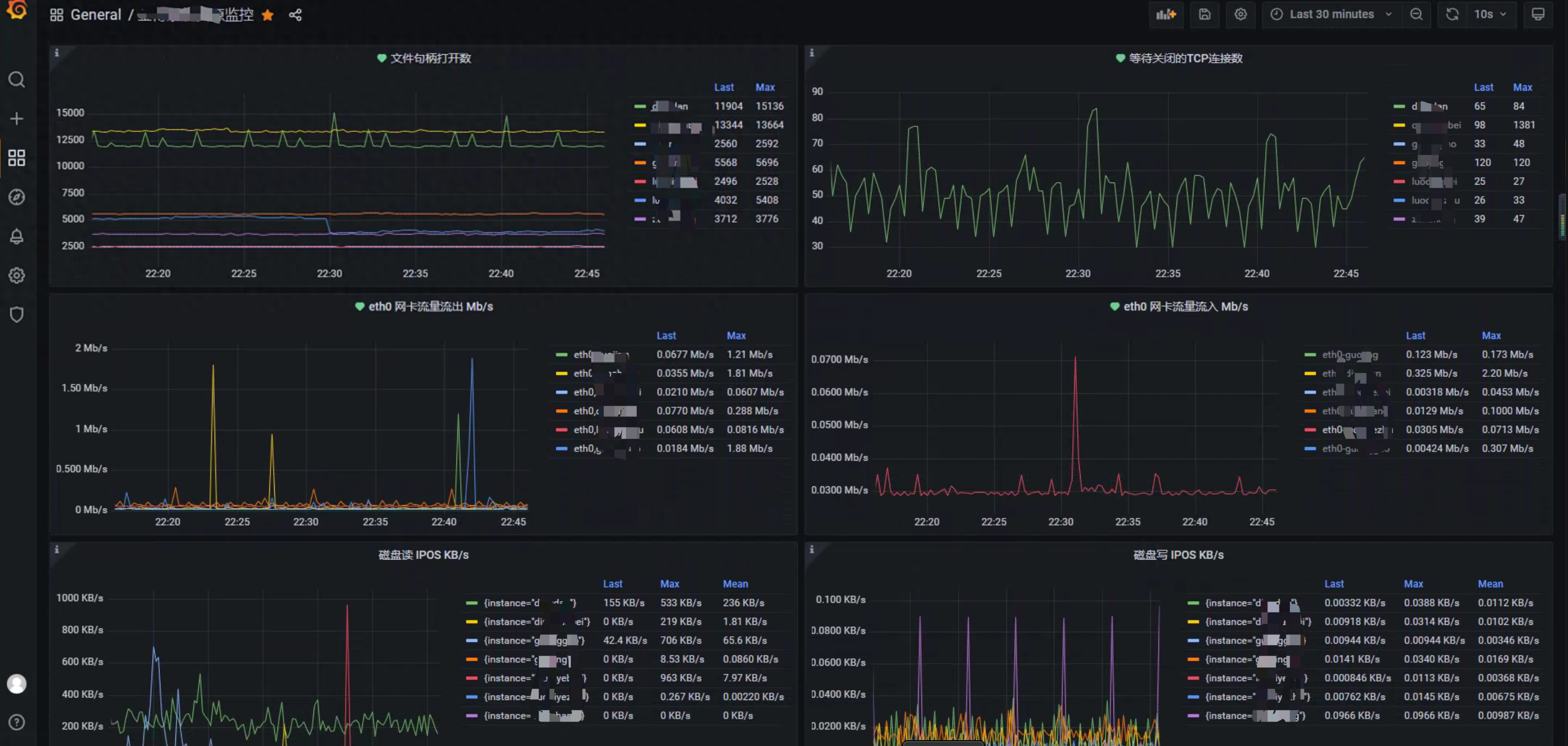
Grafana - 一个支持多平台、可分析、可视化的开源平台
Github:https://github.com/grafana/
Grafana 官网
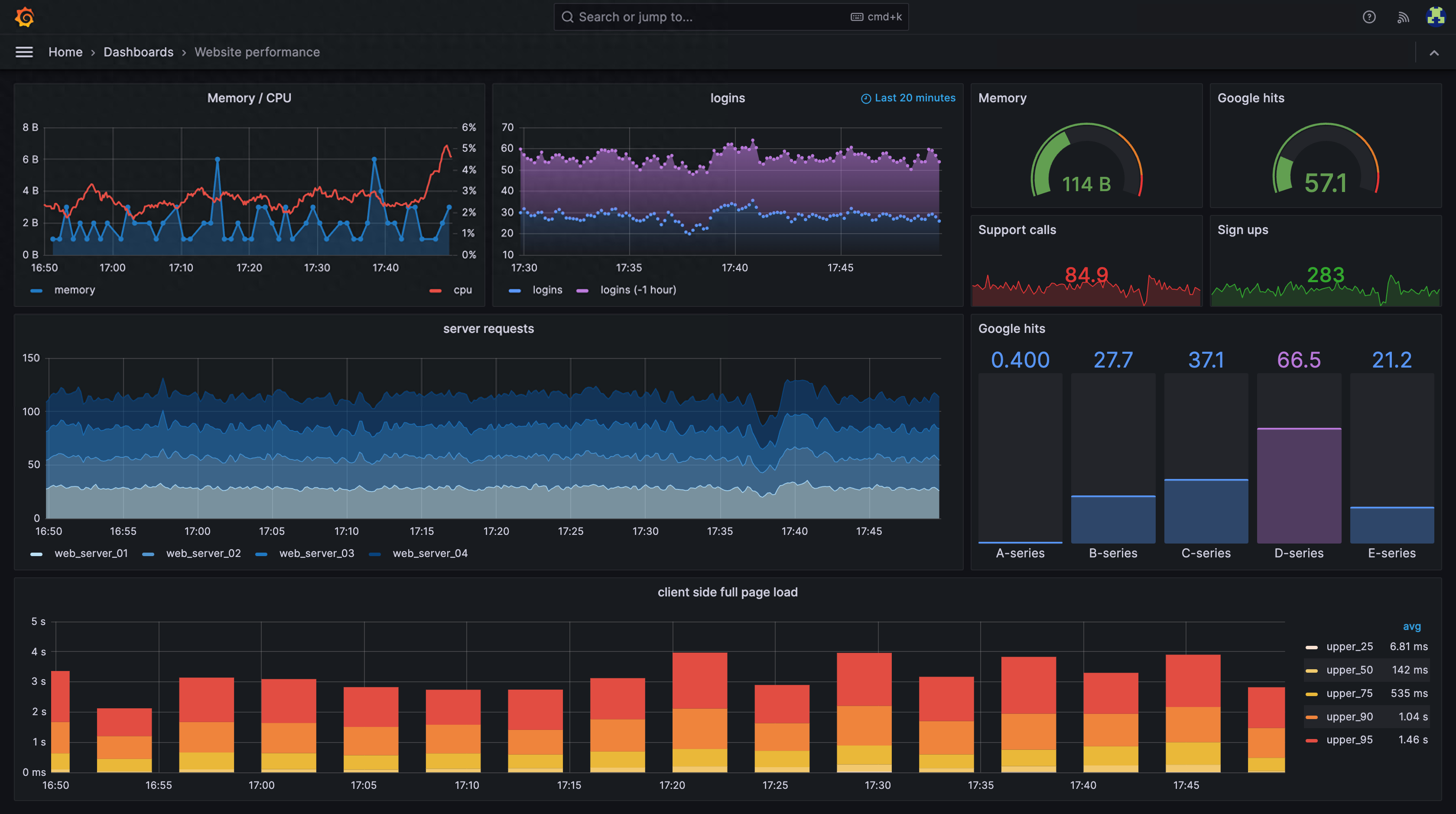
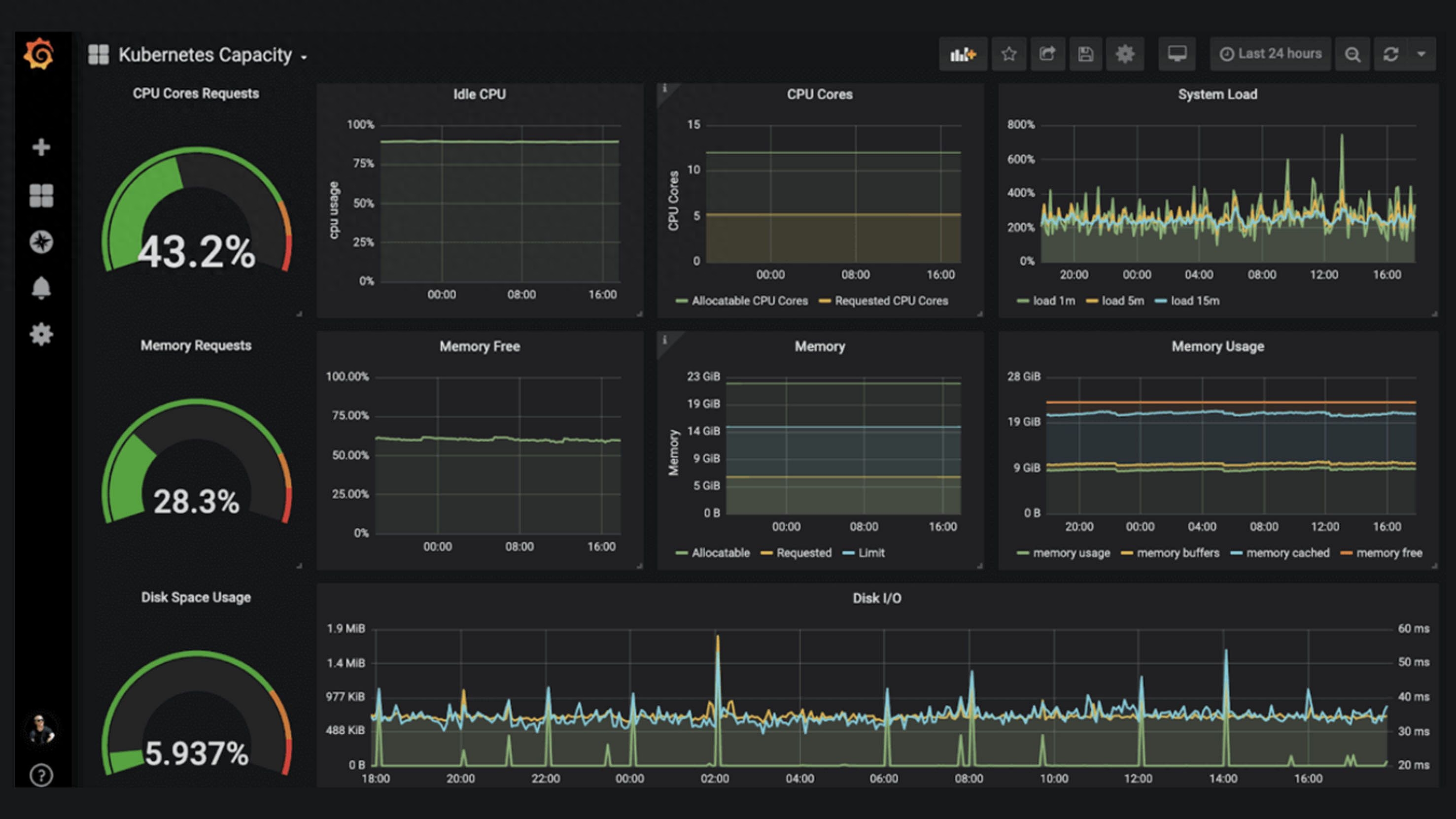
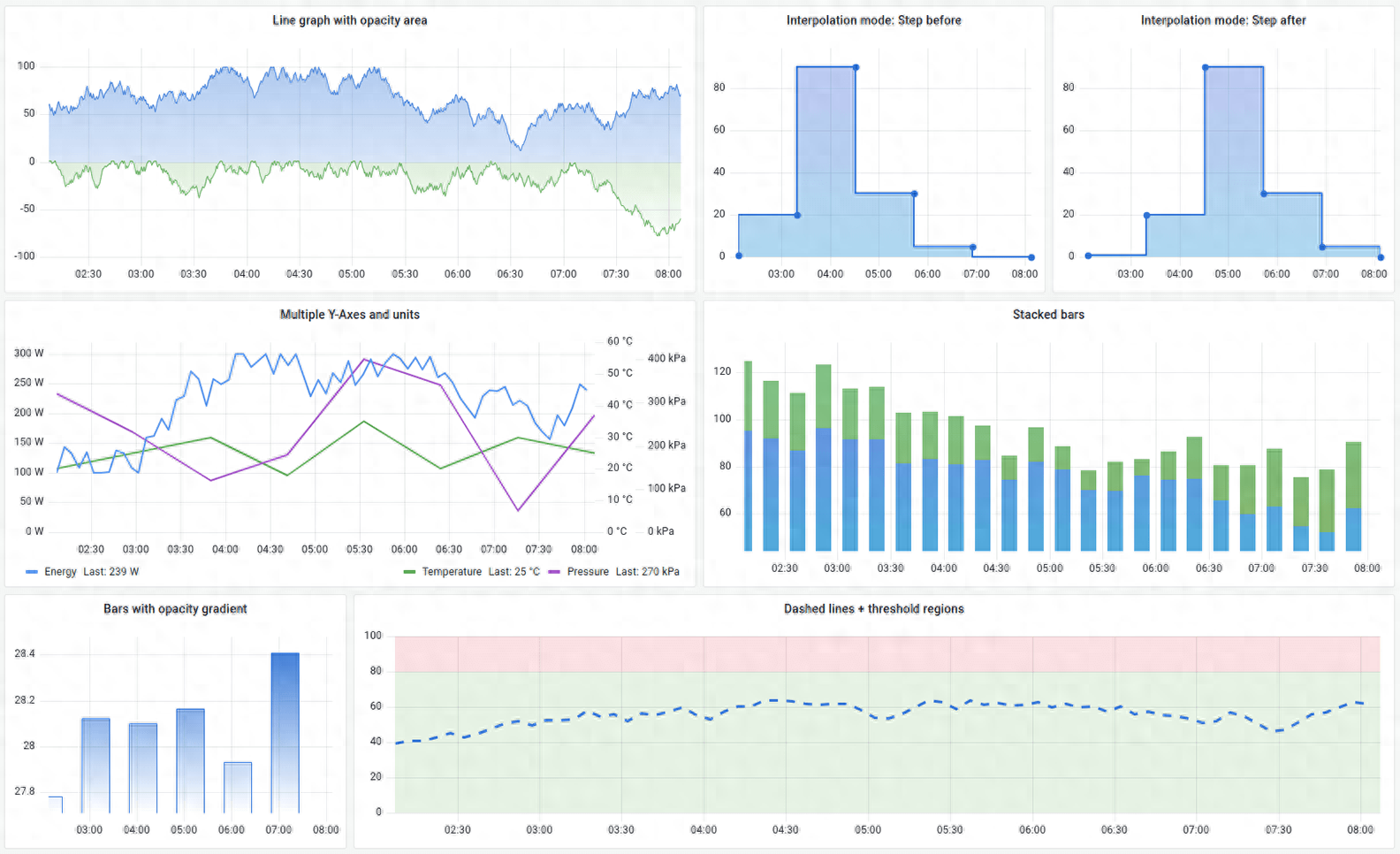
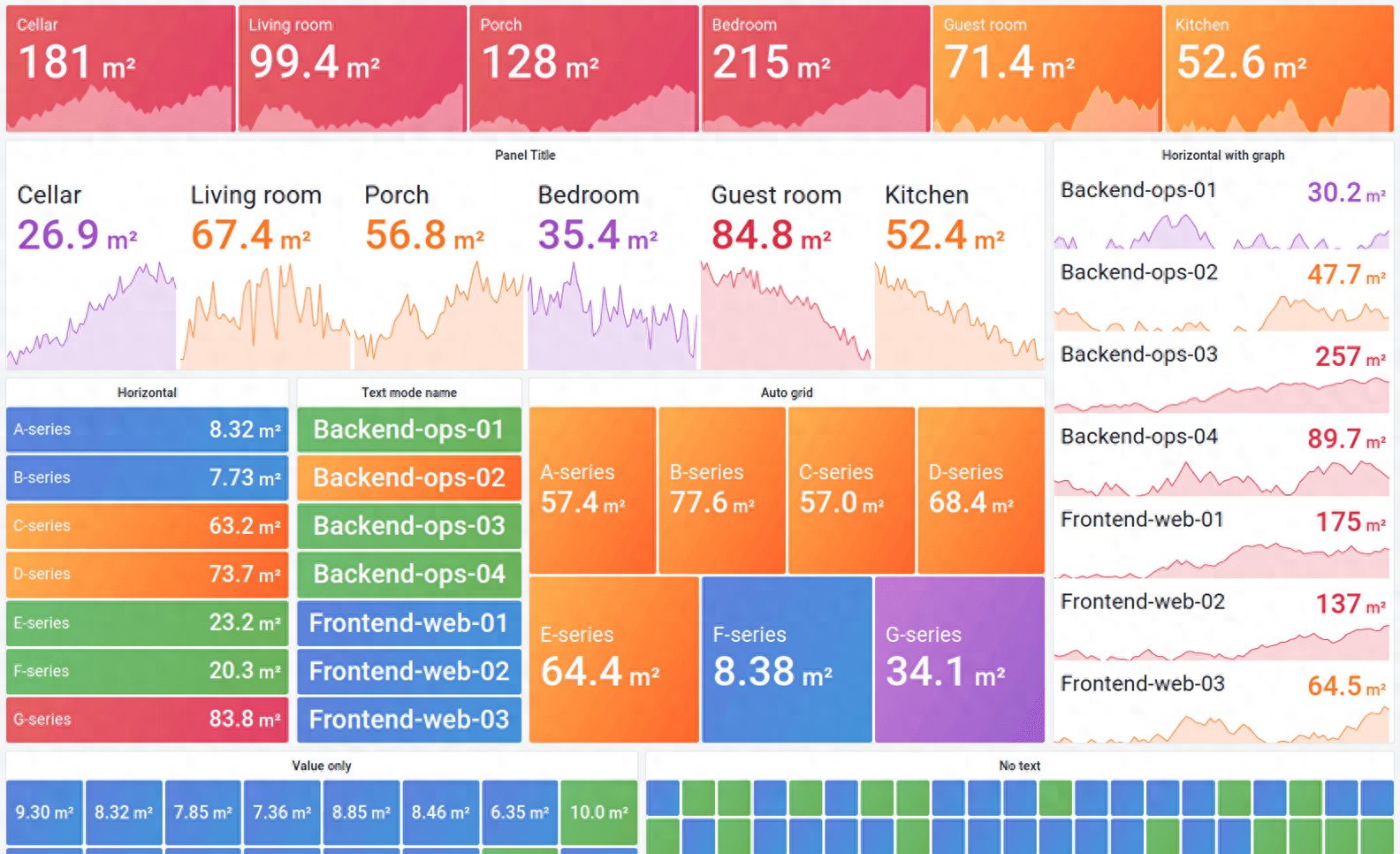
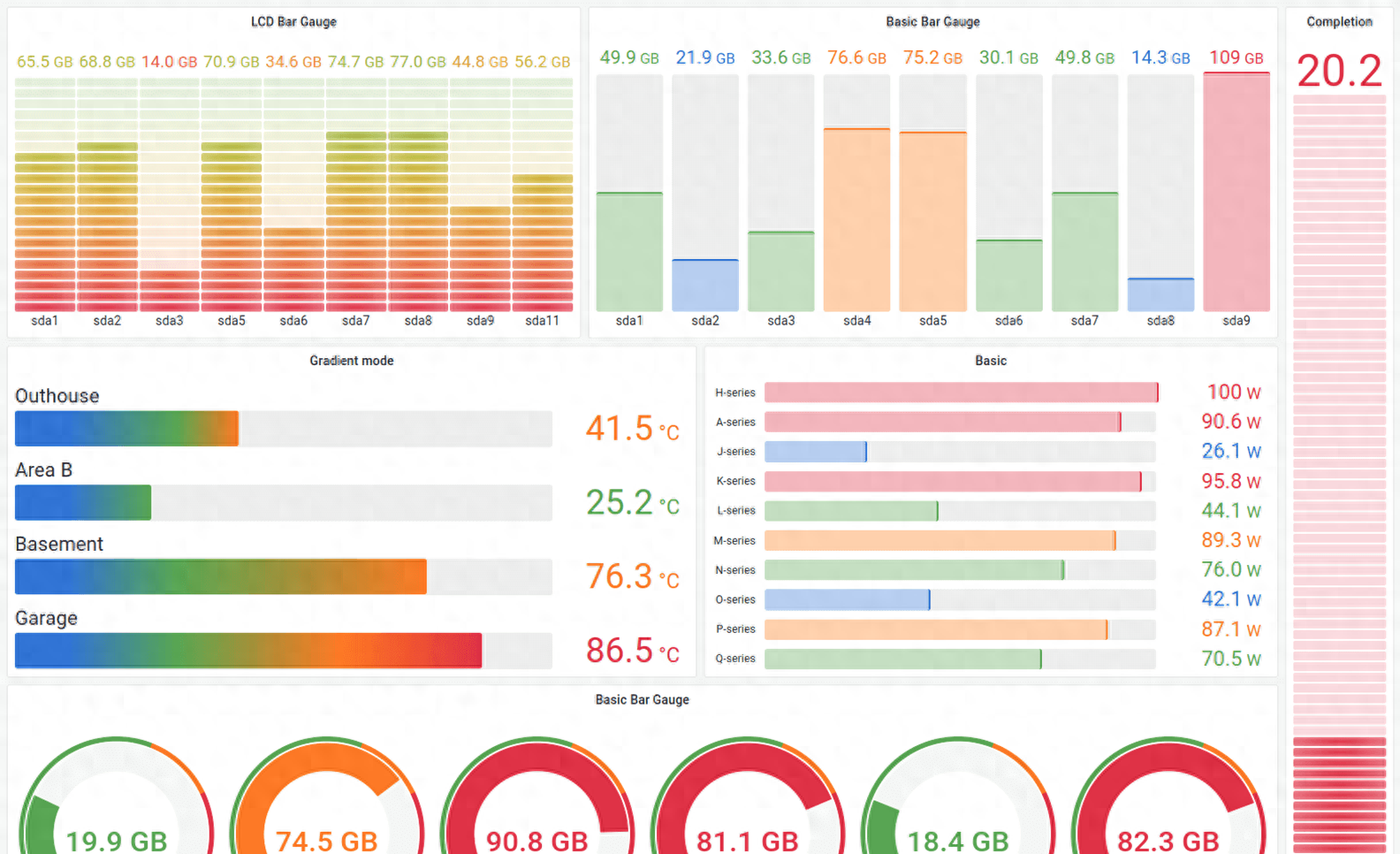
Grafana是一个支持多平台、可分析、可视化的开源平台,经常与Prometheus等监控工具结合使用。它支持基于监控数据创建美观、直观的仪表盘。
Grafana可以将应用服务器的响应时间、并发数、CPU指标、内存指标等监控数据转化为可视化图表,使运维人员更容易掌握运行趋势或者系统问题。
Grafana 可视化截图
Nagios - 一个强大的开源工具,用于监控系统、网络和基础设施
传送门:https://www.nagios.org/
Nagios 官网
Nagios是一款开源的免费网络监视工具,能有效监控Windows、Linux和Unix的主机状态,交换机路由器等网络设备,打印机等。在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。
Nagios 用于监控系统、网络和基础设施。它是监控工具的鼻祖,它的历史可以追溯到1999年。这个强大的开源工具提供了包括对系统、网络和基础设施的监控。Nagios可以持续监控服务器,跟踪服务器存在的潜在问题,在潜在问题转变成为严重问题之前及时提醒运维人员。Nagios的主要优势在于它的可扩展插件库和个性化定制能力,Nagios的插件库可以显著扩展工具的功能。但是,Nagios的学习曲线有些陡峭,对于初学者来说可能是一个缺点。
特性
1) 命令(Commands)
“命令”用于定义Nagios如何执行某特定的监控工作。它是基于某特定的Nagios插件定义出的一个抽象层,通常包含一组要执行的操作。
2)时段(Time periods)
“时段”用于定义某“操作”可以执行或不能执行的日期和时间跨度,如工作日内的每天8:00-18:00等;
3)联系人和联系人组(Contacts and contact groups)
“联系人”用于定义某监控事件的通知对象、要通知的信息以及这些接收通知者何时及如何接收通知;一个或多个联系人可以定义为联系人组,而一个联系人也可以属于多个组;
4) 主机和主机组(host and host groups)
“主机”通常指某物理主机,其包括此主机相关的通知信息的接收者(即联系人)、如何及何时进行监控的定义。主机也可以分组,即主机组(host groups),一个主机可同时属于多个组;
5) 服务(Services)
“服务”通常指某主机上可被监控的特定的功能或资源,其包括此服务相关的通知信息的接收者、如何及何时进行监控等。服务也可以分组,即服务组(Service groups),一个服务可同时属于多个服务组;
Nagios 可视化截图
Nagios XI
Nagios Log Server
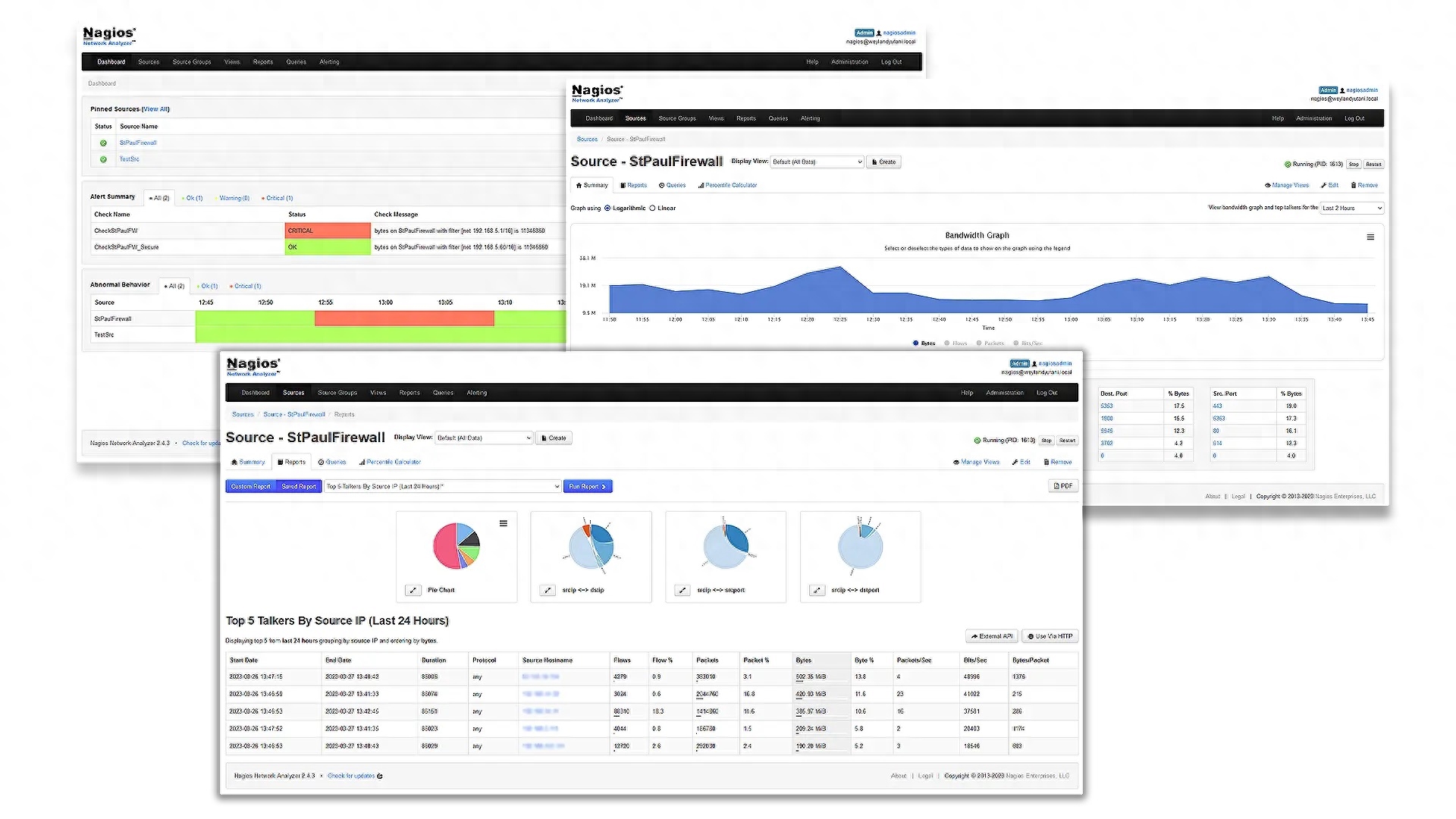
Nagios Network Analyzer
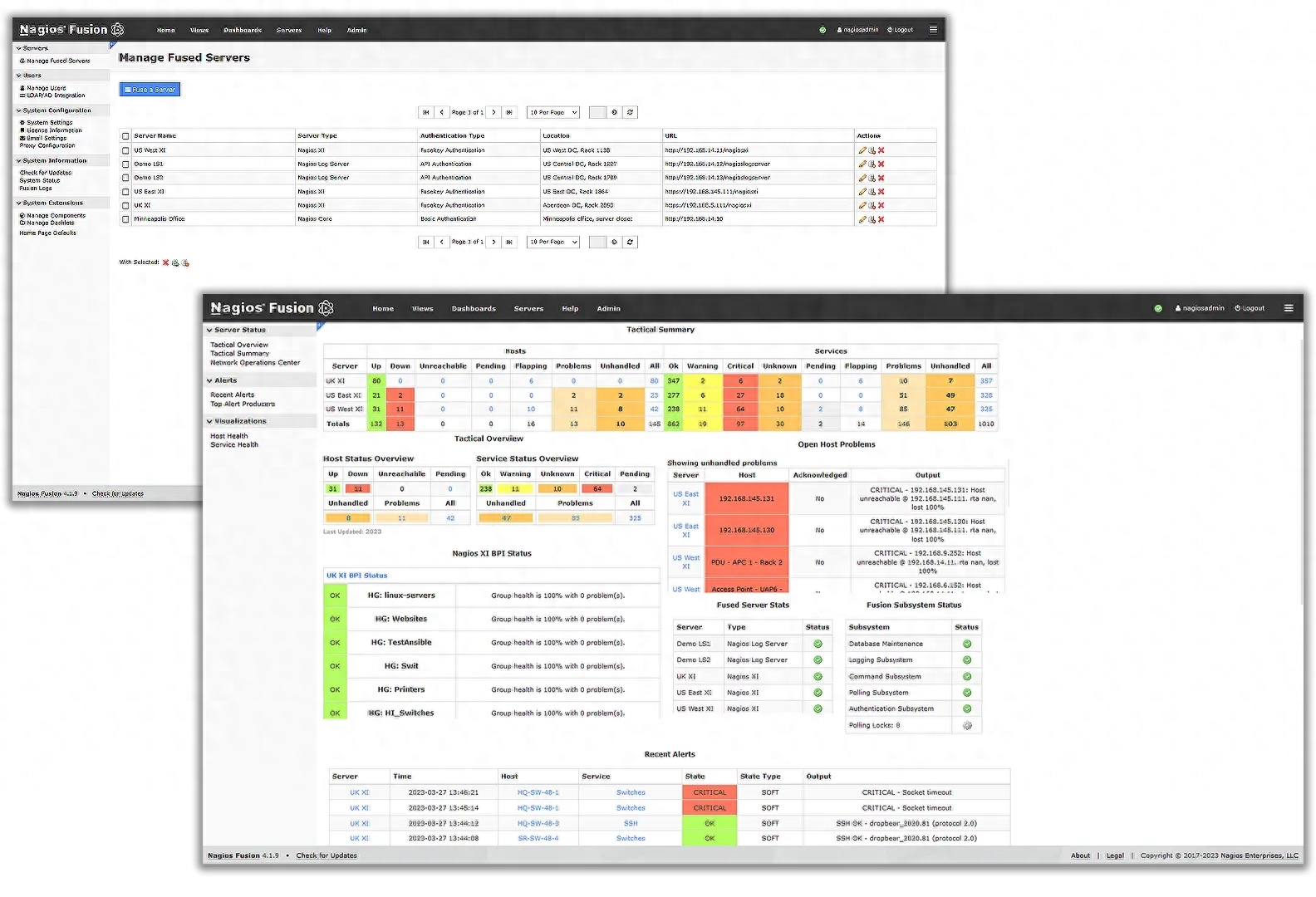
Nagios Fusion
Netdata -一个用于实时监控系统和应用程序的性能和运行状况的轻量级开源监控工具
Github : https://github.com/netdata/netdata
Netdata 官网
Netdata是一款Linux系统性能实时监控工具。是一个高度优化的Linux守护进程,可以对Linux系统、应用程序(包括但不限于Web服务器,数据库等)、SNMP服务等提供实时的性能监控。
Netdata用可视化的手段,将其被监控的信息展现出来,以便你清楚的了解到你的系统、程序、应用的实时运行状态,而且还可以与Prometheus,Graphite,OpenTSDB,Kafka,Grafana等相集成。
Netdata是免费的开源软件,目前可在Linux,FreeBSD和macOS以及从它们衍生的其他系统(例如Kubernetes和Docker)上运行。
Netdata特性
- 友好、美观的可视化界面
- 可自定义的控制界面
- 安装快速且高效
- 配置简单,甚至可零配置
- 零依赖
- 可扩展,自带插件API
- 支持的系统平台广
- 高实时性,Netdata及插件为C编写,资源占用及效率都符合要求
- 不占系统IO,除日志系统,Netdata不使用任何磁盘的IO资源,也可以通过配置文件禁用日志系统
- 不需要root权限
- 自带Web服务
- 安装便捷、开箱即用,不需要额外写任何配置
- 动态图表化显示
- 告警系统,通过配置文件,可以配置Netdata在某些指标达到阈值时进行告警
- 具体参考Netdata的GitHub以及官方文档。
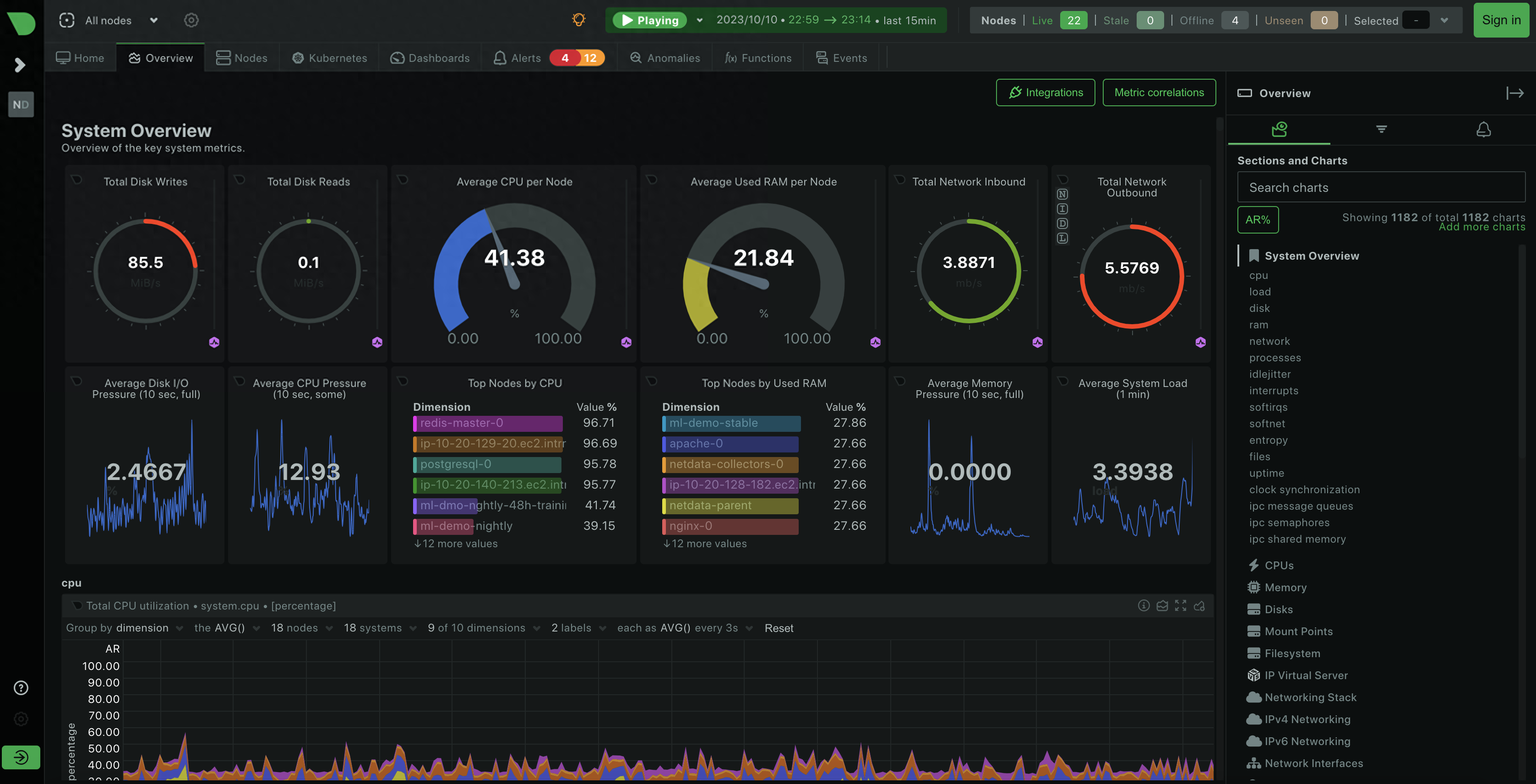
Netdata 可视化截图
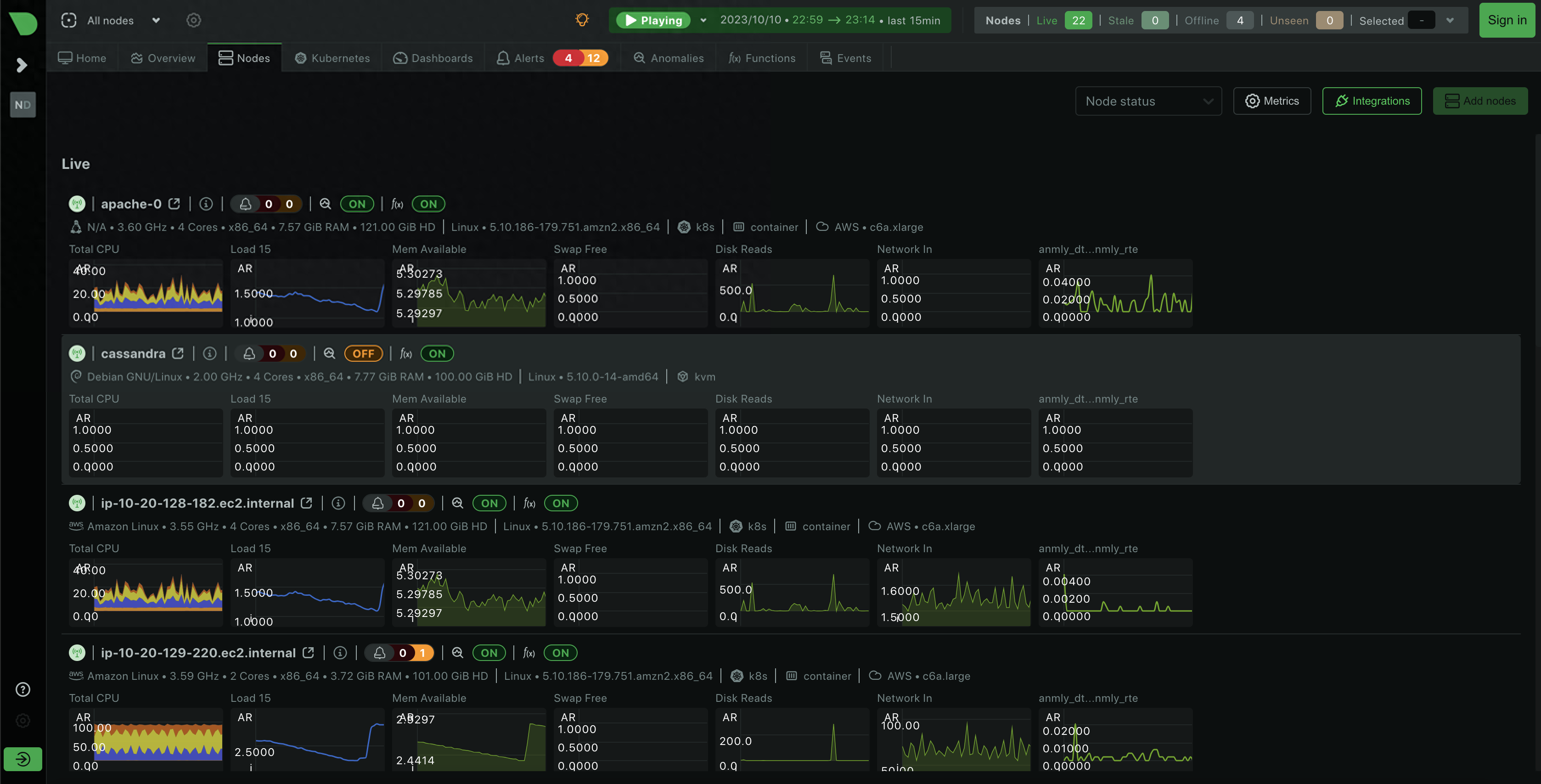
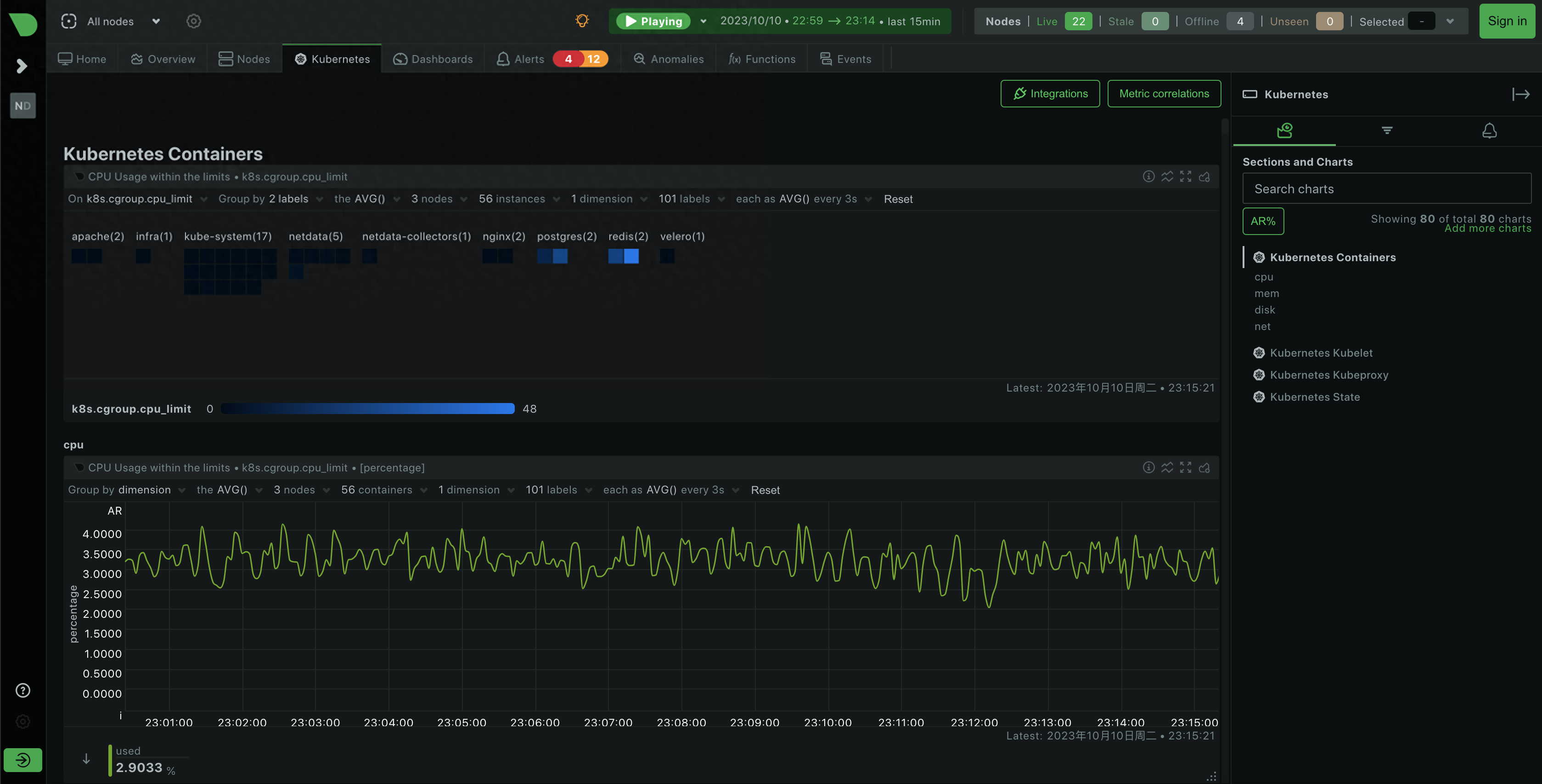
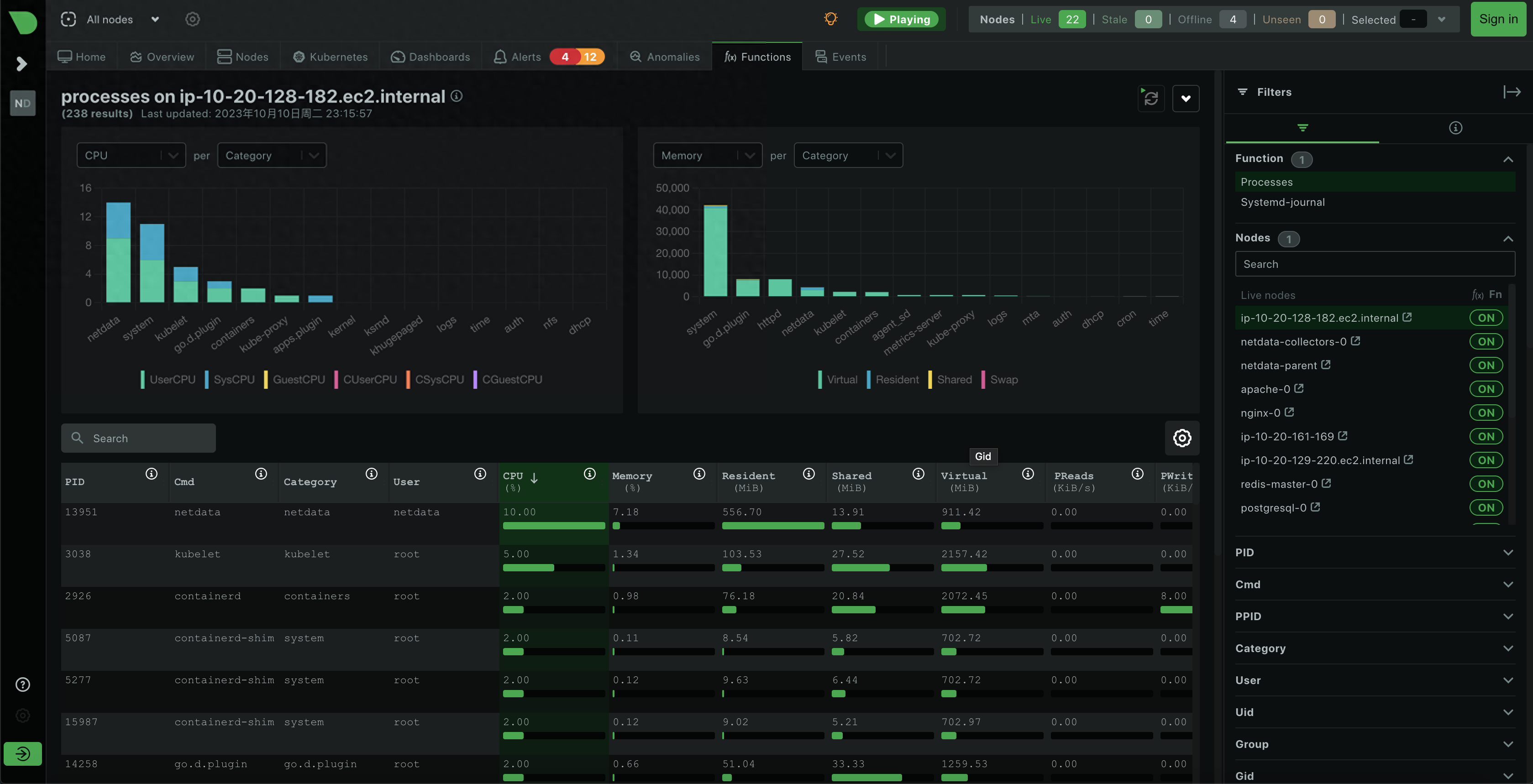
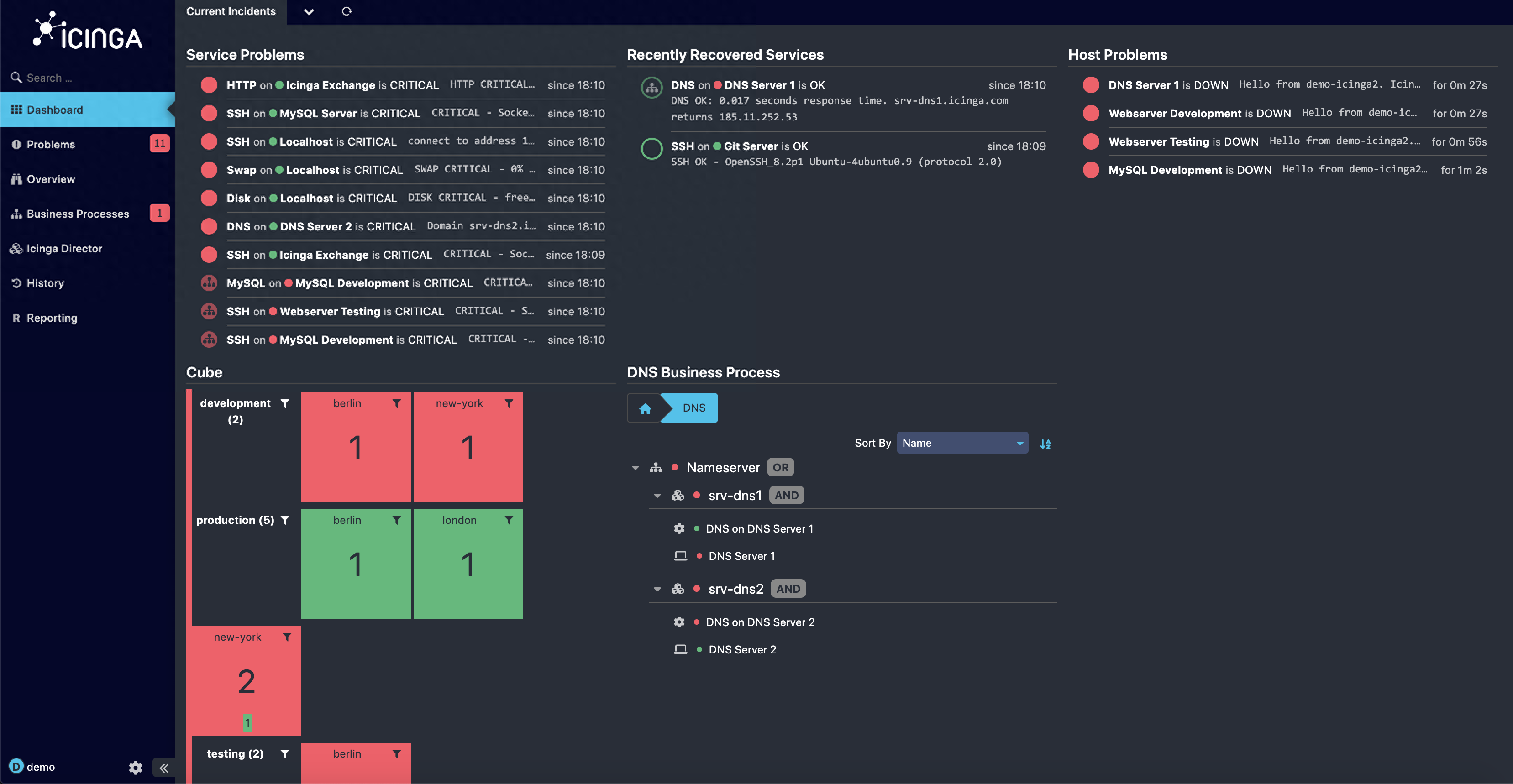
Icinga - 一个开源的网络监控系统
Github:https://github.com/Icinga
Icinga 官网
Icinga是一个开源的网络监控系统,它可以检查网络资源的可用性,将网络中断信息及时通知用户,并根据数据生成性能报告。这个工具有良好的可伸缩性和可扩展性,非常适合大型复杂环境。
在一个庞大的IoT设备网络环境中,Icinga 可以跟踪每台设备,确保它们处于在线状态并正常运行。但Icinga的设置可能有点复杂,第一次使用的用户需要花点时间。
Icinga 可视化截图

ELK Stack - 结合了Elasticsearch、Logstash和Kibana三种开源工具
Github:https://github.com/elastic

ELK Stack 官网
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
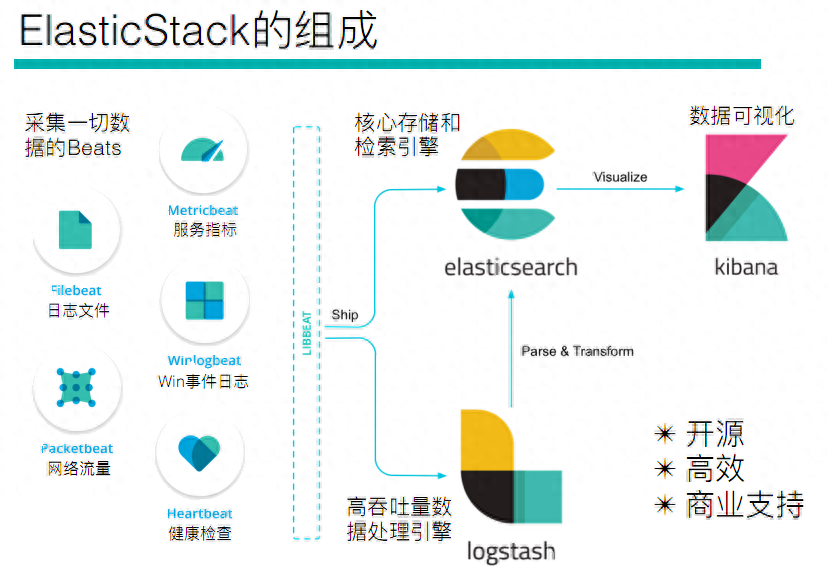
Elasticsearch 是一个搜索和分析引擎。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
在 ELK Stack 这个生态圈慢慢发展过程中,加入了一个新成员 Beats(Beats是负责单一用途数据采集并推送给Logstash或Elasticsearch的轻量级产品),就更名为 Elastic Stack
Elastic Stack 是 ELK Stack 的更新换代产品。

所以,Elastic Stack技术栈的功能为,将系统、网络、应用系统日志等各种日志及相关数据进行收集、过滤、转换、然后进行集中存放并可用于实时检索、分析和展示。
ELK Stack 可视化截图
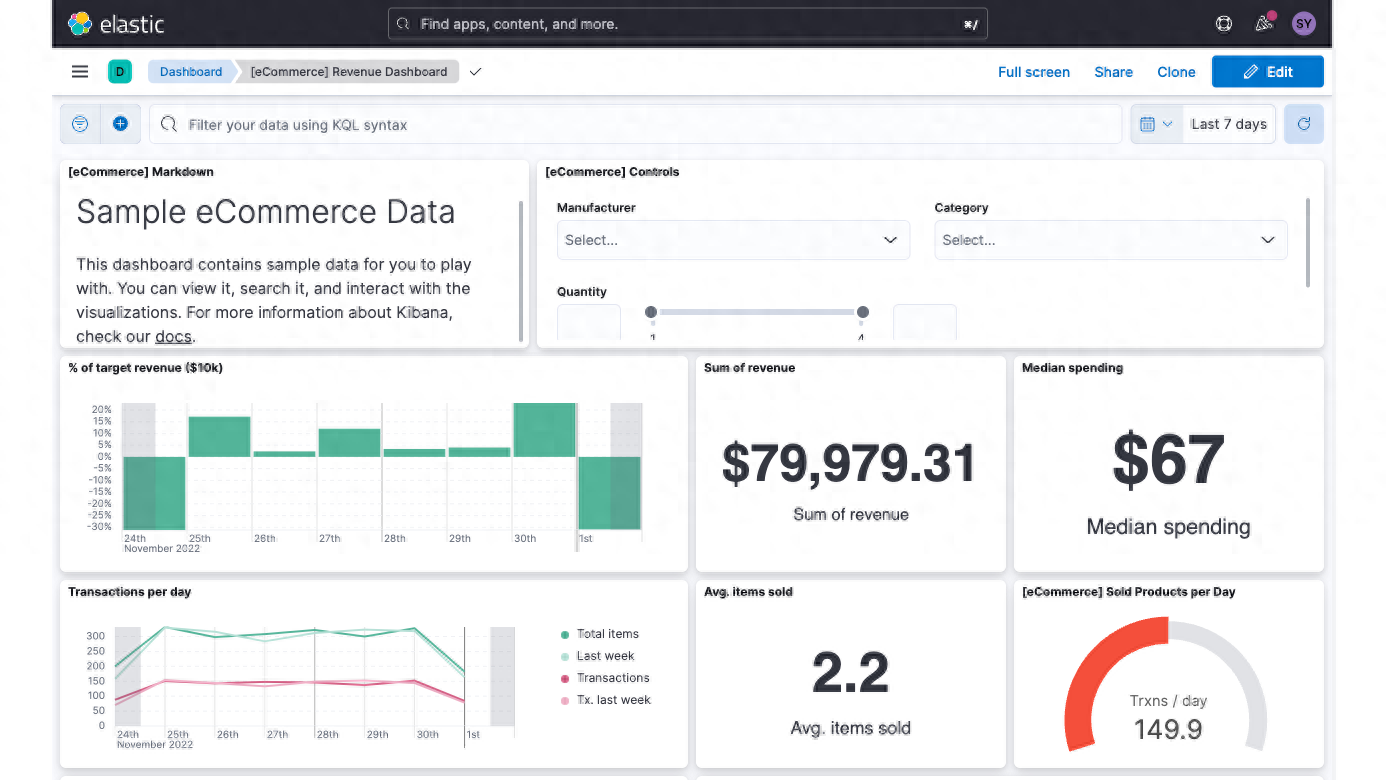
OpenNMS - 一个开源网络管理应用程序工具
传送门:https://www.opennms.com/

OpenNMS是由许多个人及组织,在OpenNMS软件专案这支大旗下,所共同打造的网络管理系统。从最初到2002年,程序代码是由Oculan Corporation开发并以GPL释出,后来后案的管理移交给 Tarus Balog。
OpenNMS是一个开源网络管理应用程序,提供自动发现、事件管理、通知管理、性能检测和服务保证等功能。例如,OpenNMS可以监控核心网络设备,并提醒高延迟链路或故障设备等问题。
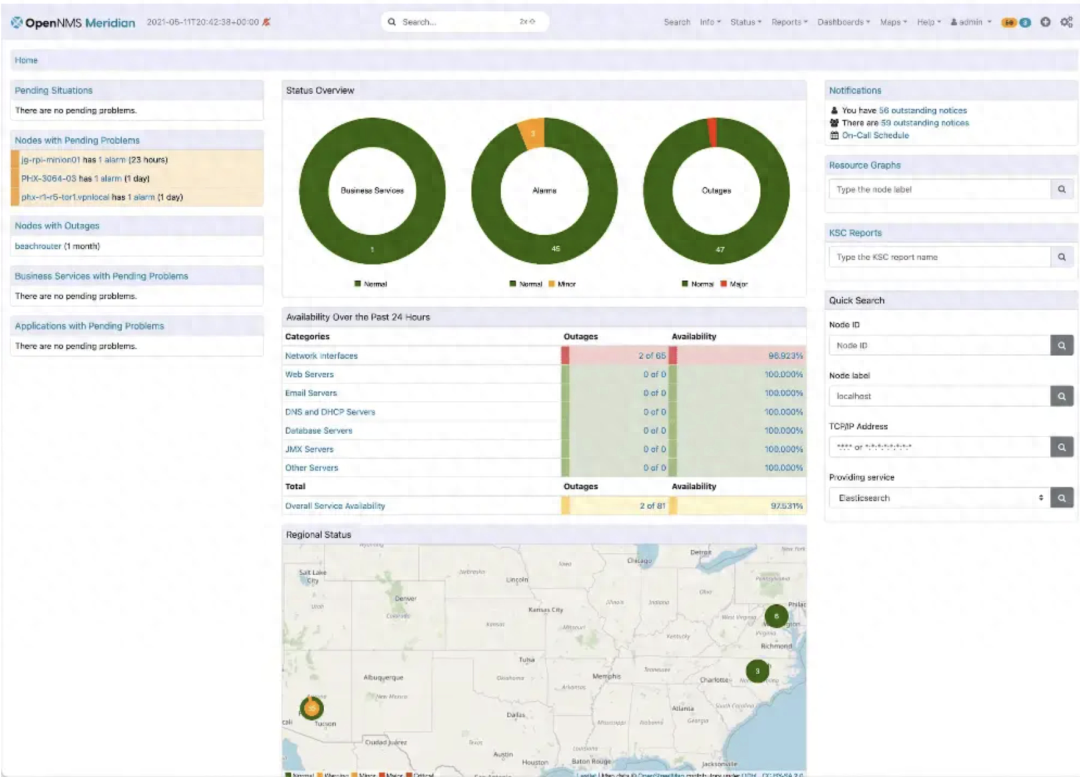
Cacti - 一个基于Web的网络监控工具
传送门:https://www.cacti.net/
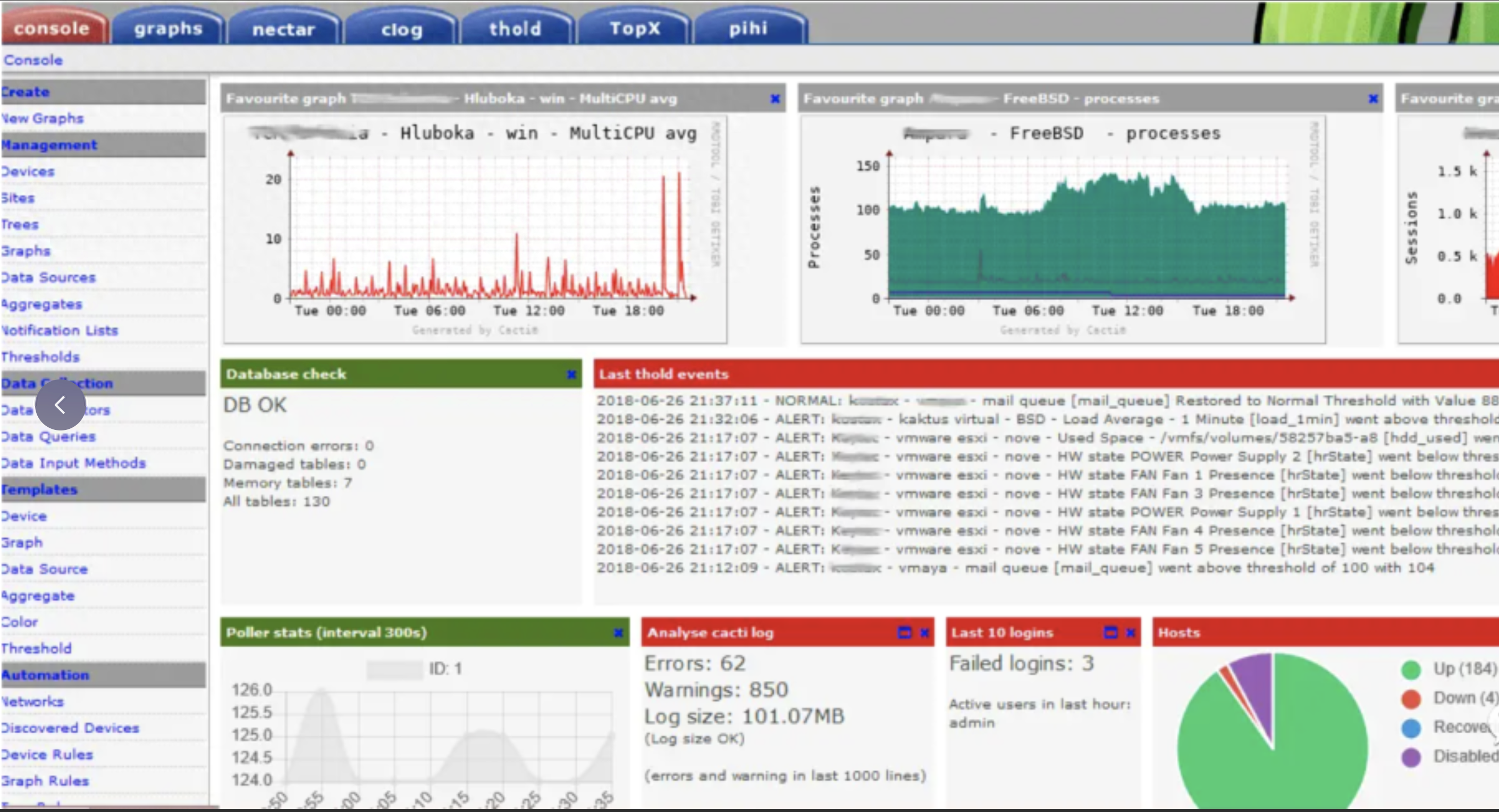
Cacti是一个基于Web的网络监控工具,它使用RRDTool来存储和显示网络统计数据。它提供了快速的轮询器、先进的图形模板以及多种数据采集的方法。
如果网络中的设备类型比较多,Cacti的SNMP支持从各种网络设备中提取指标,并以易于理解的图形显示指标信息。但Cacti的主要缺点是用户界面并不怎么直观。
Collectd - 一个可执行的守护进程工具
Github:https://github.com/collectd/collectd
Collectd 官网
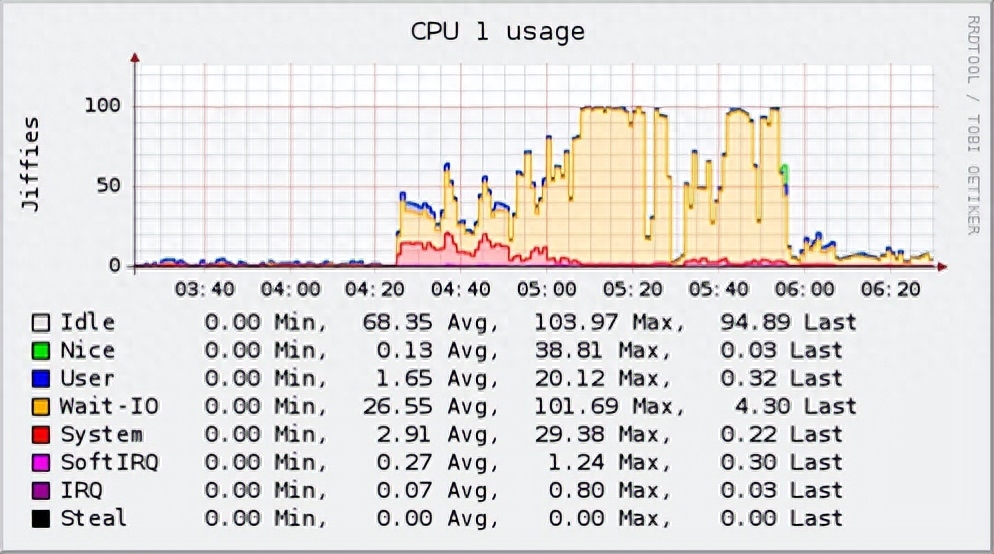
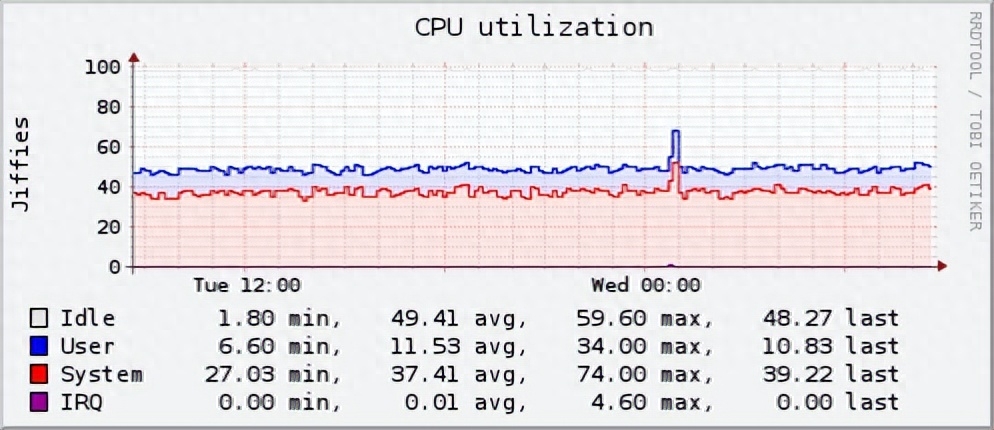
Collectd是一个可执行的守护进程,它可以定期收集系统和应用程序性能指标,并存储这些数值。这个工具它非常轻量级,几乎可以在任何系统上运行。
例如,Collectd可以用来监视小型家庭网络,并收集网络延迟、带宽使用和设备状态相关的数据。将Collectd与Grafana等可视化工具结合使用,可获得更加完整的监控解决方案。
InfluxDB- 一个能够处理高写入和高查询负载的时间序列数据库
Github:https://github.com/influxdata/influxdb
InfluxDB 官网
InfluxDB 其实是一个能够处理高写入和高查询负载的时间序列数据库,旨在存储大量带时间戳的数据,它的高性能结构可以处理大量的写入和查询负载,支持存储、分析一段比较长时间内的趋势数据。
因此,InfluxDB可以成为监控应用程序、实时分析等的理想选择。
例如:我们要跟踪网站的用户参与度,InfluxDB可以存储包括点击率、跳出率和停留时间等相关指标。这为我们提供了一个用户行为随时间变化的全面数据视图。
另外,由于InfluxDB本质是个数据库,为了便于分析,可以与Grafana结合在一起实现监控数据可视化。
InfluxDB 可视化截图
Sensu - 一个开源的监控事件管道,提供自动化的监控工作流程系统
Github:https://github.com/sensu/

Sensu 官网
Sensu是一个开源的监控事件管道,提供自动化的监控工作流程。Sensu强大的框架能够用于各种小型、大型云基础实施,方便用于观察、自动化和控制。特别适合用于云基础设施。
例如,在一个多个不同服务的大型云环境中,Sensu不仅可以监控这些服务的状态,还可以自动响应类似自动重新启动失败等服务的事件,
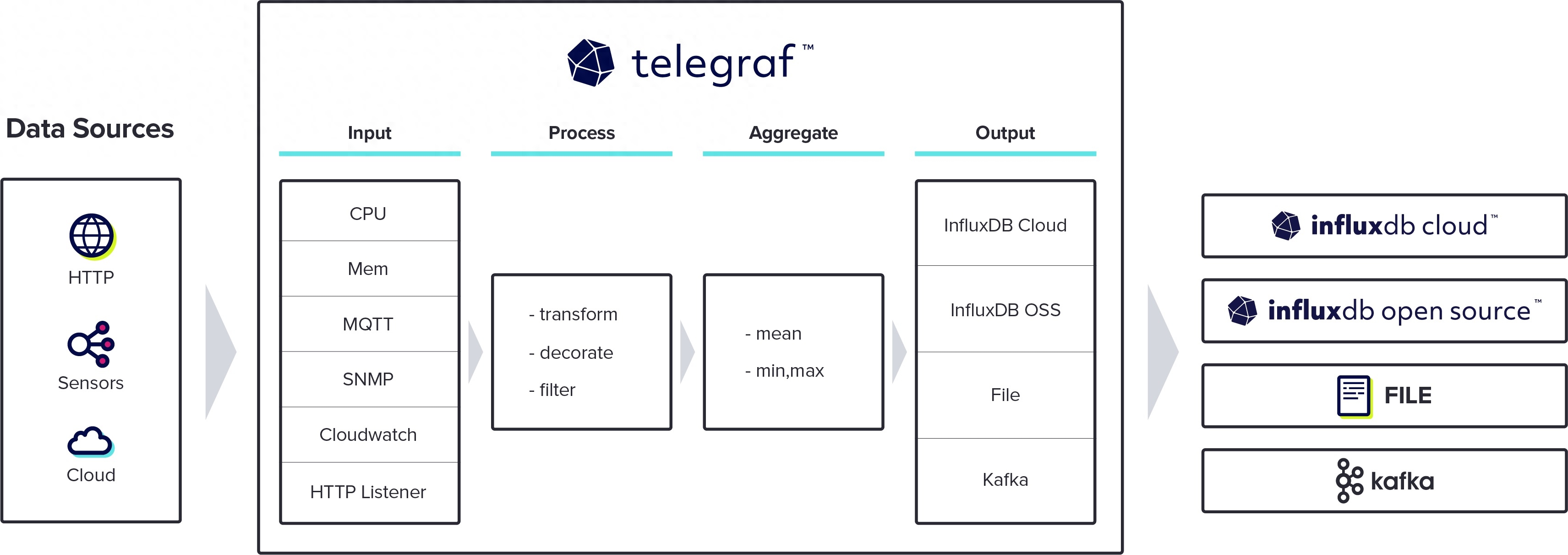
Telegraf - 一个用于收集、处理、聚合和编写指标的代理,用于收集和发送各种系统指标工具
Github:https://github.com/influxdata/telegraf
Telegraf 官网
Telegraf是一个用于收集、处理、聚合和编写指标的代理,用于收集和发送各种系统指标。它是InfluxData平台的一部分(InfluxDB也是InfluxData的一部分)。
假如需要监视在不同平台上运行的几个不同应用程序的性能。那么可以使用Telegraf从每个应用程序中收集指标并将其存储到InfluxDB,从而创建统一的监控平台。Telegraf简单且灵活,但它也只是一个日志指标代理。
Logstash - 是ELK Stack的一个重要组成部分,充当数据处理的管道。
Github:https://github.com/elastic/logstash
Logstash 官网
Logstash是ELK Stack的一个重要组成部分,充当数据处理的管道。它可以从几乎任何类型的源获取数据、动态转换数据并将数据发送到目的地。
假如我们要监控来多个系统(如Web服务器,安全设备和数据库),Logstash可以收集所有这些系统的日志,将收集到的数据以统一的格式发送到Elasticsearch。这使得分析和故障排除更加容易。Logstash虽然强大,但Logstash需要消耗一定的资源,如果您在较大的环境中使用Logstash,需要定期监控性能和微调,以避免资源浪费。
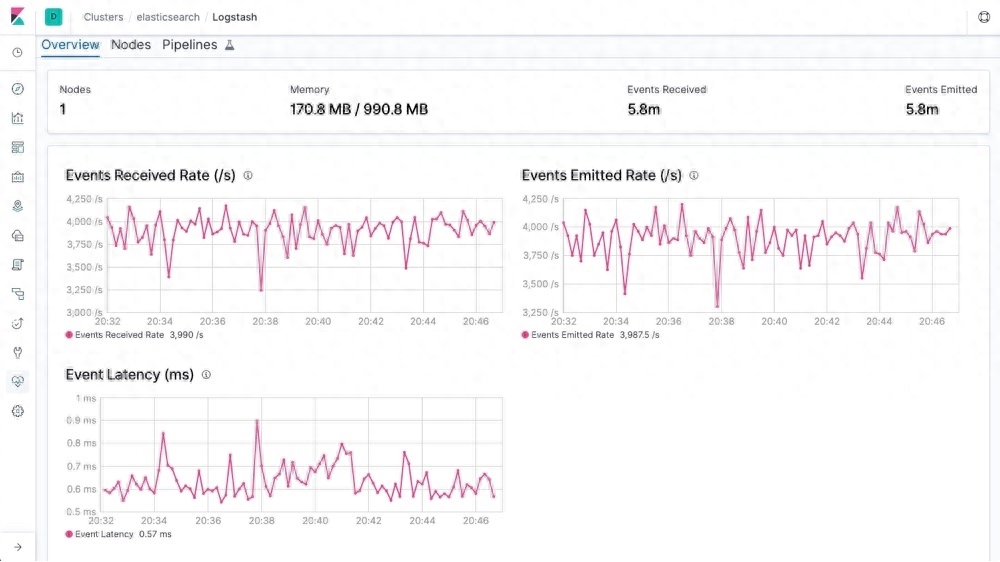
Fluentd - 一个数据采集和分析的开源工具,可用于建立统一的日志基础设施
Github:https://github.com/fluent/fluentd
Fluentd 官网
Fluentd是一个数据采集和分析的开源工具,可用于建立统一的日志基础设施。支持从Web服务器、数据库和应用程序等各种来源收集日志,并以多种格式输出。并且还可以将日志和报告可以发送到Elasticsearch。
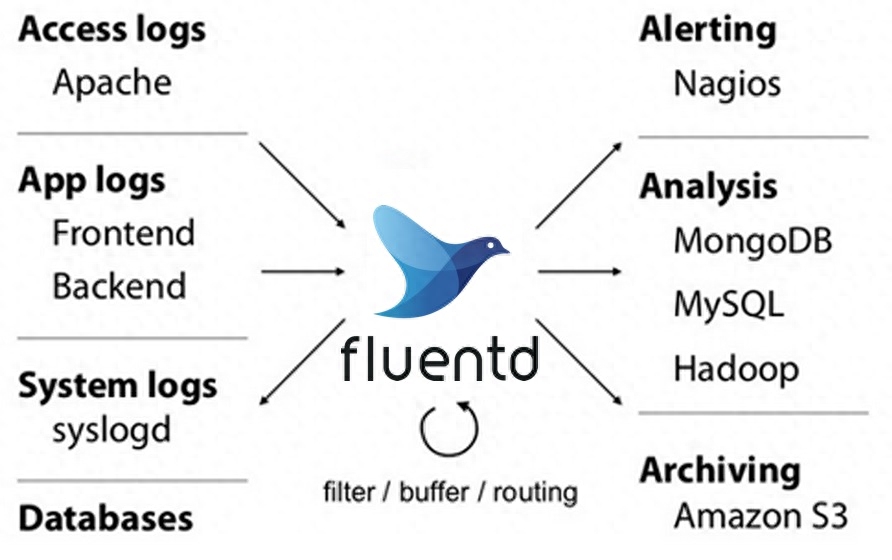
总结
以上列举的15个免费又实用的监控工具各有优缺点,选择合适的系统监控工具取决于具体的运行环境和对监控的要求。另外,在实际生产环境中,工具无法解决所有的问题,但是一个好的工具可以为我们提供最佳的解决方案。