












本文经自动驾驶之心公众号授权转载,转载请联系出处。
原标题:Cross-Dataset Experimental Study of Radar-Camera Fusion in Bird’s-Eye View
论文链接:https://arxiv.org/pdf/2309.15465.pdf
作者单位:Opel Automobile GmbH Rheinland-Pfalzische Technische Universitat Kaiserslautern-Landau German Research Center for Artificial Intelligence

论文思路:
通过利用互补的传感器信息,毫米波雷达和camera融合系统有潜力为先进的驾驶员辅助系统和自动驾驶功能提供高度稳健和可靠的感知系统。基于相机的目标检测的最新进展提供了新的毫米波雷达相机与鸟瞰特征图融合的可能性。本文提出了一种新颖且灵活的融合网络,并评估其在两个数据集上的性能:nuScenes 和 View-of-Delft。本文的实验表明,虽然camera分支需要大量且多样化的训练数据,但毫米波雷达分支从高性能毫米波雷达中受益更多。使用迁移学习,本文提高了camera在较小数据集上的性能。本文的结果进一步表明,毫米波雷达-camera融合方法显着优于仅camera和仅毫米波雷达基线。
网络设计:
最近3D目标检测的一个趋势是将图像的特征转换成一种常见的鸟瞰图(BEV)表示,它提供了一种灵活的融合架构,可以在多个camera之间进行融合,也可以使用测距传感器进行融合。在这项工作中,本文扩展了原本用于激光camera融合的BEVFusion方法来进行毫米波雷达camera融合。本文用选定的毫米波雷达数据集训练和评估了本文提出的融合方法。在几个实验中,本文讨论了每个数据集的优缺点。最后,本文应用迁移来实现进一步的改进。

图1基于BEVFusion的BEV毫米波雷达-camera融合流程图。在生成的camera图像中,本文包括投影毫米波雷达探测和 ground truth 边界框。
本文遵循BEVFusion的融合架构。图1展示了本文在BEV中进行毫米波雷达-camera融合的网络概况。请注意,融合发生时,camera和毫米波雷达特征在BEV连接。下面,本文将为每个区块提供进一步的细节。
A. Camera Encoder and Camera-to-BEV View Transform
camera编码器和视图变换采用了[15]的思想,它是一种灵活的框架,可以提取任意camera外部和内部参数的图像BEV特征。首先,使用tiny-Swin Transformer网络从每个图像中提取特征。接下来,本文利用[14]的 Lift 和 Splat 步骤将图像的特征转换到BEV平面。为此,密集深度预测之后是基于规则的block,其中的特征被转换成伪点云,并进行栅格化并累积到BEV网格中。
B. Radar Pillar Feature Encoder
此块的目的是将毫米波雷达点云编码到与图像BEV特征相同的网格上的BEV特征中。为此,本文使用了[16]的 pillar 特征编码技术,将点云光栅化为无限高的体素,即所谓的pillar。
C. BEV Encoder
与[5]相似,毫米波雷达和camera的BEV特征是通过级联融合的。融合的特征然后由联合卷积BEV编码器处理,使网络能够考虑空间错位和使用不同模态之间的协同效应。
D. Detection Head
本文使用CenterPoint检测头来预测每个类的目标中心的heatmaps。进一步的回归头预测物体的尺寸、旋转和高度,以及nuScenes的速度和类属性。而 heatmaps 采用 Gaussian focal loss 进行训练,其余的检测头采用 L1 loss 进行训练。
实验结果:
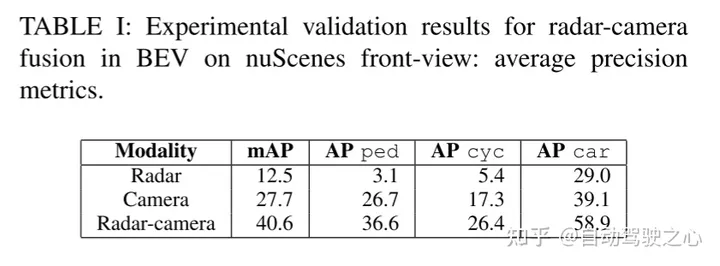

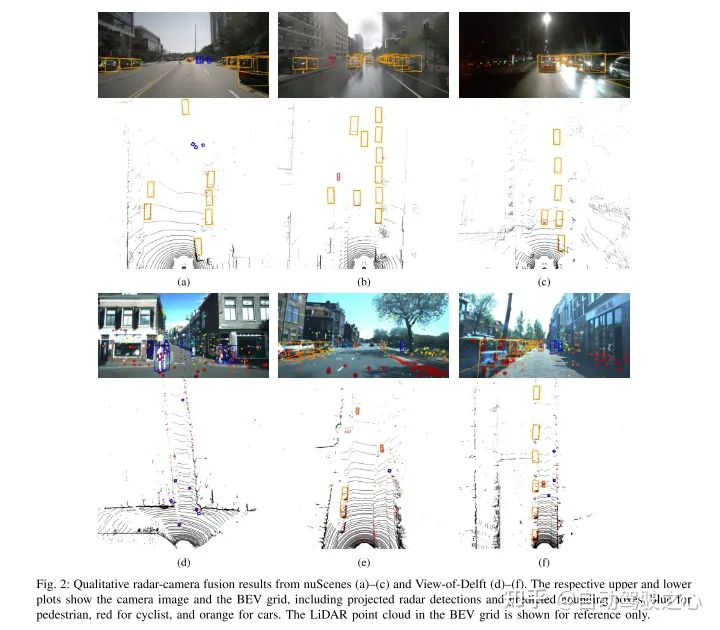
引用:
Stäcker, L., Heidenreich, P., Rambach, J., & Stricker, D. (2023). Cross-Dataset Experimental Study of Radar-Camera Fusion in Bird's-Eye View. ArXiv. /abs/2309.15465

原文链接;https://mp.weixin.qq.com/s/5mA5up5a4KJO2PBwUcuIdQ


























