













复杂数学推理是评价大语言模型推理能力的重要指标,目前常用的数学推理数据集样本量有限且问题多样性不足,导致大语言模型存在 [逆转诅咒] 的现象,即一个训练于「A 是 B」的语言模型无法推广到「B 是 A」[1]。此现象在数学推理任务中的具体形式是:即给定一个数学问题,语言模型擅于用正向推理解答问题但缺乏逆向推理解决问题的能力。逆向推理在数学问题中十分常见,如下 2 个例子。
1. 经典问题 - 鸡兔同笼
- 正向推理:笼子里有 23 只鸡和 12 只兔,问笼子里有多少个头和多少只脚?
- 逆向推理:有若干只鸡兔同在一个笼子里,从上面数,有 35 个头,从下面数,有 94 只脚。问笼中各有多少只鸡和兔?
2. GSM8K 问题
- 正向推理: James buys 5 packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay?
- 逆向推理: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay? If we know the answer to the above question is 110, what is the value of unknown variable x?
为了提升模型的正向和逆向推理能力,剑桥、港科大、华为的研究者基于两个常用的数学数据集(GSM8K 和 MATH)提出了 MetaMathQA 数据集:一个覆盖面广、质量高的数学推理数据集。MetaMathQA 由 395K 个大语言模型生成的正向逆向数学问答对组成。他们在 MetaMathQA 数据集上基于 LLaMA-2 微调得到专注于数学推理 (正向和逆向) 的大语言模型 MetaMath,在数学推理数据集上达到了 SOTA。MetaMathQA 数据集和不同规模的 MetaMath 模型已开源供研究人员使用。

- 项目地址:https://meta-math.github.io/
- 论文地址:https://arxiv.org/abs/2309.12284
- 数据地址:https://huggingface.co/datasets/meta-math/MetaMathQA
- 模型地址:https://huggingface.co/meta-math
- 代码地址:https://github.com/meta-math/MetaMath
本文中构造了一个逆向推理数据集 GSM8K-Backward。实验结果表明,目前的方法(e.g., SFT、RFT、WizardMath)在逆向推理问题中表现远差于正向推理。相较而言,MetaMath 模型在正向和反向推理上都取得了优越的性能。

方法

MetaMathQA 包含四种数据增强的方法:
1. Answer Augmentation (答案增强):给定问题,通过大语言模型生成能得到正确结果的思维链作为数据增广。
- Question: James buys 5 packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay?
- Answer: James buys 5 packs of beef that are 4 pounds each, so he buys a total of 5 * 4 = 20 pounds of beef. The price of beef is $5.50 per pound, so he pays 20 * $5.50 = $110. The answer is: 110.
2. Rephrasing Question (问题改写增强):给定元问题,通过大语言模型重写问题并生成得到正确结果的思维链作为数据增广。
- Question: What is the total amount that James paid when he purchased 5 packs of beef, each weighing 4 pounds, at a price of $5.50 per pound?
- Answer: Each pack of beef weighs 4 pounds, so 5 packs weigh 4 * 5 = 20 pounds in total. The price per pound of beef is $5.50, so the total cost for 20 pounds is 20 * $5.50 = $110. Therefore, James paid a total of $110. The answer is: 110.
3. FOBAR Question (FOBAR 逆向问题增强):给定元问题,通过掩码条件中的数字为 x,给定原有答案并反推 x 来产生逆向问题,并基于该逆向问题生成正确的思维链过程来进行数据增广(反推样例:“If we know the answer to the above question is 110, what is the value of unknown variable x?”)。
- Question: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. How much did he pay? If we know the answer to the above question is 110, what is the value of unknown variable x?
- Answer: James buys x packs of beef that are 4 pounds each, so he buys a total of 4x pounds of beef. The price of beef is $5.50 per pound, so the total cost of the beef is 5.50 * 4x = 22x. We are given that the total cost is $110, so we can write: 22x = 110. Dividing both sides by 22, we get: x = 5. The value of x is 5.
4. Self-Verification Question (Self-Verification 逆向问题增强):在 FOBAR 的基础上,通过大语言模型改写逆向问题部分为陈述的语句来进行数据增广(改写样例:“How much did he pay?” (with the answer 110) 被改写成 “He paid 110”)。
- Question: James buys x packs of beef that are 4 pounds each. The price of beef is $5.50 per pound. He paid 110. What is the value of unknown variable x?
- Answer: To solve this problem, we need to determine the value of x, which represents the number of packs of beef that James bought. Each pack of beef weighs 4 pounds and costs $5.50 per pound. The total amount James paid is $110. We can set up the equation as follows: Number of packs of beef * Weight per pack * Price per pound = Total amount paid; x * 4 * $5.50 = $110; Let's simplify and solve for x: 4x * $5.50 = $110; 22x = $110; To isolate x, we divide both sides of the equation by 22: 22x / 22 = $110 / 22; x = $5; The value of x is 5.
实验结果
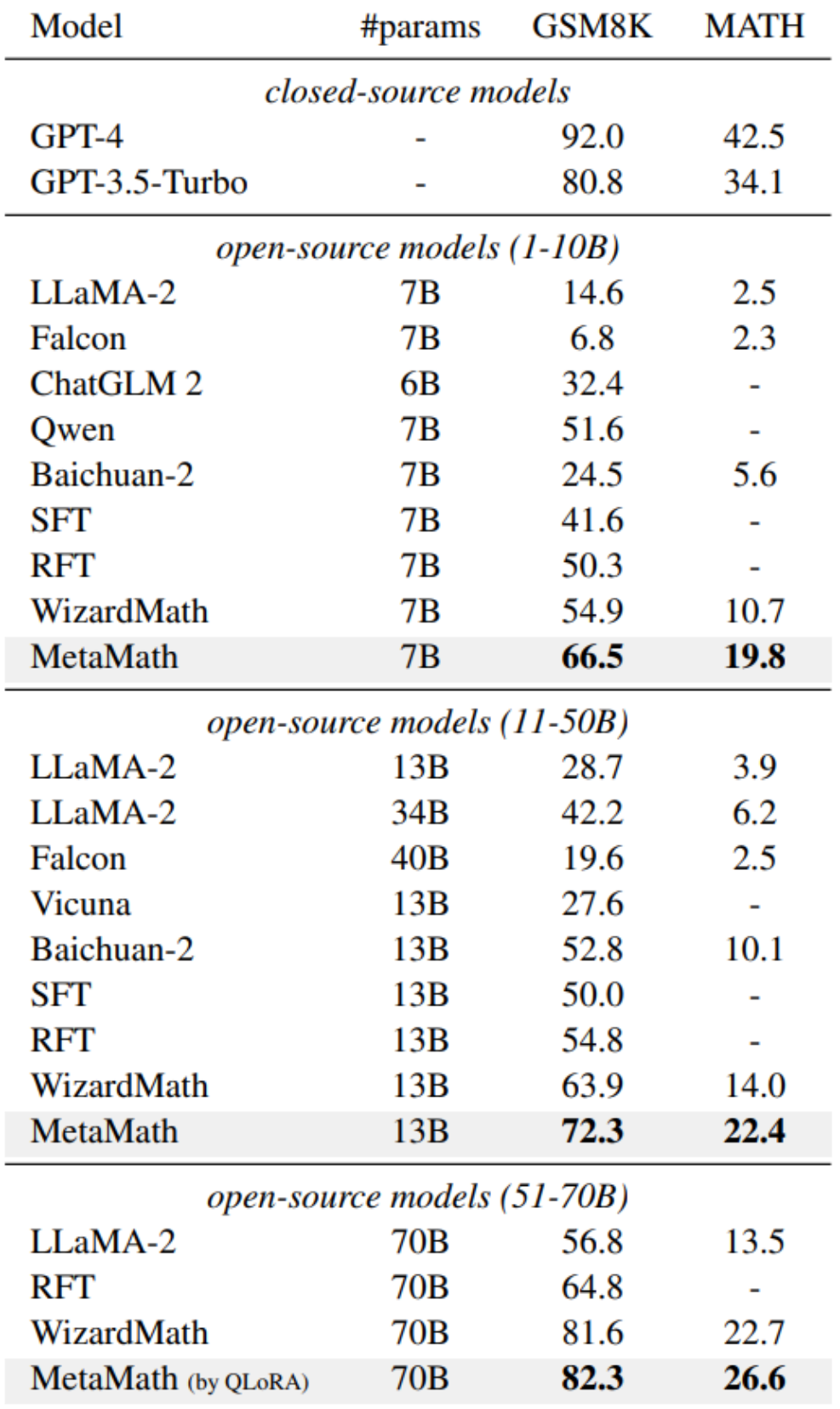

在两个常见数学推理数据集(GSM8K 和 MATH)的实验结果表明,在不借助外部工具(e.g., code interpreter), MetaMath 在性能上显著优于已有开源 LLM 模型。其中,我们的 MetaMath-7B 模型在 GSM8K 上达到了 66.5% 的准确率,在 MATH 上达到了 19.8% 的准确率,超过了相同规模的最先进模型分别 11.6% 和 9.1%。特别地,MetaMath-70B 在 GSM8K 上达到了 82.3% 的准确率,超过 GPT-3.5-Turbo。
根据 Superficial Alignment Hypothesis [2],大语言模型的能力源于预训练,而来自下游任务的数据则激活了预训练期间学习到的语言模型的固有能力。由此产生了两个重要问题:(i)什么类型的数据可以最有效地激活潜在知识,以及(ii)为什么一个数据集在这种激活中比另一个数据集更好?
为什么 MetaMathQA 有用?提高了思维链数据的质量 (Perplexity)

如上图所示,研究者们计算了 LLaMA-2-7B 模型在仅答案数据、GSM8K CoT 以及 MetaMathQA 数据的各部分上的 perplexity。MetaMathQA 各部分的 perplexity 显著低于其他两个数据集,这突显了它固有的易学性,可能更有助于引导出模型的潜在知识。
为什么 MetaMathQA 有用?增加了思维链数据的多样性 (Diversity)
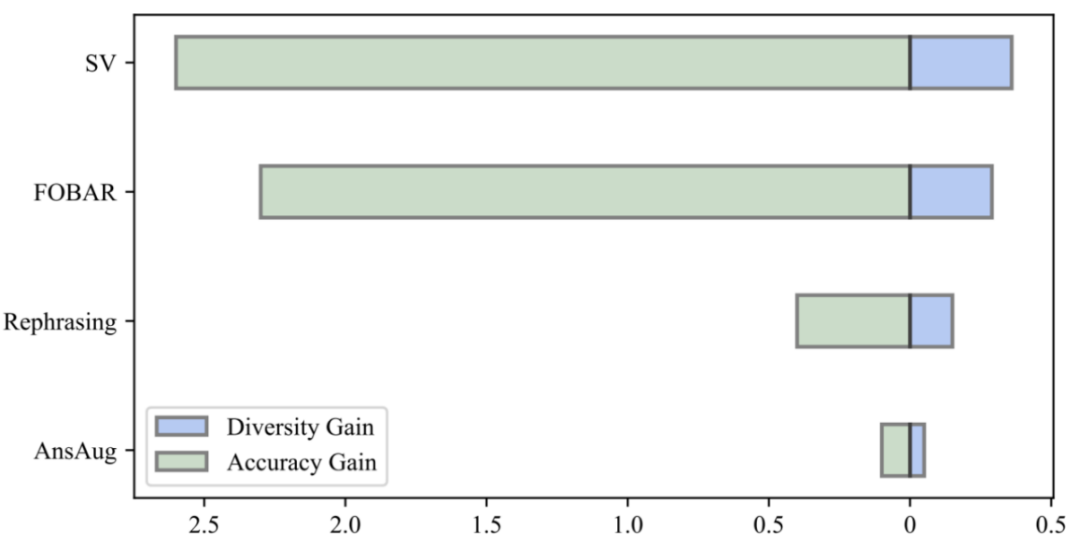
通过比较数据的多样性增益和模型的准确率增益,他们发现 Rephrasing、FOBAR 和 SV 添加相同数量的增广数据带来了明显的多样性增益,显著提升了模型准确率。相比之下,简单地使用答案增强会导致明显的准确率饱和。在准确率饱和之后,增加 AnsAug 数据只会带来有限的性能提升。






























