物理世界和数字世界的信息转换是数字化发展的一个技术内容。而光学字符识别(Optical Character Recognition:简称OCR)正是其中之一。
OCR是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。OCR常常被用于:证件识别、车牌识别、pdf文档转换为Word、拍照识别、截图识别、网络图片识别、无人驾驶、无纸化办公、稿件编辑校对、物流分拣、文档检索、字幕识别、文献资料检索等领域。特别是在业务流程自动化领域OCR是RPA的一个重要技术组成,起到重要作用。

随着AI技术的发展,目前开源市场出现了许多非常优秀的OCR项目。下面介绍目前比较流行的开源OCR项目,这些项目能够为您OCR技术选型或者OCR模型算法研究提供参考。
1.Tesseract
https://github.com/tesseract-ocr/tesseract

Tesseract是一个非常经典的开源OCR引擎,最初由Hewlett-Packard开发,现在由Google维护。Tesseract以其准确性和多功能性而闻名,可以提取数据并将扫描的文档、图像和手写文字转换为机器理解的文本。Tesseract支持100多种语言,并兼容多种操作系统,并且提供了非常方便的命令行界面。
优势:
- 准确性:Tesseract提供了非常高OCR准确性,特别是在打印文本和扫描文档方面。
- 语言支持:Tesseract支持广泛的语言,允许识别多种语言的文本,包括一些特殊语种,使其成为多语言应用的理想选择。
- 持续改进:Tesseract的开源社区非常活跃,能够及时地更新升级项目、修复Bug、完善用户反馈的性能需求等。
缺点:
- 复杂布局文档识别:Tesseract在简单布局的文档上表现非常好,但在布局比较复杂的文档上就需要额外的预处理或后续处理步骤。
- 手写识别准确度:Tesseract在识别机器打印文本方面表现出色,但在手写文本上的表现并不尽如人意,有时还不如一些专用手写识别工具准确。
2.Tesseract.js
https://tesseract.projectnaptha.com/

Tesseract.js是一个基于TesseractOCR的Web浏览器OCR软件。你可以在浏览器中使用它,并且非常易用。与Tesseract OCR一样,它也支持多种语言,包括中文。

3.OCRopus
https://github.com/ocropus

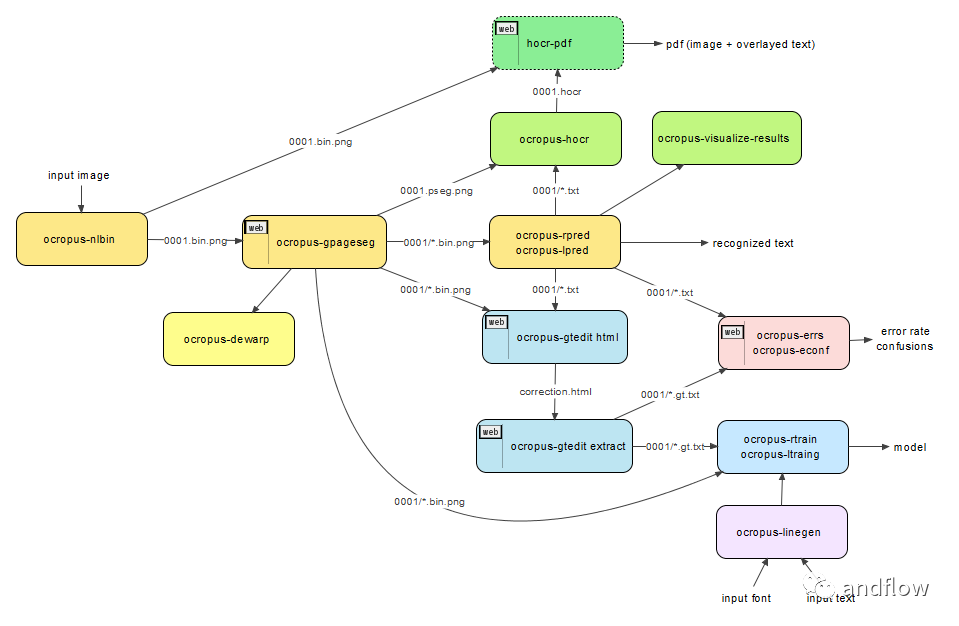
OCRopus是由Google开发的OCR相关工具集合,它扩展了Tesseract OCR引擎的功能。它提供了布局分析、文本识别和样本数据生成的高级功能。
另外,OCRopus可以从命令行通过指定输入的图像来执行它。它会将识别的文本直接输出到标准输出,或者将其作为hOCR(基于HTML)代码写入文件,然后可以将其转换为可搜索的PDF。如果需要更精确的控制,可以在命令行上指定选项来执行特定操作。
优势:
- 布局分析:OCRopus在布局分析方面非常精确,使其成为具有复杂布局或多列结构文档识别的理想选择。
- 文本识别准确性:OCRopus通过利用Tesseract的精确OCR引擎和其他组件,能够提高识别的准确性。
- 可定制性:OCRopus能够生成用于训练的样本数据,用于训练自定义的OCR模型,从而在专业应用中实现更高可定制性和准确性。
缺点:
- 学习曲线:与独立的OCR引擎相比,OCRopus由于其工具和组件的范围比较广,因此具有更陡峭的学习曲线。
- 资源密集型:OCRopus的高级功能可能需要更多的计算资源,这个可能需要较高的成本,并且也需要考虑项目对处理时间的要求。
4.GOCR
https://jocr.sourceforge.net/

GOCR是在GNU通用公共许可证下开发的开源OCR引擎。它能够识别各种图像文件格式中的文本内容,并支持多种语言和操作平台。
虽然它的准确性可能无法超过其他OCR引擎,但GOCR的优势是非常简单易用。
优势:
- 简单性:GOCR的主要优势在于它的简单性。该软件提供了一个简单易用的界面,适合那些喜欢简单OCR解决方案而不需要大量配置或复杂设置的用户。
- 多语言支持:GOCR支持多种语言,允许用户从包含不同语言内容的图像中提取文本。
缺点
- 准确性:虽然GOCR提供了基本的OCR功能,但其准确性可能无法与其他更高级的OCR引擎相媲美。
- 高级功能:GOCR专注于简单的OCR任务,可能缺乏布局分析或专业识别算法等高级功能。因此,如果您需要高级功能,这个工具并不是很适合。
4. CuneiForm
CuneiForm是一个开源的OCR,专门用于将扫描的文档和图像转换为可编辑的文本。 它的主要目标是提供准确的OCR结果,同时具有比较灵活的输入源和输出格式。CuneiForm还支持多种语言,并兼容各种操作系统。
优势:
- 准确性:CuneiForm以其从扫描图像中识别文本的准确性而闻名,即使对于复杂的文档的识别也非常可靠。
- 语言支持:CuneiForm支持多种语言,使用户能够从不同语言环境中的文档中提取文本。
- 输入和输出灵活性:CuneiForm接受各种格式的扫描图像,包括TIFF和JPEG。此外,还可以以TXT、HTML和PDF等格式输出识别的文本,为进一步处理提供了灵活性。
缺点:
- 使用者界面:CuneiForm的用户界面可能不像其他一些OCR工具那样直观或用户友好。因此,您可能需要熟悉OCR软件或文档,才能有效地使用其功能。
- 定制化:虽然CuneiForm为一般OCR任务提供了准确的结果,但在可定制化或专业OCR要求方面存在局限性。
5.Ocrad
https://www.gnu.org/software/ocrad/
Ocrad以其简单性和识别速度而闻名,它提供了一个轻量级的OCR解决方案,主要以识别印刷文本而闻名。它旨在提供一个简单高效的OCR解决方案,侧重文本识别提取的速度和易用性。
优势:
- 易用性和识别效率:Ocrad简单的设计和轻量级的特性有助于其易用性和识别效率。特别适合用于快速和简单的OCR解决方案需求。
- 打印文本识别:Ocrad擅长从扫描图像中识别打印文本,可以从清晰且格式良好的打印文档中识别提取出可靠的结果。
缺点:
- 缺乏高级功能:Ocrad的侧重点在于基础的OCR任务,它可能缺乏高级功能,例如布局分析或手写识别等。
- 复杂文本和低质量图像的准确性:在处理复杂的文本结构或低质量的扫描图像时,Ocrad的准确性可能会降低。
6.Ocrad.js
http://antimatter15.com/ocrad.js/demo.html
Ocrad.js是一个基于Ocrad的浏览器的OCR软件。在JavaScript中使用它。支持的图像格式包括JPEG、PNG、GIF、BMP、SVG、NetBPM等。
它非常简单易用,只需要通过调用OCRAD的函数即可实现对img标签的识别。虽然在识别精度方面比Tesseract.js逊色,但Ocard的优势是它的模型文件比Tesseract小30倍以上。
7.GImage Reader
https://github.com/manisandro/gImageReader
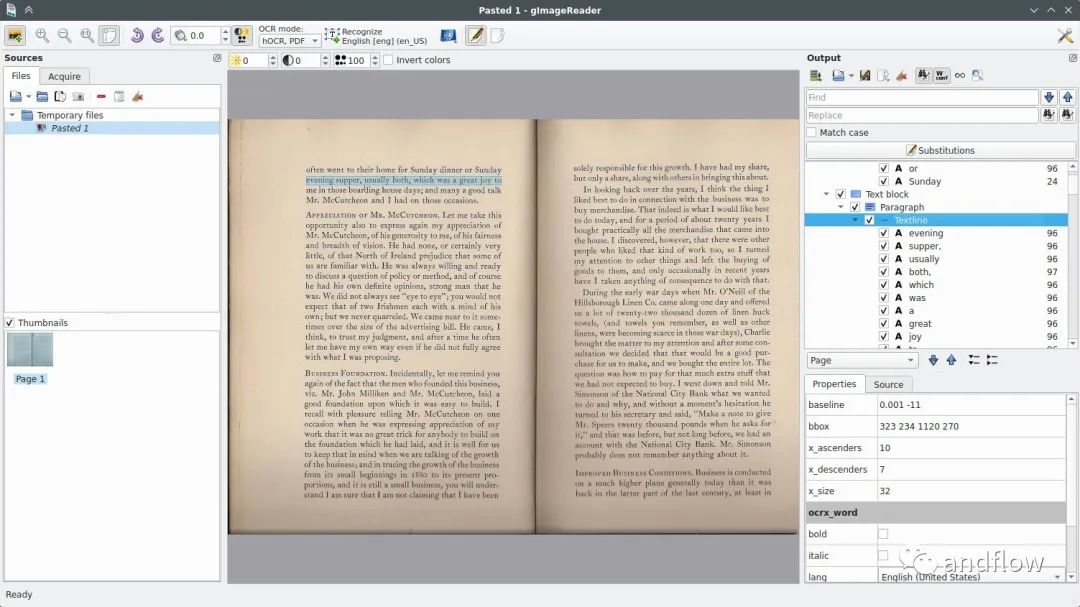
GImage Reader工具它能够识别多种语言以及各种图像文件格式的文本,使其适合从扫描的文档、屏幕截图或者照片中提取文本;并且它提供了一个简单直观的用户界面,允许您快速加载图像并获得文本结果。
优势:
- 友好的用户界面:GImage Reader的界面非常直观易用,用户可以轻松访问,能够轻松加载图像并获取结果。
- 多语言支持:GImage Reader支持多种语言,允许您从包含不同语言内容的图像中提取文本。
缺点:
- 缺乏高级功能:GImage Reader主要专注于比较基本的OCR任务,如果需要更加专业的内容识别,它就不适合了。
- 准确度和性能:虽然GImage Reader可用于基本的OCR任务,但其准确性和性能可能会受到图像质量和文本复杂性的影响。
8.Capture2Text
https://capture2text.sourceforge.net/
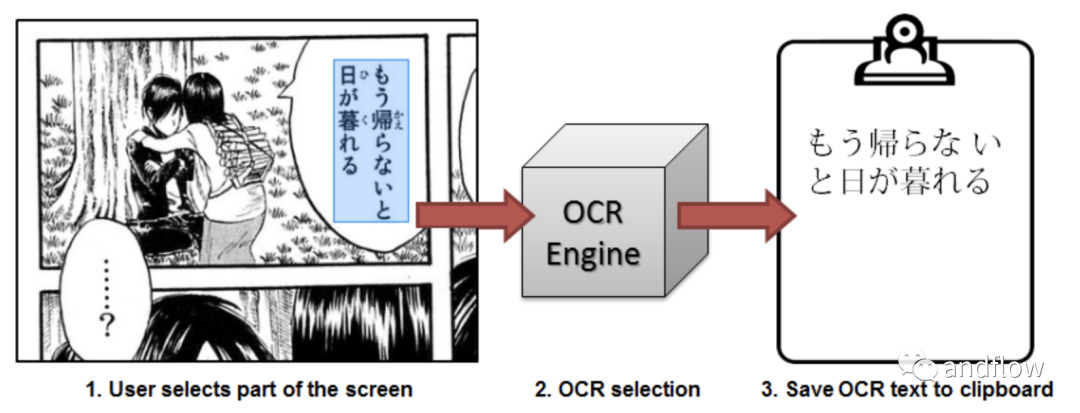
Capture2Text是一个基于命令行的Windows OCR软件。它支持多种语言,包括日语。它不仅能识别水平的字符,还能识别垂直的字符。可以在你需要的时候使用windows命令行调用OCR命令,识别出的文本将被保存进剪贴板。
9.NDLOCR
https://github.com/ndl-lab
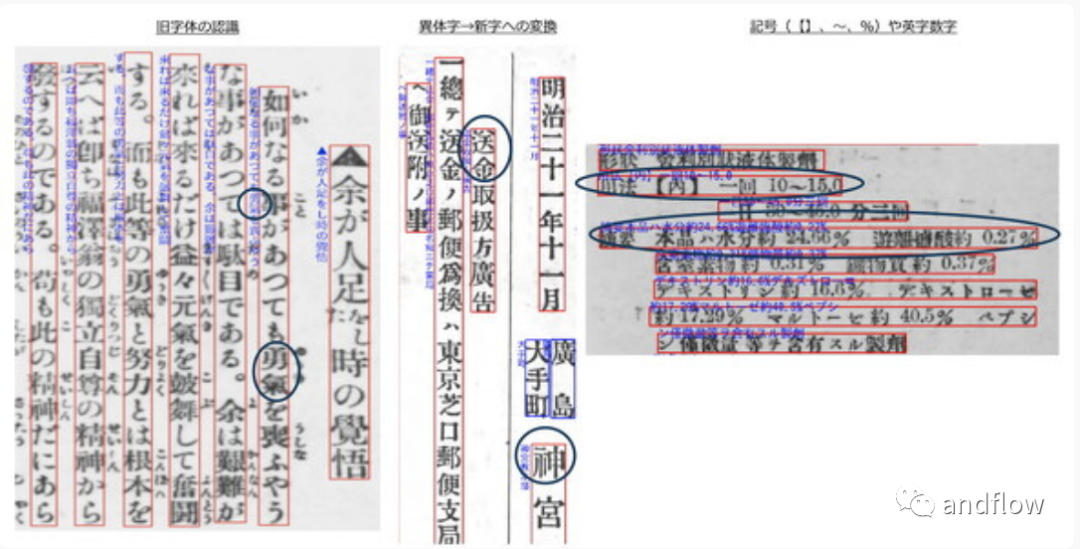
NDLOCR日本国立国会图书馆开源的ocr项目,比较适合古籍中一些复杂排版的ocr识别。比较适合日本语言的识别。
另外,它也支持在识别的文本中备注汉字读音、删除非字符,以及在广告区域读取字符的功能。还采取了一些有趣的举措,例如:根据年龄提高识别准确性。
项目只适合研究学习,至于实际的汉字识别用场景难以使用。
10.OCRmyPDF
https://github.com/ocrmypdf/OCRmyPDF

OCRmyPDF是一个专门用于PDF的OCR识别软件,它能够将识别到的文本信息作为透明的文本添加到PDF中。因此,您可以在PDF中搜索文本。
如果您将其用于没有文本信息的PDF,则可以进行搜索,从而增加了方便性。由于它基于Tesseract OCR引擎进行文本识别,因此也支持中文。

11.EasyOCR
https://github.com/JaidedAI/EasyOCR

EasyOCR基于机器学习(CRNN)实现OCR功能。它能够识别超过80种语言的文字,包括简体中文和繁体中文。它是使用python开发的,因此使用Python调用也非常简单。例如:
识别包含中文的图片:
识别结果为:

更多的例子可以通过以下这个网址进行测试:https://www.jaided.ai/easyocr/
12.kraken
https://github.com/mittagessen/kraken

kraken是一个由Python开发的OCR软件,主要用于非拉丁字符的识别。它支持从右到左书写的语言,例如阿拉伯语,也支持从上到下书写的语言,例如日语。可以从命令行运行OCR识别PDF、JPEG和TIFF等格式的文件。
它的特点包括:
- 支持自定义训练的布局分析和字符识别
- 支持从右到左, 自上而下的识别
- 提供ALTO、PageXML、abbyyXML和hOCR 格式输出
- 能够识别单词边界框,支持字符剪切
- 多脚本识别支持
- 模型文件的公共存储库
- 动图识别网络架构
更多的介绍可以参考网站:https://kraken.re/main/index.html
总之
以上介绍的这些OCR软件可以为项目的OCR技术选型或者OCR研发提供一个参考。另外,在一些垂直领域业务应用的时候也可以结合自身业务需求自主训练识别模型来提高应用效果。随着AI技术的发展,OCR识别准确性也将不断提高。