













生成模型在图像生成领域取得了巨大的成功,但将这一技术扩展到 3D 领域一直面临着重重挑战。典型的多头怪问题,即文本生成3D中多视角一致性问题,一直得不到很好的解决。谭平团队最新的研究论文都致力于解决这一基础问题,为这一领域带来了突破和创新。
谭平博士是香港科技大学电子与计算机工程系教授。他曾经担任阿里巴巴达摩院XR实验室负责人,人工智能实验室计算机视觉首席科学家。于近期创立公司光影焕像,依然专注在3D领域,将自己多年的研究成果进行转化。
论文 "SweetDreamer" 采用3D数据对2D扩散模型进行Alignment,成功实现文本生成高质量3D模型的任务,解决几何不一致问题。通过赋予 2D 模型视角感知能力和引入规范坐标映射(CCM),它有效地对齐了 3D 几何结构,保留了多样化高质量物体的生成能力,并在人类评估中取得了 85% 以上的一致性,远超以往方法(仅 30% 左右),为文本到 3D 生成领域带来了新的技术突破。

- 论文地址:https://arxiv.org/pdf/2310.02596.pdf
- 论文网站:https://sweetdreamer3d.github.io/
论文 "Ctrl-Room" 采用了两阶段生成方式,即 "布局生成阶段" 和 "外观生成阶段",解决了文本生成 3D 室内场景的多视角不一致性问题。在布局生成阶段,该方法生成了合理的室内布局,考虑到了家具类型和位置,以及墙壁、门窗等因素。而在外观生成阶段,它生成了全景图像,确保了不同视角图像之间的一致性,从而保证了 3D 房间结构和家具排列的合理性。"Ctrl-Room" 甚至允许用户对生成的 3D 房间进行灵活编辑,包括调整家具大小、位置和语义类别等操作,以及替换或修改家具。

论文地址:https://arxiv.org/abs/2310.03602v1
论文网址:https://fangchuan.github.io/ctrl-room.github.io/
接下来,我们一起来看看这两篇论文的关键内容。
SweetDreamer
谭平团队和腾讯、华南理工共同合作的 SweetDreamer 重点解决文本生成 3D 物体中的多视角不一致性问题,通过改进 2D 扩散模型,成功将文本转化为高质量的 3D 对象,实现了文本到 3D 生成的重大突破。
“SweetDreamer” 的核心贡献在于解决了文本到 3D 生成中的多视图不一致性问题。团队指出,现有方法中的主要问题来自几何不一致性,即在将 2D 结果提升到 3D 世界时,由于 2D 模型仅学习视角无关的先验知识,导致多视图不一致性问题。这种问题主要表现为几何结构的错位,而解决这些错位结构可以显著减轻生成结果中的问题。因此,研究团队通过使 2D 扩散模型具备视角感知能力,并生成规范坐标映射(CCM),从而在提升过程中与 3D 几何结构对齐,解决了这一问题。
论文中的方法只使用了粗略的 3D 信息,只需要少量的 3D 数据。这种方式不仅解决了几何不一致性问题,还保留了 2D 扩散模型生成从未见过的多样化高质量物体的能力。
最终,他们的方法在人类评估中取得了 85% 以上的一致性,远超过以往的方法 30% 左右的结果,这意味着他们的方法在文本到 3D 生成领域实现了新的技术突破。这一研究不仅对于 3D 生成具有重要意义,还对于虚拟现实、游戏开发、影视制作领域等有着广泛的应用前景,为实现更高质量、更多样化的 3D 生成打开了新的可能性。
方法介绍
“SweetDreamer” 的核心目标是解决多视角不一致性的问题。这个问题主要可以从两个角度来看:几何不一致性问题,以及外观不一致性问题。团队通过研究发现,大多数 3D 不一致性问题的主要原因是几何结构的错位,因此这项技术的主要目标是通过改进 2D 先验模型,使其能够生成 3D 一致的几何结构,同时保持模型的通用性。
为了实现这一目标,团队提出了一种方法,即通过与 3D 数据集中的规范坐标映射(CCM)对齐的方式,确保 2D 扩散模型中的几何先验能够正确生成 3D 一致的几何结构。这项技术依赖 3D 数据集,并假设数据集中的模型都具有规范的方向和标准化的尺寸。然后,从随机角度渲染深度图,并将其转换为规范坐标。需要注意的是,这个过程的目标是对齐几何先验,而不是生成几何细节。
最后,通过对 2D 扩散模型进行微调,就能够在指定的视角下生成规范坐标图,从而对齐 2D 扩散模型中的几何先验。这些对齐的几何先验(AGP)可以轻松集成到各种文本到 3D 生成管道中,从而显著减轻了不一致性问题,最终产生高质量和多样化的 3D 内容。

“SweetDreamer” 的关键步骤如下:
- 规范坐标映射(CCM)。首先,为了简化建模过程,研究人员假设在训练数据中,同一类别的所有物体都遵循规范的方向。然后,他们将物体的大小归一化,使得其包围框的最大范围长度为 1,并且位于原点的中心。此外,他们还对从物体渲染的坐标映射进行了各向异性缩放,以增强不同视角下薄结构的空间坐标差异,从而改善了对 3D 结构的感知。
- 相机信息注入。虽然规范坐标映射包含粗略的视角信息,但研究人员发现扩散模型难以有效利用它。因此,他们将相机信息注入模型以提高视角感知。这个步骤的目的是生成粗略的几何结构,而不是准确的 3D 模型。
- 微调 2D 扩散模型。在获得规范坐标映射和相应的相机参数之后,研究人员微调 2D 扩散模型,以在特定视角条件下生成规范坐标映射,最终对齐 2D 扩散模型中的几何先验。
这一技术不仅解决了多视角 3D 结构一致,并且保持了 2D 扩散模型的灵活性和丰富性,可以被集成到不同的渲染管线中。团队在文中展示了两种不同的渲染管线,分别是基于神经辐射场(NeRF)的 DreamFusion 和基于传统三角网格的 Fantasia3D。

基于神经辐射场的管线:团队对 3D 对象进行体素渲染,以获取 RGB 图像,并将其输入到扩散模型以计算 SDS 损失。在优化期间,团队渲染规范坐标映射(CCM),并将其输入到对齐几何先验(AGP),以计算几何 SDS 损失来更新 NeRF 的几何分支。
基于传统三角网格的管线:这里只需要添加一个额外的并行分支,将对齐几何先验(AGP)纳入原始流程的几何建模监督中。在优化的时候,团队将对齐几何先验(AGP)在粗略和精细几何建模阶段都作为额外的监督引入,就可以轻松获得高质量和视角一致的结果。
实验结果呈现
通过将 AGP 集成到文本生成 3D 的网络中,结果得到了显著改善。原始的方法容易受到多视角不一致性的干扰,而生成多头、多手等几何结构错乱的结果。团队发现新的方法对结果有明显的提升,生成的结果明显具有高度的 3D 一致性。
团队的定量评估着重于评估 3D 结果的多视角一致性。具体而言,团队随机选择了 80 个文本提示,执行文本到 3D 合成,生成了每种方法的 80 个结果。然后手动检查和统计 3D 不一致性(例如,多个头、手或腿)的出现次数,并报告成功率,即 3D 一致对象的数量除以生成结果的总数。结果表明,SweetDreamer 在两种渲染管线中的成功率都超过了 85%,而之前的方法只有大约 30%。

团队认为,尽管同时期的工作 MVDream 也可以解决多视角不一致性问题,但它容易过拟合有限的 3D 数据,扩散模型的泛化性能受到影响。例如使用提示词 “一张猪背着背包的图像”,MVDream 会漏掉 “背包” 的存在。相比而言,AGP 的结果有更丰富的外观,这是因为 AGP 仅对几何建模产生影响,而不会影响由扩散模型从数十亿真实图像中学到的强大的外观先验。
Ctrl-Room
谭平团队和南开大学共同合作的 Ctrl-Room 重点解决文本生成 3D 室内场景中的多视角不一致性问题,通过解耦布局和外观,可以用文字提示实现逼真的 3D 室内场景生成,而且还可以对室内物品进行灵活编辑,包括调整大小和移动位置等操作。
"Ctrl-Room" 的核心贡献在于方法采用了一种创新的两阶段生成方式,分别是 "布局生成阶段" 和 "外观生成阶段"。在布局生成阶段,该方法可以生成合理的室内布局,包括各种家具类型和位置,甚至考虑到了有门窗的墙壁。这一阶段的关键是采用了一种全面的场景代码参数化方法,将房间表示为一组对象,每个对象由一个向量表示,其中包括其位置、大小、语义类别和方向。
在外观生成阶段,该方法生成了室内场景的外观,将其呈现为全景图像。与以往的文本生成全景图方法不同,这一方法明确遵循了室内布局约束,能够确保各个不同视角图像之间的一致性,确保了 3D 房间结构和家具排列的合理性。
最重要的是,由于布局与外观分离的设计,"Ctrl-Room" 允许对生成的 3D 房间进行灵活编辑。用户可以轻松地调整家具物品的大小、语义类别和位置。这一方法甚至允许用户通过指令或鼠标点击来替换或修改家具,而无需昂贵的特定于编辑的训练。
方法介绍
这项技术分为两个关键阶段:布局生成阶段和外观生成阶段。在布局生成阶段,团队通过一种全面的场景代码来描述室内场景,并利用扩散模型学习其分布。这样就可以从文字输入中生成房间的整体结构,包括墙壁和各种物品的位置和大小。用户可以随心所欲地编辑这些物品,拖拽它们、调整它们的类型、位置或大小,以满足用户的个性化需求。
在外观生成阶段,团队通过一个经过预训练的扩散模型生成室内场景的纹理,将室内布局转化为全景图。为了确保图像的左右连贯,团队提出了一种新的循环一致性采样方法,使室内场景看起来更加真实。最终,通过估算生成的全景图的深度图来获得带纹理贴图的 3D 场景。

“Ctrl-Room” 的关键步骤如下:
1. 布局生成阶段
这个阶段的主要目标是从文本输入中创建室内三维场景的布局。与以往方法不同,团队不仅仅考虑了家具,还包括了墙壁、门和窗户等要素,以更全面地定义室内场景的布局。
团队将室内场景中的各个元素编码成一种统一的格式,并将其称为 “场景代码”。这个代码包含了室内场景中所有元素的信息,包括它们的位置、尺寸、朝向和类别。然后团队利用这个场景代码来构建一个扩散模型,用于学习场景布局的分布。
这个模型通过逐渐向场景代码添加高斯噪声来创建一个离散时间的马尔可夫链。噪声逐渐增加,直到最终的分布呈现高斯分布。然后,通过训练神经网络来反向这个过程,从添加了噪声的场景代码中还原出干净的场景代码。这个过程能够将文本输入转化为具体的场景布局,为后续的场景生成和编辑提供了基础。
在布局生成阶段的末尾,场景代码被表示为一组不同语义类型的包围盒,这些包围盒将用于后续的交互式编辑,允许用户根据自己的需求自定义 3D 场景。
2. 外观生成阶段
这个阶段旨在根据室内场景的布局信息生成合适的全景图像,以表现其外观。过去有的方法采用增量式的方式,逐步生成不同视角的图像来合成全景图,但容易受到多视角不一致性的影响,导致最终的全景图不能保持合理的房间结构。这里团队利用了 ControlNet 技术,根据布局的结果一次性生成整个全景图,可以更好保持房间结构。
为了实现这一点,团队将包围盒表示的布局转换成了语义分割全景图。然后,研究团队对 ControlNet 进行了微调,使用了结构化 3D 数据集来增强训练数据。团队还引入了 "循环一致采样" 的概念,以确保生成的全景图在左右两侧无缝连接。
3.交互编辑
这个模块允许用户通过更改物体包围盒的位置、语义类别和大小来修改生成的三维室内场景。这一编辑过程需要实现两个目标,即根据用户的输入改变内容,并保持未编辑部分的外观一致性。
这个编辑过程分为两个步骤,填充步骤和优化步骤。填充步骤是为了将物体移动后露出部分进行填充。而优化步骤是为了保持被移动过的家具、物品的外观一致性。
实验结果呈现
研究人员使用了包含 3,500 个由专业艺术家设计的房屋的 3D 室内场景数据集 Structured3D 对模型进行评估。为了评估方法,研究人员选取了 4,961 个卧室和 3,039 个客厅,其中 80% 用于训练,其余用于测试。
相比以往的算法,例如 Text2Room 和 MVDiffusion,Ctrl-Room 能够更好保持房间结构。而 Text2Room 和 MVDiffusion 往往在不同视角的图像中反复生成同一个物体,例如在客厅中多次重复壁炉、电视机,在卧室中多次重复床等显著性高的物体。因此这些方法生成的场景往往从全局结构上看非常混乱。而 Ctrl-Room 通过显示的引入房间布局的生成,并用布局引导最终室内场景的生成,可以非常好的解决这个问题。

为了衡量生成的全景图像的质量,团队使用了 Frechet Inception Distance (FID)、CLIP Score (CS) 和 Inception Score (IS) 等指标。此外,研究人员还比较了生成 RGB 全景图像的时间成本,以及生成的 3D 室内场景的质量,包括 CLIP Score (CS) 和 Inception Score (IS)。
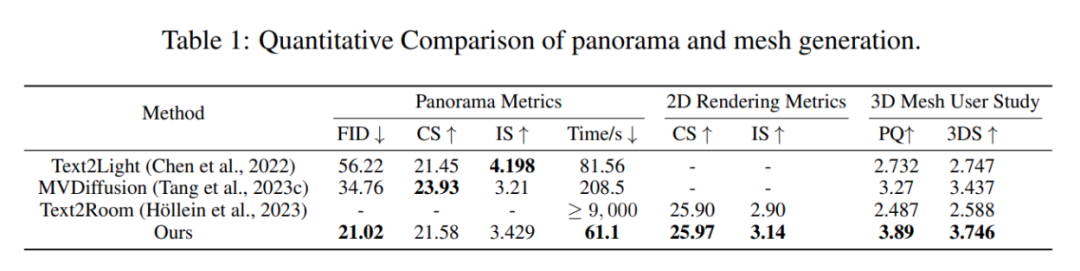
Ctrl-Room 在生成全景图像方面表现出色。它在 FID 指标上取得了最佳成绩,并大幅领先其他对比方法,这意味着它能更好地捕捉房间的外观,因为它能忠实地恢复房间布局。而 CS 指标对房间内物体的数目并不敏感,即便一个卧室中生成了 3-4 张床 CS 指标也可以很高,因此不能准确评价场景生成。与此同时,Ctrl-Room 在生成时间方面表现出色,相对于其他方法,它需要更短的时间。
团队还进行了用户研究,询问了 61 名用户对最终室内场景的感知质量和 3D 结构完整性进行评分。Ctrl-Room 技术也被用户认为在房间布局结构和家具排列方面具有更清晰的优势。











