译者 | 布加迪
审校 | 重楼
ChatGPT于2020年6月发布,由OpenAI开发。它已促使许多领域迎来了革命性变化。其中一个领域就是创建数据库查询。数据库查询可以通过ChatGPT由纯文本生成。它可以帮助您了解您不甚了解的数据库。

随着ChatGPT的大行其道,人工智能已经逐渐融入到我们的日常生活当中,并且发展势头正猛。在切入正题之前,不妨先简单地探究一下ChatGPT。
为了充分理解ChatGPT的功能,有必要充分掌握其底层架构。ChatGPT是基于GPT架构而开发的。因此不妨先看看Transformer。
若要直接访问该项目,请点击这里:https://github.com/ademakdogan/ChatSQL?ref=hackernoon.com。
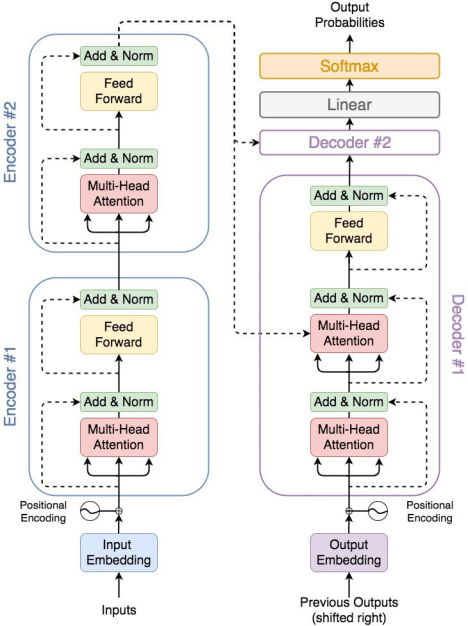 图1. 来自Transformer的编码器和解码器
图1. 来自Transformer的编码器和解码器
Transformer使用seq2seq框架,从而能够将一个序列转换成另一个序列。序列定义了排序。举例来说,我们可以将句子看作是一连串单词。Transformer还可以用于解决文本翻译之类的自然语言处理(NLP)问题。我们需要大量的标记数据来训练这个架构。这对Transformer来说很难学习。我们可以使用迁移学习来解决这个问题。Transformer由两个部分组成(见图1):编码器和解码器,它们都擅长获得熟练的语言表示。
这种熟练程度使我们能够从每个部分构建语言模型。通过堆叠编码器,我们获得了Transformer的双向编码器表示(通常称为BERT)。与之相似,通过堆叠解码器单元,我们可以获得生成式预训练(即GPT)。在本文这个例子中,我们仅关注GPT。不妨在GPT的背景下考虑迁移学习。当我们从头开始训练一个模型时,它通常需要数量庞大的数据,因为参数最初是随机设置的。然而,想象一下这样一个场景:参数偶然与我们需要的值相一致或相对齐。在这种情况下,我们不需要一个广泛的数据集来获得我们想要的结果。正如我们所理解,BERT和GPT用于迁移学习概念中。
因此,GPT训练分为两个部分。一个是预训练部分,我们训练GPT架构以理解语言是什么;另一个是微调部分,我们使用迁移学习来进一步训练GPT架构,使其针对特定的语言任务时表现良好。
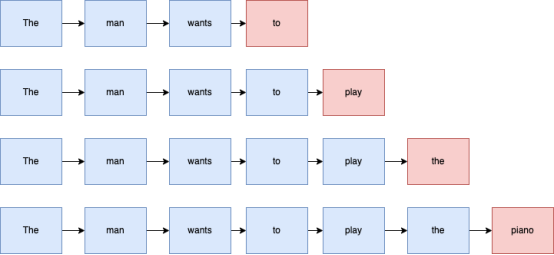 图2. 示例性的下一个单词预测
图2. 示例性的下一个单词预测
GPT有一种结构,可以将随机单词序列作为输入,并预测下一个最合适的单词。示例性预测如图2所示。
语言建模被选为理解语言基本方面的一个理想基础,而且很容易进行微调。它通常被称为自监督任务,因为句子本身同时可以充当输入标签和输出标签。
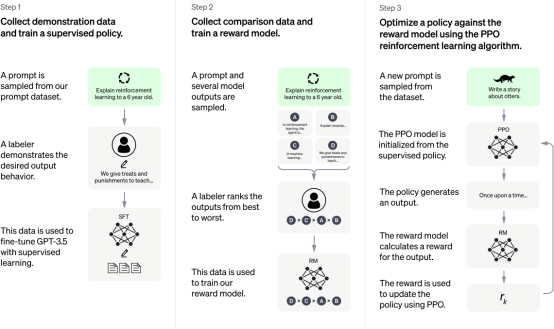 图3. ChatGPT示意图
图3. ChatGPT示意图
不妨继续讨论ChatGPT。如图3所示,整个ChatGPT过程可以分为三个主要步骤。在第一步中,使用GPT模型,该模型已针对理解语言本身进行了预训练。下一步涉及对模型进行微调,以便有效地处理用户提示,并根据这些提示生成适当的响应。为了方便这个过程,标记人员获得已标记的数据;这些标记人员不仅提供提示,还为每个提示指定所需的响应。这便于对GPT模型进行监督式微调,因为既有输入提示,又有相应的输出响应。
在下一步中,使用从第一步获得的监督式微调模型。单个提示通过模型来传递,并生成多个响应。然后,标记人员对这些响应的质量进行评估和评定。每个生成的响应都被分配一个相应的奖励,这个奖励被用来训练另一个GPT模型:奖励模型。奖励模型本身就是一个模型,其功能是将初始提示和其中一个响应作为输入,生成奖励作为输出。这种奖励量化了响应的质量或好坏。
在第三步中,一个看不见的提示将被拿来通过监督式微调模型的复制品来传递。这将生成响应,然后使用奖励模型来评估响应的等级或质量。获得的等级用于进一步完善我们已经微调过的模型。这通过将等级合并到PPO模型的损失函数中来实现,允许通过反向传播来更新模型的参数。特别吸引人的地方是,这个过程不仅帮助模型表现出无害的行为,还使它能够生成实际的响应。这是由于奖励本身是基于响应的质量而生成的。
ChatSQL
现在不妨使用Python借助ChatGPT创建一个项目。该项目使用了LangChain框架。
我们的目标是使用纯文本从数据库检索信息。为此,我们使用MySQL作为目标数据库。然而,这种方法也可以用于在其他数据库上生成查询。示例数据库如下所示。
所有代码都可以在这里找到(https://github.com/ademakdogan/ChatSQL)
+-----+--------------------------------------------------------+------------------------+-------------------+--------+------------------+
| ID | Title | Author | Genre | Height | Publisher |
+-----+--------------------------------------------------------+------------------------+-------------------+--------+------------------+
| 1 | Fundamentals of Wavelets | Goswami, Jaideva | signal_processing | 228 | Wiley |
| 2 | Data Smart | Foreman, John | data_science | 235 | Wiley |
| 3 | God Created the Integers | Hawking, Stephen | mathematics | 197 | Penguin |
| 4 | Superfreakonomics | Dubner, Stephen | economics | 179 | HarperCollins |
| 5 | Orientalism | Said, Edward | history | 197 | Penguin |
| 6 | Nature of Statistical Learning Theory, The | Vapnik, Vladimir | data_science | 230 | Springer |
| 7 | Integration of the Indian States | Menon, V P | history | 217 | Orient Blackswan |
| 8 | Drunkard's Walk, The | Mlodinow, Leonard | science | 197 | Penguin |
| 9 | Image Processing & Mathematical Morphology | Shih, Frank | signal_processing | 241 | CRC |
| 10 | How to Think Like Sherlock Holmes | Konnikova, Maria | psychology | 240 | Penguin |
| 11 | Data Scientists at Work | Sebastian Gutierrez | data_science | 230 | Apress |
| 12 | Slaughterhouse Five | Vonnegut, Kurt | fiction | 198 | Random House |
| 13 | Birth of a Theorem | Villani, Cedric | mathematics | 234 | Bodley Head |
| 14 | Structure & Interpretation of Computer Programs | Sussman, Gerald | computer_science | 240 | MIT Press |
| 15 | Age of Wrath, The | Eraly, Abraham | history | 238 | Penguin |
| 16 | Trial, The | Kafka, Frank | fiction | 198 | Random House |
| 17 | Statistical Decision Theory' | Pratt, John | data_science | 236 | MIT Press |
| 18 | Data Mining Handbook | Nisbet, Robert | data_science | 242 | Apress |
| 19 | New Machiavelli, The | Wells, H. G. | fiction | 180 | Penguin |
| 20 | Physics & Philosophy | Heisenberg, Werner | science | 197 | Penguin |
| 21 | Making Software | Oram, Andy | computer_science | 232 | O'Reilly |
| . | ....... | ....... | .... | ... | .... |
| . | ....... | ....... | .... | ... | .... |ChatSQL由两个主要部分组成。首先,MySQL查询是通过ChatGPT由给定的纯文本生成的。执行这些生成的查询。在第二步中,对数据库中返回的结果进行评估。在这个阶段,结果可以直接呈现给用户,也可以发回给ChatGPT进行进一步的分析和解释。因此,您可以使用ChatGPT与您的数据库进行互动。
假设用户想要“显示篇幅大于175页、少于178页的图书类型小说。作者不应该是‘Doyle, Arthur Conan’。”因此,可以在这种情况下使用以下命令。
python3 chatsql.py -p 'Show me the book type fiction which they height bigger than 175 and smaller than 178. The author shouldn't be 'Doyle, Arthur Conan'. '结果,获得了如下信息。
CHATGPT QUERY------------------:
SELECT * FROM bt WHERE Genre = 'Fiction' AND Height > 175 AND Height < 178 AND Author != 'Doyle, Arthur Conan'
RAW RESULT------------------:
[(32, 'Pillars of the Earth, The', 'Follett, Ken', 'fiction', 176, 'Random House'), (37, 'Veteran, The', 'Forsyth, Frederick', 'fiction', 177, 'Transworld'), (38, 'False Impressions', 'Archer, Jeffery', 'fiction', 177, 'Pan'), (72, 'Prisoner of Birth, A', 'Archer, Jeffery', 'fiction', 176, 'Pan'), (87, 'City of Joy, The', 'Lapierre, Dominique', 'fiction', 177, 'vikas'), (128, 'Rosy is My Relative', 'Durrell, Gerald', 'fiction', 176, 'nan')]
PROCESSED RESULT------------------ :
The books 'Pillars of the Earth, The' by Ken Follett, 'Veteran, The' by Frederick Forsyth, 'False Impressions' by Jeffery Archer, 'Prisoner of Birth, A' by Jeffery Archer, 'City of Joy, The' by Dominique Lapierre, and 'Rosy is My Relative' by Gerald Durrell are all fiction books with 176 or 177 pages published by Random House, Transworld, Pan, Vikas, and Nan, respectively.如果数据库列名称正确,ChatGPT将理解这些名称,并相应地响应查询。然而在一些情况下,数据库中的列名可能没有意义,或者ChatGPT可能无法完全搞清楚其上下文。因此,为了确保系统正常运行,有必要向ChatGPT提供有关数据库的先前信息。info.json文件可以用来添加信息。
+-----+--------------------------------------------------------+------------------------+-------------------+------+------------------+
| ID | aa | bb
| cc | dd | ee |
+-----+--------------------------------------------------------+------------------------+-------------------+------+------------------+
| 1 | Fundamentals of Wavelets | Goswami, Jaideva
| signal_processing | 228 | Wiley |
| 2 | Data Smart | Foreman, John
| data_science | 235 | Wiley |
| 3 | God Created the Integers | Hawking, Stephen
| mathematics | 197 | Penguin |
| 4 | Superfreakonomics | Dubner, Stephen
| economics | 179 | HarperCollins |
| 5 | Orientalism | Said, Edward
| history | 197 | Penguin |
| . | ....... | .......
| .... | ... | .... |
| . | ....... | .......
| .... | ... | .... |比如说,我们有一个命名糟糕的数据库,如下所示。在这种情况下,有关数据库的必要信息被输入到了info.json文件中。
{“bt”: “Table Name”, “aa”: “Title of the book”, “bb”: “Author of the book”, “cc”: “Type of book”, “dd”: “Height of the book”, “ee”: “Book Publisher”}然后使用相同的命令:
python3 chatsql.py -p 'Show me the book type fiction which they height bigger than 175 and smaller than 178. The author shouldn't be 'Doyle, Arthur Conan'. '即使数据库中的列名选择不当,ChatGPT也会生成正确的查询,因为我们提供了正确的信息。
{'query': "SELECT aa, bb, cc, dd FROM bt WHERE cc = 'fiction' AND dd > 175 AND dd < 178 AND bb != 'Doyle, Arthur Conan'", 'raw_result': "[('Pillars of the Earth, The',
'Follett, Ken', 'fiction', 176), ('Veteran, The', 'Forsyth, Frederick', 'fiction',
177), ('False Impressions', 'Archer, Jeffery', 'fiction', 177), ('Prisoner of Birth,
A', 'Archer, Jeffery', 'fiction', 176), ('City of Joy, The', 'Lapierre, Dominique',
'fiction', 177), ('Rosy is My Relative', 'Durrell, Gerald', 'fiction', 176)]",
'processed_result': '\nThe books "Pillars of the Earth, The" by Ken Follett, "Veteran,
The" by Frederick Forsyth, "False Impressions" by Jeffery Archer, "Prisoner of Birth,
A" by Jeffery Archer, "City of Joy, The" by Dominique Lapierre and "Rosy is My
Relative" by Gerald Durrell are all fiction and have page lengths of 176 or 177.'}下一个项目将是使用免费模型(Llama)由提示生成查询(Mongo和SQL)。
- 项目代码仓库:https://github.com/ademakdogan/ChatSQL
- GitHub:https://github.com/ademakdogan
- 领英:https://www.linkedin.com/in/adem-akdoğan-948334177/
原文标题:ChatSQL: Enabling ChatGPT to Generate SQL Queries from Plain Text,作者:Adem Akdogan