Tesseract库的概述
在当今数字化时代,光学字符识别(OCR)技术正变得越来越重要。OCR技术使得计算机能够识别和理解印刷或手写的文本,从而使得文档的数字化处理和搜索变得更加便捷。在OCR领域,Tesseract库是一个备受推崇的开源OCR引擎,它提供了一种可靠且高效的方式来实现文本识别。
Tesseract库最初由惠普实验室于1985年开发,后来被Google收购并于2006年开源。自那时以来,Tesseract库经历了多个版本的迭代和改进,现在已经成为OCR领域的先驱之一。它支持超过100种语言,并且在各种操作系统上都能够运行,包括Windows、Linux和Mac OS。
Tesseract库的核心功能是将输入的图像转换为可编辑的文本。它能够处理各种图像格式,包括JPEG、PNG和TIFF等。Tesseract库使用了一种称为“光学字符识别”的算法,该算法通过分析图像中的像素信息来识别和提取文本。它能够识别不同字体、大小和颜色的文本,并且在处理扫描文档或摄影图像时表现出色。
Tesseract库的使用非常简单,它提供了丰富的API和命令行工具。作为一个程序员,可以使用Tesseract库的API将其集成到应用程序中。如果更喜欢命令行界面,可以使用Tesseract库的命令行工具来进行文本识别。无论是想要识别单个图像还是批量处理大量图像,Tesseract库都能够满足需求。
除了基本的文本识别功能,Tesseract库还提供了一些高级特性。例如,它支持文本方向检测和自动校正,可以自动识别和修复图像中的文字方向。它还支持多种语言模型,可以根据需要加载不同的语言模型来提高识别准确性。此外,Tesseract库还支持字典和格式规则,可以用于提高特定领域的文本识别效果。
尽管Tesseract库是一个强大的OCR引擎,但它并不是完美的。在某些情况下,它可能会出现识别错误或无法处理特定的图像。然而,Tesseract库具有开源的优势,这意味着可以自己修改和改进它,以满足你的特定需求。
Tesseract库适用场景
- 文字识别:Tesseract是一个强大的OCR引擎,适用于从印刷体文本中提取文字。它可以处理多种语言,并且在识别准确性方面表现良好。因此,如果您需要从扫描文档、照片或其他图像中提取文本信息,Tesseract是一个理想的选择。
- 多语言支持:Tesseract支持超过100种不同语言的文本识别,包括中文、英文、法文、德文、日文等。这使得它适用于跨语言的应用程序和项目。
- 跨平台应用:Tesseract可以在多个平台上运行,包括Windows、Linux、macOS和Android。因此,无论您是运行在哪个操作系统上,都可以使用Tesseract进行文本识别任务。
- 图像处理:Tesseract对输入图像有一定的要求,它需要清晰度较高、对比度良好的图像才能达到较好的识别效果。因此,如果您的应用程序需要对图像进行预处理、增强或调整,Tesseract可以与图像处理库(如OpenCV)结合使用,以提供更好的识别结果。
- 开源项目和研究:作为一个开源项目,Tesseract是一个受欢迎的选择,特别适用于开发人员和研究人员。您可以自由访问和修改Tesseract的源代码,以满足特定需求,并参与Tesseract社区的改进和扩展。
Tesseract库的优缺点
Tesseract库作为一款开源的OCR引擎,具有以下优点和缺点:
优点:
- 准确性:Tesseract在文本识别方面具备较高的准确性,尤其对于印刷体文字的识别效果较好。它经过多次改进和优化,可以提供可靠的结果。
- 多语言支持:Tesseract支持超过100种不同语言的文本识别,包括中文、英文、日文、法文等。这使得它适用于全球范围内的多语言场景。
- 跨平台支持:Tesseract可以在多个平台上运行,包括Windows、Linux、macOS和Android。这使得它可以被广泛应用于各种应用程序和系统中。
- 自由开源:Tesseract是一个开源项目,使用和修改都是免费的。这意味着开发人员可以自由地访问和定制Tesseract的代码,以满足特定需求。
- 易于集成:Tesseract提供了多种编程语言的API接口,如C++、Python、Java等,使得开发人员可以方便地将Tesseract集成到他们的应用程序中。
缺点:
- 图像处理要求高:Tesseract对输入图像的质量要求较高,需要清晰、高分辨率的图像才能达到较好的识别效果。模糊、低对比度或噪声较多的图像可能会导致准确率下降。
- 对表格和结构化数据支持有限:Tesseract主要专注于识别文本,对于复杂的表格、结构化数据和图像中的特定格式(如日期、邮政编码)的识别可能不够强大。
- 难以处理手写体:与印刷体文字相比,Tesseract对手写体文字的识别能力较差。手写体的形状和风格变化较大,使得准确识别手写文字更加困难。
- 需要预处理:为了提高识别准确性,通常需要在使用Tesseract之前进行图像预处理,如清晰度增强、去噪等操作。这增加了整体识别过程的复杂性和时间消耗。
- 缺少高级特性:相对于一些商业OCR引擎,Tesseract的功能相对较基础。它缺乏一些高级特性,如表格分析、语义理解等。
Net项目中使用Tesseract库的安装和配置
基本流程:

- 安装 Tesseract OCR 引擎: 前往 Tesseract 官方网站(https://github.com/tesseract-ocr/tesseract)下载并安装最新版本的 Tesseract OCR 引擎。根据您的操作系统选择适当的安装包,并按照说明进行安装。
- 安装 Tesseract.NET 包: 在 Visual Studio 中打开您的 .NET 项目解决方案,通过 NuGet 包管理器或包管理控制台安装 Tesseract.NET 包。Tesseract.NET 是一个提供对 Tesseract 引擎的封装的.NET库,使您可以在.NET项目中轻松地使用 Tesseract 功能。
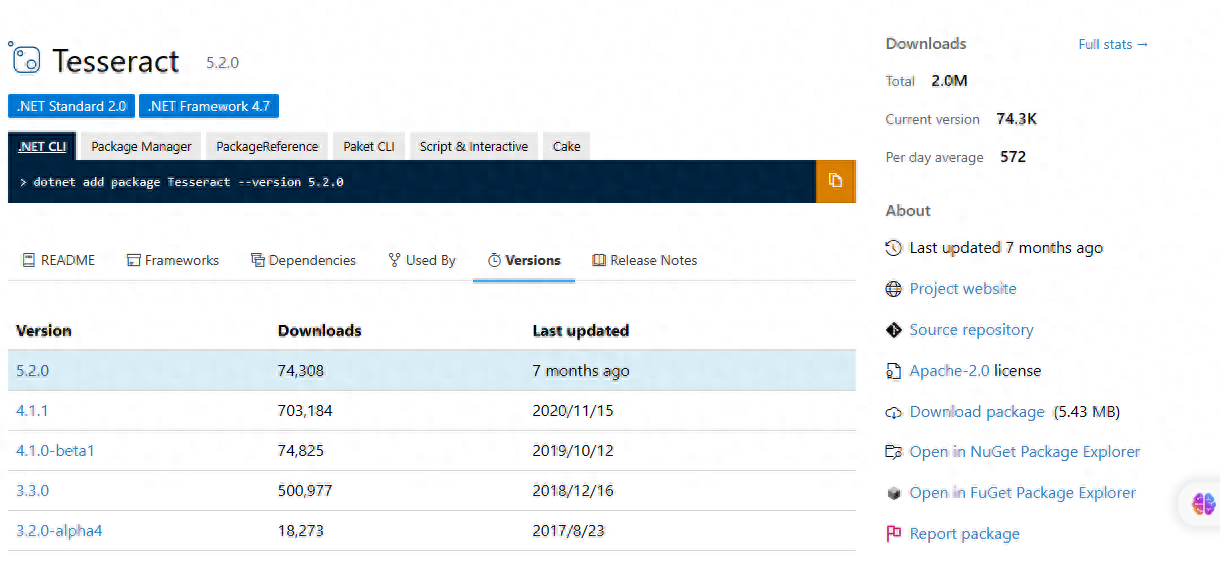
- 配置 Tesseract 数据文件: Tesseract 需要语言数据文件才能进行文本识别。您可以从 Tesseract GitHub 存储库(https://github.com/tesseract-ocr/tessdata)下载所需的语言数据文件。将这些文件放置在您的项目中一个可访问的位置,以供 Tesseract 使用。
- 初始化 Tesseract 引擎: 在您的 .NET 代码中,使用 Tesseract.NET 库初始化 Tesseract 引擎。首先,引入 Tesseract 命名空间,然后创建一个 TesseractEngine 对象,并设置语言数据文件路径和其他配置选项。
using Tesseract;
// ...
// 设置语言数据文件路径
string tessDataDir = @"C:\path\to\your\tessdata";
string language = "eng";
// 创建 TesseractEngine 对象
var engine = new TesseractEngine(tessDataDir, language, EngineMode.Default);- 进行文本识别: 使用初始化的 TesseractEngine 对象,您可以加载图像并对其进行文本识别。例如,您可以将图像加载到 Pix 对象中,然后使用 Recognize 方法进行文本识别。示例如下:
using Tesseract;
// ...
// 加载图像到 Pix 对象
using (var image = Pix.LoadFromFile("path/to/your/image.png"))
{
// 对图像进行文本识别
using (var page = engine.Process(image))
{
string extractedText = page.GetText();
Console.WriteLine(extractedText);
}
}示例代码
当使用Tesseract库进行图像识别时,下面是一个简单的示例代码:
using System;
using System.Drawing;
using Tesseract;
namespace TesseractExample
{
class Program
{
static void Main(string[] args)
{
try
{
// 初始化Tesseract引擎
using (var engine = new TesseractEngine("./tessdata", "eng", EngineMode.Default))
{
// 加载图像
using (var image = new Bitmap("image.png"))
{
// 图像预处理
using (var processedImage = PreprocessImage(image))
{
// 进行文本识别
string result = ExtractTextFromImage(engine, processedImage);
// 打印识别结果
Console.WriteLine(result);
}
}
}
}
catch (Exception ex)
{
Console.WriteLine("发生错误:" + ex.Message);
}
Console.ReadLine();
}
private static Bitmap PreprocessImage(Bitmap image)
{
// 在这里添加图像预处理逻辑,例如调整大小、灰度化、去噪等
// 示例:将图像调整为指定的宽度
int targetWidth = 800;
int targetHeight = image.Height * targetWidth / image.Width;
Bitmap processedImage = new Bitmap(targetWidth, targetHeight);
using (Graphics graphics = Graphics.FromImage(processedImage))
{
graphics.DrawImage(image, 0, 0, targetWidth, targetHeight);
}
// 返回预处理后的图像
return processedImage;
}
private static string ExtractTextFromImage(TesseractEngine engine, Bitmap image)
{
using (var img = PixConverter.ToPix(image))
{
using (var page = engine.Process(img))
{
var text = page.GetText();
return text;
}
}
}
}
}在上述示例代码中,我们实现了一个控制台应用程序。在Main方法中,我们进行了以下操作:
- 初始化Tesseract引擎,并指定Tesseract数据文件的路径和语言。
- 使用Bitmap类加载图像。
- 调用PreprocessImage方法对图像进行预处理。
- 调用ExtractTextFromImage方法从预处理后的图像中提取文本。
- 打印识别结果到控制台。
请注意,示例中使用的图像是名为"image.png"的文件。您需要将其替换为您自己的图像文件路径。
以下是关于Tesseract的一些学习资料
- 官方网站:https://github.com/tesseract-ocr/tesseract。
- Tesseract GitHub存储库:https://github.com/tesseract-ocr/tesseract。
- Tesseract的文档:https://tesseract-ocr.github.io/tessdoc/。
- Tesseract的安装指南和用法:https://github.com/tesseract-ocr/tesseract/wiki。
- Tesseract支持的语言列表:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#data-files-for-version-400-november-29-2016。
- Tesseract的示例代码和用法:https://github.com/tesseract-ocr/tesseract/wiki/CodeExamples。
- Tesseract.NET库:https://github.com/charlesw/tesseract。