












不得了了!
现在只用打几个字就能创造精美、高质量的3D模型出来了?
这不,国外一篇博客引爆网络,把一个叫MVDream的东西摆到了我们面前。
用户只需要寥寥数语,就可以创造出一个栩栩如生的3D模型。

而且和之前不同的是,MVDream看起来是真的「懂」物理。
下面就来看看这个MVDream有多神奇吧~
MVDream
小哥表示,大模型时代,我们已经看到了太多太多文本生成模型、图片生成模型。而且这些模型的性能也越来越强大。
后来,我们甚至还目睹了文生视频模型的诞生,当然也包括今天要提到的3D模型。
试想一下,你只需要输入一句话,就可以生成一个宛如存在于真实世界的物体模型,甚至还包含着所有必要细节,这个场景该有多酷。
而且这绝对不是一件简单的事,尤其是用户需要生成的模型所呈现的细节要足够逼真。
先来看看效果~

同一个prompt,最右侧就是MVDream的成品。
肉眼可见5个模型的差距。前几个模型完全违背了客观事实,只有从某几个角度看才是对的。
比如前四张图片,生成的模型居然有不止两只耳朵。而第四张图片虽然看起来细节更丰满一点,但是转到某个角度我们能发现,人物的脸是凹进去的,上面还插着一只耳朵。
谁懂啊,小编一下就想起了之前很火的小猪佩奇正视图。

就是那种,某些角度是展示给你看的,别的角度千万别看,会死人。
可最右边MVDream的生成模型显然不一样。无论3D模型怎样转动,你都不会觉得有任何反常规的地方。
这也就是开头所提到的,MVDream真懂物理常识,而不会为了保证在每个视图下都有两只耳朵而搞出一些奇奇怪怪的东西。
小哥指出,一个3D模型是否成功,最主要的就是观察这个模型的不同视角是不是都足够逼真,质量都足够高。
而且还要保证模型在空间上的连贯性,而不是像上面多个耳朵的模型那样。
生成3D模型的主要方法之一,就是对摄像机的视角进行模拟,然后生成某一视角下所能看到的东西。
换个词,这就是所谓的2D提升(2D lifting)。就是将不同的视角拼接在一起,形成最终的3D模型。
出现上面多耳的情况,就是因为生成模型对整个物体在三维空间的样态信息掌握的不充分。而MVDream恰恰就是在这方面往前迈了一大步。
新模型解决了之前一直出现的3D视角下的一致性问题。
分数蒸馏采样
而用到的方法叫做分数蒸馏采样(score distillation sampling),由DreamFusion开发。
在了解分数蒸馏采样技术之前,我们需要先了解一下该方法所使用的架构。
简而言之,这其实只是另一种二维图像的扩散模型,同类的还有DALLE、MidJourney和Stable Diffusion模型。
更具体地说,一切的一切都是从预训练好的DreamBooth模型开始的,DreamBooth是一个基于Stable Diffusion生图的开源模型。
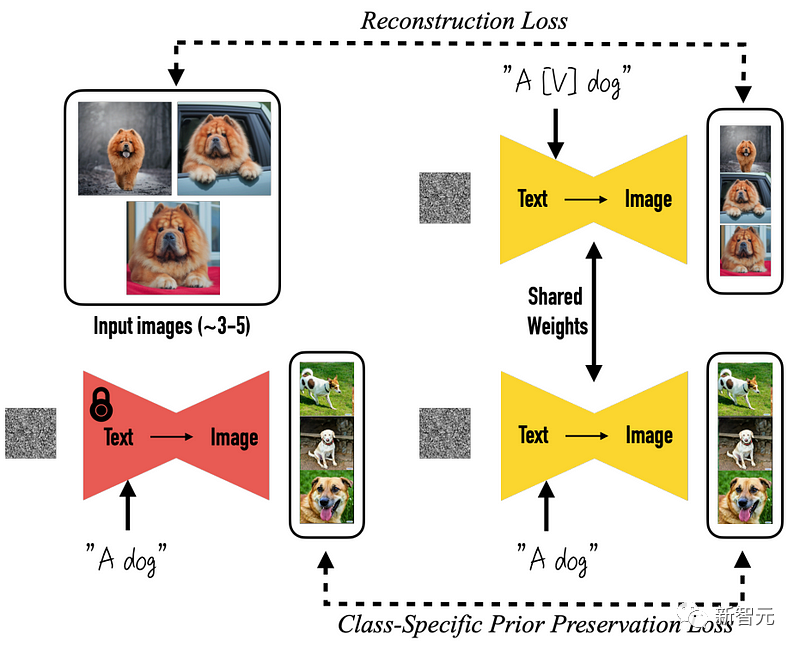
然后,改变来了。
研究团队后续所做的是,直接渲染一组多视角图像,而不是只渲染一张图像,这一步需要有各种物体的三维数据集才可以完成。
在这里,研究人员从数据集中获取了三维物体的多个视图,利用它们来训练模型,再使其向后生成这些视图。
具体做法是将下图中的蓝色自注意块改为三维自注意块,也就是说,研究人员只需要增加一个维度来重建多个图像,而不是一个图像。
在下图中,我们可以看到摄像机和时间步(timestep)也都被输入到了每个视图的模型中,以帮助模型了解哪个图像将用在哪里,以及需要生成的是哪种视图。
现在,所有图像都连接在一起,生成也同样在一起完成。因此它们就可以共享信息,更好地理解全局的情况。
然后,再将文本输入模型,训练模型从数据集中准确地重建物体。
而这里也就是研究团队应用多视图分数蒸馏采样过程的地方。
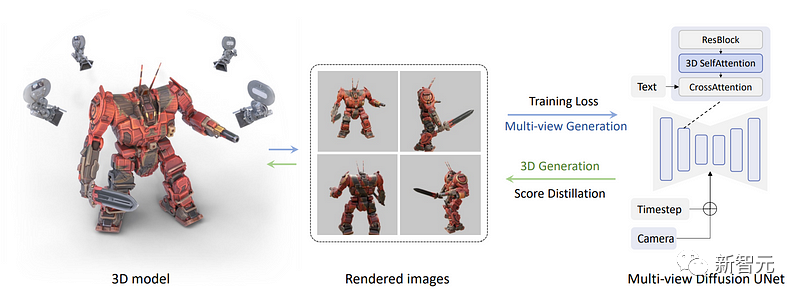
现在,有了一个多视图的扩散模型,团队可以生成一个物体的多个视图了。
下一步,就是用这些视图来重建一个和真实世界一致的三维模型,而不仅仅是视图。
这里需要使用NeRF(neural radiance fields,神经辐射场)来实现,就像前面提到的DreamFusion一样。
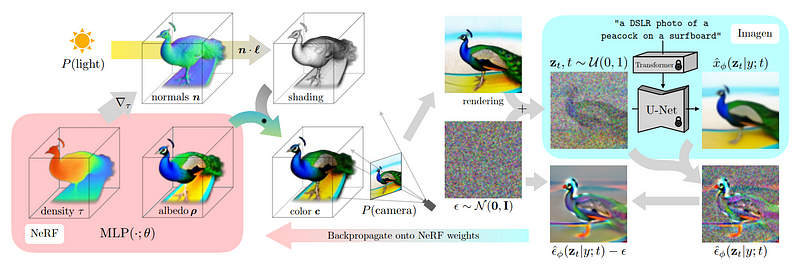
基本上这一步就是把前面训练好的多视角扩散模型给冻住,也就是说,在这一步中,上面各个视角的图片只是被「使用」,而不会被再「训练」。
在初始渲染的引导下,研究人员开始使用多视角扩散模型生成一些添加了噪声(noise)的初始图像版本。
研究人员添加噪声是为了让模型知道,它需要生成不同版本的图像,但同时仍能接收到背景信息。
然后,再使用该模型进一步生成更高质量的图像。
添加用于生成该图像的图像,并移除我们手动添加的噪声,以便在下一步中使用该结果来指导和改进NeRF模型。
这些步骤都是为了更好地理解NeRF模型应该集中在图像的哪个部分,以便在下一步中生成更好的结果。
如此反复,直到生成出令人满意的3D模型。

而对于多视角扩散模型的图像生成质量的评估,以及不同的设计会如何影响其性能的判断,该团队是这么操作的。
首先,他们比较了用于建立跨视角一致性模型的注意力模块的选择。
这些选项包括:
(1)视频扩散模型中广泛使用的一维时间自注意;
(2)在现有模型中添加新的三维自注意模块;
(3)重新使用现有的二维自注意模块进行三维注意。
在本实验中,为了清楚地显示这些模块之间的差异,研究人员使用了8帧的90度视角变化来训练模型,这更加接近视频的设置。
同时在实验中,研究团队还保持了较高的图像分辨率,即512×512作为原始的标清模型。结果如下图所示,研究人员发现,即使在静态场景中进行了如此有限的视角变化,时间自注意力仍然会受到内容偏移的影响,无法保持视角的一致性。
团队假设,这是因为时间注意力只能在不同帧的相同像素之间交换信息,而在视点变化时,相应像素之间可能相距甚远。
另一方面,在不学习一致性的情况下,添加新的三维注意会导致严重的质量下降。
研究人员认为,这是因为从头开始学习新参数会耗费更多的训练数据和时间,不适合这种三维模型有限的情况。研究人员提出的重新使用二维自注意的策略在不降低生成质量的情况下实现了最佳的一致性。
团队还注意到,如果将图像大小减小到256,视图数减小到4,这些模块之间的差异会小得多。然而,为了达到最佳一致性,研究人员在以下实验中根据初步观察做出了选择。

此外,对于多视角的分数蒸馏采样,研究人员在threestudio(thr)库中实现了多视角扩散的引导,该库在统一框架下实现了最先进的文本到三维模型的生成方法。
研究人员使用threestudio中的隐式容积(implicit-volume)实现作为三维表示,其中包括多分辨率的哈希网格( hash-grid)。
对于摄像机视图,研究人员采用了与渲染三维数据集时完全相同的方式对摄像机进行俩人采样。
此外,研究人员还使用AdamW优化器对3D模型进行了10000步优化,学习率为0.01。
对于分数蒸馏采样,在最初的8000 步中,最大和最小时间步长分别从0.98步降到了0.5步和0.02步。
渲染分辨率从64×64开始,经过5000步后逐步增加到了256×256。
更多案例如下:

以上就是研究团队如何利用二维文本到图像模型,将其用于多视角合成,最后利用它迭代,并创建出文本到3D模型的过程。
当然,目前这种新方法还存在一定的局限性,最主要的缺陷在于,现在生成的图像只有256x256像素,分辨率可以说很低了。
此外,研究人员还指出,执行这项任务的数据集的大小在某种程度上一定会限制这种方法的通用性,因为数据集的太小的话,就没办法更逼真的反应我们这个复杂的世界。

























