














在知乎上看到一个问题“为什么编程更关注内存而很少关注CPU?”这是一个引人深思的问题。作为一位C#软件工程师,可以从以下几个角度来分析为什么编程更关注内存而很少关注CPU。
1、内存限制:
内存是程序运行时的关键资源之一。在很多场景下,程序需要处理大量的数据,如果不合理地管理内存,可能会导致内存溢出或者性能下降。因此,关注内存的使用情况,进行内存优化是非常重要的。
举例说明:
在某些工作场景中,我们可能需要处理大型数据集,如读取和分析大型日志文件、处理大量的数据库记录或者进行图像/视频处理等。以下是一个在C#中处理大型日志文件的示例,展示了如何合理地管理内存并进行优化。
using System;
using System.IO;
class Program
{
static void Main()
{
string logFilePath = "path/to/logfile.log";
// 使用StreamReader逐行读取日志文件
using (StreamReader reader = new StreamReader(logFilePath))
{
string line;
while ((line = reader.ReadLine()) != null)
{
// 处理日志行数据
ProcessLogLine(line);
}
}
Console.WriteLine("日志处理完成。");
}
static void ProcessLogLine(string line)
{
// 在这里编写代码来处理单行日志数据
// 可能的操作包括解析数据、分析数据、提取有用信息等
// 例如,统计特定事件的发生次数、获取某个时间段的日志等
// 示例:在控制台打印日志行
Console.WriteLine(line);
}
}在上述示例中,我们使用StreamReader逐行读取大型日志文件,而不是一次性将整个文件加载到内存中。这样可以避免因为文件过大而导致的内存溢出问题。
通过逐行读取日志文件,我们可以针对每一行数据进行处理,例如解析数据、分析数据或提取有用信息。在ProcessLogLine方法中,我们展示了一个简单的操作,即在控制台打印每一行日志。
除了逐行读取外,我们还应该注意及时释放不再使用的资源。在读取大型文件时,可以使用using语句来确保在不再需要时及时释放StreamReader。
在实际工作中,内存优化的策略和技术取决于具体的场景和需求。例如,在处理大量数据库记录时,可以使用分页查询、延迟加载等技术来减少内存消耗;在图像/视频处理中,可以使用流式处理的方式,避免一次性加载整个文件。
2、内存访问速度:
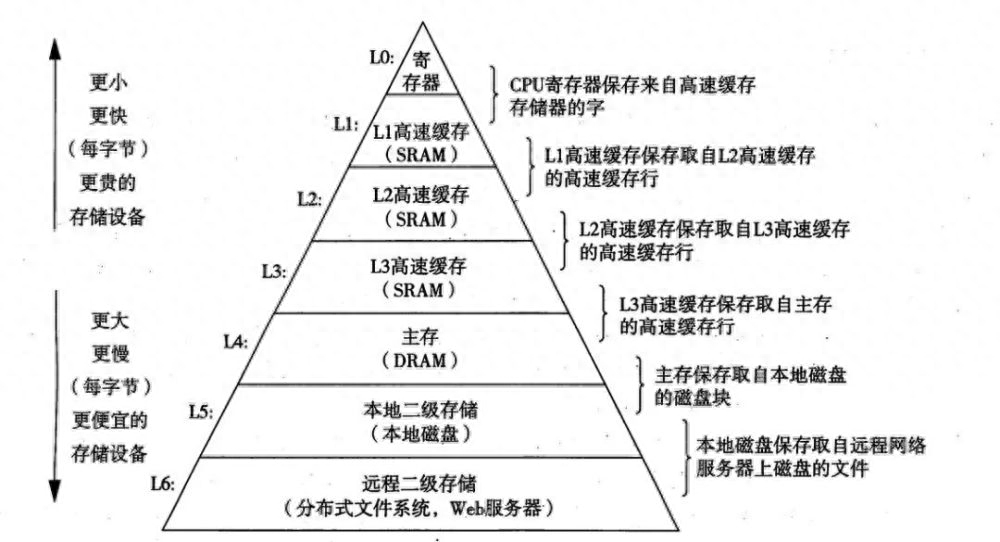
相比于CPU,内存的访问速度较慢。CPU可以通过高速缓存(Cache)来加速数据访问,但当数据无法在高速缓存中找到时,需要从内存中加载数据,这会引入较大的延迟。因此,减少对内存的访问次数,提高内存访问的局部性,可以有效提升程序的性能。
在实际工作场景中,一个常见的情况是处理大量的数据集。例如,在金融领域,我们可能需要对市场交易数据进行分析和计算,以生成报告或者进行决策。这种数据集通常很大,并且需要进行复杂的计算操作。在这样的情况下,内存访问的效率对程序的性能起着至关重要的作用。
假设我们正在编写一个金融数据分析的应用程序,需要对大量的股票交易数据进行移动平均线计算。移动平均线是一种常见的技术指标,用于平滑价格走势以及预测趋势的变化。
我们有一个包含数百万条股票交易数据的数组,每条数据包含日期和价格。我们需要计算每个交易日的5日移动平均线。为了优化内存访问并提高程序性能,我们可以采取以下策略:
class Program
{
static void Main()
{
// 模拟股票交易数据
List<TradeData> tradeData = new List<TradeData>();
// 初始化股票交易数据...
// ...
int dataSize = tradeData.Count;
int movingAveragePeriod = 5;
// 用于存储移动平均线结果的数组
double[] movingAverages = new double[dataSize];
// 计算移动平均线
for (int i = 0; i < dataSize; i++)
{
// 检查是否有足够的数据进行计算
if (i >= movingAveragePeriod - 1)
{
double sum = 0;
// 计算移动平均值
for (int j = i; j >= i - (movingAveragePeriod - 1); j--)
{
sum += tradeData[j].Price;
}
// 存储移动平均值
movingAverages[i] = sum / movingAveragePeriod;
}
else
{
// 不足够的数据,将移动平均线值设为0或其他合适的初始值
movingAverages[i] = 0;
}
}
// 打印移动平均线结果
foreach (double average in movingAverages)
{
Console.WriteLine(average);
}
Console.WriteLine("移动平均线计算完成。");
}
}
// 股票交易数据类
class TradeData
{
public DateTime Date { get; set; }
public double Price { get; set; }
// 其他属性...
}在这个示例中,我们使用一个TradeData类来表示股票交易数据,包括日期和价格等信息。我们首先创建一个包含数百万条交易数据的列表tradeData,然后定义了移动平均线的期间为5天。
为了优化内存访问,我们遍历每一条数据,并在每个交易日都计算移动平均线。由于移动平均线的计算需要考虑一定的历史数据,我们利用一个内部循环,从当前交易日往前回溯5天并计算总和,最后除以5得到移动平均值。通过这种方式,我们在计算移动平均线时只访问了必要的数据,减少了对内存的访问次数。
需要注意的是,当交易日不足5天时,我们将移动平均线值设为0或其他合适的初始值,以避免对无效数据进行计算。
这个示例展示了如何在工作场景中(金融数据分析)应用内存访问的优化策略。通过减少内存访问次数和提高内存访问的局部性,我们可以显著提升程序的性能,特别是处理大量数据时。
3、内存泄漏和悬挂引用:
内存管理不当可能导致内存泄漏和悬挂引用的问题。内存泄漏是指程序中存在无法访问的对象占用内存的情况,这会导致内存占用不断增加。悬挂引用是指程序中存在被引用但实际上已经不再使用的对象,这些对象仍然被引用,导致GC无法回收它们。因此,关注内存管理,及时释放不再使用的对象,可以避免这些问题的出现。
内存泄漏和悬挂引用是在程序开发中常见的问题。在实际工作场景中,一个典型的例子是在Web应用程序中使用数据库连接对象。如果不正确地管理这些连接对象,可能会导致内存泄漏和悬挂引用的问题。
假设我们正在开发一个在线购物网站的后端服务,使用C#编写。在该网站中,我们需要使用数据库来存储用户的订单信息。为了与数据库进行通信,我们需要创建和释放数据库连接对象。
以下是一个简化的示例代码:
class Program
{
private static List<DbConnection> openConnections = new List<DbConnection>();
static void Main()
{
// 模拟处理用户订单的业务逻辑
ProcessOrders();
// 关闭所有数据库连接
CloseAllConnections();
Console.WriteLine("程序执行完毕。");
}
static void ProcessOrders()
{
// 模拟处理多个订单
for (int i = 0; i < 1000; i++)
{
// 创建数据库连接
DbConnection connection = CreateConnection();
// 执行一些数据库操作...
// ...
// 将连接添加到已打开连接列表中
openConnections.Add(connection);
}
}
static DbConnection CreateConnection()
{
// 创建数据库连接对象
DbConnection connection = new DbConnection();
// 连接数据库...
// ...
return connection;
}
static void CloseAllConnections()
{
// 关闭所有数据库连接
foreach (DbConnection connection in openConnections)
{
// 关闭连接
connection.Close();
}
// 清空连接列表
openConnections.Clear();
}
}
// 模拟数据库连接类
class DbConnection
{
// 连接数据库的一些属性和方法...
// ...
}在这个示例中,我们首先创建了一个静态变量openConnections,用于存储所有打开的数据库连接对象。然后,在处理订单的业务逻辑中,我们循环创建数据库连接对象,并执行一些数据库操作。为了避免内存泄漏和悬挂引用,我们将每个打开的连接对象添加到openConnections列表中。
最后,在程序执行完毕之前,我们通过调用CloseAllConnections方法关闭所有的数据库连接并清空连接列表。
通过上述代码,我们有效地管理了数据库连接对象的生命周期,确保在不使用时及时释放。这样可以避免内存泄漏,因为在每次处理订单的循环中,我们都会创建新的连接对象并添加到openConnections列表中,而在程序结束之前会将所有连接关闭并清空列表。
如果我们没有正确地管理这些连接对象,可能会导致内存泄漏。例如,如果在处理订单的循环中未将连接添加到openConnections列表中,那么这些连接对象将无法被正常关闭和释放,从而占用内存并可能导致内存泄漏。
同样,如果在程序结束后未关闭连接和清空列表,那么这些连接对象将继续被引用,无法被垃圾回收器回收,从而导致悬挂引用的问题。
因此,在实际工作场景中,正确地管理和释放对象是确保程序性能和稳定性的重要一步。及时释放不再使用的对象可以避免内存泄漏和悬挂引用的问题,提高系统的可靠性和资源利用率。
4、并发和并行:
在多线程和并行编程中,内存访问往往是一个关键的性能瓶颈。多个线程同时访问共享的内存,可能会引发竞态条件和数据一致性的问题。因此,合理地管理内存,使用锁机制或者其他并发控制手段,可以提高程序的并发性能。
在实际工作场景中,多线程和并行编程经常用于处理大规模数据、提高系统性能和响应速度。然而,当多个线程同时访问共享的内存时,可能会引发竞态条件(Race Condition)和数据一致性问题。为了避免这些问题,需要正确地管理内存访问,使用锁机制或其他并发控制手段。
假设我们正在开发一个电子商务网站,需要实现一个库存管理系统。在这个系统中,多个线程将并发地读取和更新商品的库存信息。我们使用C#编写以下示例代码来模拟这个场景:
class InventoryManager
{
private Dictionary<string, int> inventory; // 商品库存信息
private object lockObject; // 锁对象
public InventoryManager()
{
inventory = new Dictionary<string, int>();
lockObject = new object();
}
public void UpdateStock(string product, int quantity)
{
lock (lockObject) // 使用锁保证线程安全
{
if (inventory.ContainsKey(product))
{
inventory[product] += quantity;
}
else
{
inventory[product] = quantity;
}
}
}
public int GetStock(string product)
{
lock (lockObject) // 使用锁保证线程安全
{
if (inventory.ContainsKey(product))
{
return inventory[product];
}
else
{
return 0;
}
}
}
}
class Program
{
static void Main()
{
InventoryManager inventoryManager = new InventoryManager();
// 模拟多个线程并发地更新库存
Thread t1 = new Thread(() => inventoryManager.UpdateStock("Product A", 10));
Thread t2 = new Thread(() => inventoryManager.UpdateStock("Product B", 5));
t1.Start();
t2.Start();
// 等待两个线程执行完毕
t1.Join();
t2.Join();
// 输出商品的最终库存
Console.WriteLine("Product A stock: " + inventoryManager.GetStock("Product A"));
Console.WriteLine("Product B stock: " + inventoryManager.GetStock("Product B"));
Console.WriteLine("程序执行完毕。");
}
}在这个示例中,我们创建了一个InventoryManager类,用于管理商品库存信息。在构造函数中初始化了一个字典inventory用来存储每个商品的库存数量,并创建了一个对象lockObject作为锁对象。
UpdateStock方法用于更新商品库存的数量,它使用lock语句来获取锁对象,确保同一时间只有一个线程可以执行该方法。在方法内部,首先检查字典inventory是否已经包含了该商品的库存信息,如果存在,则增加数量;否则,将该商品的数量添加到字典中。
GetStock方法用于获取商品的库存数量,同样也使用lock语句来获取锁对象,确保线程安全。在方法内部,通过判断字典inventory是否包含了该商品的库存信息来返回相应的库存数量。
在Main方法中,我们创建一个InventoryManager对象,并模拟两个线程并发地更新库存。每个线程调用UpdateStock方法来增加商品的数量。然后,通过调用GetStock方法获取商品的最终库存数量,并输出结果。
通过使用锁机制,即在访问共享资源前获取锁对象,我们可以确保在同一时间只有一个线程能够访问和修改共享的内存资源。这样就避免了竞态条件和数据不一致的问题,提高了程序的并发性能和数据的正确性。
需要注意的是,锁机制可能会引起线程阻塞和性能损失,特别是在高并发情况下。因此,在实际开发中,根据具体情况可以考虑使用更高级的并发控制手段,如使用读写锁(ReaderWriterLock)来允许多个线程同时读取共享资源,但保证只有一个线程能够写入资源。或者使用并发集合类(ConcurrentDictionary、ConcurrentBag等)来管理共享资源,这些类底层已经实现了线程安全的操作。
总之,在多线程和并行编程中,合理地管理内存访问是确保程序性能和数据正确性的重要一环。使用锁机制或其他并发控制手段可以有效避免竞态条件和数据一致性问题,并提高程序的并发性能。
关注CPU的部分
抽象层次:编程语言和开发框架提供了高层次的抽象,使得开发人员可以更专注于业务逻辑和应用程序的功能实现,而不需要过多关注底层的硬件细节。这种抽象层次的提升使得开发人员能够更快速地开发软件,并降低了对CPU的依赖。
多核处理器的普及:随着多核处理器的普及,现代计算机系统可以同时执行多个线程或进程。这意味着开发人员可以通过并发编程来充分利用多核处理器的性能,而无需过多关注单个CPU的细节。相反,开发人员更关注如何设计并发算法和数据结构,以充分利用多核处理器的性能。
编译器和运行时优化:编译器和运行时环境会自动对代码进行优化,以提高程序的性能。这些优化包括指令重排、内联函数、循环展开等技术,使得程序在执行时可以更有效地利用CPU的资源。因此,开发人员不需要手动优化代码以充分利用CPU的性能。
跨平台和可移植性:现代软件开发越来越注重跨平台和可移植性。开发人员希望他们的软件能够在不同的操作系统和硬件平台上运行。为了实现这一目标,他们更倾向于使用高级编程语言和跨平台的开发框架,这些工具会自动处理不同CPU架构的差异,使得开发人员无需关注底层的CPU细节。
综上所述,尽管CPU也是程序执行的重要组成部分,但在编程中更关注内存的原因主要包括内存限制、内存访问速度、内存泄漏和悬挂引用问题以及并发和并行编程的需求。尽管如此,对于一些特定的应用场景,如高性能计算、嵌入式系统、游戏开发等,开发人员可能仍然需要关注CPU的细节,以充分利用硬件资源和提高程序性能。在这些情况下,开发人员可能需要使用底层的编程语言(如汇编语言)或使用特定的优化技术来手动优化代码。但对于大多数常见的应用程序开发,关注CPU的细节并不是必需的。

















