如今,GPT-4、PaLM等巨型神经网络模型横空出世,已经展现出惊人的少样本学习能力。
只需给出简单提示,它们就能进行文本推理、编写故事、回答问题、编程......
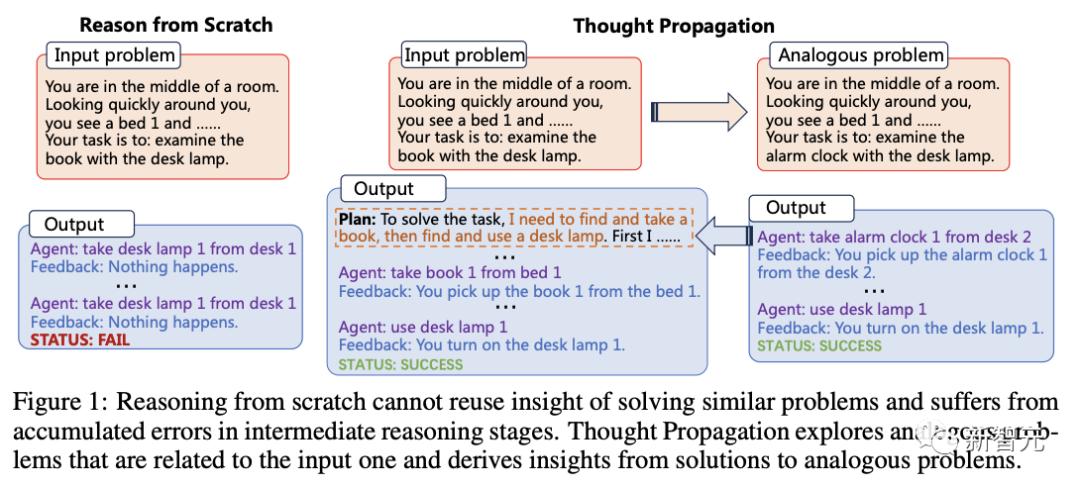
对此,中国科学院和耶鲁大学的研究人员提出了一种「思维传播」(Thought Propagation)新框架,能够通过「类比思维」增强LLM的推理。

论文地址:https://arxiv.org/abs/2310.03965
「思维传播」灵感来自人类认知,即当遇到一个新问题时,我们经常将其与我们已经解决的类似问题进行比较,以推导出策略。
因此,这一方法的核心便是,让LLM在解决输入的问题之前,探索与输入相关的「类似」问题。
最后,它们的解决方案可以拿来即用,或提取有用计划的见解。
可以预见的是,「思维传播」在为LLM逻辑能力的固有限制提出的全新思路,让大模型像人类一样用「类比」方法解决难题。
LLM多步推理,败给人类
显而易见,LLM擅长根据提示进行基本推理,但在处理复杂的多步骤问题时仍有困难,比如优化、规划。
反观人类,他们会汲取类似经验中的直觉来解决新问题。
大模型无法做到这点,是由其固有的局限性决定的。
因为LLM的知识完全来自于训练数据中的模式,无法真正理解语言或概念。因此,作为统计模型,它们很难进行复杂的组合泛化。

最最重要的是,LLM缺乏系统推理能力,无法像人类那样逐步推理,从而解决具有挑战性的问题。
再加上,大模型的推理是局部的、「短视的」,因此LLM很难找到最佳解决方案,也很难在长时间范围内保持推理的一致性。
总之,大模型在数学证明、战略规划和逻辑推理方面的缺陷,主要源于2个核心问题:
- 无法重用先前经验中的见解。
人类从实践中积累了可重复使用的知识和直觉,有助于解决新问题。相比之下,LLM在处理每个问题时都是 「从0开始」,不会借鉴先前的解决方案。
- 多步骤推理中的复合错误。
人类会监控自己的推理链,并在必要时修改最初的步骤。但是LLM在推理的早期阶段所犯的错误会被放大,因为它们会把后面的推理引向错误的道路。
以上这些弱点,严重阻碍了LLM应对需要全局最优或长期规划的复杂挑战中的应用。
对此,研究人员提出了一种全新的解决方法——思维传播。
TP框架
通过类比思维,让LLM更像人类一样进行推理。
在研究者看来,从0开始推理无法重复使用解决类似问题的见解,而且会在中间推理阶段出现错误累积。
而「思维传播」可以探索与输入问题相关的类似问题,并从类似问题的解决方案中获得启发。
下图是「思维传播」(TP)与其他代表性技术的比较,对于输入问题 p,IO、CoT和ToT会从头开始推理,才得出解决方案s。
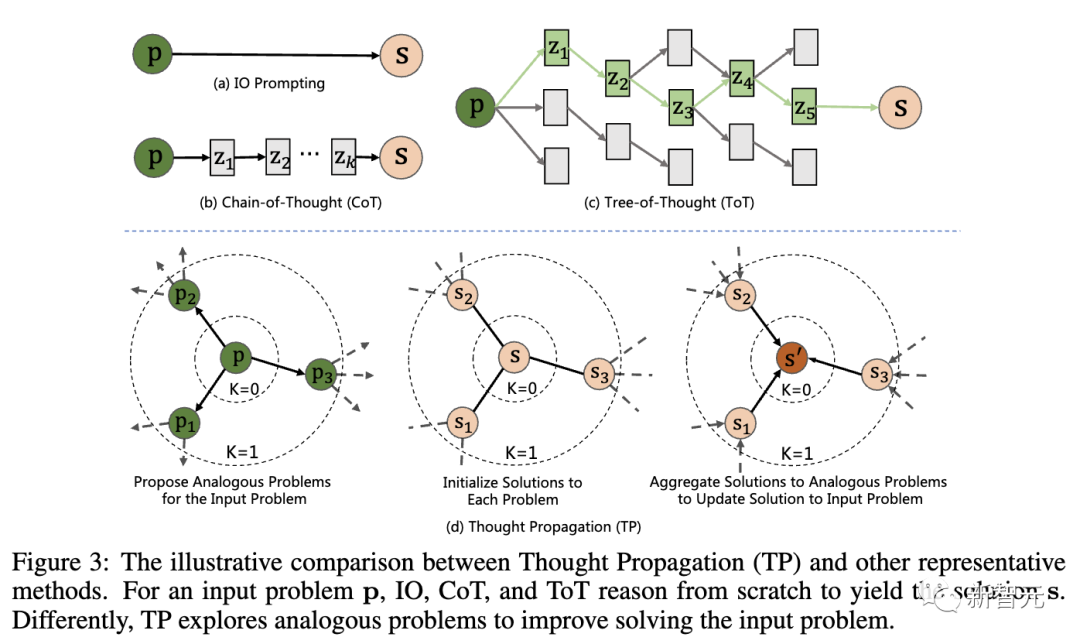
具体来说,TP包括了三个阶段:
1. 提出类似问题:LLM通过提示生成一组与输入问题有相似之处的类似问题。这将引导模型检索潜在的相关先前经验。
2. 解决类似问题:通过现有的提示技术,如CoT,让LLM解决每个类似的问题。
3. 汇总解决方案:有2种不同的途径——根据类比解决方案,直接推断出输入问题的新解决方案;通过比较输入问题的类比解决方案,推导出高级计划或策略。
这样一来,大模型就可以重用先前的经验和启发式方法,还可以将其初始推理与类比解决方案进行交叉检查,以完善这些解决方案。
值得一提的是,「思维传播」与模型无关,可以在任何提示方法的基础上进行单个问题解决步骤。
这一方法关键的新颖之处在于,激发LLM类比思维,以引导复杂的推理过程。
「思维传播」究竟能让LLM多像人类,还得实操结果来说话。
中国科学院和耶鲁的研究人员在3个任务中进行了评估:
- 最短路径推理:需要在图中找到节点之间的最佳路径需要全局规划和搜索。即使在简单的图上,标准技术也会失败。
- 创意写作:生成连贯、有创意的故事是一个开放式的挑战。当给出高层次的大纲提示时,LLM通常会失去一致性或逻辑性。
- LLM智能体规划:与文本环境交互的LLM智能体与长期战略方面举步维艰。它们的计划经常会出现「漂移」或陷入循环。
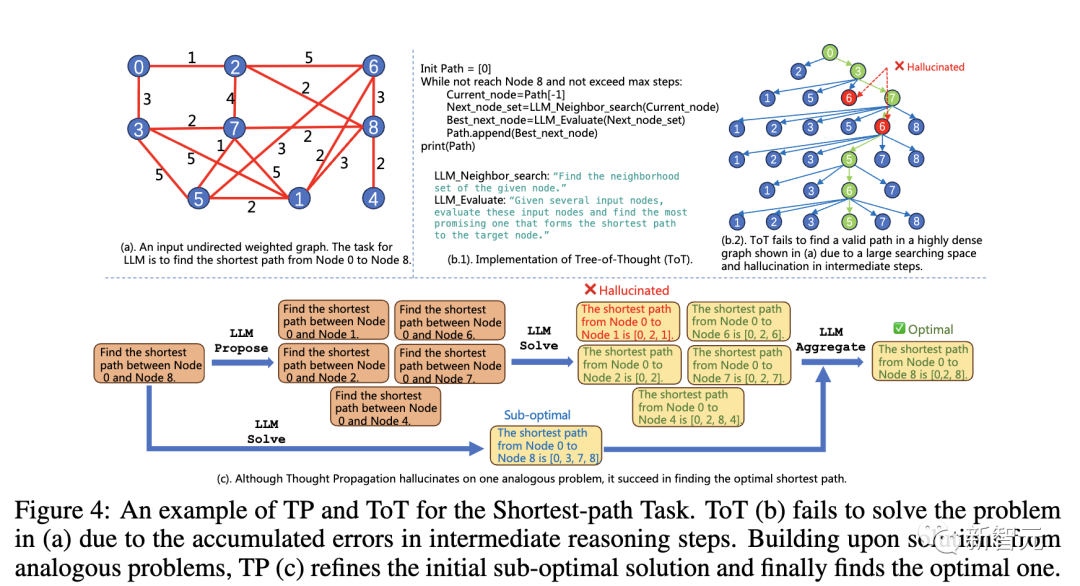
最短路径推理
最短路径推理任务中,现有的方法推理遇到的问题无法解决。
虽然(a)中的图非常简单,但由于推理从0开始,这些方法只能让LLM找到次优解(b,c),甚至重复访问中间节点(d)。

如下是结合了TP和ToT使用的例子。
由于中间推理步骤的错误累积,ToT (b) 无法解决 (a) 中的问题。基于类似问题的解决方案,TP (c) 完善了最初的次优解决方案,并最终找到了最优解决方案。
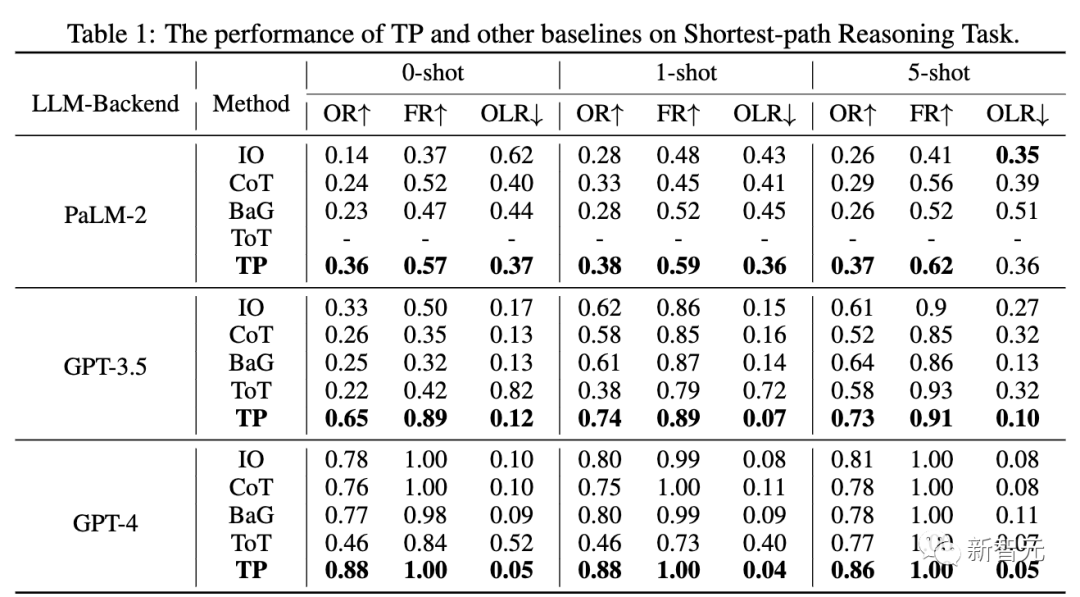
通过与基线比较,TP在处理最短路径任务中的性能显著提升了12%, 生成了最优和有效的最短路径。
此外,由于OLR最低,与基线相比,TP生成的有效路径最接近最优路径。
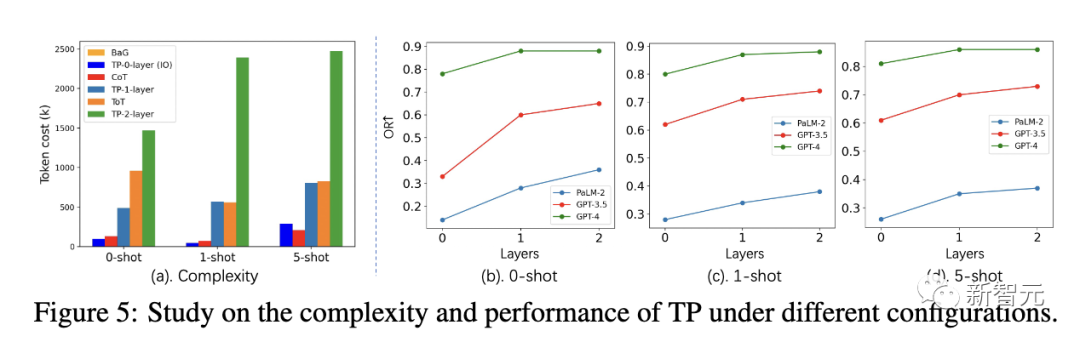
同时,研究人员还进一步研究了TP层数对最短路径任务复杂性和性能的影响。
在不同设置下,1层TP的token成本与ToT类似。但是,1层TP在寻找最优最短路径方面,已经取得了非常有竞争力的性能。
此外,与0层TP(IO)相比,1层TP的性能增益也非常显著。图5 (a) 显示了2层TP的token成本增加。
创意写作
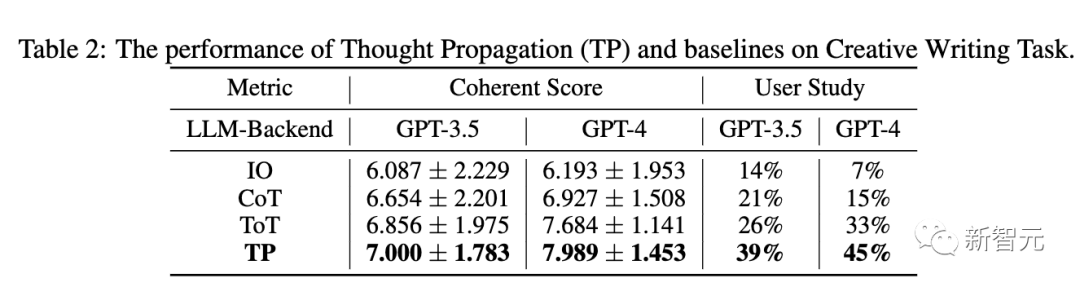
下表2显示了TP和基线在GPT-3.5和GPT-4中的表现。在一致性上,TP都超过了基线。另外,在用户研究中,TP在创意写作中人类偏好提高了13%。
LLM智能体规划
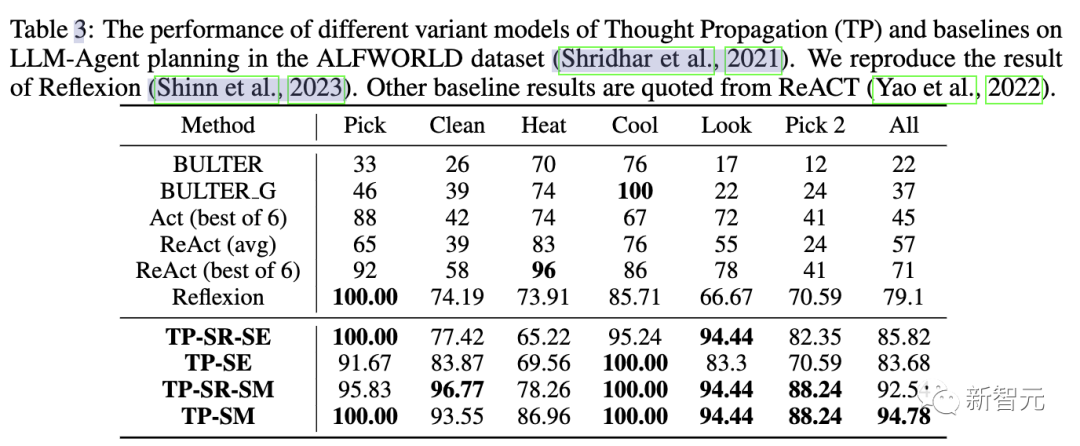
在第三个任务评估中,研究人员使用ALFWorld游戏套件,在134个环境中实例化LLM智能体规划任务。
TP在LLM智能体规划中任务完成率提高15%。这表明,在完成类似任务时,对成功规划的反思TP具有优越性。
通过以上的实验结果表明,「思维传播」可以推广到各种不同的推理任务中,并在所有这些任务中表现出色。
增强LLM推理的关键
「思维传播」模型为复杂的LLM推理提供了一种全新的技术。
类比思维是人类解决问题能力的标志,它可以带来一系列系统性的优势,比如更高效的搜索和错误纠正。
类似的,LLM也能通过提示类比思维,更好地克服自身弱点,如缺乏可重用的知识和级联的局部错误等。
然而,这些研究结果存在一些限制。
高效地生成有用的类比问题并不容易,而且链式更长的类比推理路径可能会变得臃肿不堪。同时,控制和协调多步推理链也依旧十分困难。
不过,「思维传播」还是通过创造性地解决LLM的推理缺陷,为我们提供了一个有趣的方法。
随着进一步的发展,类比思维可能会使LLM的推理变得更加强大。而这也为在大语言模型中实现更像人类的推理指明了道路。
作者介绍
Ran He(赫然)

赫然是中国科学院自动化研究所模式识别国家实重点验室和中国科学院大学的教授, IAPR Fellow和IEEE高级会员。
此前,他在大连理工大学获得学士和硕士学位,并于2009年于中国科学院自动化研究所获得博士学位。
他的研究方向是生物识别算法(人脸识别与合成、虹膜识别、人物再识别)、表征学习(使用弱/自监督或迁移学习预训练网络)、生成学习(生成模型、图像生成、图像翻译)。
他在国际期刊和会议上发表了200多篇论文,其中包括IEEE TPAMI、IEEE TIP、IEEE TIFS、IEEE TNN、IEEE TCSVT等著名国际期刊,以及CVPR、ICCV、ECCV、NeurIPS等顶级国际会议。
他是IEEE TIP、IEEE TBIOM和Pattern Recognition编委会成员,并曾担任CVPR、ECCV、NeurIPS、ICML、ICPR和IJCAI等国际会议的区域主席。
Junchi Yu(俞俊驰)

俞俊驰是中国科学院自动化研究所的四年级博士生,导师是赫然教授。
此前,他曾在腾讯人工智能实验室实习,并与Tingyang Xu博士、Yu Rong博士、Yatao Bian博士和Junzhou Huang教授共事。目前,他是耶鲁大学计算机科学系的交流生,师从Rex Ying教授。
他的目标是开发具有良好可解释性和可移植性的可信图学习(TwGL)方法,并探索其在生物化学方面的应用。