












译者 | 朱先忠
审校 | 重楼
在当今这个数据驱动的世界里,保护个人的隐私和匿名是至关重要的事情。从保护个人身份到遵守GDPR(General Data Protection Regulation,即《通用数据保护条例》,为欧盟制订的条例)等严格法规,对各种媒体格式的人脸匿名化高效可靠解决方案的需求前所未有。
简介
在本文提供的这个实战项目中,我们将探索并比较人脸模糊算法相关的几种解决方案,并开发了一个用于比较评估这几种算法的网络应用程序。
首先,让我们来介绍这样一个应用程序的系统需求:
- 保护隐私
- 驾驭监管环境:随着监管环境的快速发展,世界各地的行业和地区都在实施更严格的规范,以保护个人身份信息。
- 训练数据保密性:机器学习模型在多样化和准备充分的训练数据上蓬勃发展。然而,共享此类数据通常需要谨慎的匿名化。
总体来看,这个实战项目可以划分成两个基本部分:
- 人脸检测
- 面部模糊技术
人脸检测
为了解决匿名化挑战,首先要解决的问题是定位图像中存在人脸的区域。为此,我测试了三个用于图像检测的模型。
Haar Cascade算法

图1:类哈尔特征算法(来源——原始论文)
Haar Cascade是一种机器学习方法,用于图像或视频中的人脸等对象的检测。它通过利用一组被称为“类哈尔特征”(图1)的训练特征进行操作,这些特征是简单的矩形滤波器,专注于图像区域内像素强度的变化。这些特征可以捕捉人脸中常见的边缘、角度和其他特征。
训练过程包括为算法提供正面样本(包含人脸的图像)和负面样本(不包含人脸的图片)。然后,该算法通过调整特征的权重来学习区分这些样本。经过训练后,Haar Cascade本质上变成了一个分类器的层次结构,每个阶段都逐步完善检测过程。
为了实现人脸检测,我使用了一个预先训练的Haar Cascade模型,该模型是在人脸的前向图像上训练的。关键实现代码如下所示:
import cv2
face_cascade = cv2.CascadeClassifier('./configs/haarcascade_frontalface_default.xml')
def haar(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
print(len(faces) + " total faces detected.")
for (x, y, w, h) in faces:
print(f"Face detected in the box {x} {y} {x+w} {y+h}")MTCNN算法
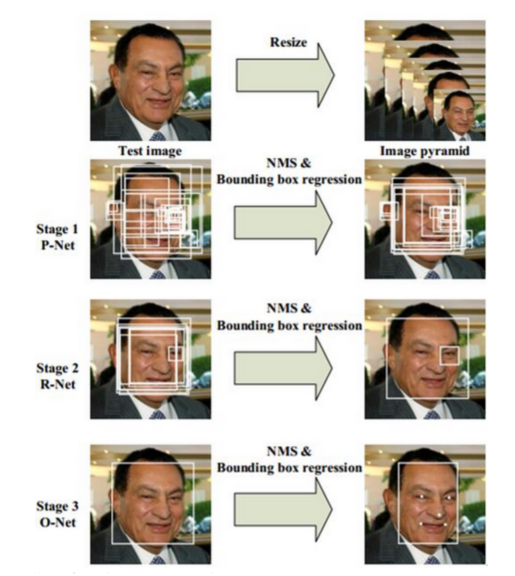
图2:MTNN算法中的人脸检测过程(来源——原始论文:)
MTNN(Multi-Task Cascaded Convolutional Networks,多任务级联卷积网络)是一种复杂且高度准确的人脸检测算法,超过了前面的Haar Cascades算法的能力。MTCNN算法设计在具有不同面部大小、方向和照明条件的场景中表现出色,它利用了一系列神经网络,每个神经网络都适合执行面部检测过程中的特定任务。
- 第一阶段——提案生成:MTNN通过一个小型神经网络生成大量潜在的人脸区域(边界框)来启动这一过程。
- 第二阶段——细化:在第一阶段生成的候选信息在此步骤中进行筛选。算法中的第二个神经网络用来评估所提出的边界框,调整它们的位置,以便与真实面部边界更精确地对齐。这有助于提高准确性。
- 第三阶段——识别和定位面部特征点:该阶段负责识别面部标志,如眼角、鼻子和嘴巴。然后,使用神经网络来精确定位这些特征。
MTNN算法引入的级联架构使其能够在过程的早期快速丢弃没有人脸的区域,将计算集中在包含人脸概率较高的区域。与Haar Cascades算法相比,它能够处理不同比例(缩放级别)的人脸和旋转,非常适合复杂场景下的应用。然而,这种算法的计算强度源于其基于神经网络的顺序方法。
为了实现MTNN,我使用了MTCNN库。关键实现代码如下所示:
import cv2
from mtcnn import MTCNN
detector = MTCNN()
def mtcnn_detector(image):
faces = detector.detect_faces(image)
print(len(faces) + " total faces detected.")
for face in faces:
x, y, w, h = face['box']
print(f"Face detected in the box {x} {y} {x+w} {y+h}")YOLOv5算法
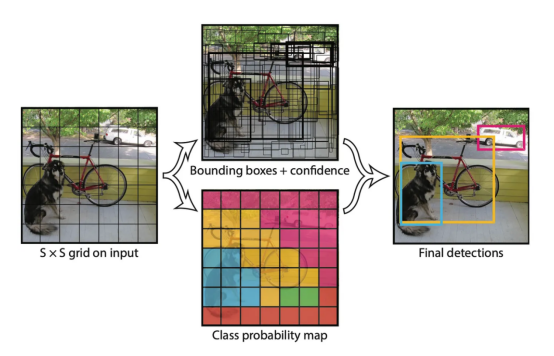
图3:YOLO目标检测过程(来源——原始论文)
YOLO(You Only Look Once)算法是一种用于检测包括人脸在内的大量对象的算法。与前代产品不同,YOLO通过神经网络进行单次检测,使其更快、更适合实时应用程序和视频场景。总体来看,使用YOLO检测媒体中人脸的过程可以分为四个部分:
- 图像网格划分:输入图像被划分为单元格网格。每个单元负责预测位于其边界内的对象。对于每个单元,YOLO算法预测边界框、对象概率和类概率。
- 边界框预测:在每个单元格中,YOLO算法预测一个或多个边界框及其相应的概率。这些边界框表示潜在的对象位置。每个边界框由其中心坐标、宽度、高度以及对象存在于该边界框内的概率来定义。
- 类别预测:对于每个边界框,YOLO预测对象可能属于的各种类别(例如,“脸”、“车”、“狗”)的概率。
- 非极大值抑制(NMS):为了消除重复的边界框,YOLO应用了NMS子算法。该过程通过评估冗余边界框的概率来丢弃冗余边界框,并与其他框重叠,只保留最可靠和不重叠的边界框。
YOLO算法的主要优势在于它的速度。由于它通过神经网络在一次前向传递中处理整个图像,因此它比涉及滑动窗口或区域建议的算法快得多。然而,这种速度可能会与精度略有权衡,尤其是对于较小的对象或拥挤的场景。
YOLO算法可以通过在人脸特定数据上对其进行训练并修改其输出类别以便仅包括一个类别(“脸”)来适应人脸检测。为此,我使用了基于YOLOv5算法构建的一个名叫“yoloface”的开源库。关键实现代码如下所示:
import cv2
from yoloface import face_analysis
face=face_analysis()
def yolo_face_detection(image):
img,box,conf=face.face_detection(image, model='tiny')
print(len(box) + " total faces detected.")
for i in range(len(box)):
x, y, h, w = box[i]
print(f"Face detected in the box {x} {y} {x+w} {y+h}")面部模糊(Face blurring)
在识别出图像中潜在人脸周围的边界框后,下一步是对其进行模糊处理以删除这些边界标识。对于这个任务,我开发了两个实现版本。用于演示这个任务的参考图像如图4所示。
 图4:参考图片(Ethan Hoover引自提供免费高清图片素材资源的Unsplash网站)
图4:参考图片(Ethan Hoover引自提供免费高清图片素材资源的Unsplash网站)
高斯模糊(Gaussian Blur)
 图5:具有高斯模糊的模糊参考图像
图5:具有高斯模糊的模糊参考图像
高斯模糊是一种用于减少图像噪声和污迹细节的图像处理技术。这在人脸模糊领域尤其有用,因为它可以从图像的这一部分中删除细节。这种算法计算每个像素附近的像素值的平均值。该平均值以被模糊的像素为中心,并使用高斯分布进行计算,从而为附近的像素赋予更多权重,而为远处的像素赋予更少权重。其结果是生成一个减少高频噪声和精细细节的软化图像。应用高斯模糊的结果如前面图5所示。
高斯模糊采用三个参数:
1. 要模糊的图像部分。
2. 内核大小:用于模糊操作的矩阵。较大的内核大小会导致更强的模糊。
3. 标准偏差:值越高,模糊效果越强。
f = image[y:y + h, x:x + w]
blurred_face = cv2.GaussianBlur(f, (99, 99), 15) #你可以调整模糊参数
image[y:y + h, x:x + w] = blurred_face像素化(Pixelization)
 图6:带像素化的模糊参考图像
图6:带像素化的模糊参考图像
像素化是一种图像处理技术,其中图像中的像素被替换为单一颜色的较大块。这种效果是通过将图像划分为单元格网格来实现的,其中每个单元格对应于一组像素。然后,将该单元中所有像素的颜色或强度作为该单元中全部像素的颜色的平均值,并将该平均值应用于该单元中的所有像素。此过程可创建简化的外观,从而降低图像中精细细节的级别。应用像素化的结果如图6所示。正如你所观察到的,像素化使识别一个人的身份变得非常复杂。
像素化算法使用一个主要的参数,该参数决定了一个特定区域应该有多少分组像素。例如,如果我们有一个包含人脸的图像的(10,10)部分,它将被10x10像素组所取代。越小的数字结果越模糊。
f = image[y:y + h, x:x + w]
f = cv2.resize(f, (10, 10), interpolation=cv2.INTER_NEAREST)
image[y:y + h, x:x + w] = cv2.resize(f, (w, h), interpolation=cv2.INTER_NEAREST)实验结果与评估
我将从两个角度评估不同的上述算法:实时性能分析和特定的图像场景。
实时性能
使用相同的参考图像(如图4所示)的情况下,我计算了每个人脸检测算法在图像中定位人脸边界框所需的时间。结果数据基于每种算法的10个测量值的平均值。模糊算法所需的时间可以忽略不计,在评估过程中不会考虑。
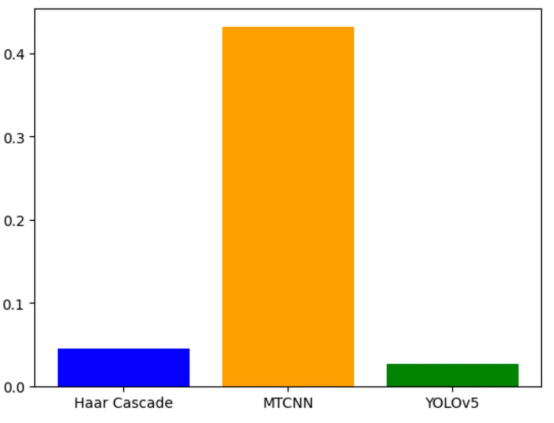 图7:每个算法检测人脸所需的平均时间(秒)花销
图7:每个算法检测人脸所需的平均时间(秒)花销
可以观察到,YOLOv5由于其通过神经网络的单程处理而实现了最佳性能(速度)。相比之下,像MTNN这样的方法需要通过多个神经网络进行顺序遍历。这进一步使算法的并行化过程复杂化。
基于场景的性能
为了评估上述算法的性能,除了参考图像(图4)外,我还选择了几张在各种场景中测试算法的图像:
1. 参考图像(图4)
2. 一群人靠得很近——以评估算法捕捉不同人脸大小的能力,有些更近,有些更远(图8)
3. 侧视人脸——测试算法检测不直视相机的人脸的能力(图10)
4. 翻转的人脸,180度——测试算法检测旋转180度人脸的能力(图11)
5. 翻转人脸,90度——测试算法检测侧向旋转90度人脸的能力(图12)
 图8:尼古拉斯·格林提供的在Unsplash网站上的人群相片
图8:尼古拉斯·格林提供的在Unsplash网站上的人群相片
 图9:Naassom Azevedo提供的在Unsplash网站上的多重面孔照片
图9:Naassom Azevedo提供的在Unsplash网站上的多重面孔照片
 图10:Unsplash网站上的来自Kraken Images的侧面图
图10:Unsplash网站上的来自Kraken Images的侧面图
 图11:将图4照片翻转180度
图11:将图4照片翻转180度
 图12:将图4照片翻转90度
图12:将图4照片翻转90度
Haar Cascade算法
Haar Cascade算法通常在匿名人脸方面表现良好,只有少数例外。它成功地检测到了参考图像(图4)和“多张脸”场景(图9)。在“人群”场景(图8)中,它可以很好地处理任务,尽管有些人脸没有被完全检测到或距离更远。Haar Cascade算法遇到了人脸不直接面对相机(图10)和旋转人脸(图11和12)的挑战,无法完全识别人脸。
 图13:Haar Cascade算法的运算结果
图13:Haar Cascade算法的运算结果
MTCNN算法
MTCNN算法设法实现了与Haar Cascade算法非常相似的结果,具有相同的优势和劣势。此外,MTNN算法很难检测到图9中肤色较深的人脸。
 图14:MTCNN算法的运算结果
图14:MTCNN算法的运算结果
YOLOv5算法
YOLOv5算法产生的结果与Haar Cascade算法和MTCNN算法略有不同。它成功地检测到人们没有直视相机的一张脸(图10),以及旋转了180度的脸(图11)。然而,在“人群”图像(图8)中,它并没有像前面提到的算法那样有效地检测更远的人脸。
 图15:YOLOv5算法的运算结果。
图15:YOLOv5算法的运算结果。
隐私问题
在解决图像处理中的隐私挑战时,需要考虑的一个关键方面是在保持图像自然外观的同时,在使人脸无法识别之间保持微妙的平衡。
高斯模糊
高斯模糊有效地模糊了图像中的面部区域(如图5所示)。然而,它的成功取决于用于模糊效应的高斯分布的参数。在图5中,很明显,面部特征仍然是可辨别的,这表明需要更高的标准差和内核大小来实现最佳结果。
像素化
与高斯模糊相比,像素化(如图6所示)作为一种人脸模糊方法,通常看起来更符合人眼的视觉感受。用于像素化的像素数量在这种情况下起着关键作用,因为较小的像素数量会使面部不太容易识别,但可能导致不太自然的外观。
总的来说,相对于高斯模糊算法,像素化算法一直是人们更喜欢的选择。理由在于人们更为熟悉这种算法以及这种算法语境的自然性,其在隐私和美学之间取得了较好的平衡。
逆向工程
随着人工智能工具的兴起,预测旨在从模糊图像中去除隐私过滤器的逆向工程技术的潜力变得至关重要。然而,模糊面部的行为不可逆转地用更广义的面部细节取代了特定的面部细节。到目前为止,人工智能工具只能在呈现同一个人的清晰参考图像时对模糊的人脸进行逆向工程。不过,这里也存在一个矛盾问题:这首先与逆向工程的必要性相矛盾,因为使用逆向工程的话必须以了解个人身份为前提。因此,面对不断发展的人工智能技术,人脸模糊是保护隐私的一种比较有效和必要的手段。
视频领域中的使用
由于视频本质上是一系列图像,因此修改每个算法以对视频进行匿名化相对简单。然而,在这里,处理耗费的时间变得至关重要。例如,对于以每秒60帧(每秒图像)记录的给定30秒视频,算法将需要处理1800帧。在这种情况下,像MTNN这样的算法是不可行的,尽管它们在某些场景中会有所改进。因此,我决定使用YOLO模型来实现视频匿名化。
import cv2
from yoloface import face_analysis
face=face_analysis()
def yolo_face_detection_video(video_path, output_path, pixelate):
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
raise ValueError("Could not open video file")
#取得视频属性
fps = int(cap.get(cv2.CAP_PROP_FPS))
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 定义编解码器并为输出视频创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'H264')
out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
tm = time.time()
img, box, conf = face.face_detection(frame_arr=frame, frame_status=True, model='tiny')
print(pixelate)
for i in range(len(box)):
x, y, h, w = box[i]
if pixelate:
f = img[y:y + h, x:x + w]
f = cv2.resize(f, (10, 10), interpolation=cv2.INTER_NEAREST)
img[y:y + h, x:x + w] = cv2.resize(f, (w, h), interpolation=cv2.INTER_NEAREST)
else:
blurred_face = cv2.GaussianBlur(img[y:y + h, x:x + w], (99, 99), 30) # 你可以调整模糊参数
img[y:y + h, x:x + w] = blurred_face
print(time.time() - tm)
out.write(img)
cap.release()
out.release()
cv2.destroyAllWindows()Web应用程序
为了简化对不同算法的比较与评估,我创建了一个Web版本的网络应用程序,用户可以在其中上传任何图像或视频,选择人脸检测和模糊算法。处理后,结果返回给用户。实现是使用Flask和Python在后端完成的,利用前面提到的库以及OpenCV和React.js在前端进行用户与模型的交互。完整的代码可在链接https://github.com/dani2221/dpns处获得。
结论
在本文项目中,我对包括Haar Cascade、MTNN和YOLOv5在内的各种人脸检测算法进行了不同方面的探索、比较和分析。此外,该项目还专注分析了图像模糊技术。
实验数据证明,Haar Cascade算法在某些场景中被证明是一种有效的方法,通常表现出良好的时间性能。MTNN算法作为一种在各种条件下都具有实体人脸检测能力的算法脱颖而出,尽管它在处理通常不处于传统方向的人脸时遇到了困难。YOLOv5算法具有实时人脸检测功能,是时间作为关键因素的场景(如视频)应用的绝佳选择,尽管在群组对象环境中的准确性略有下降。
最后,我把所有算法和技术都集成到一个单独的Web应用程序中。该应用程序提供了对所有人脸检测和模糊方法的轻松访问和利用,以及使用模糊技术处理视频的能力。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Exploration and Model Comparison,作者:Danilo Najkov




















