数据库数据同步中间件是用于实现数据库之间数据同步的工具或组件,它可以处理多种数据库类型,包括MySQL、Oracle、SQL Server等。
一、常见数据同步中间件
(1) DBSyncer
这是一款开源的数据同步中间件,适用于MySQL、Oracle、SqlServer、ES、SQL(Mysql/Oracle/SqlServer)等同步场景,同时支持上传插件自定义同步转换业务,还提供监控全量和增量数据统计图、应用性能预警功能。
(2) Canal
由Alibaba开源,基于binlog的增量日志组件,能够伪装成Mysql的slave,发送dump协议获取binlog,解析并存储起来给客户端消费。这使得它能够同步任何非查询类操作DDL和DML语句(除了数据查询语句select)。
(3) Apache Kafka
可以用来采集实时数据,并且支持分布式处理。
二、各数据同步中间件原理
1. DBSyncer同步原理
DBSyncer是一款开源的数据同步中间件,它的同步原理并不复杂,主要通过以下步骤实现。
(1) 读取双方数据
DBSyncer不依靠数据库日志、触发器、脚本等内部过程,只读取双方数据,并且采用独有高效算法,快速扫描比较,找出增量并写入目标库,从而使双方保持一致。
(2) 设置数据库连接字串
使得DBSyncer能连接双方数据库,再指定双方表与字段的对应关系,再设置同步方式(如增量同步)、同步频度(如每分钟一次),即可开始同步。
(3) 实时监控
DBSyncer提供实时监控功能,可以驱动全量或增量实时同步运行状态、结果、同步日志和系统日志。
2. Canal同步原理
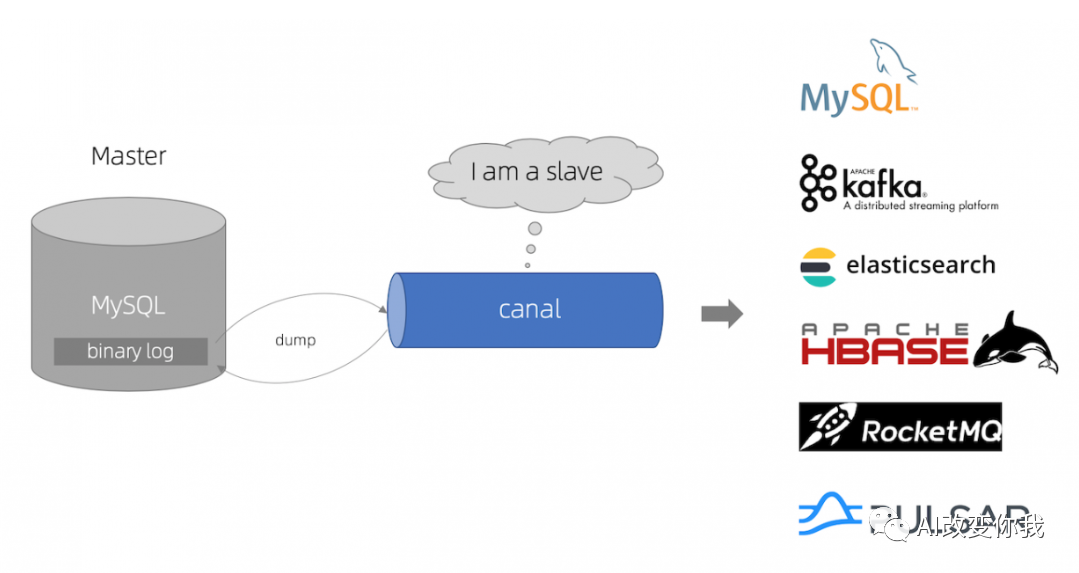
Canal的同步原理基于模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议。MySQL master收到dump请求后,开始推送binary log给slave(即canal)。canal解析这些binary log对象(原始的字节流),实现了MySQL数据库的增量订阅和消费业务。
Canal的工作原理主要解决了杭州和美国双机房部署的存在跨机房同步的业务需求。通过对数据库日志的分析,获取增量变更进行数据同步,以此实现MySQL数据库的增量订阅&消费的业务。
3. kafka同步原理
Kafka的数据同步原理基于生产者-消费者模型,并采用拉取(pull)方式进行数据传输。
(1) 数据可靠性保证
Kafka通过数据可靠性保证和数据同步来实现发送的数据能可靠地发送到指定的topic。每个topic的每个partition在收到生产者发送的数据后,都会向生产者发送一个ack(acknowledgement确认收到)。如果生产者收到ack,就会进行下一轮的数据发送,否则会重新发送数据。
(2) Kafka副本同步
Kafka的每个分区都有大量的数据,为了容忍n台节点的故障,Kafka的同步方案需要满足以下要求:
同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本。
虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
当ISR(In-Sync Replica,同步副本)中的follower完成数据的同步之后,leader就会给follower发送ack。
三、各数据同步中间件优缺点
1. canal的优缺点
Canal主要被设计用于实现数据库之间的增量数据同步,它具有以下优点:
- 实时性好:Canal基于binlog实现增量数据同步,可以实时地捕获数据库的变更,并及时推送到目标端。
- 分布式:Canal可以支持分布式环境下的数据同步,可以实现多台从数据库的增量数据同步到一台中心数据库,然后再由中心数据库将数据分发给其他的消费者节点。
- ACK机制:Canal在数据同步过程中引入了ACK机制,可以有效地降低数据传输的风险,提高数据同步的可靠性。
但是,Canal也存在一些缺点:
- 只支持增量同步:Canal只支持增量数据同步,而不支持全量同步。这意味着如果需要实现全量同步,还需要采用其他工具或方法来实现。
- 单点压力大:由于Canal的设计原理,当一个实例只能有一个消费端消费时,会存在单点压力较大的问题。如果这个实例出现故障,可能会影响到整个数据同步的过程。
- 日志量大:Canal对这种模式的binlog支持的比较好,每一条会修改数据的sql都会记录在binlog中,如果生产环境中的sql语句非常多,就会产生大量的日志量,可能会对数据库造成一定的压力。
以上就是Canal的优缺点,需要根据自身业务需求和使用场景来评估是否适合使用Canal。
2. Kafka的优缺点
Kafka的优点:
- 高可靠性:Kafka通过多种机制保证数据传输的可靠性,例如通过Canal解析MySQL的binlog日志来保证数据的准确性和完整性,以及提供高可用性和数据复制机制。
- 高性能:Kafka结合Canal能够实现高效的数据同步和分发。CanalClient通过binlog增量获取数据,降低了数据同步的工作量,而Kafka提供了高吞吐量的消息队列,可以快速地处理大量的数据流。
Kafka的缺点:
- 消息持久化:Kafka的消息是持久化到硬盘的,虽然可以保证消息不丢失,但是硬盘I/O会成为瓶颈,且有可能拖慢整体性能。
- 不具备原子性操作:Kafka中的每一个消息都有其唯一的offset,消费者通过这个offset来读取消息,但是这并不保证原子性操作。如果需要实现原子性操作,还需要在应用层进行额外的处理。
- 无法回溯旧消息:Kafka一旦写入就无法改变,如果需要修改旧消息,只能重新写入一条新的消息。
- 消息重复消费:如果消费者在处理消息时发生异常,可能会导致消息被重复消费。
- 不适合高频小数据量的处理:Kafka是设计用来处理大数据流量的,对于小数据量的高频处理可能并不是最优选择。
- 去中心化架构:虽然Kafka是去中心化的架构,没有中心节点,但是这也会带来一些问题,例如如果集群中的节点都出现故障,那么整个集群就会停止工作。
3. DBSynce的优缺点
DBSyncer是一款开源的数据同步中间件,它具有以下优点:
- 支持多种数据库类型:DBSyncer支持MySQL/Oracle/SqlServer/PostgreSQL/Elasticsearch(ES)、Kafka/File/SQL等多种数据库类型,可以满足不同场景下的数据同步需求。
- 自定义同步转换业务:DBSyncer支持上传插件自定义同步转换业务,用户可以通过编写插件来实现自己的同步转换逻辑,使得数据同步更加灵活和定制化。
- 监控全量和增量数据统计图:DBSyncer提供监控全量和增量数据统计图,用户可以实时查看数据同步的状态、结果和同步日志以及系统日志,方便故障排查和问题定位。
- 组合驱动和实时监控:DBSyncer支持自定义库同步到库组合,并可以实现关系型数据库与非关系型之间的组合,任意搭配表同步映射关系。同时,它还支持实时监控全量或增量实时同步运行状态、结果、同步日志和系统日志的功能。
然而,DBSyncer也存在一些不足之处:
- 开源社区较小:相较于其他一些知名数据库中间件,DBSyncer的开源社区相对较小,活跃度和贡献度相对较低,这可能会影响到其后续的发展和维护。
- 技术门槛较高:DBSyncer的使用和配置相对较为复杂,需要一定的技术能力和经验,对于一些技术新手可能存在一定的学习门槛。
- 稳定性有待提高:在某些场景下,DBSyncer可能会出现一些稳定性问题,例如内存占用过高、处理速度较慢等,这可能会影响到数据同步的效率和可靠性。
- 功能有待进一步完善:虽然DBSyncer已经具备一些基本的数据同步功能,但在某些高级功能方面还有待进一步完善,例如数据校验、断点续传等。
综上所述,DBSyncer在某些方面具有一定的优势,但也存在一些不足之处,用户需要根据自己的实际需求和使用场景来评估是否适合使用该中间件。
除了DBSyncer和Canal,还有其他一些数据同步中间件,包括但不限于以下几种:
- Apache Flink:Apache Flink是一种高性能、高吞吐量的流处理和批处理框架,可以处理大规模的数据流和批处理任务。它支持事件时间处理和状态保持,可以进行实时数据流的处理和分析。
- Apache Beam:Apache Beam是一种统一的编程模型,可以用于批处理和流处理任务。它提供了一组可扩展的API,可以用于编写批处理和流处理任务,并可以在不同的执行引擎上运行,包括Flink、Spark等。
- Apache NiFi:Apache NiFi是一种用于自动化和管理数据流的工具,可以用于创建复杂的流程和数据处理工作流。它可以与各种数据源和数据目的地集成,包括Kafka、HDFS、关系型数据库等。
- Apache Camel:Apache Camel是一种基于路由和中介器模式的开源集成框架,可以用于集成不同的系统和数据源。它可以自动路由和转换消息,并支持多种消息协议和数据格式。
这些中间件各有特点,具体选择哪种中间件需要根据实际业务需求和使用场景来评估。
四、各同步组件应用场景
每个数据库同步中间件的应用场景可能有所不同,以下是几种常见的应用场景:
- DBSyncer主要用于分布式业务数据的同步,例如电子商务平台、金融服务、游戏服务等等。这些业务需要对数据进行实时处理和备份,才能确保业务的顺畅和稳定。DBSyncer可以提供高效、可靠以及高度安全的数据同步服务,进一步提升业务的可信度和稳定性。
- Canal设计用于实现数据库之间的增量数据同步,基于binlog实现增量数据同步,可以实时地捕获数据库的变更,并及时推送到目标端。它主要应用于像阿里巴巴等大型互联网公司,用来实现大规模数据的实时同步。
- Apache Kafka主要处理大规模的实时数据流,如日志、事件、传感器数据等。它广泛应用于实时数据管道和流式处理应用中。
- Apache Flink主要用于处理大规模的数据流和批处理任务,支持事件时间处理和状态保持,可以进行实时数据流的处理和分析。
- Apache Beam是一个统一的编程模型,可应用于批处理和流处理任务,提供了一组可扩展的API,可以用于编写批处理和流处理任务,并可以在不同的执行引擎上运行。
- Apache NiFi则是用于自动化和管理数据流的工具,可与各种数据源和数据目的地集成,例如Kafka、HDFS、关系型数据库等。