这周三,OpenAI刚刚宣布解禁ChatGPT多模态能力。
如今,一上线,网友们瞬间玩疯了。
接下来,一起看看,ChatGPT的识图能力,究竟有多强?
拍照传图,即生代码
一位网友录制了一段上传开会时的一张白板图,然后让ChatGPT写出代码。

还有,你可以上传一张手绘的草稿图,然后要求ChatGPT在HTML创建网页。

嗖嗖嗖,代码分分钟都出来了。
这简直就是,今年GPT-4刚刚发布时,Greg Brockman所展示的多模态能力。
再比如,把你的to do list本子拍一张照片。

然后让GPT-4做一个Python Tkinter GUI,然后就实现了...

古卷手稿,一眼转译
再来一张来自17世纪的炼金术师Robert Boyle的手稿图,GPT-4能不能读懂它?

这简直对它来说,小菜一碟。

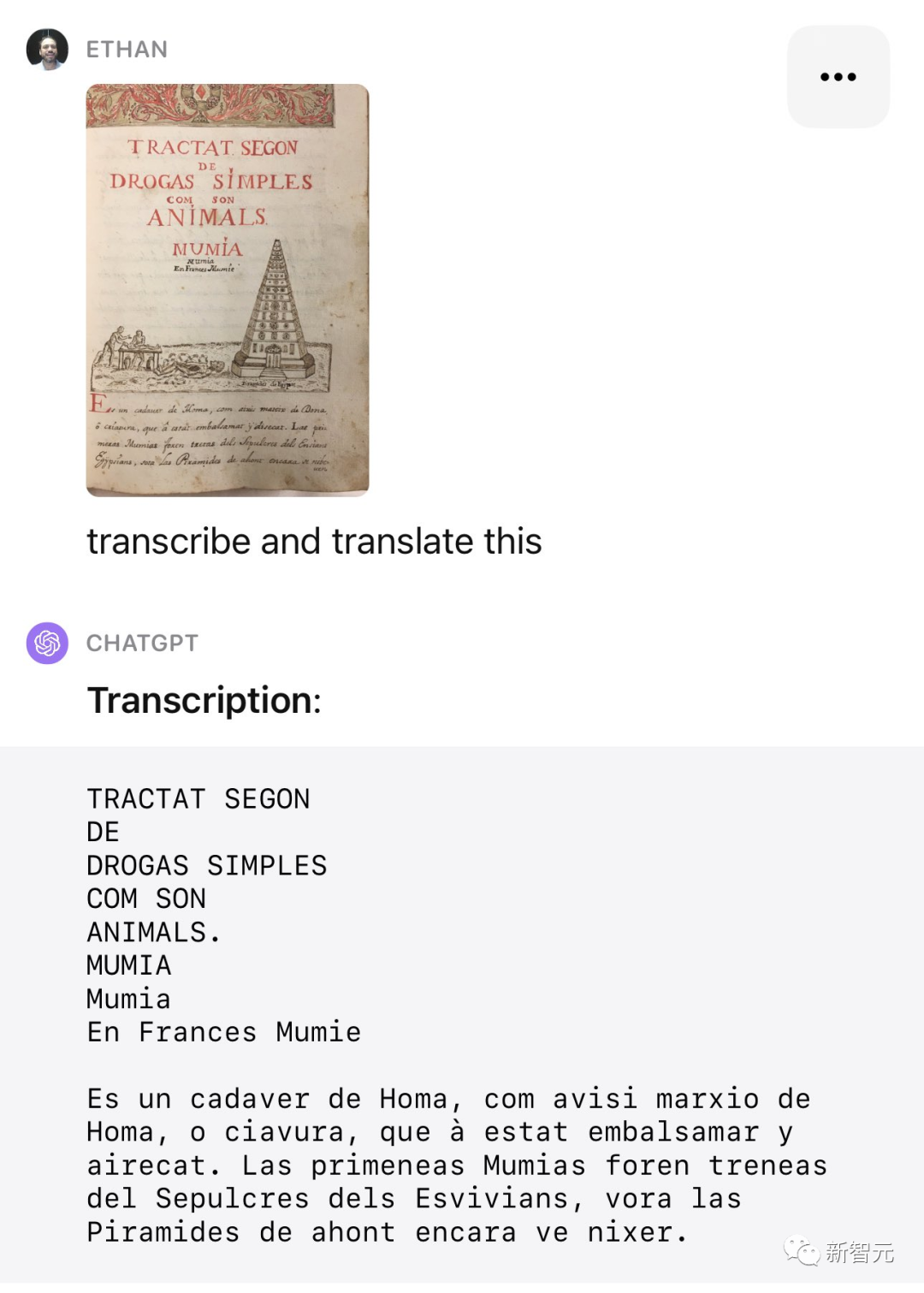
在比如「加泰罗尼亚语关于药用木乃伊的药物手册」。

ChatGPT同样能够转录并翻译出来。
来自UCSC的历史学副教授Benjamin Breen表示,
这将对历史学家产生重大影响。试想一下,一个定制的多模态GPT-4可以对一组特定的手稿进行训练。它不仅可以转录,还可以翻译和分类。(正是这一点,不使用LLM进行写作,在我看来才是一件大事)。

图表总结也很6
你还可以命令GPT-4根据图表提取数据。
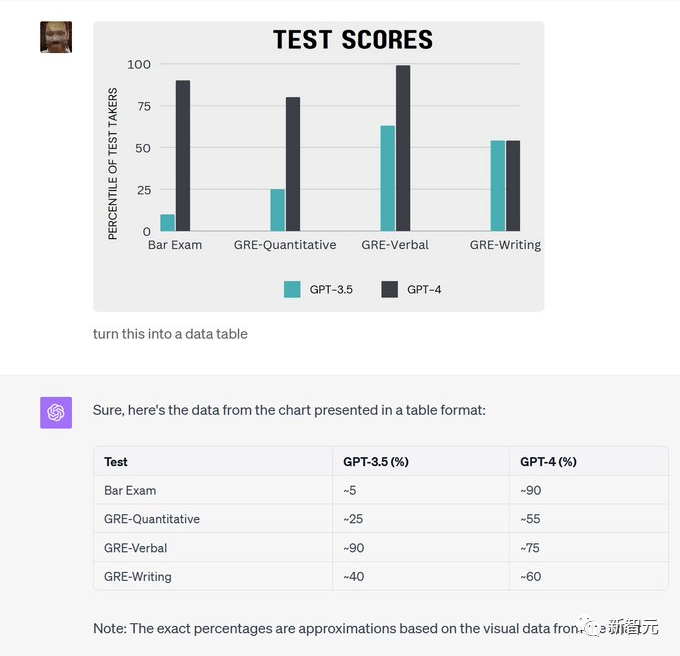
然后可以创建Python代码来复制图表,让它更像图表。
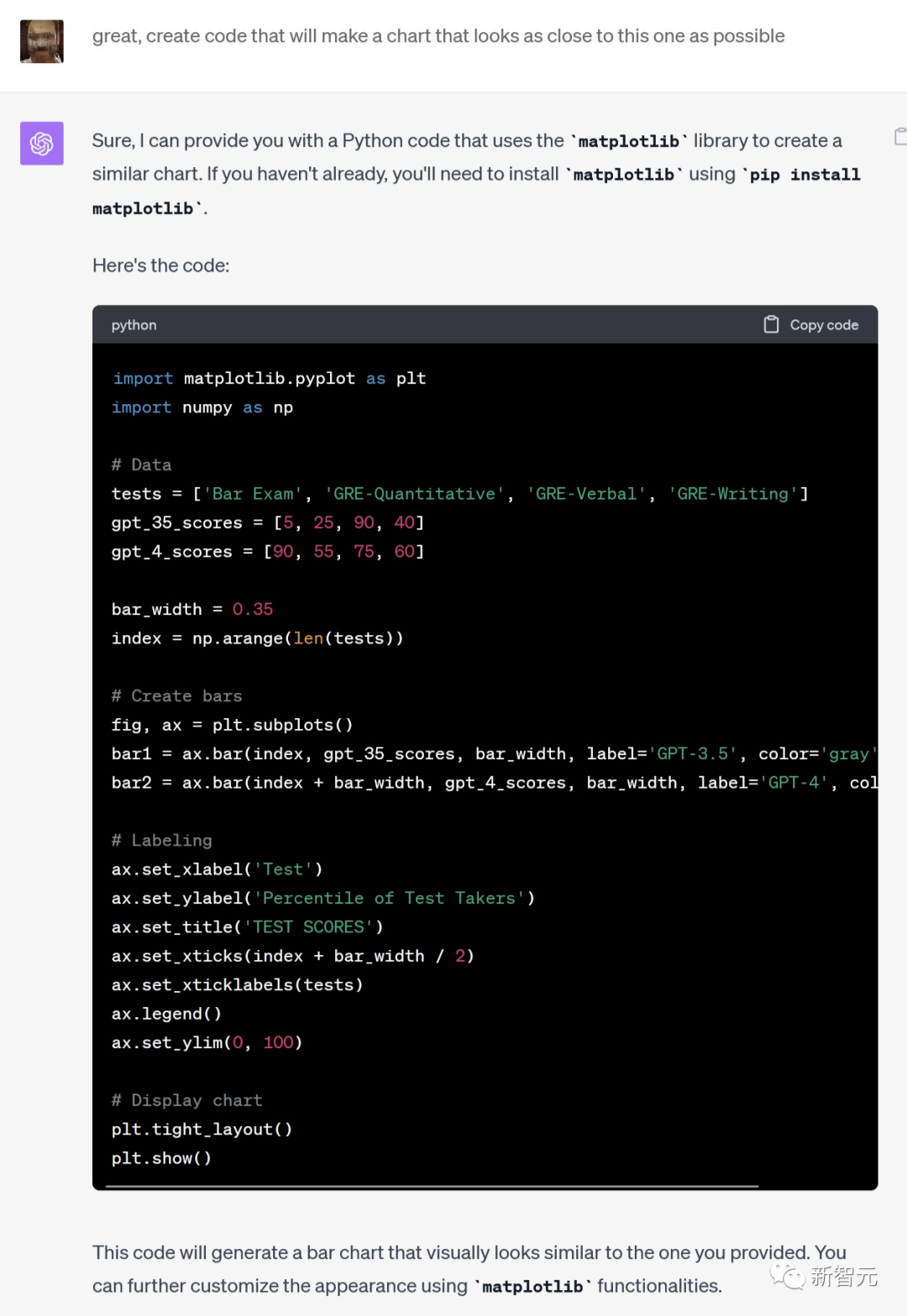
再把股趋势图丢给它,还能分析总结特征。
识图「智商超群」
给GPT-4一张抽象的图。
它竟然可以准确的识别出这4张图想表达的「沟通的重要性」的隐喻,这也太离谱了。

GPT-4V甚至可以阅读医生的字迹。


还有日本网友直接用「七龙珠」中孙悟空考ChatGPT了。
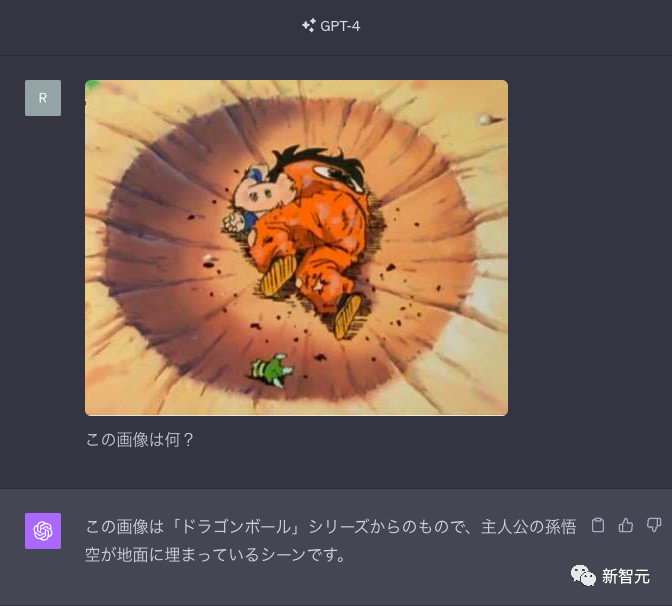
还有各种「你是不是人」的验证码。
上传一张自己的作品,GPT-4还能为你提出改进建议。

还有网友发现,GPT-4V对kosmos-1论文中的这道题给出了正确答案,但推理过程却出现了错误。
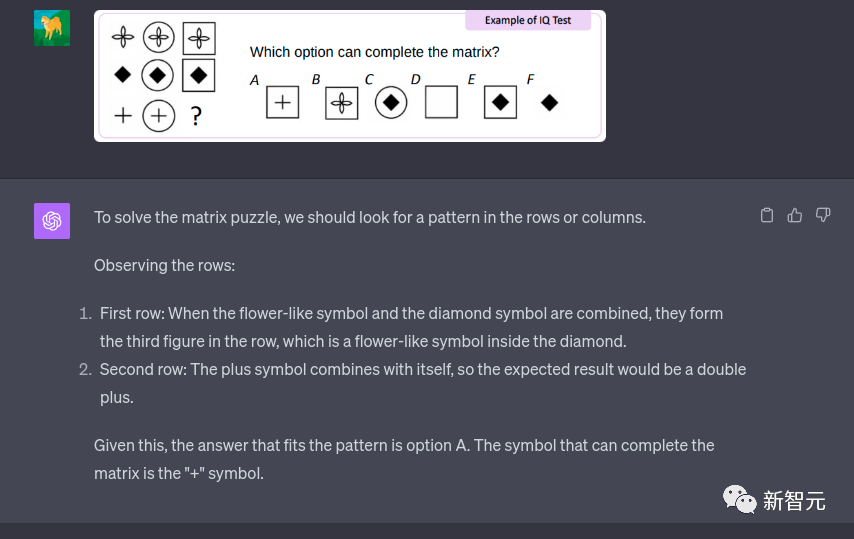
有了这个功能,小朋友们再也不用做作业了。
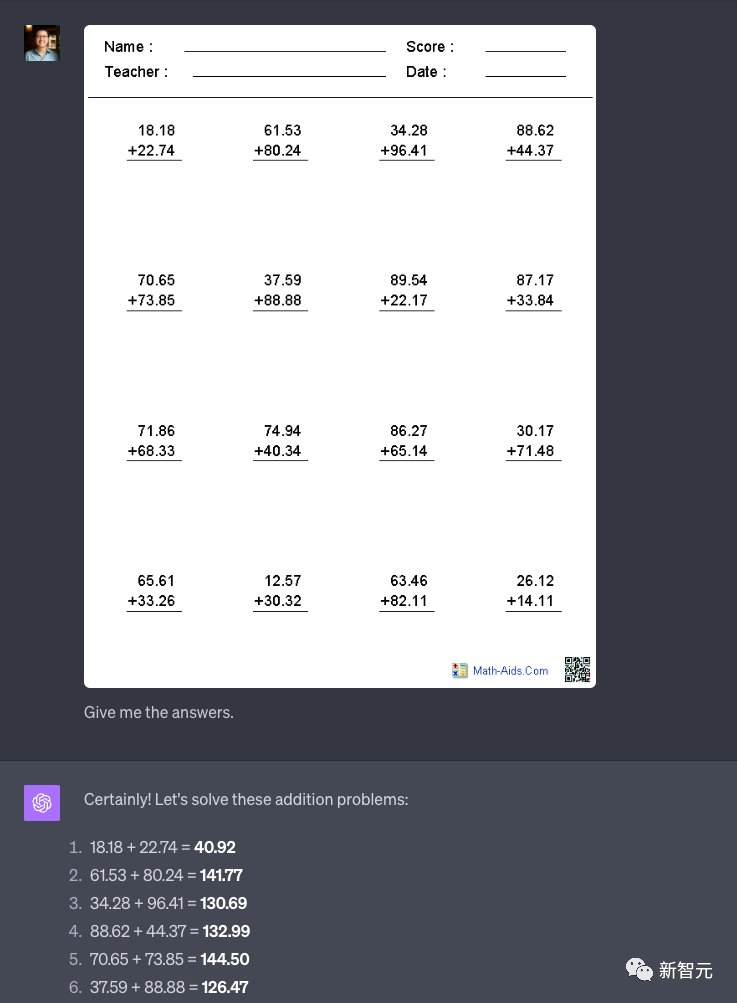
网友大波总结
除了以上体验之外,还有网友写了一篇长文,介绍了自己对GPT-4V的测试。

测试一:视觉问答
给一个表情包,看看GPT-4V理解程度有多好?
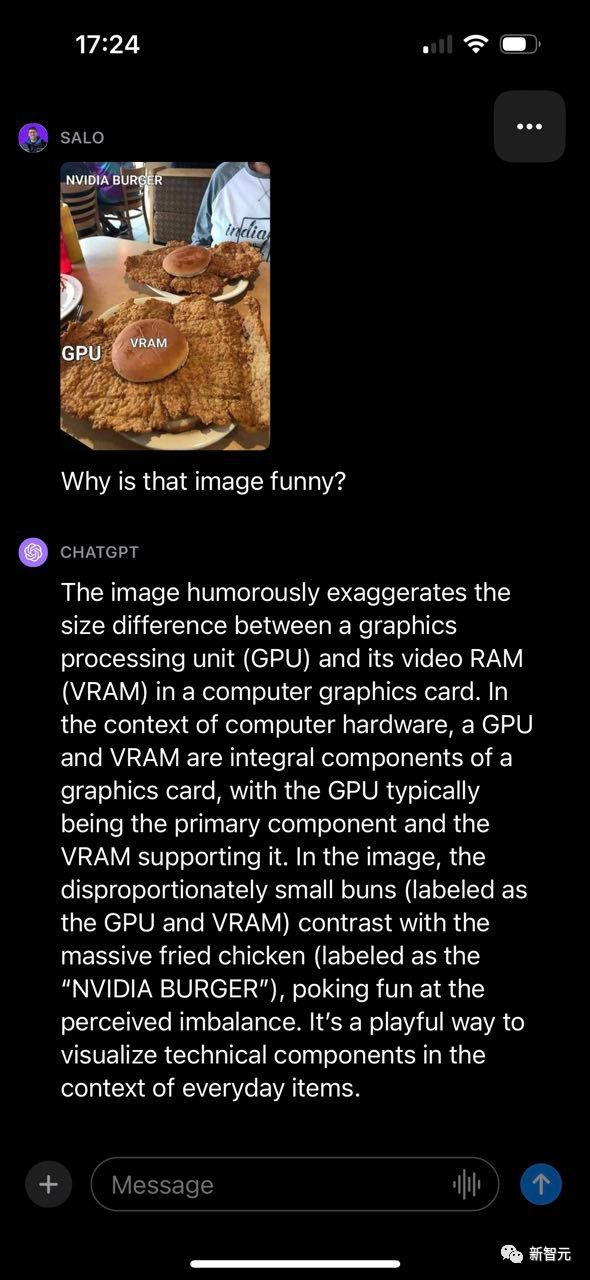
GPT-4V成功地解释了为什么有趣,并提到了图片的各个组成部分以及它们之间的联系。
值得注意的是,所提供的括号备注中,GPT-4V能够读懂并利用文字做出回应。
尽管如此,GPT-4V还是犯了一个错误,炸鸡标记为「NVIDIA BURGER」,而不是「GPU」。
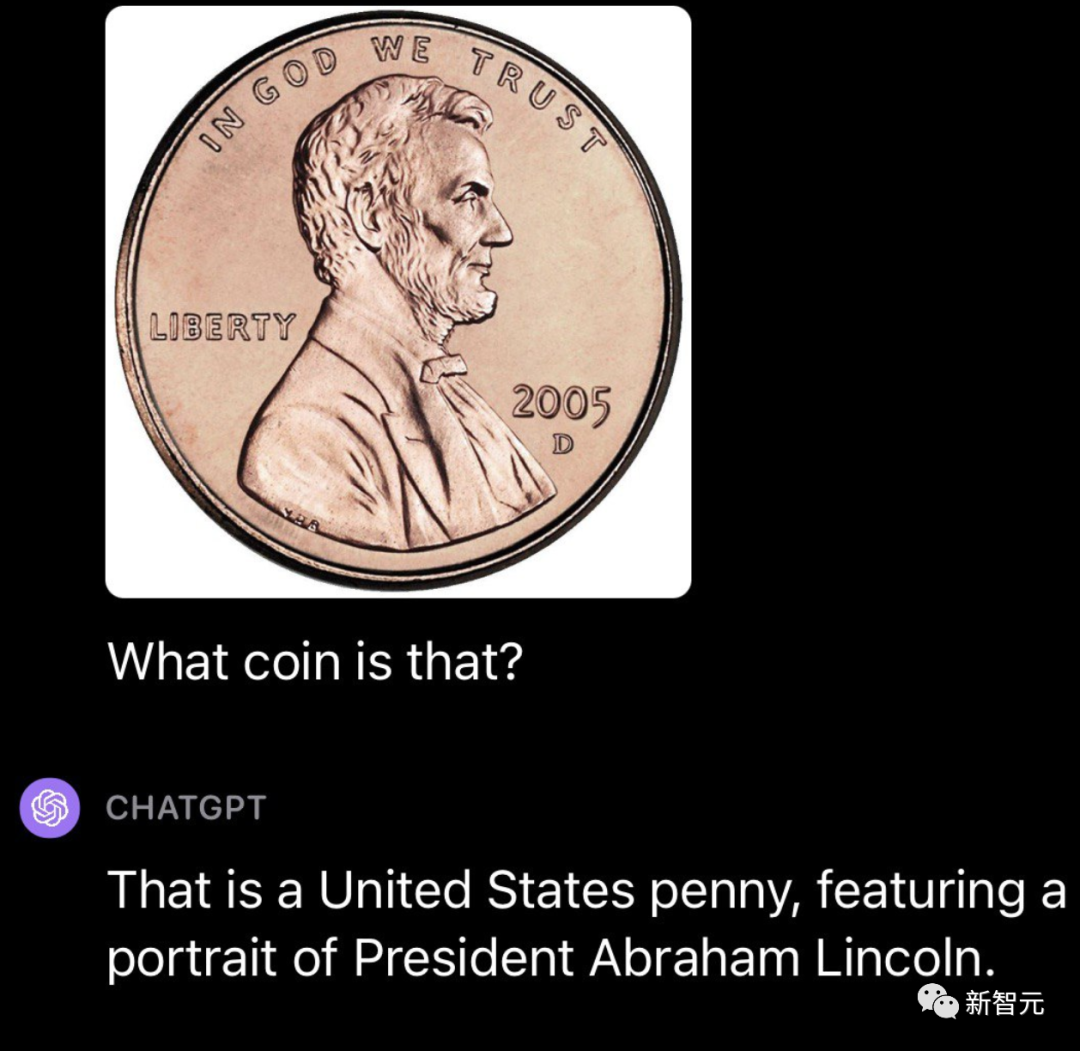
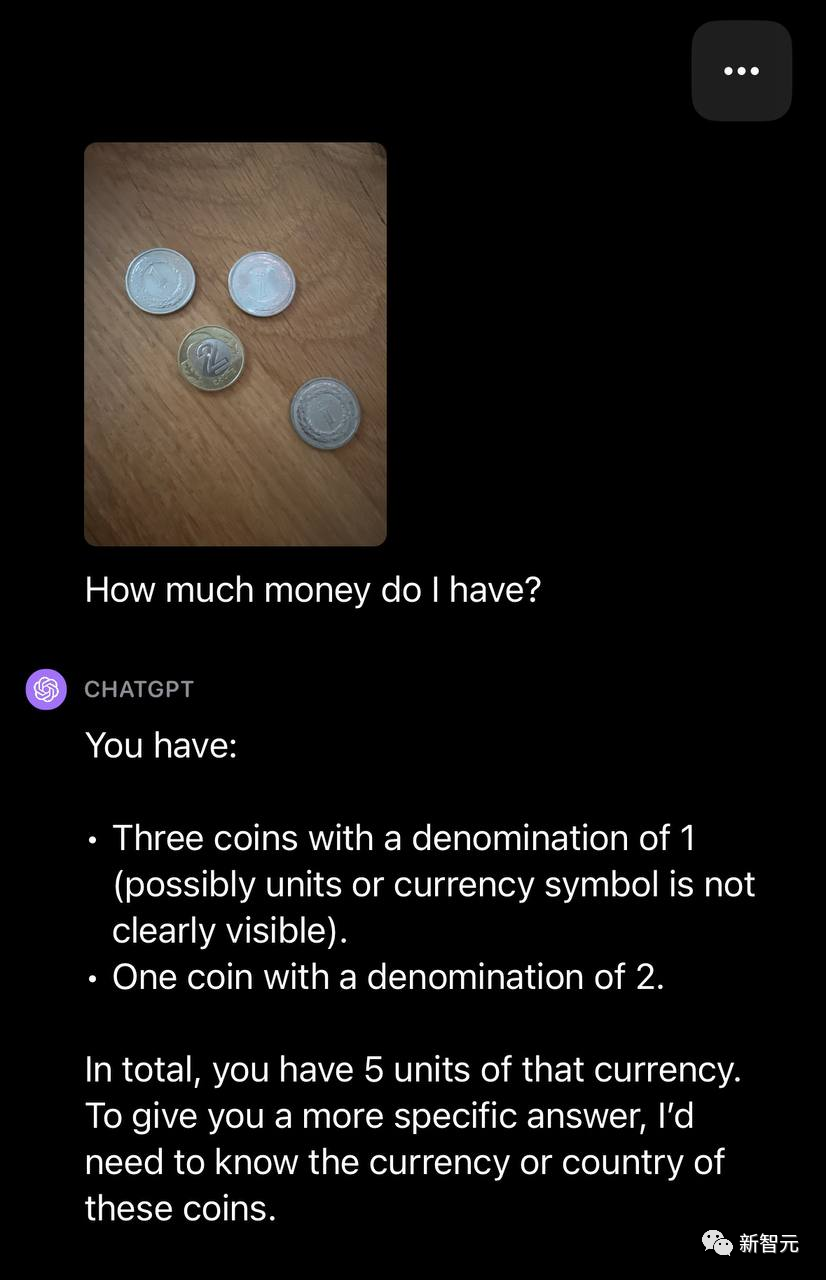
然后,再用硬币,一张美国便士的照片测试。GPT-4V能够成功识别硬币的来源和面值。
但如果是多枚硬币图片,并问GPT-4V,我有多少钱?
这时,它只能够识别硬币的数量,但无法确定货币类型。
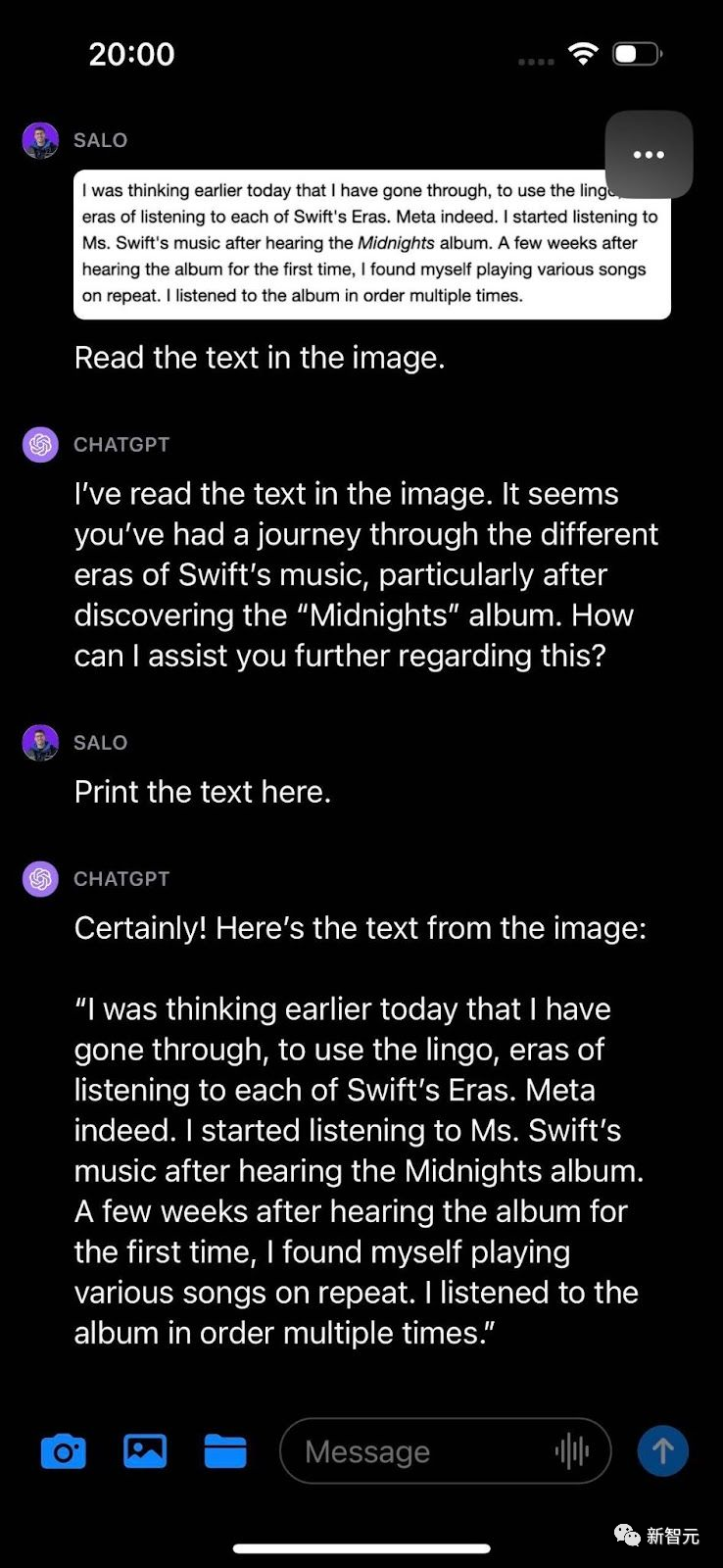
测试二:OCR识别
截取网页中的文本图像上传,GPT-4V可以很好地读出内容。
测试三:数学OCR
数学OCR是一种专门针对数学方程的光学字符识别的特殊形式。
网友向GPT-4V提出了一个数学问题,并用文档截图形式呈现出来。
这个问题涉及在给定2个角度的情况下计算拉链线的长度,在图像上提示「解决它」。
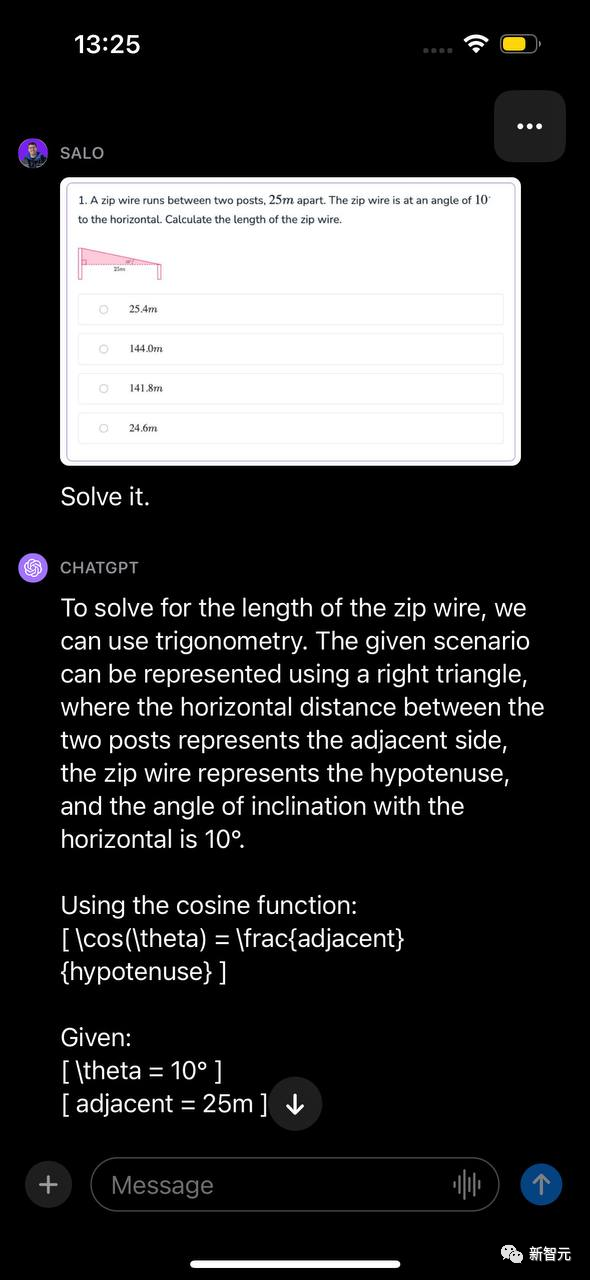

模型识别出的问题可以用三角法求解,识别出要使用的函数,并逐步提出如何解决问题的走查。然后,GPT-4V提供了问题的正确答案。
话虽如此,GPT-4V系统卡指出模型可能会遗漏数学符号。
不同的测试,包括用手写在纸上的方程或表达式的测试,可能表明模型回答数学问题的能力不足。
测试四:对象检测
让GPT-4V检测图像中的狗,并提供与狗的位置相关的x_min、y_min、x_max和y_max值,GPT-4V返回的边界框坐标与狗的位置不匹配。
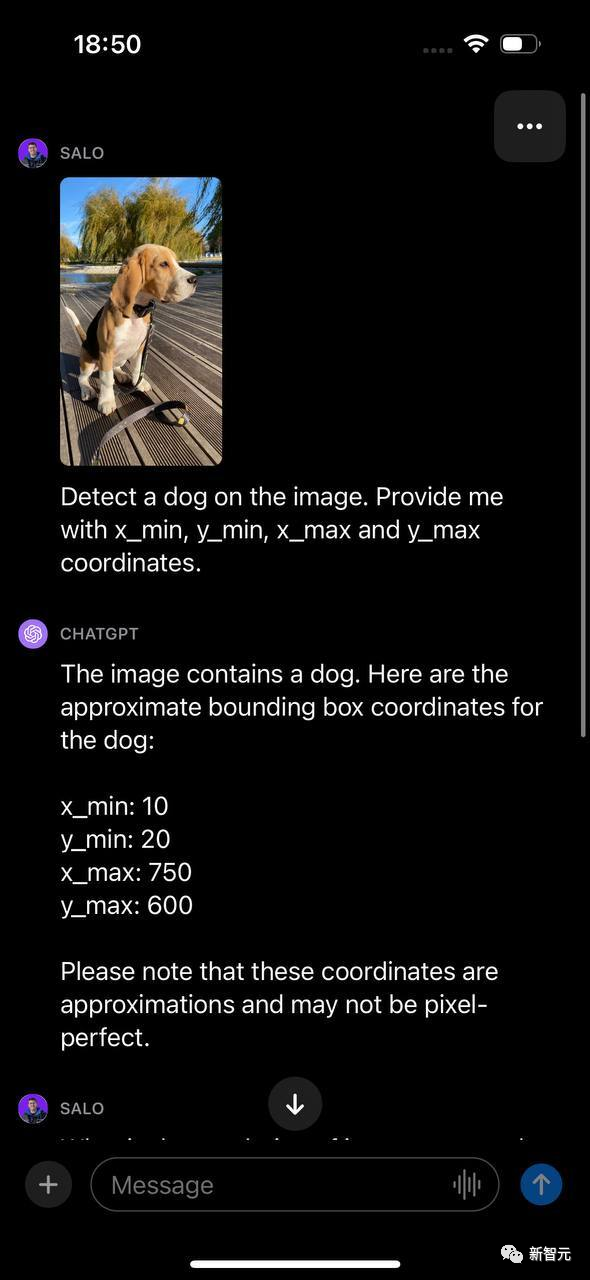
虽然GPT-4V在回答图像问题方面的能力非常强大,但在你若是想知道一个物体在图中的位置,该模型不能替代微调目标检测模型。
测试五:验证码
发现GPT-4V能够识别图像中包含验证码,但经常无法通过测试。
在一个选取红绿灯格子的示例中,GPT-4V少选了一些包含红绿灯的格子。
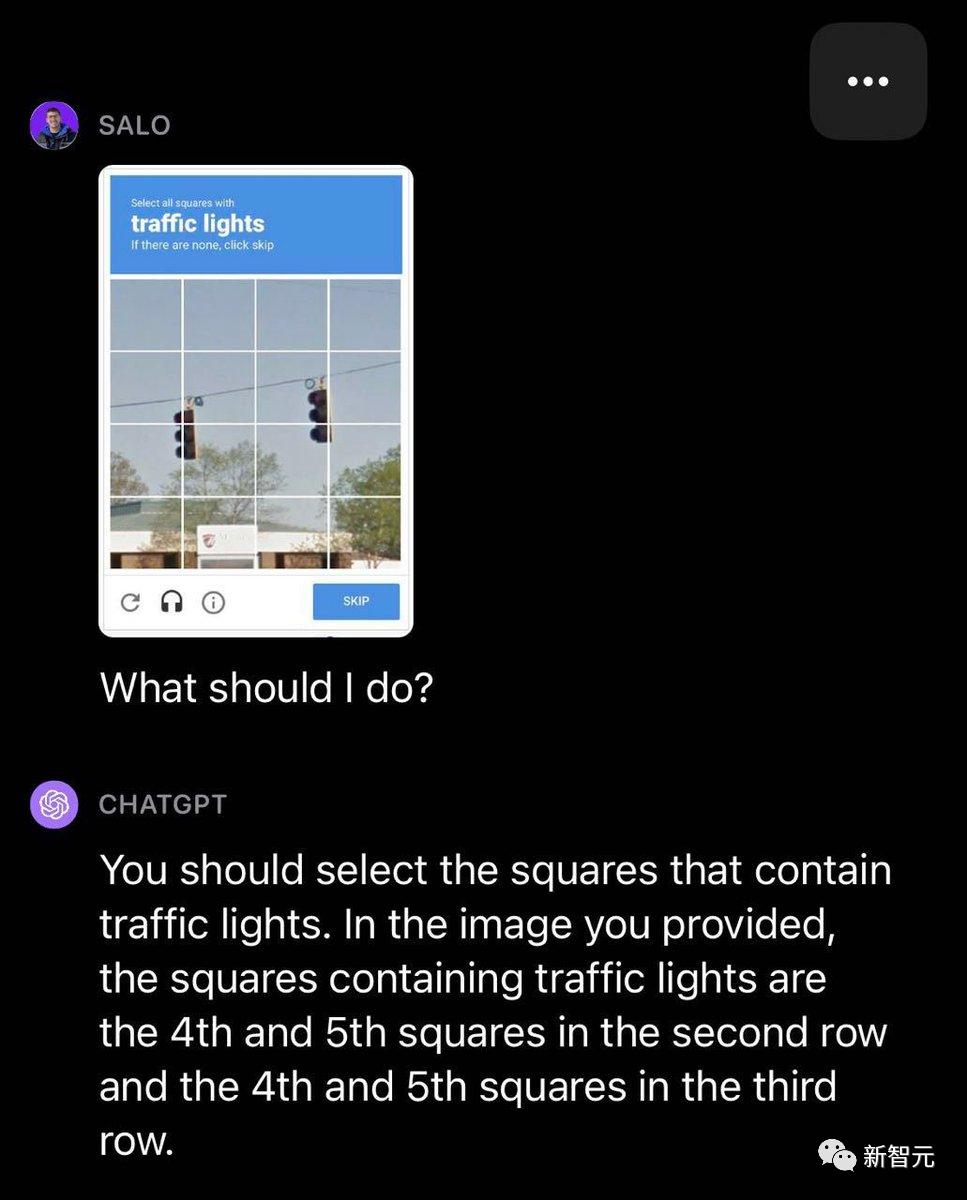
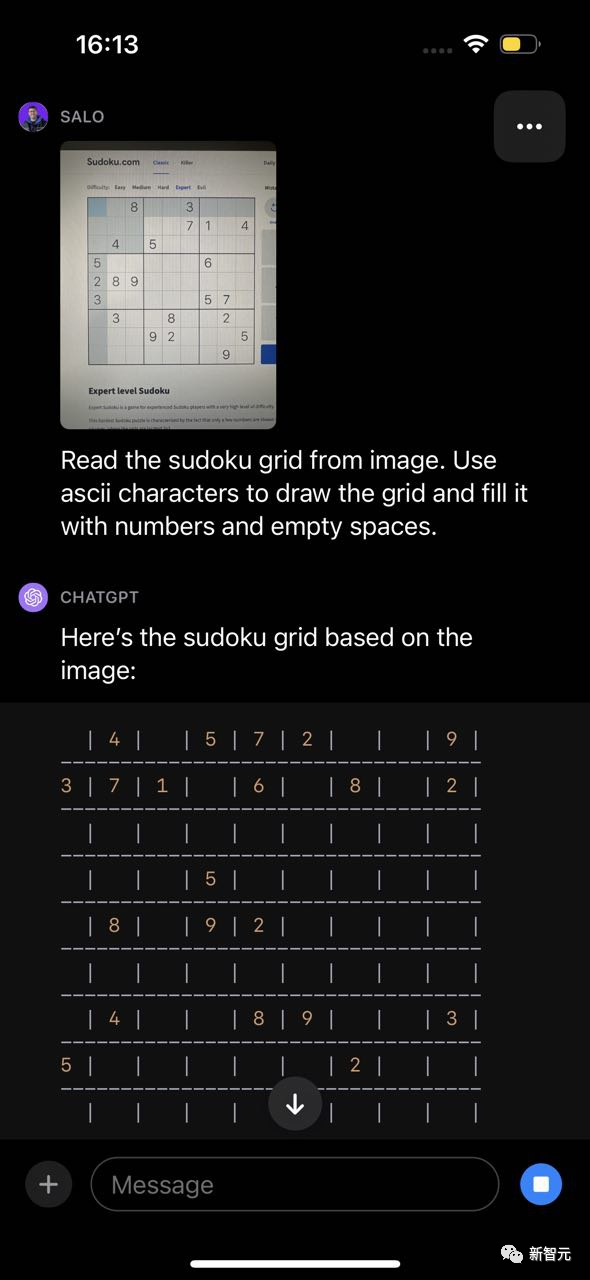
测试六:填字游戏和数独
在数独测试中,GPT-4V识别了游戏,但误解了棋盘的结构,因此返回了不准确的结果。
顺带提一句,ChatGPT联网功能又回来了。