在大语言模型内部,是否有一个世界模型?
LLM是否具有空间感?并且在多个时空尺度上都是如此?
最近,MIT的几位研究者发现,答案是肯定的!

论文地址:https://arxiv.org/abs/2310.02207
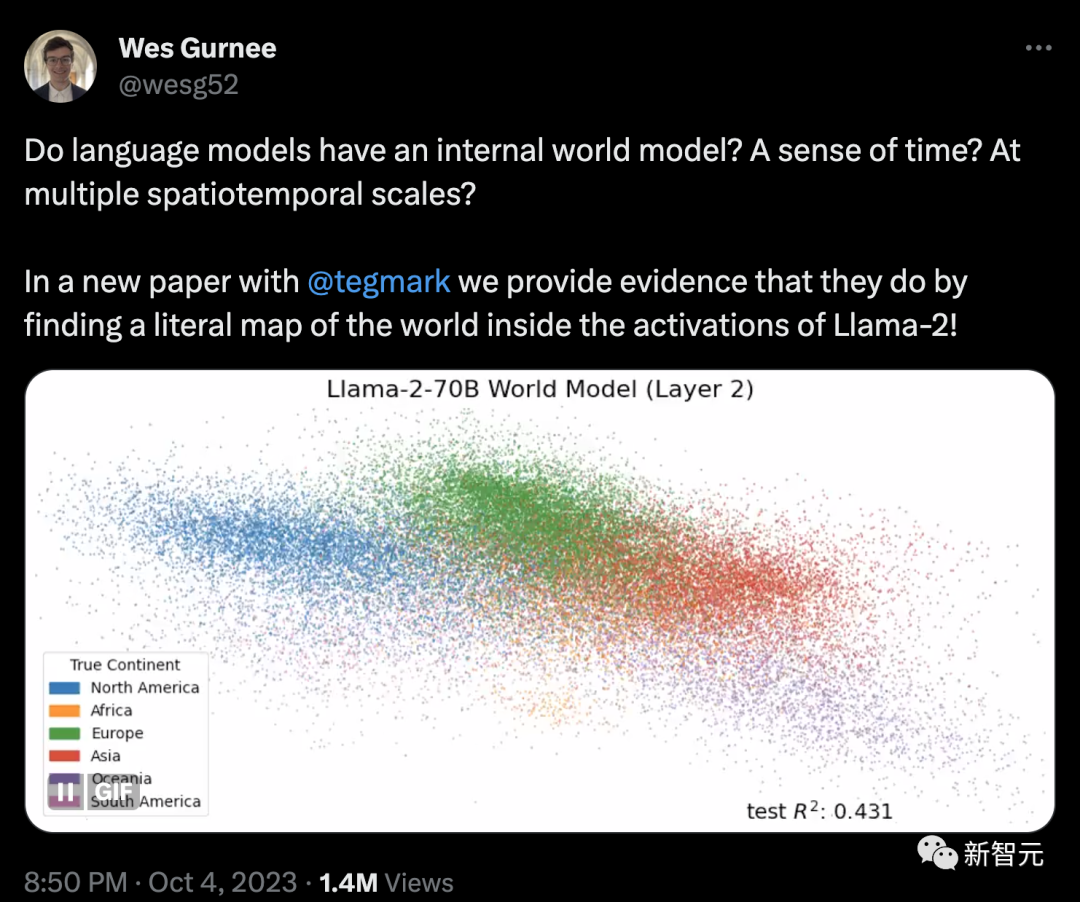
他们发现,在Llama-2-70B竟然能够描绘出研究人员真实世界的文字地图。

在空间表征上,研究者对世界各地数以万计的城市、地区和自然地标的名称运行了Llama-2模型。
他们在最后的token激活时训练了线性探测器,然后发现:Llama-2可以预测每个地方真实纬度和经度。

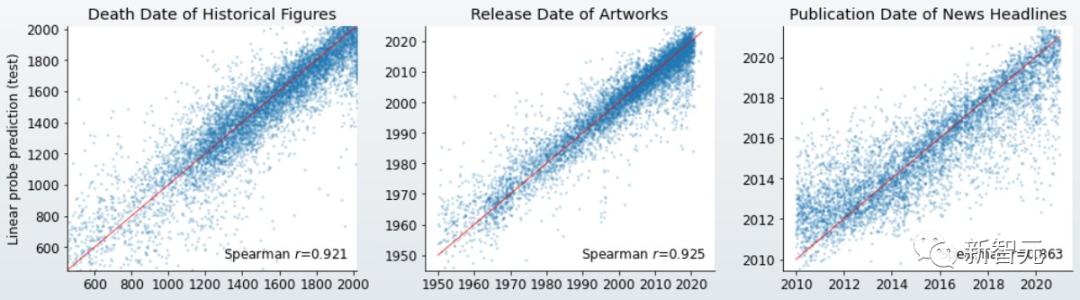
在时间表征上,研究者对过去3000年名人的名字、1950年以来的歌曲、电影和书籍的名称以及2010年代的《纽约时报》头条新闻运行了模型,并训练了线性探针(linear probe)成功预测到了名人的死亡年份、歌曲电影书籍的发布日期和新闻的出版日期。
总之,一切结论都显示:LLM不仅仅是随机鹦鹉——Llama-2包含世界的详细模型,毫不夸张地说,人类甚至在大语言模型中发现了一个「经度神经元」!

这项工作一推出,立马获得热烈反响。作者在推上转发了论文的概要,不到15个小时阅读量就已超过140万!
网友们纷纷惊呼:这项工作太了不起了!
有人表示:在直觉上,这是合理的。因为大脑正是提炼了我们的物理世界,将其存储在生物网络中。当我们「看到」事物时,它们实际上就是我们的大脑在内部处理的投射。
令人难以置信的是,你们竟然能够对此进行建模!
有人持相同观点,表示或许是我们试图模仿大脑的方式欺骗了造物主。

LLM不是随机鹦鹉
此前,许多人就这样猜想:大语言模型表现出的惊人能力,或许只是因为它学习了大量肤浅的统计数据集合,而并不是因为它是一个包含数据生成过程的连贯模型(也即世界模型)。
2021年,华盛顿大学语言学家Emily M. Bender发表了一篇论文,认为大型语言模型不过是「随机鹦鹉」(stochastic parrots)而已,它们并不理解真实世界,只是统计某个词语出现的概率,然后像鹦鹉一样随机产生看起来合理的字句。

由于神经网络的不可解释性,学术界也弄不清楚语言模型到底是不是随机鹦鹉,各方观点差异分歧极大。
由于缺乏广泛认可的测试,模型是否能「理解世界」也成为了哲学问题,而非科学问题。
然而MIT的研究者发现,LLM在多个尺度上都学习了空间和时间的线性表征,而这些表征对不同的提示变化具有稳健性,并且在不同的环境类型(如城市和地标)中具有统一性。
他们甚至发现,LLM还具有独立的「空间神经元」和「时间神经元」,可以可靠地编码空间和时间坐标。
也就是说,LLM绝不仅仅是学习了表面的统计数据,而是获得了关于空间和时间等基本维度的结构化知识。
总之,大语言模型能够理解世界。
LLM能理解空间和时间
在这篇论文中,研究人员提出了一个问题:LLM是否能通过数据集内容形成世界(以及时间)模型。
研究人员试图通过从LLM中提取真实的世界地图,来回答这个问题。
具体来说,研究人员构建了六个数据集,其中包含跨越多个时空维度的地点或事件名称以及相应的空间或时间坐标:
其中包括了世界范围内的地址,美国国内的地址和纽约市范围内的地址。

另外数据集还包括了不同的时间坐标:
1)历史人物的死亡年份
2)过去 3000 年的历史
3)20 世纪 50 年代以来艺术作品和娱乐节目的发布日期
4)2010年至2020年新闻头条的发布日期
使用 Llama 2 系列模型,研究人员训练了线性回归探针(probe),研究了这些地点和事件在模型每一层的名称的内部激活,来预测它们的真实世界位置或时间。
这些探索性的实验揭示了模型在整个早期层中构建空间和时间表征的证据,然后在模型中点附近达到稳定状态(plateauing),这个过程的结果在较大的模型的表现始终优于较小的模型。
进一步,研究人员证明这些表征是
(1)线性的,因为非线性探针表现不佳
(2)对提示的变化能有很高的鲁棒性
(3)不同类型的概念之间是相似的(例如,城市和自然地标之间是相似的)
研究人员认为,对于这个结果的一种可能的解释是,模型仅学习了从地方到国家的映射,而探针实际上学习了这些不同群体在地理空间(或时间)上如何相关的全球地理结构。
为了研究这一点,研究人员进行了一系列稳健性检查,以了解探针如何在不同的数据分布上进行泛化以及在 PCA 组件上训练的探针如何执行。

研究人员的研究结果表明,探针记住了这些概念的「绝对位置」,但模型确实具有一些反映「相对定位」的表征。
换句话说,探针学习了从模型中的坐标到人类可解释坐标的映射。
最后,研究人员使用探针来寻找作为空间或时间函数激活的单个神经元,提供强有力的证据证明该模型确实使用了这些特征。
准备工作
为了进行调查,研究人员构建了六个实体名称(人物、地点、事件等)的数据集,其中还包括了它们各自的位置或发生的时间,每个数据集的规模大小不同。
对于每个数据集,研究人员包含多种类型的实体,例如城市等人口稠密的地方和湖泊等自然地标,以研究不同对象类型的统一表示。
此外,研究人员优化并且丰富了相关元数据(metadata),以便能够通过更详细的细分来分析数据,识别训练测试泄漏的来源。
位置信息
研究人员构建了世界、美国和纽约市的三个地名数据集。研究人员的世界数据集是根据 DBpedia Lehmann 等人查询的原始数据构建的。
进一步,研究人员囊括了人口稠密的位置、自然位置和结构性位置(例如建筑物或基础设施)。然后,研究人员将这些内容与维基百科文章进行匹配,并过滤掉三年内页面浏览量不低于5000次的实体。
研究人员的美国数据集包括了城市、县、邮政编码、大学、自然地点和结构的名称,其中人口稀少或查看位置类似地被过滤掉。
纽约市数据集包含城市内的学校、教堂、交通设施和公共住房等位置。

时间信息
研究人员的三个时间数据集包括 :
(1) 公元前 1000 年至公元 2000 年之间去世的历史人物的姓名和职业,
(2) 使用维基百科页面浏览量过滤技术从DBpedia构建了包括1950年至 2020 年歌曲、电影和书籍的标题和作者;
(3) 2010 年至 2020 年《纽约时报》新闻头条,来自撰写时事新闻的新闻栏目。
数据准备
研究人员所有的实验都是使用基础版的Llama 2系列模型展开的,涵盖 70 亿到 700 亿个参数。
对于每个数据集,研究人员通过模型运行每个实体名称,可能会在前面加上一个简短的提示,并将隐藏状态(残留流,residual stream)的激活(activation)保存在每层的最后一个实体token上。
对于一组n个实体,这会为每个层生成一个 激活数据集。
激活数据集。
探针
为了寻找LLM中空间和时间表征的证据,研究人员使用标准探针技术。
它在网络激活(network activations)上拟合一个简单的模型,用来预测与标记输入数据相关的一些目标标签(target label)。特别是,给定激活数据集 A ∈ Rn×dmodel 和包含时间或二维纬度和经度坐标的目标 Y,研究人员拟合了线性岭回归探针(fit linear ridge regression probes)。

从而获得了线性探针:

对样本外数据的高预测性能表明基础模型在其表示中具有可线性解码的时间和空间信息,尽管这并不意味着该模型实际上使用了这些表征。
在所有实验中,研究人员在探针训练集上使用有效的留出交叉验证(efficient leave-out-out cross validation)来调整λ。
空间和时间的线性模型
存在性
研究人员首先研究这个实证问题:模型是否表征时间和空间?如果是这样,在模型内部的什么位置?表征质量是否会随着模型规模的变化而发生显著变化?
在研究人员的第一个实验中,研究人员为每个空间和时间数据集的Llama 2-{7B, 13B, 70B} 的每一层训练了探针。
研究人员的主要结果下图所示,显示了跨数据集相当一致的模式。特别是,空间和时间特征都可以通过线性探针恢复。
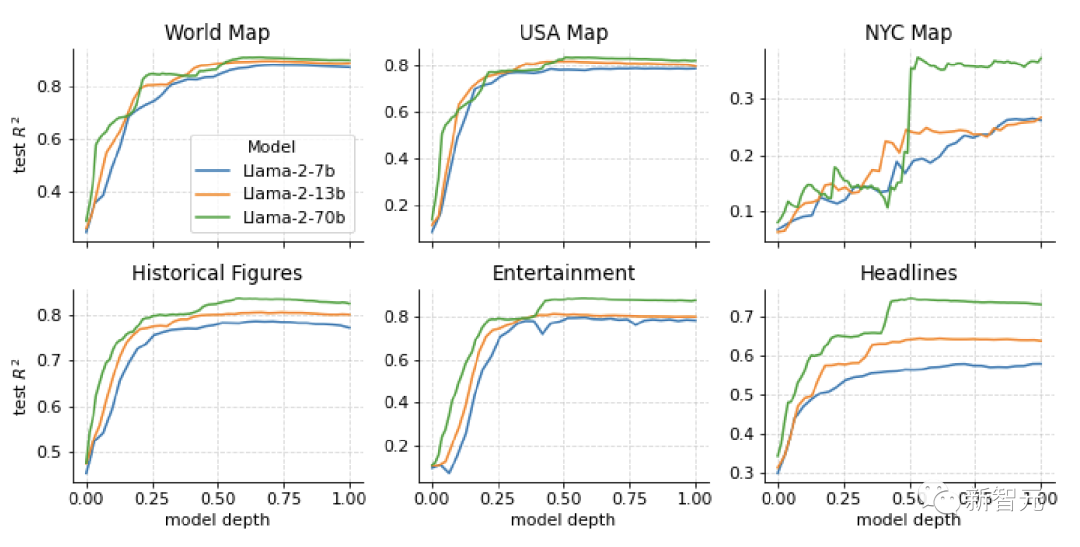
随着模型规模的增加,这些表示会变得更加准确,并且在达到稳定状态之前,模型前半层的表示质量会平稳提高。
这些观察结果与事实回忆文献的结果一致,表明早期到中期的 MLP 层负责回忆有关事实主题的信息。
性能最差的数据集是纽约市数据集。考虑到大多数实体与其他数据集相比相对模糊,这是预料之中的。
然而,这也是最大模型具有最佳相对性能的数据集,其R几乎是较小模型的2倍,这表明足够大的LLM最终可以形成各个城市的详细空间模型。
线性表征
在可解释性的文献中,越来越多的证据支持线性表征假设——神经网络中的特征是线性表示的。
也就是说,可以通过将相关激活投影到某个特征向量来读出特征的存在或强度。然而,这些结果几乎总是针对二元或分类特征,与空间或时间的自然连续特征不同。
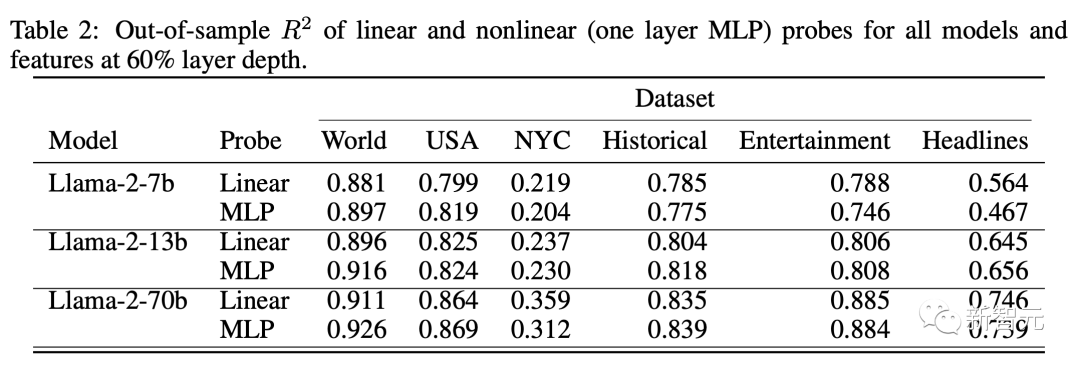
为了测试空间和时间特征是否以线性方式表示,研究人员将线性岭回归探针(linear ridge regression probes)的性能与更具表现力的非线性MLP ( more expressive nonlinear MLP)的性能进行了比较。
结果如下,表明对于任何数据集或模型,使用非线性探针对 R 的改进微乎其微。
研究人员将此作为强有力的证据,证明空间和时间也可以线性表示(或者至少是线性可解码的),尽管它们是连续的。
对提示词的敏感性
另一个很显然的问题是,这些空间或时间特征是否对提示词敏感,即上下文能否诱发或抑制对这些事实的回忆?
直观地,对于任何实体token,自回归模型都会被激励来生成适合解决任何未来可能的上下文或问题的表征。
为了研究这个问题,研究人员创建了新的激活数据集,其中研究人员按照几个基本主题为每个实体标记添加了不同的提示。在所有情况下,研究人员都包含了一个「空」提示,除了实体token(以及序列token的开头)之外不包含任何内容。
然后,研究人员添加一个提示,要求模型回忆相关事实,例如「<位置>的经纬度是多少?」或「<书> 的发行日期是哪一天?」
对于美国和纽约市的数据集,研究人员还包含这些提示的版本,询问该位置位于美国或纽约市的哪个位置,以消除常见地点名称的歧义(例如市政厅)。
作为基线,研究人员包括 10 个随机token的提示(针对每个实体进行采样)。为了确定研究人员是否可以混淆主题,对于某些数据集,研究人员将所有实体的名称完全大写。
最后,对于标题数据集,研究人员尝试探测最后一个token和附加到标题的句号token。
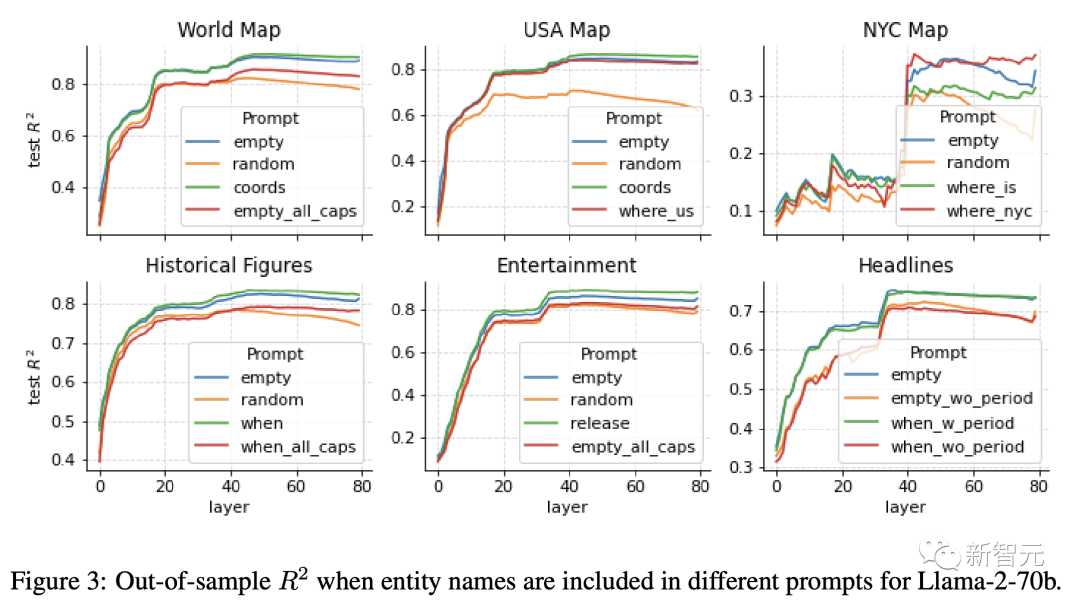
上图是70B模型的结果,下图是所有模型的结果。
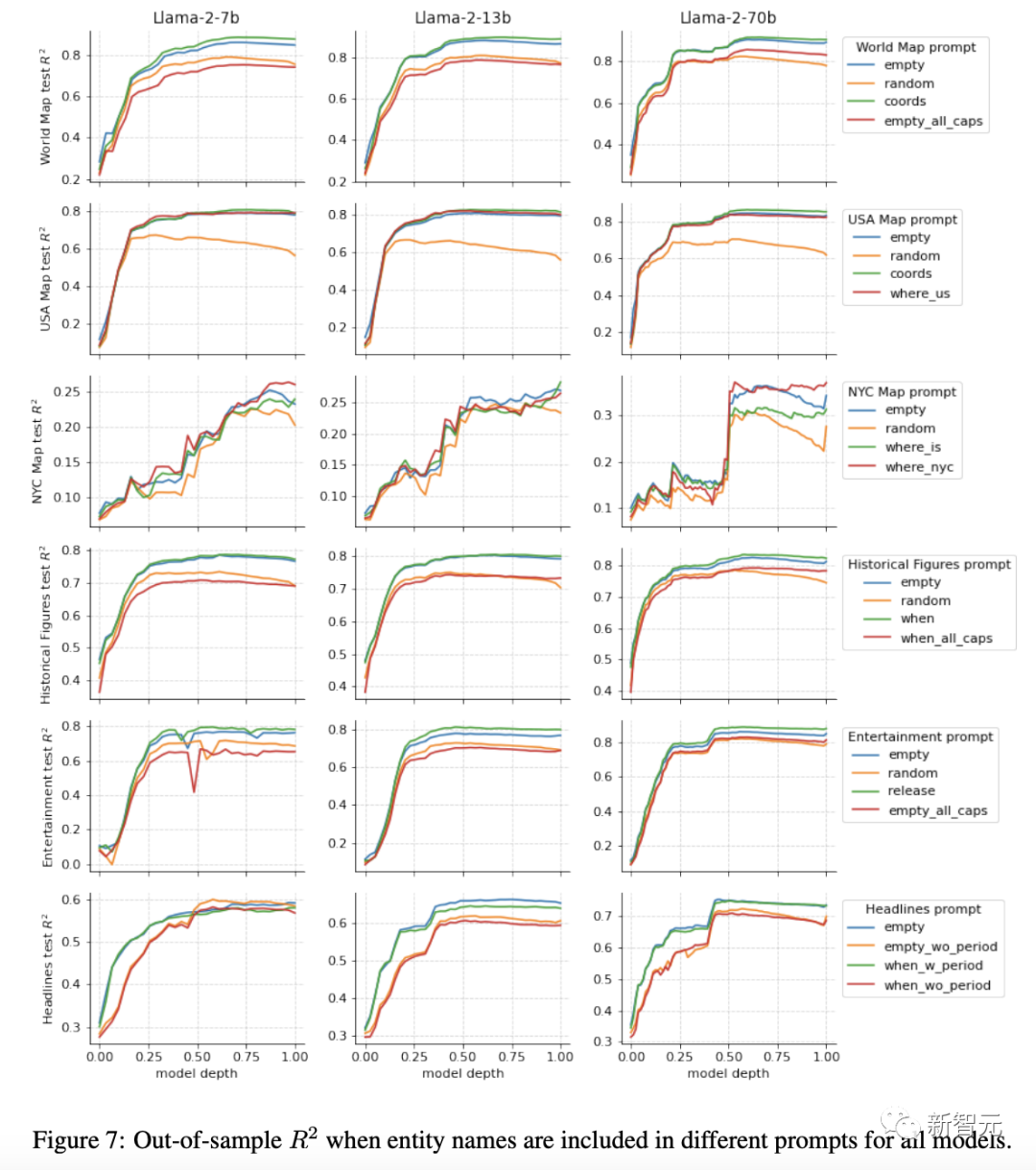
研究人员发现,明确提示模型输入信息,或者给出消歧提示,例如某个地方位于美国或纽约市,对性能几乎没有影响。然而,研究人员对随机干扰token降低性能的程度感到惊讶。
将实体名称大写也会降低性能,尽管不那么严重且不也不太出乎意料,因为这可能会干扰实体的「去token化」。
显著提高性能的一项修改是对标题后面的句号token进行探测,表明句号包含了结尾的句子的一些摘要信息。
鲁棒性检测
上一节已经表明,不同类型的事件或地点的真实时间或空间点可以从LLM中后期层的内部激活中线性恢复。
然而,这并不意味着模型是否(或如何)实际上使用了由探针学习到的特征方向,因为探针本身可以学习模型实际使用的更简单特征的一些线性组合。
通过泛化进行验证
为了说明研究人员的结果的潜在问题,考虑表示完整世界地图的任务。
如果模型如研究人员所期望的那样,「在X 国」具有几乎正交的二元特征,然后可以通过将每个国家的这些正交特征向量相加来构建高质量的纬度(经度)探针,其系数等于该国家/地区的纬度(经度)那个国家。
假设一个地方仅位于一个国家,这样的探测会将每个实体置于其国家质心。
然而,在这种情况下,模型实际上并不代表空间,仅代表国家成员资格,并且它只是从显式监督中学习不同国家几何形状的探针。
为了更好地区分这些情况,研究人员分析了探针在提供特定数据块时如何泛化。
特别是,研究人员训练了一系列探针,对于每个探针,研究人员分别提供世界、美国、纽约市、历史人物、娱乐和头条新闻数据集的一个国家、州、行政区、世纪、十年或年份。
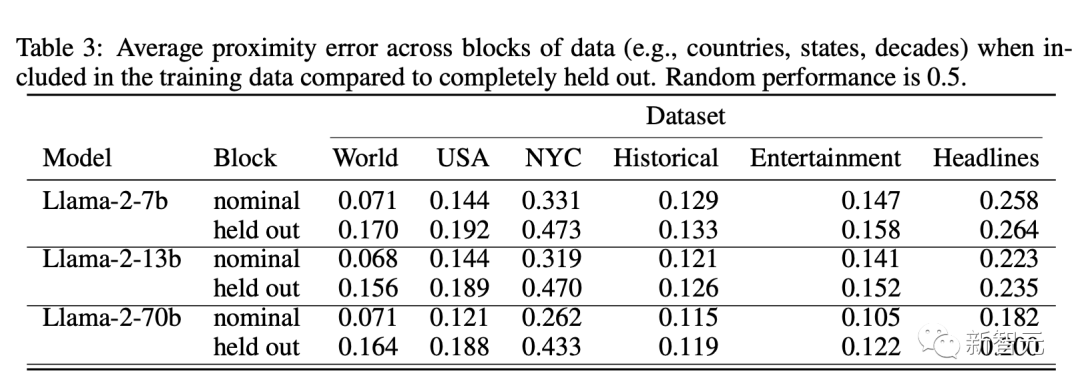
然后研究人员评估对保留的数据块的探测。在上表中,研究人员报告了完全保留时数据块的平均邻近误差,与默认训练-测试分割中该块的测试点的误差(对所有保留块进行平均)进行比较。
研究人员发现,虽然泛化性能受到影响,特别是对于空间数据集,但它明显优于随机数据集。通过绘制下图中所标注的州或国家的预测,一幅更清晰的图样就这样出现了。
 世界范围
世界范围
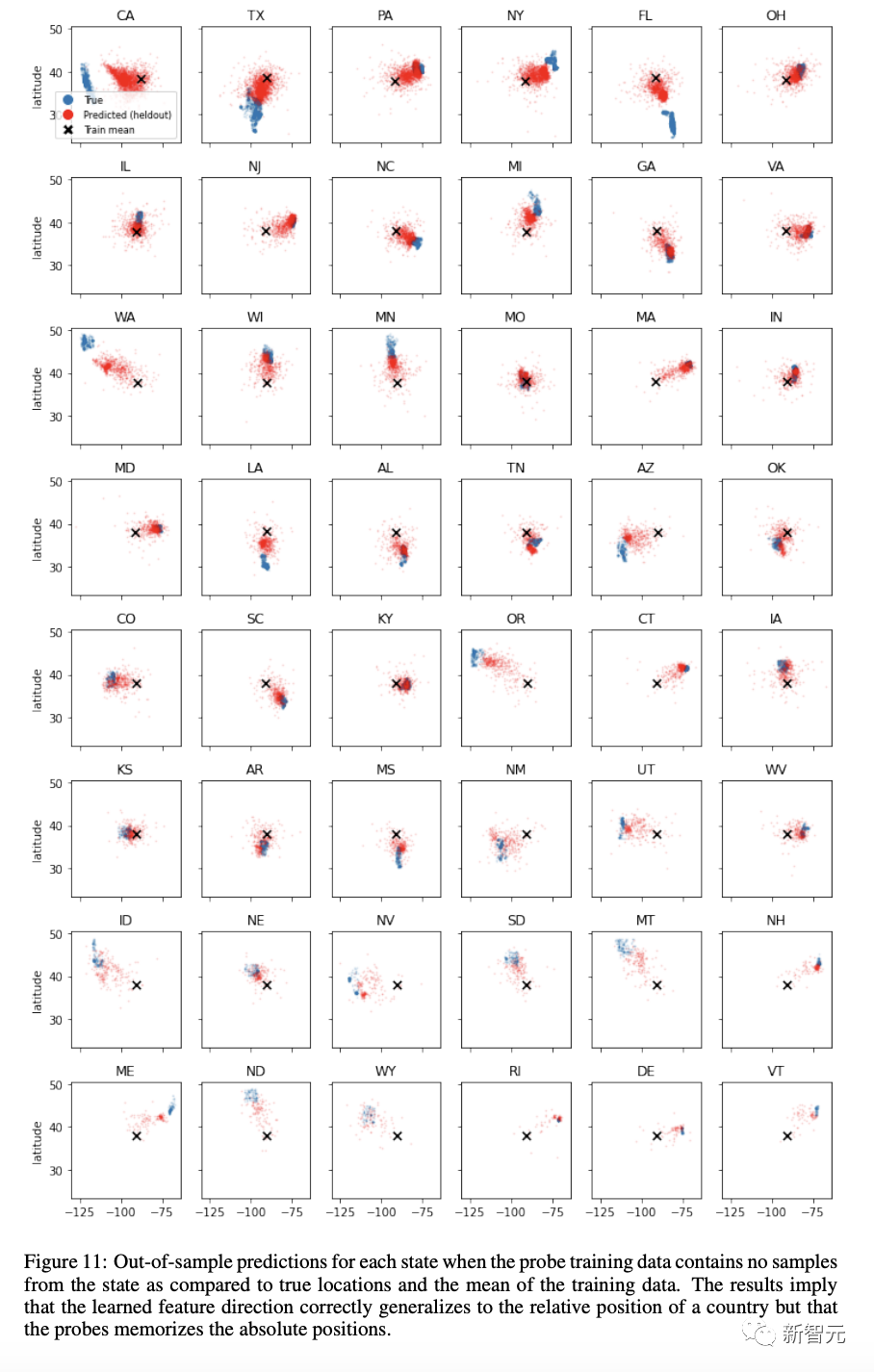
也就是说,探针通过将点放置在正确的相对位置(通过真实质心和预测质心之间的角度测量)而不是绝对位置来正确地进行概括。
研究人员将此视为微弱的证据,表明探针正在通过模型提取显式学习的特征,但正在记住从模型坐标到人类坐标的转换。
然而,这并不能完全排除潜在的二元特征假设,因为可能存在不遵循国家或十年边界的此类特征的层次结构。
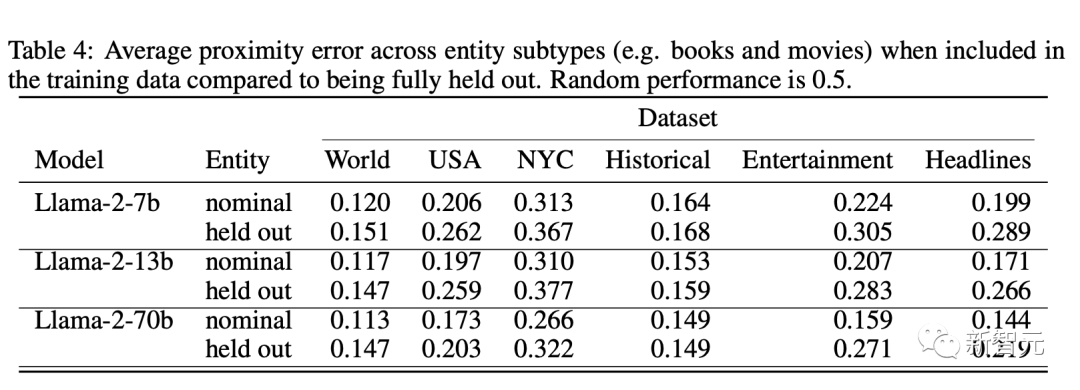
跨实体泛化
到目前为止,研究人员的讨论中隐含的主张是,该模型以统一的方式表示不同类型实体(如城市或自然地标)的空间或时间坐标。
然而,与纬度探测可能是隶属特征的加权和( be a weighted sum of membership features)类似,纬度探测也可以是城市纬度和自然地标纬度的不同(正交)方向的总和。
与上面类似,研究人员通过训练一系列探针来区分这些假设,其中执行训练测试分割以保留特定实体类的所有点如下表所示,了邻近度与保留时相比,默认测试拆分中的实体的误差,如之前对所有此类拆分进行平均。
结果表明,探针在很大程度上概括了实体类型,只有娱乐数据集除外。
空间和时间神经元
虽然之前的这些结果很有启发性,但没任何证据直接表明模型使用了探针学习到的特征。
为解决这个问题,研究人员搜索了具有输入或输出权重的单个神经元,这些权重与学习的探测方向具有高余弦相似性。
也就是说,研究人员寻找的神经元,其读取或写入的方向与探针学习到的方向相似。
他们发现,将激活数据集投射到最相似神经元的权重上时,这些神经元确实对实体在空间或时间上的真实位置高度敏感。
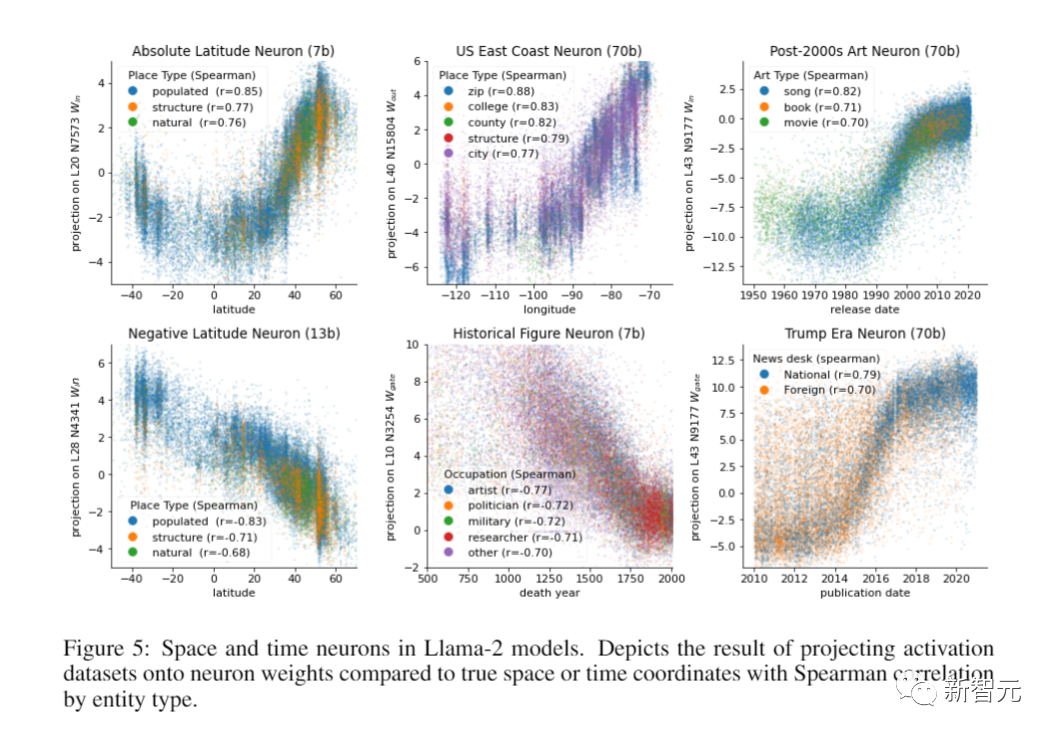
也就是说,模型中存在个别神经元,它们本身就是具有相当预测能力的特征探针。
此外,这些神经元对数据集中的所有实体类型都很敏感,这就更加表明了,这些表征是统一的。
如果说,在显式监督下训练的探针,是模型表示这些空间和时间特征程度的近似上限,那么单个神经元的表现就是下限。
特别是,学者们通常认为特征是叠加分布的,这使得单个神经元的分析水平是错误的 。
尽管如此,这些单个神经元的存在(除了下一个token预测之外,它们没有接受任何监督)依然是强有力的证据,证明模型学习并使用了空间和时间的特征。
奥赛罗GPT证明LLM理解世界,获吴恩达力赞
启发MIT研究者最直接的灵感,就是此前对深度学习系统在多大程度上形成数据生成过程的可解释模型的研究。
而最有力、最清晰的演示,无疑就来自在国际象棋和奥赛罗游戏上训练的GPT模型了——这些模型对于棋盘和游戏状态都有明确的表征。
今年2月,来自哈佛大学、麻省理工学院的研究人员共同发表了一项新研究Othello-GPT,在简单的棋盘游戏中验证了内部表征的有效性。
他们认为语言模型的内部确实建立了一个世界模型,而不只是单纯的记忆或是统计,不过其能力来源还不清楚。

论文链接:https://arxiv.org/pdf/2210.13382.pdf
实验过程非常简单,在没有任何奥赛罗规则先验知识的情况下,研究人员发现模型能够以非常高的准确率预测出合法的移动操作,捕捉棋盘的状态。
吴恩达在「来信」栏目中对该研究表示高度认可,他认为基于该研究,有理由相信大型语言模型构建出了足够复杂的世界模型,在某种程度上来说,确实理解了世界。
博客链接:https://www.deeplearning.ai/the-batch/does-ai-understand-the-world/
棋盘世界模型
如果把棋盘想象成一个简单的「世界」,并要求模型在对局中不断决策,就可以初步测试出序列模型是否能够学习到世界表征。

研究人员选择一个简单的黑白棋游戏奥赛罗(Othllo)作为实验平台,其规则是——
在8*8棋盘的中心位置,先放入四个棋子,黑白各两个;然后双方轮流下子,在直线或斜线方向,己方两子之间的所有敌子(不能包含空格)全部变为己子(称为吃子),每次落子必须有吃子;最后棋盘全部占满,子多者为胜。
相比国际象棋来说,奥赛罗的规则简单得多;同时棋类游戏的搜索空间足够大,模型无法通过记忆完成序列生成,所以很适合测试模型的世界表征学习能力。
Othello语言模型
研究人员首先训练了一个GPT变体版语言模型(Othello-GPT),将游戏脚本(玩家做出的一系列棋子移动操作)输入到模型中,但模型没有关于游戏及相关规则的先验知识。
模型也没有被明确训练以追求策略提升、赢得对局等,只是在生成合法奥赛罗移动操作时准确率比较高。
数据集
研究人员使用了两组训练数据:
锦标赛(Championship)更关注数据质量,主要是从两个奥赛罗锦标赛中专业的人类玩家采用的、更具战略思考的移动步骤,但分别只收集到7605个和132921个游戏样本,两个数据集合并后以8:2的比例随机分成训练集(2000万个样本)和验证集(379.6万个)。

合成(Synthetic)更关注数据的规模,由随机的、合法的移动操作组成,数据分布不同于锦标赛数据集,而是均匀地从奥赛罗游戏树上采样获得,其中2000万个样本用于训练,379.6万个样本用于验证。
每场游戏的描述由一串token组成,词表大小为60(8*8-4)。
模型和训练
模型的架构为8层GPT模型,具有8个头,隐藏维度为512。
模型的权重完全随机初始化,包括word embedding层,虽然表示棋盘位置的词表内存在几何关系(如C4低于B4),但这种归纳偏置并没有明确表示出来,而是留给模型学习。
预测合法移动
模型的主要评估指标就是模型预测的移动操作是否符合奥赛罗的规则。
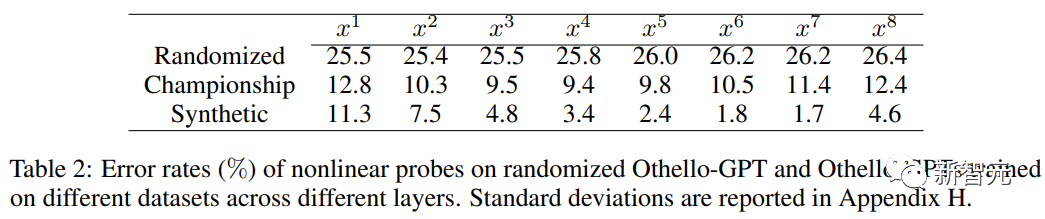
在合成数据集上训练的Othello-GPT错误率为0.01%,在锦标赛数据集上的错误率为5.17%,相比之下,未经训练的Othello-GPT的错误率为93.29%,也就是说这两个数据集都一定程度上让模型学会了游戏规则。
一个可能的解释是,模型记住了奥赛罗游戏的所有移动操作。
为了验证这个猜想,研究人员合成了一个新的数据集:在每场比赛开始时,奥赛罗有四种可能的开局棋位置(C5、D6、E3和F4),将所有C5开局的走法移除后作为训练集,再将C5开局的数据作为测试,也就是移除了近1/4的博弈树,结果发现模型错误率仍然只有0.02%。
所以Othello-GPT的高性能并不是因为记忆,因为测试数据是训练过程中完全没见过的,那到底是什么让模型成功预测?
探索内部表征
一个常用的神经网络内部表征探测工具就是探针(probe),每个探针是一个分类器或回归器,其输入由网络的内部激活组成,并经过训练以预测感兴趣的特征。
在这个任务中,为了检测Othello-GPT的内部激活是否包含当前棋盘状态的表征,输入移动序列后,用内部激活向量对下一个移动步骤进行预测。
当使用线性探针时,训练后的Othello-GPT内部表征只比随机猜测的准确率高了一点点。

当使用非线性探针(两层MLP)时,错误率大幅下降,证明了棋盘状态并不是以一种简单的方式存储在网络激活中。
干预实验
为了确定模型预测和涌现世界表征之间的因果关系,即棋盘状态是否确实影响了网络的预测结果,研究人员进行了一组干预(intervention)试验,并测量由此产生的影响程度。
给定来自Othello-GPT的一组激活,用探针预测棋盘状态,记录相关联的移动预测,然后修改激活,让探针预测更新的棋盘状态。
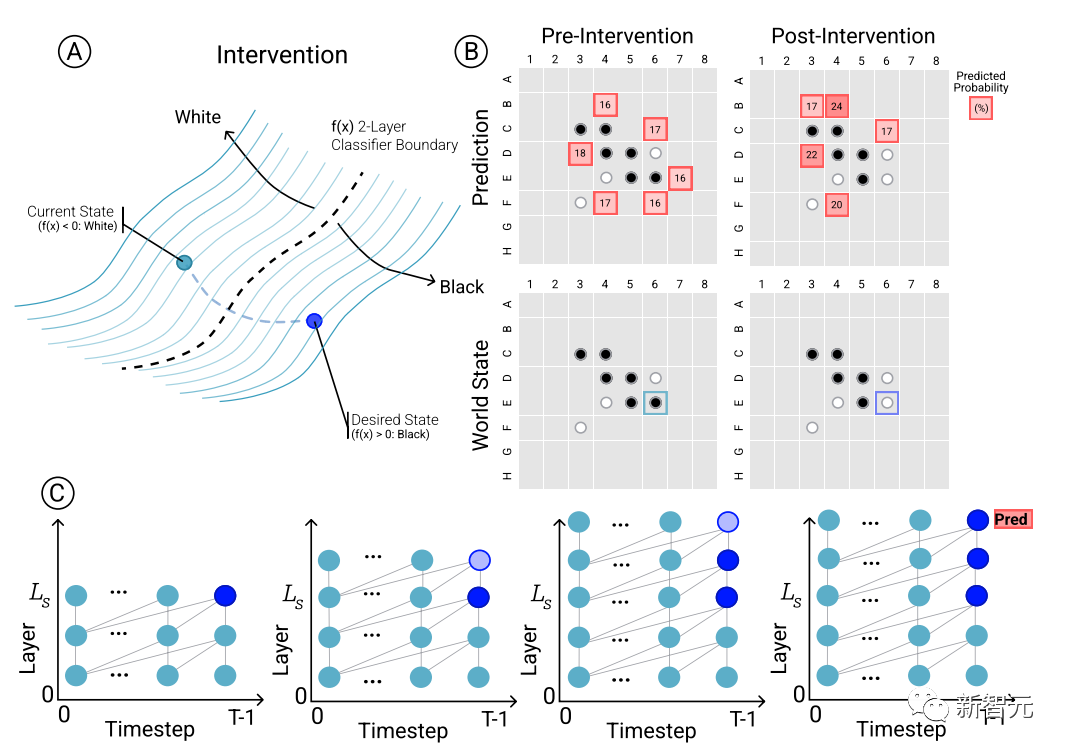
干预操作包括将某个位置的棋子从白色变成黑色等,一个小的修改就会导致模型结果发现内部表征能够可靠地完成预测,即内部表征与模型预测之间存在因果影响。
可视化
除了干预实验验证内部表征的有效性外,研究人员还将预测结果可视化,比如说对于棋盘上的每个棋子,可以询问模型如果用干预技术将该棋子改变,模型的预测结果将如何变化,对应预测结果的显著性。
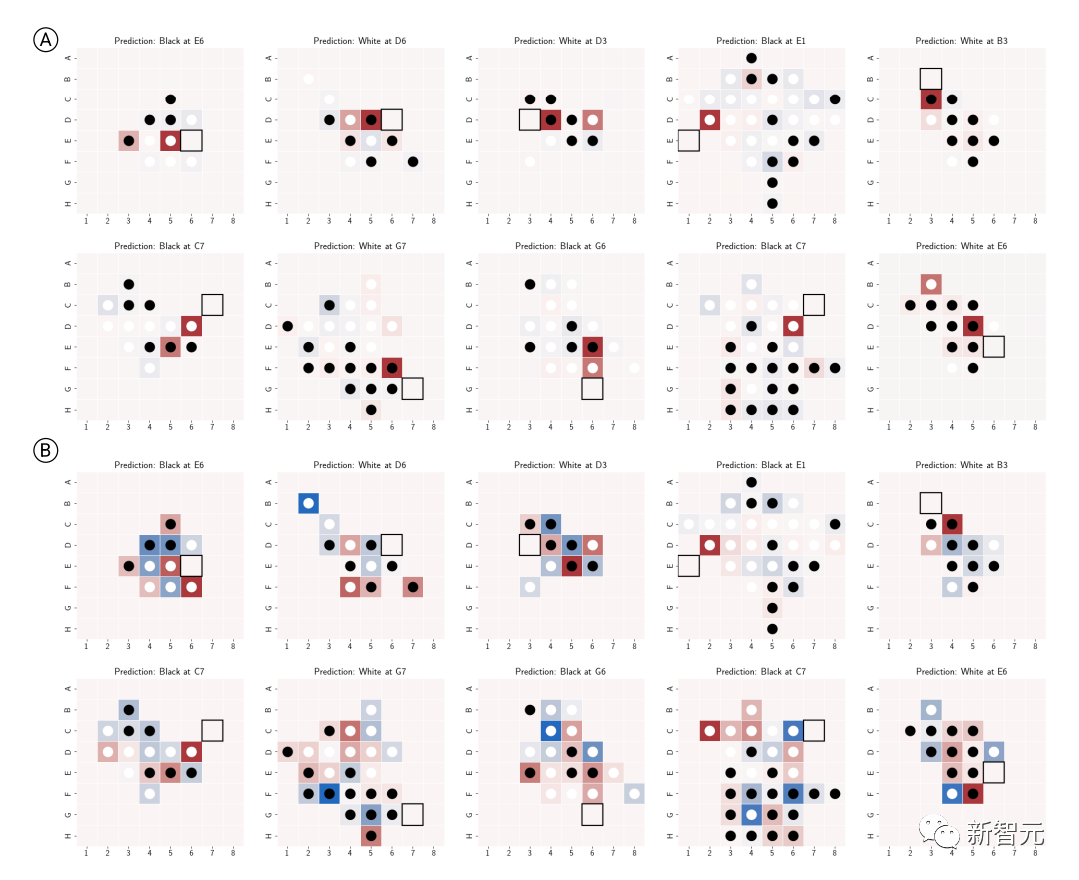
可以看到,在合成和锦标赛数据集上训练的Othello-GPTs的top1预测的潜显著性图中都展现出了清晰的模式。
总之,从哈佛和MIT的这项研究中可以看出,大语言模型的确理解了世界,无怪乎会得到吴恩达的赞赏了。
GPT-4只是AGI的火花?LLM终将退场,世界模型才是未来
为什么「世界模型」如此吸引人?
这正是因为,人工智能的终极形态和发展的最终目标——通用人工智能(AGI),一个「能够理解世界的模型」,而不仅仅是「描述世界的模型」。
1931 年,Kurt Gödel发表了不完备性定理。
Gödel定理表明,即使是数学也无法最终证明一切——人类始终会有无法证明的事实——而量子理论则说明,研究人员的世界缺乏确定性,使研究人员无法预测某些事件,例如电子的速度和位置。

尽管爱因斯坦曾表达过「上帝不会与宇宙玩骰子」这一著名的观点,但从本质上讲,仅仅在预测或理解物理中的事物时,人类的局限性就已经体现得淋漓尽致。
在「How We Learn」一书中,学者Stanislas Dehaene将学习定义为 「形成世界模型的过程」。
2016年,AlphaGo在围棋比赛中以 4 比 1 的大比分击败世界冠军李世石。
然而,它缺乏人类那种识别不常见战术,并做出相应调整的能力。因此,它仅仅是一种弱人工智能。
而研究人员所需的AGI,是一个与经验一致且能做到准确预测的世界模型。
4月13日,OpenAI的合作伙伴微软发布了一篇论文「Sparks of Artificial General Intelligence:Early experiments with GPT-4」(通用人工智能的火花:GPT-4的早期实验)。

论文地址:https://arxiv.org/pdf/2303.12712
其中提到:
GPT-4不仅掌握了语言,还能解决涵盖数学、编码、视觉、医学、法律、心理学等领域的前沿任务,且不需要人为增加任何的特殊提示。
并且在所有上述任务中,GPT-4的性能水平都几乎与人类水平相当。基于GPT-4功能的广度和深度,研究人员相信它可以合理地被视为通用人工智能的近乎但不完全的版本。
然而,就如同诸多专家所批评的,错误地将性能等同于能力,意味着GPT-4生成的是对世界的摘要性描述认为是对真实世界的理解。
现在的大多数模型仅接受文本训练,不具备在现实世界中说话、听声、嗅闻以及生活行动的能力。
就仿佛柏拉图的洞穴寓言,生活在洞穴中的人只能看到墙上的影子,而不能认识到事物的真实存在。

而无论是哈佛和MIT 2月的研究,还是今天的这篇论文,都指出了大语言模型的确在一定程度上能够理解世界,而并不仅仅是保证自己在语法上的正确。
仅仅是这些可能性,已经足够令人振奋。