一、大数据集群现状
首先来介绍一下 EasyEagle 诞生的背景。
1、Hadoop 大数据生态圈现状

EasyEagle 是一个大数据智能运维平台服务,智能运维主要是为了监控、分析与解决大数据平台在使用过程中遇到的诸多问题。在长时间的大数据研发及运维实践中,我们发现大数据组件以及任务在治理运维中存在许多问题,可以总结为四个不透明:
- 首先是服务健康不透明。比如 HDFS、Hive 等这类组件服务,他们的健康情况是不透明的。主要表现为三个方面,第一是组件服务是否真正可用是不透明的,很多公司会使用进程监控来看服务是不是异常了,但实际上很多情况下进程变成了僵尸进程,看起来进程还在,但是服务已经不可用了。第二是服务虽然可用,但实际上存在健康风险,可能运行一段时间后就不能正常工作了。第三是服务组件出现了异常,如何快速的定位、分析以及解决。这三个方面问题在原生的 Hadoop 生态里目前是没有提供解决方案的。
- 第二是计算资源不透明。首先大数据集群的队列资源水位怎么样是不清楚的,哪些队列的资源使用率高,哪些空闲。其二是任务的真实资源利用率是怎么样的不清楚,真实资源利用率指的是任务实际执行过程中使用的资源量与任务申请资源量的比值,有可能申请的多但使用的很少。其三,假如队列的资源水位比较高,那么哪些任务的资源申请最多,这些任务是否真正需要申请这么多资源,这部分信息是拿不到的。这些计算资源的不透明导致在集群运行时,出现了非常普遍的资源浪费以及任务运行效率偏低。
- 第三是任务运行不透明,指的是Spark任务、Hive任务或Impala任务运行过程中的细节信息不透明。比如某个Spark任务今天比昨天执行的耗时长了很多,那到底耗时长在哪里,现在实际是没有的。另外,集群中跑了几千个或上万个任务,这其中哪些任务可以进行参数优化提高运行效率,当前系统并没有提供这些信息。
- 最后是存储资源不透明。在实际的运维实践中,包括跟客户的沟通过程中发现,很多客户反馈现在集群容量水位比较高,已经到百分之七八十了。这种情况下被动的解决方案是扩容机器,但这是要增加企业成本的,更加主动的解决方案是进行存储资源治理,而治理的前提是搞清楚到底哪些表的存储增长比较快,这些表的增长是否合理。另外,集群中一定是有很多无用文件的,这些文件是可以直接清理的,哪些文件是无用文件目前也是拿不到这些信息,支持我们做下一步的决策。除此之外,还有比如集群小文件比较多,但是又不知道哪些表的小文件比较多,小文件的平均大小到底小到什么程度。这些都属于存储资源的不透明。
接下来分别用几个案例展开讲解这四个不透明。
2、服务健康不透明

上图是 HDFS 的 NameNode 的排队时间监控图,可以看到在10点40左右,有一波排队时间大幅增加,到12点才下去。这个时间段所有的任务请求在 HDFS 都会出现排队,一旦排队时间达到秒级,很多 Spark 任务的 Driver 阶段因为有大量 rename 操作就会卡顿,会导致 Spark 任务耗时延迟,这样的 RPC 异常使得 SLA 没办法得到保证,危险性是非常大的,尤其对于底层 HDFS 服务一旦异常,所有上层任务比如 Hive 任务、Spark 任务都会受到影响。
现在知道了这个现象,但还不知道具体原因,如果是某个任务执行异常命令引起的话,人工定位可能会花费几个小时甚至几天,难度非常大,影响也非常大,对于我们来说是非常致命的问题。
因此服务健康不透明,对保障性和稳定性来说是一个非常大的隐患。
3、计算资源不透明

上面这张图表示一个队列的资源使用情况,绿线表示资源的申请量已经打满了,达到百分之百了。
这会引出两个问题,第一个问题是因为申请不到资源,新增的任务没办法提交。第二个是已经提交的任务,不断申请 Container 的时候会产生竞争,因为资源已经没了,只能等待,任务延迟增大,最终可能导致产出不及预期。
针对上述问题,因为队列容量已经满了,通常会采购机器,但是采购机器会增加成本。实际上,下面这条蓝线是队列的实际资源使用率,可以看到大概在50%左右,表示申请了100核,可能只使用了50核,而申请了100核就把队列资源申请满了,这时候任务提交不上来。但是从物理机的层面来看,资源使用率只有50%或者更低。这就是计算资源不透明的现象。
4、任务运行不透明

上图中显示的任务执行了7.9个小时,大家会问这个任务执行真的需要这么长时间吗?到底哪个阶段需要这么长时间?
大家知道离线任务,或者 Impala 任务的执行是分很多阶段的,它的链路非常长。七八个小时到底花在哪个阶段了,实际上没有开源工具来看,这就是任务运行不透明的现象。
5、存储资源不透明

上图中左侧,从去年8⽉份到10⽉份,集群⽂件数快速增⻓,会导致 HDFS 元数据量增⻓⾮常快, NameNode 内存急速往上飚,会出现严重的 GC,或其他⼀些不稳定的因素。这个时候就需要知道到底是哪个业务、哪个表增长比较快,这样才能针对性地去处理问题。包括小文件也是一样的,增长这么多,到底有多少小文件是不清楚的。这就是存储资源不透明。
针对上述问题,第一件事情是要把不透明变成透明。更近一步,是在透明化的基础上,分析诊断服务健康以及任务健康、分析治理计算(存储)资源等。这正是 EasyEagle 要做的工作。
二、产品核心能力介绍
接下来就将对 EasyEagle 的核心能力进行介绍。

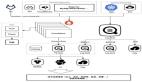
EasyEagle 是网易数帆国产大数据基础平台 NDH 的一个产品。 上图是 NDH 的架构图,红色的是原生的组件;蓝色组件,包括 HDFS、Impala、Spark、Flink 等,我们做了大量的功能增强;绿色的部分,包括 EasyEagle、湖仓一体、Arctic,是自研产品服务。
EasyEagle 主要是为了解决刚才讲的四个不透明问题,并在此基础上提出相应的分析诊断以及治理的策略,为 NDH 平台高效健康运行保驾护航。它的核心竞争力是基于大量真实客户业务经验和实践经验所形成的方法论。

EasyEagle 包括四个模块,分别针对刚才讲的四个不透明。
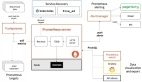
第一个模块称为服务健康的监控诊断,针对服务健康不透明的问题。重点包括三个功能:第一个功能是服务状态的探针,解决服服务不可用的问题;第二个是服务智能巡检,解决服务健康是否存在风险,以及应该如何去解决的问题;第三个是异常智能诊断,解决的是服务发生异常后,快速帮忙分析出本质原因,快速止损,这是服务健康诊断的三个能力。
第二个模块是计算资源监控治理。包括计算、队列、任务三个层面的资源监控分析,解决从不透明变成透明的问题。资源空闲队列、资源浪费队列的治理,这两项是在透明化之上进行的进一步分析,提出相应的资源治理方法论和产品形态。
第三个模块是任务全链路诊断优化,对应任务运行不透明问题。第一个是集群任务执行的概况;第二个是任务全链路监控;第三个是任务自助诊断优化,在透明化的基础上,怎么去解决优化。
第四个模块是存储资源治理模块,对应存储资源不透明的问题。首先从集群维度看存储资源的大盘有多少表,有多少数据这些基本信息。第二是集群容量的分析治理,比如哪些表是无用的,哪些表是没有压缩过的,哪些表最近的增长非常快,是从容量分析的视角来看问题。还有一个就是从集群小文件的视角来分析问题。
1、服务健康监控与诊断

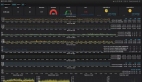
接下来重点看一下第一部分,服务健康监控与诊断。上图以 Impala 服务为例,左边是基本信息,右边包含两部分信息,第一个是探针 SQL 执行的状态,解决可用不可用的问题。另一部分包括集群的存活状况,元数据同步的状况,队列的排队状况,以及队列内存使用率的状况。实际上是对相关指标巡检,解决有没有风险的问题。
下面这部分基于时间线,比如选择了最近五天,有一段时间是正常的,有一段时间有警告,有一段时间红色变成了有异常。这时候可以追溯服务在最近一周的实际运行情况。对于警告或异常,点进去之后,可以看到一个诊断,告诉你问题是什么原因导致的,包括风险点,建议的措施以及异常的原因等等。
2、计算资源监控与治理

第二个介绍的模块是集群计算资源监控,包括三个粒度的透明化:集群粒度、队列粒度、任务粒度。
首先是集群粒度。上图是我们的集群,有上千台机器,平均的 CPU 利用率以及内存利用率是怎么样的,可以看到有两张折线图,上面的折线是实际申请的情况,下面是实际使用的情况,可以从集群维度知道资源水位情况。还可以直观地看出集群是否有资源浪费,对于很多架构师、集群的运维同学、采购同学来说都是非常有帮助的。
下面的散点图里,每个点都表示集群里面的节点。横坐标是内存的利用率,纵坐标是 CPU 的利用率。如果在原点附近,表示 CPU 利用率和内存利用率都很低,如果大量的散点落在这个区间,就说明集群是非常空闲的。

接下来是第二个层面,队列粒度。集群分很多的队列,每个队列可能给不同的业务。图中最上面的曲线是队列资源的使用情况,一条线是内存资源,一条线是 CPU 资源。下面的曲线是队列对应 Label 资源的使用情况。

接下来最细粒度的任务层面。第一个图是任务的 CPU 使用情况,第二个是任务的内存使用情况。以 CPU 来看,上面这条线是任务申请分配的 VCore 的值,下面的绿线是实际使用的 VCore 值。很显然可以看到,这个任务从启动到结束,资源的实际使用率非常低,内存也是一样的。
上面是从集群、队列到任务三个视角去看资源的透明化,接下来结合这些信息进行资源的分析治理。

上图中可以看到,通过列表可以知道哪些队列的水位比较低,哪些队列的水位比较高。对于低水位的队列,可以知道通过治理可以省多少内存,省多少 CPU。
上面是解决空闲资源,第二是解决资源满载。比如刚才队列资源满了,可以在产品上定位到对应时间点的任务列表,然后按照内存使用量、CPU 使用量进行排序,找到资源使用量最大的部分任务,结合任务资源监控的分析,进行相应的治理。

还有一种情况是任务的资源利用率异常。可以看到队列实际内存使用率是相对比较低的,比如内存利用率只有8%,也就是申请了100GB,执行了只有8GB。我们会把这资源利用低的队列显示出来,并给出经过治理后可以节省多少内存以及 VCore 等。

这些队列点进去之后会将这个队列中的任务按照内存利用率进行排序,浪费资源最多的任务会排在第一名。浪费资源多表现为两点,第一点就是任务申请了大量资源,但是使用了比较少;第二点就是任务的运行时间比较长。结合这两点去做乘法,就会把浪费的内存、VCore计算出来,按照这个浪费的资源进行排序。排序之后就可以知道,要针对哪些任务进行优化。根据经验来看,对Top的队列的治理能够获得显著的收益。
3、任务全链路诊断优化
第三个部分是任务全链路的诊断优化,解决的是任务运行不透明的问题。下图可以很清楚地看到哪些任务是可以优化的,哪些任务是执行出现异常的。

拿到异常或待优化列表之后,就可以开始进行任务的详细诊断。下图是任务诊断详情的一个示例:

这个任务相比平时执行耗时增长了六倍,下面的柱状图表示这个调度任务执行一次各阶段的耗时,最后一天执行耗时明显比其他几天的时间要长很多。原因在图里面能看出来,是蓝色阶段耗时最多,蓝色阶段代表 AM 分配的耗时阶段。找到问题后,还会看到一个诊断意见,比如我们发现 AM 内存的使用率达到90%多,其实是没有 AM 的内存可以分配出来,导致一直在等,这就是问题产生的原因,解决方案就是要去增加 AM 内存。

4、存储资源监控治理
第四部分是存储资源的治理,包括两大方面,一个是容量治理,另一个是小文件治理。

大盘中展示了集群里面的表信息,哪些表的存储量最大,通过Top N可以排出来。右边这张图中可以看到哪些表的月增长量最多,这些可以作为容量治理的重要依据。

小文件管理方面,可以看到集群里面哪些表有大量的小文件,哪些表的小文件增长最快,也会排列展示出来。对于治理是非常有帮助的。
5、落地成果
最后简单介绍一下落地成果。
首先是服务健康透明化。HDFS 集群 RPC 延迟增大等问题的责任应用定位耗时,由原先的数小时,缩短到了5分钟之内。
第二是资源使用的透明化。网易 A 业务,高峰时间段集群资源使用率由96%下降到70%左右(释放了7.9T内存),任务量增长16%左右。网易 B 业务,经过多维度计算资源治理,总共节省了上万vcore资源。商业化某客户,在优化280个任务后,集群资源利用率提升了49%以上。
第三是任务运行透明化。相较于原先的人工排查,整体耗时减少了90%以上,大部分问题能在5分钟内定位,并告知开发、运行相关处理意见。
最后是数据资产透明化。网易B业务,经过无用表治理、小文件治理等,降低了20PB+的存储容量。
三、后期规划
后期规划主要有三个方面。
首先,继续扩展 EasyEagle 在服务健康诊断方面的能力,将沉淀的更多场景下的成熟诊断和优化的方法持续予以赋能,进一步提升大数据平台核心服务的健康性和稳定性。
另一方面,深化 EasyEagle 在数据资产治理方面的能力,将存储治理的方法策略以及工具以更加友好的方式进行组织,体现治理的逻辑性。
最后,探索 AIGC 赋能,把 EasyEagle 平台做成更加智能、更加易用的平台。