













虽然大型语言模型在处理日常问答、总结文本等任务上表现非常出色,但如何让LLM在不显著增加计算需求、不降低短文本性能的前提下,能够处理「超长文本输入」仍然是一个难题。
最近,Meta团队公开了支持长上下文的模型Llama 2 Long的训练方法,该模型的有效上下文窗口多达32768个token,在各种合成上下文探测、语言建模任务上都取得了显著的性能提升。

论文链接:https://arxiv.org/pdf/2309.16039.pdf
并且,模型在指令调优的过程中不需要借助人工标注的长指令数据,70B参数量的模型就已经在各种长上下文任务中实现了超越gpt-3.5-turbo-16 k的性能。
除了结果外,论文中还对模型的各个组件进行了深入分析,包括Llama的位置编码,并讨论了其在建模长依赖关系的限制;预训练过程中各种设计选择的影响,包括数据混合和序列长度的训练策略。
消融实验表明,在预训练数据集中具有丰富的长文本并不是实现强大性能的关键,验证了长上下文持续预训练比从头开始长序列预训练更有效,同样有效。
LLAMA 2加长版
1、持续训练(Continual Pretraining)
由于注意力机制需要进行二次复杂度的计算,如果使用更长的输入序列进行训练会导致巨大的计算开销,研究人员通过实验对比了不同的训练策略:从头开始进行长序列(32768)预训练、以及在不同阶段(20%、40%、80%)从4096长度切换到32768的持续学习。
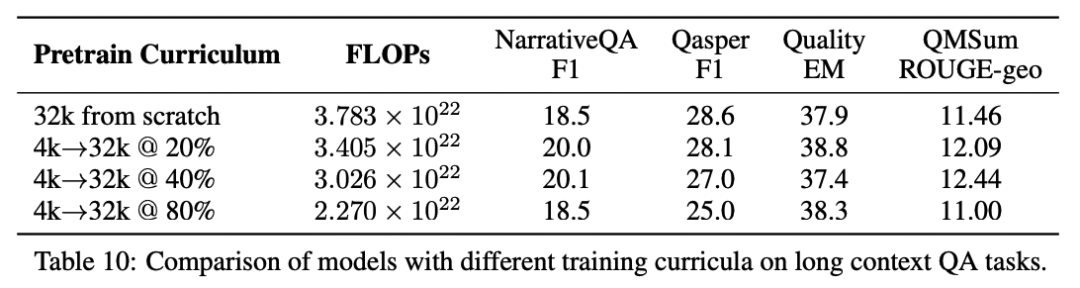
结果发现,在输入token数量长度相同的情况下,两个模型的性能几乎相同,但持续训练最多可以减少40%的FLOPs
位置编码(Positional Encoding)
在持续预训练中,LLAMA 2的原始架构基本没有变化,仅针对长距离信息捕获需求对位置编码进行了修改。
通过对7B尺寸LLAMA 2模型的实验,研究人员发现了LLAMA 2的位置编码(PE)的一个关键局限性,即阻碍了注意力模块汇集远处token的信息。

为了进行长上下文建模,研究人员假设该瓶颈来源于LLAMA 2系列模型使用的RoPE位置编码,并控制超参数基础频率(base frequency)从10, 000增加到500, 000来减少RoPE位置编码中每个维度的旋转角度,从而降低了RoPE对远处token的衰减效应。

从实验结果来看,RoPE ABF在所有位置编码变体中取得了最好的效果,证明了简单修改RoPE即可有效提升模型的上下文长度。
并且,研究人员也选择没有选择稀疏注意力,考虑到LLAMA 2-70B的模型维h为8192,只有当输入序列长度超过6倍h(即49,152)个token时,注意力矩阵计算和值聚合的成本才会成为计算瓶颈。
数据混合(Data Mix)
在使用改良版位置编码的基础上,研究人员进一步探索了不同预训练数据的组合,通过调整 LLAMA 2 的预训练数据比例或添加新的长文本数据来提高长上下文能力。

实验结果发现,在长上下文、持续预训练的设置下,数据质量往往比文本长度发挥着更关键的作用。
优化细节
研究人员持续增加预训练LLAMA 2检查点的输入序列长度,同时保持与LLAMA 2相同的每批token数量;
对所有模型进行了100,000步共计400B个token的训练;
使用Flash-Attention,当增加序列长度时,GPU 内存开销几乎可以忽略不计,使用70B模型的序列长度从4,096增加到 16,384 时,可以观察到大约17%的速度损失;
对于7B/13B模型,使用学习率2e^-5和余弦学习率调度,预热步骤为 2000 步;
对于较大的34B/70B模型,必须设置较小的学习率1e^-5才能获得单调递减的验证损失。
2、指令微调(Instruction Tuning)
为LLM对齐收集人工演示和偏好标签是一个繁琐而耗时耗力的过程,在长上下文场景下,往往会涉及到复杂的信息流和专业知识,例如处理密集的法律/科学文档,标注成本还会更高,所以目前大多数开源指令数据集主要由短样本组成。
在这项工作中,研究人员发现一种简单且容易实现的方法,可以利用预先构建的大型多样化短提示数据集,在长语境基准测试中效果也出奇地好。
具体来说,首先使用LLAMA 2-Chat中使用的RLHF数据集,并用LLAMA 2-Chat本身生成的自指导(self-instruct)长数据对其进行扩充,预期模型能够通过大量RLHF数据学习到一系列不同的技能,并通过自指导数据将知识转移到长上下文的场景中。
数据生成过程侧重于QA格式的任务:从预训练语料库中的长文档开始,随机选择一个文本块,并提示LLAMA 2-Chat根据文本块中的信息编写问答对,通过不同的提示收集长短格式的答案。
除此之外,生成过程还包括自我批判(self-critque)步骤,即提示LLAMA 2-CHAT验证模型生成的答案。
给定生成的 QA 对,使用原始长文档(已截断以适应模型的最大上下文长度)作为上下文来构建训练实例。
对于短指令数据,将其连接为16,384个token序列;对于长指令数据,在右侧添加填充token以便模型可以单独处理每个长实例,而无需截断。
虽然标准指令微调只计算输出token的损失,但同时计算长输入提示的语言建模损失也可以提升下游任务的性能。
实验结果
1、预训练评估
短任务
要使长上下文LLM具备普遍实用性,一个重要的要求是确保其在标准短上下文任务中的强大性能。

在短任务实验中,可以看到其结果与LLAMA 2相当,而且在大多数情况下比LLAMA 2要更强,在编码、数学和知识密集型任务(如 MMLU)上的结果有明显改善,优于GPT-3.5

相比其他长上下文方法在短任务的不佳表现,研究人员将该模型的性能改进归功于额外的计算FLOPs以及从新引入的长数据中学到的知识。
长任务
之前的方法大多依靠易错性和合成任务来衡量模型在长上下文场景下的性能,与此不同,研究人员使用真实世界的语言任务来进行长上下文的评估:
在NarrativeQA上评估零样本性能,在QuALITY和Qasper上评估2-shot性能,在QMSum上评估1-shot性能,具体的样本数根据每个数据集的平均样本长度决定。
使用的提示非常简单「{Context} Q: {Question}, A:」,可以减少评估误差;如果提示语超过模型的最大输入长度或16,384个词组,输入提示语将从左侧截断。

对比其他开源长上下文模型,在 7B 尺度上,只有Together-7B 32k可以与该模型的性能相媲美。
有效利用上下文(Effective Context Utilization)
为了验证该模型能够有效利用增加的上下文窗口,从实验中可以看到,随着上下文长度的增加,每个长任务的结果都在单调地改善。

除此之外,模型的语言建模损失与上下文长度呈幂律加常数的比例关系,结果表明,尽管收益递减,但该模型在 32,768 个文本token以内仍然显示出性能增益(语言建模损失),更大的模型可以更有效地利用上下文。

2、指令微调结果
研究人员在ZeroSCROLLS基准上对指令微调模型进行测试,包含10个长上下文数据集,如摘要、问题回答和多文档聚合任务。
为了进行公平比较,模型设置为相同的提示、截断策略和最大生成长度等。
实验结果显示,在不使用任何人类标注的长上下文数据的情况下,70B的chat模型在10项任务中的7项都优于gpt-3.5-turbo-16k
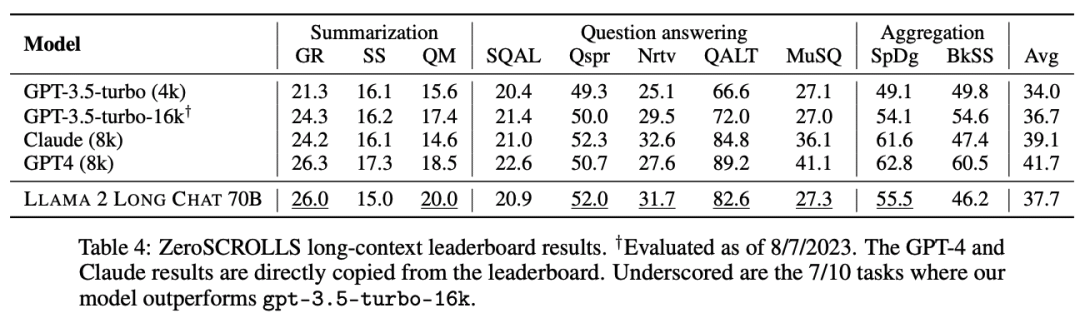
如果使用更多不同的数据进行微调,研究人员预计其性能还会进一步提高。
值得一提的是,评估长上下文LLM是一项比较困难的任务,基准中使用的自动指标在很多方面都有局限性,例如只有单个参考的文本摘要,n-gram也不一定符合人类偏好。
3、人类评估
作为自动评估基准结果的补充,通过询问标注人在有用性、诚实性和无害性等方面,更喜欢来自文中提出的指令微调模型,还是来自MPT-30B-chat、GPT-4、GPT-3.5-turbo-16k和Claude-2等专有模型的生成来进行人工评估。
与自动度量不同,人类更擅长评估长上下文模型的模型响应质量,因为可接受答案的空间很大。
研究人员主要关注两个应用场景,评估模型利用信息(检索到的文档)来回答给定查询的能力。
1)多回合对话数据,每个提示都是聊天历史,模型需要基于聊天历史生成一致的响应;
2)多文档搜索查询应答应用,该模型提供了从搜索会话中检索到的几个最相关的文档以及相应的搜索查询。
总共2352个样本,其中每个样本由3个不同的人类标注人员进行评估,模型相对于其他模型的标准胜率是通过平均每个比较示例的结果来计算的。
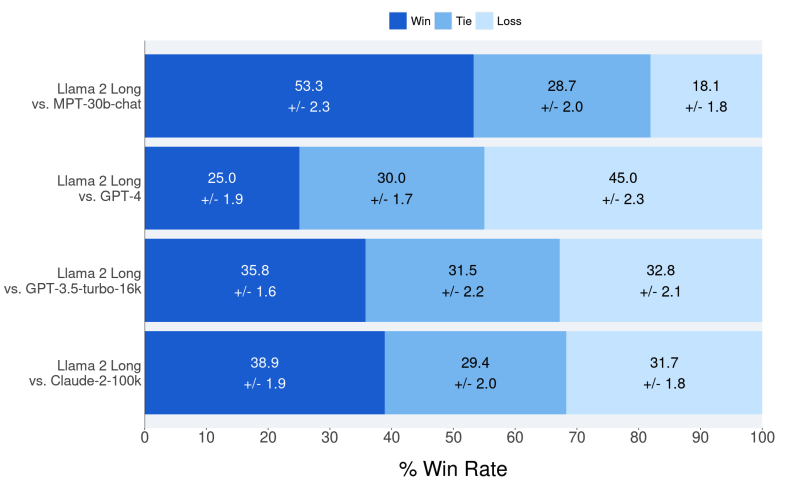
可以看到,Llama 2 Long只需要很少的指令数据就可以实现与MPT-30B-chat、GPT-3.5-turbo-16k和Claude-2相近的性能。





























