TCP 协议的核心概念
要了解服务器的工作原理首先需要了解 TCP 协议的工作原理。TCP 是一种面向连接的、可靠的、基于字节流的传输层全双工通信协议,它有 4 个特点:面向连接、可靠、流式、全双工。下面详细讲解这些特性。
面向连接
TCP 中的连接是一个虚拟的连接,本质上是主机在内存里记录了对端的信息,我们可以将连接理解为一个通信的凭证。如下图所示。

那么如何建立连接呢?TCP 的连接是通过三次握手建立的。
服务器首先需要监听一个端口。
客户端主动往服务器监听的端口发起一个 syn 包(第一次握手)。
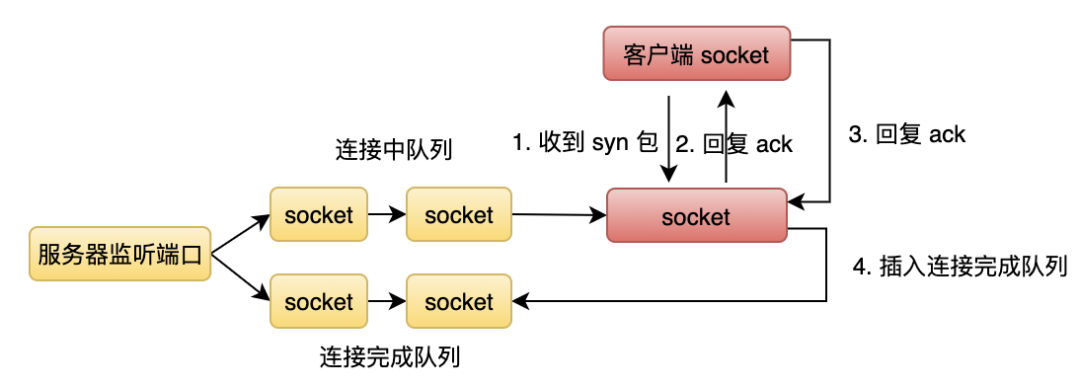
当服务器所在操作系统收到一个 syn 包时,会先根据 syn 包里的目的 IP 和端口找到对应的监听 socket,如果找不到则回复 rst 包,如果找到则发送 ack 给客户端(第二次握手),接着新建一个通信 socket 并插入到监听 socket 的连接中队列(具体的细节会随着不同版本的操作系统而变化。比如连接中队列和连接完成队列是一条队列还是两条队列,再比如是否使用了 syn cookie 技术来防止 syn flood 攻击,如果使用了,收到 syn 包的时候就不会创建 socket,而是收到第三次握手的包时再创建)。
客户端收到服务器的 ack 后,再次发送 ack 给服务器,客户端就完成三次握手进入连接建立状态了。
当服务器所在操作系统收到客户端的 ack 时(第三次握手),处于连接中队列的 socket 就会被移到连接完成队列中。
当操作系统完成了一个 TCP 连接,操作系统就会通知相应的进程,进程从连接完成队列中摘下一个已完成连接的 socket 结点,然后生成一个新的 fd,后续就可以在该 fd 上和对端通信。具体的流程如下图所示。
完成三次握手后,客户端和服务器就可以进行数据通信了。操作系统收到数据包和收到 syn 包的流程不一样,操作系统会根据报文中的 IP 和端口找到处理该报文的通信 socket(而不是监听 socket),然后把数据包(操作系统实现中是一个 skb 结构体)挂到该通信 socket 的数据队列中。
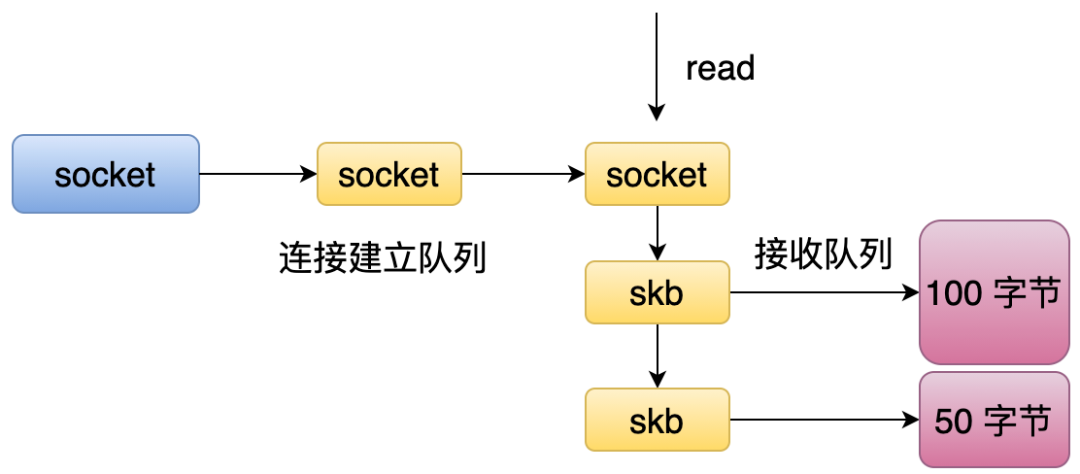
当应用层调用 read 读取该 socket 的数据时,操作系统会根据应用层所需大小,从一个或多个 skb 中返回对应的字节数。同样,写也是类似的流程,当应用层往 socket 写入数据时,操作系统不一定会立刻发送出去,而是会保存到写缓冲区中,然后根据复杂的 TCP 算法发送。
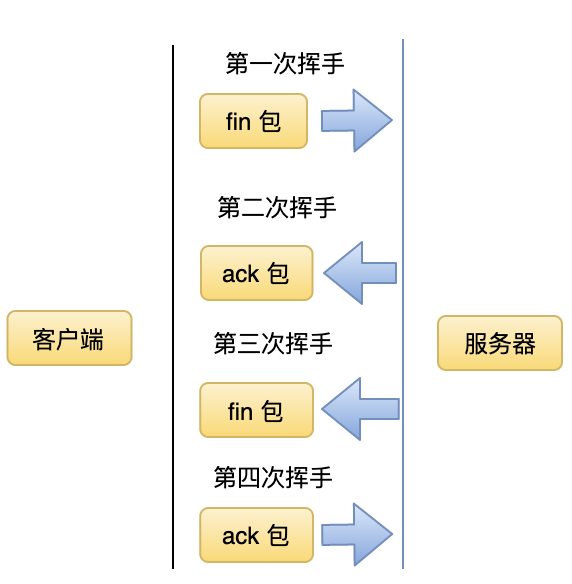
当两端完成通信后需要关闭连接,否则会浪费内存。TCP 通过四次挥手实现连接的断开,第一次挥手可以由任意一端发起。前面讲过 TCP 是全双工的,所以除了通过四次挥手完成整个 TCP 连接的断开外,也可以实现半断开,比如客户端关闭写端表示不会再发送数据,但是仍然可以读取来自对端发送端数据。四次挥手的流程如下。
可靠
TCP 发送数据时会先缓存一份到已发送待确认队列中,并启动一个超时重传计时器,如果一定时间内没有收到对端到确认 ack,则触发重传机制,直到收到 ack 或者重传次数达到阈值才会结束流程。
流式
建立连接后,应用层就可以调用发送接口源源不断地发送数据。通常情况下,并不是每次调用发送接口,操作系统就直接把数据发送出去,这些数据的发送是由操作系统按照一定的算法去发送的。对操作系统来说,它看到的是字节流,它会按照 TCP 算法打包出一个个包发送到对端,所以当对端收到数据后,需要处理好数据边界的问题。
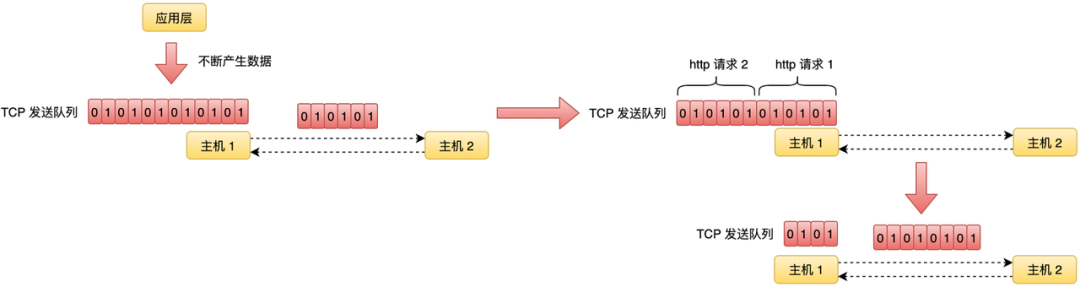
从上图中可以看到,假设应用层发送了两个 HTTP 请求,操作系统在打包数据发送时可能的场景是第一个包里包括了 HTTP 请求 1 的全部数据和部分请求 2 的数据,所以当对端收到数据并进行解析时,就需要根据 HTTP 协议准确地解析出第一个 HTTP 请求对应的数据。
因为 TCP 的流式协议,所以基于 TCP 的应用层通常需要定义一个应用层协议,然后按照应用层协议实现对应的解析器,这样才能完成有效的数据通信,比如常用的 HTTP 协议。对比来说 UDP 是面向数据包的协议,当应用层把数据传递给 UDP 时,操作系统会直接打包发送出去(如果数据字节大小超过阈值则会报错)。
全双工
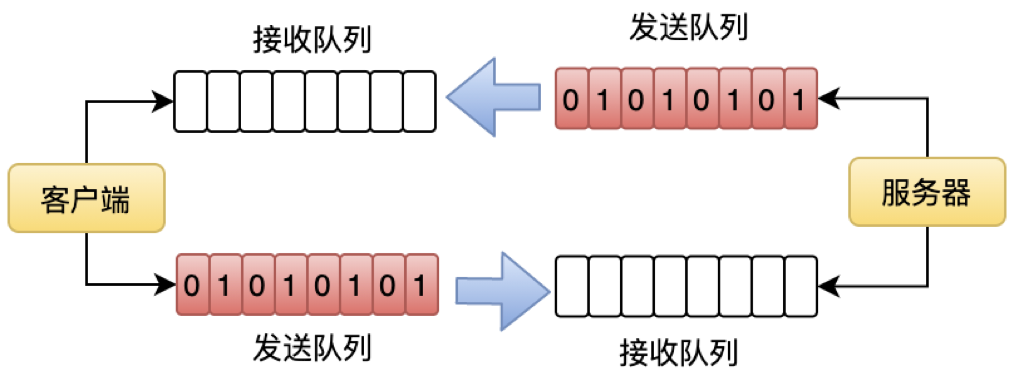
刚才提到 TCP 是全双工的,全双工就是通信的两端都有一个发送队列和接收队列,可以同时发送和接收,互不影响。另外也可以选择关闭读端或者写端。
服务器的工作原理
介绍了 TCP 协议的概念后,接着看看如何创建一个 TCP 服务器(伪代码)。
执行完以上步骤,一个服务器就启动了。服务器启动的时候会监听一个端口,如果有连接到来,我们可以通过 accept 系统调用拿到这个新连接对应的 socket,那这个 socket 和监听的 socket 是不是同一个呢?
其实 socket 分为监听型和通信型。表面上服务器用一个端口实现了多个连接,但是这个端口是用于监听的,底层用于和客户端通信的其实是另一个 socket。每当一个连接到来的时候,操作系统会根据请求包的目的地址信息找到对应的监听 socket,如果找不到就会回复 RST 包,如果找到就会生成一个新的 socket 与之通信(accept 的时候返回的那个)。监听 socket 里保存了监听的 IP 和端口,通信 socket 首先从监听 socket 中复制 IP 和端口,然后把客户端的 IP 和端口也记录下来。这样一来,下次再收到一个数据包,操作系统就会根据四元组从 socket 池子里找到该 socket,完成数据的处理。因此理论上,一个服务器能接受多少连接取决于服务器的硬件配置,比如内存大小。
接下来分析各种处理连接的方式。
串行模式
串行模式就是服务器逐个处理连接,处理完前面的连接后才能继续处理后面的连接,逻辑如下。
上面的处理方式是最朴素的模型,如果没有连接,则服务器处于阻塞状态,如果有连接服务器就会不断地调用 accept 摘下完成三次握手的连接并处理。假设此时有 n 个请求到来,进程会从 accept 中被唤醒,然后拿到一个新的 socket 用于通信,结构图如下。

这种处理模式下,如果处理的过程中调用了阻塞 API,比如文件 IO,就会影响后面请求的处理,可想而知,效率是非常低的,而且,并发量比较大的时候,监听 socket 对应的队列很快就会被占满(已完成连接队列有一个最大长度),导致后面的连接无法完成。这是最简单的模式,虽然服务器的设计中肯定不会使用这种模式,但是它让我们了解了一个服务器处理请求的整体过程。
多进程模式
串行模式中,所有请求都在一个进程中排队被处理,效率非常低下。为了提高效率,我们可以把请求分给多个进程处理。因为在串行处理的模式中,如果有文件 IO 操作就会阻塞进程,继而阻塞后续请求的处理。在多进程的模式中,即使一个请求阻塞了进程,操作系统还可以调度其它进程继续执行新的任务。多进程模式分为几种。
按需 fork
按需 fork 模式是主进程监听端口,有连接到来时,主进程执行 accept 摘取连接,然后通过 fork 创建子进程处理连接,逻辑如下。
这种模式下,每次来一个请求,就会新建一个进程去处理,比串行模式稍微好了一点,每个请求都被独立处理。假设 a 请求阻塞在文件 IO,不会影响 b 请求的处理,尽可能地做到了并发。它的缺点是
1. 进程数有限,如果有大量的请求,需要排队处理。
2. 进程的开销会很大,对于系统来说是一个负担。
3. 创建进程需要时间,实时创建会增加处理请求的时间。
pre-fork 模式 + 主进程 accept
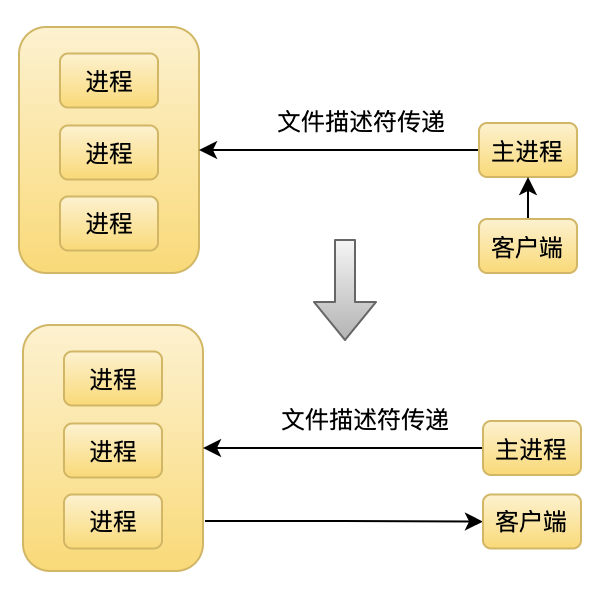
pre-fork 模式就是服务器启动的时候,预先创建一定数量的进程,但是这些进程是 worker 进程,不负责接收连接,只负责处理请求。处理过程为主进程负责接收连接,然后把接收到的连接交给 worker 进程处理,流程如下。
逻辑如下:
和 fork 模式相比,pre-fork 模式相对比较复杂,因为在前一种模式中,主进程收到一个请求就会实时 fork 一个子进程,这个子进程会继承主进程中新请求对应的 fd,可以直接处理该 fd 对应的请求。但是在进程池的模式中,子进程是预先创建的,当主进程收到一个请求的时候,子进程中无法拿得到该请求对应的 fd 。这时候就需要主进程使用传递文件描述符的技术把这个请求对应的 fd 传给子进程。
pre-fork 模式 + 子进程 accept
刚才介绍的模式中,是主进程接收连接,然后传递给子进程处理,这样主进程就会成为系统的瓶颈,它可能来不及接收和分发请求给子进程,而子进程却很空闲。子进程 accept 这种模式也是会预先创建多个进程,区别是多个子进程会调用 accept 共同处理请求,而不需要父进程参与,逻辑如下。
这种模式下多个子进程都阻塞在 accept,如果这时候有一个请求到来,那么所有的子进程都会被唤醒,但是先被调度的子进程会摘下这个请求节点,后续的进程被唤醒后可能会遇到已经没有请求可以处理,而又进入睡眠,这种进程被无效唤醒的现象就是著名的惊群现象。这种模式的处理流程如下。

Nginx 中解决了惊群这个问题,它的处理方式是在 accpet 之前先加锁,拿到锁的进程才进行 accept,这样就保证了只有一个进程会阻塞在 accept,不会引起惊群问题,但是新版操作系统已经在内核层面解决了这个问题,每次只会唤醒一个进程。
多线程模式
除了使用多进程外,也可以使用多线程技术处理连接,多线程模式和多进程模式类似,区别是在进程模式中,每个子进程都有自己的 task_struct,这就意味着在 fork 之后,每个进程负责维护自己的数据、资源。线程则不一样,线程共享进程的数据和资源,所以连接可以在多个线程中共享,不需要通过文件描述符传递的方式进行处理,比如如下架构。
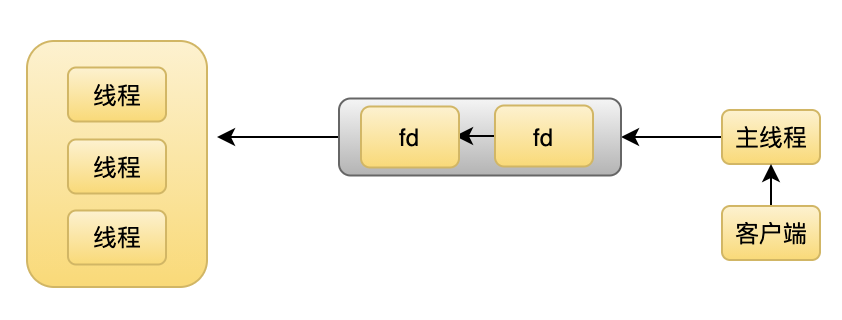
上图中,主线程负责 accept 请求,然后通过互斥的方式插入一个任务到共享队列中,线程池中的子线程同样是通过互斥的方式,从共享队列中摘取节点进行处理。
事件驱动
从之前的处理模式中我们知道,为了应对大量的请求,服务器通常需要大量的进程 / 线程,这是个非常大的开销。现在很多服务器(Nginx、Nodejs、Redis)都开始使用单进程 + 事件驱动模式去设计,这种模式可以在单个进程中轻松处理成千上万的请求。
但也正因为单进程模式下,再多的请求也只在一个进程里处理,这样一个任务会一直在占据 CPU,后续的任务就无法执行了。因此,事件驱动模式不适合 CPU 密集型的场景,更适合 IO 密集的场景(一般都会提供线程 / 线程池,负责处理 CPU 或者阻塞型的任务)。大部分操作系统都提供了事件驱动的 API,但是事件驱动在不同系统中实现不一样,所以一般都会有一层抽象层抹平这个差异。这里以 Linux 的 epoll 为例子。
事件驱动模式的处理流程为服务器注册文件描述符和事件到 epoll 中,然后 epoll 开始阻塞,当有事件触发时 epoll 就会返回哪些 fd 的哪些事件触发了,接着服务器遍历就绪事件并执行对应的回调,在回调里可以再次注册 / 删除事件,就这样不断驱动着进程的运行。epoll 的原理其实也类似事件驱动,它底层维护用户注册的事件和文件描述符,本身也会在文件描述符对应的文件 / socket / 管道处注册一个回调,等被通知有事件发生的时候,就会把 fd 和事件返回给用户,大致原理如下。
SO_REUSEPORT 端口复用
新版 Linux 支持 SO_REUSEPORT 特性后,使得服务器性能有了很大的提升。SO_REUSEPORT 之前,一个 socket 是无法绑定到同一个地址的,通常的做法是主进程接收连接然后传递给子进程处理,或者主进程 bind 后 fork 子进程,然后子进程执行 listen,但底层是共享同一个 socket,所以连接到来时所有子进程都会被唤醒,但是只有一个连接可以处理这个请求,其他的进程被无效唤醒。SO_REUSEPORT 特性支持多个子进程对应多个监听 socket,多个 socket 绑定到同一个地址,当连接到来时,操作系统会根据地址信息找到一组 socket,然后根据策略选择一个 socket 并唤醒阻塞在该 socket 的进程,被 socket 唤醒的进程处理自己的监听 socket 下的连接就行,架构如下。

除了前面介绍的模式外,还有基于协程的模式,服务器技术繁多,就不一一介绍了。
IO 模型
IO 模型是服务器中非常重要的部分,操作系统通常会提供了多种 IO 模型,常见的如下。
阻塞 IO
当线程执行一个 IO 操作时,如果不满足条件,当前线程会被阻塞,然后操作系统会调度其他线程执行。
非阻塞 IO
非阻塞 IO 在不满足条件的情况下直接返回一个错误码给线程,而不是阻塞线程。
那么这个阻塞是什么意思呢?直接看一段操作系统的代码。
通过这段代码,我们就可以非常明确地了解到阻塞和非阻塞到底是指什么。
多路复用 IO
在阻塞式 IO 中,我们需要通过阻塞进程来感知 IO 是否就绪,在非阻塞式 IO 中,我们需要通过轮询来感知 IO 是否就绪,这些都不是合适的方式。为了更好感知 IO 是否就绪,操作系统实现了订阅发布机制,我们只需要注册感兴趣的 fd 和事件,当事件发生时我们就可以感知到。多路复用 IO 可以同时订阅多个 fd 的多个事件,是现在高性能服务器的基石。看一个例子。
异步 IO
前面介绍的几种 IO 模型中,当 IO 就绪时需要自己执行读写操作,而异步 IO 是 IO 就绪时,操作系统帮助线程完成 IO 操作,然后再通知线程操作完成了。下面以 io_uring(Linux 中的异步 IO 框架) 为例了解下具体的情况。
上面的代码就是我们提交了一个读请求给操作系统,然后操作系统在文件可读并且读完成后通知我们。
Libuv 虽然写着是异步 IO 库,但是它并不是真正的异步 IO。它的意思是,你提交一个 IO 请求时,可以注册一个回调,然后就可以去做其他事情了,等操作完成后它会通知你,它的底层实现是线程池 + 多路复用 IO。
Node.js TCP 服务器的实现
Node.js 服务器的底层是 IO 多路复用 + 非阻塞 IO,所以可以轻松处理成千上万的请求,但是因为 Node.js 是单线程的,所以更适合处理 IO 密集型的任务。下面看看 Node.js 中服务器是如何实现的。
启动服务器
在 Node.js 中,我们通常使用以下方式创建一个服务器。
使用 net.createServer 可以创建一个服务器,然后拿到一个 Server 对象,接着调用 Server 对象的 listen 函数就可以启动一个 TCP 服务器了。下面来看一下具体的实现。
createServer 返回的是一个一般的 JS 对象,继续看一下 listen 函数的逻辑,listen 函数逻辑很繁琐,但是原理大致是一样的,所以只讲解常用的情况。
listen 处理了入参后,接着调用了 listenIncluster。
这里只分析在主进程创建服务器的情况,listenIncluster 中执行了 _listen2,_listen2 对应的函数是 setupListenHandle。
setupListenHandle 的逻辑如下。
1. 调用 new TCP 创建一个 handle(new TCP 对象关联了 C++ 层的 TCPWrap 对象)。
2. 保存处理连接的函数 onconnection,当有连接时被执行。
3. 调用了 bind 绑定地址到 socket。
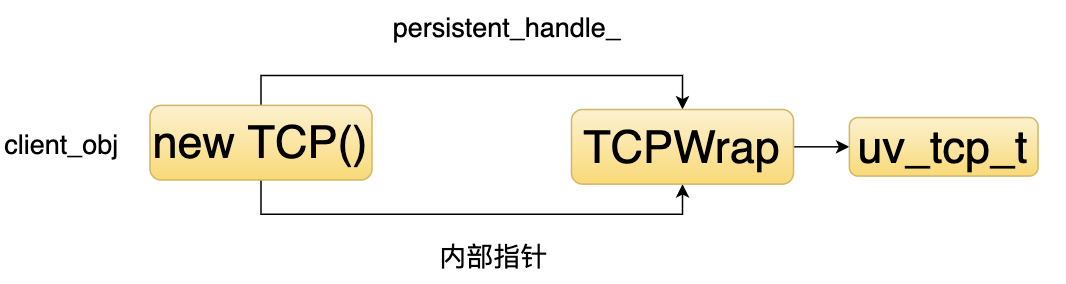
4. 调用 listen 函数修改 socket 状态为监听状态。首先看看 new TCP 做了什么。
new TCP 本质上是创建一个 TCP 层的 TCPWrap 对象,并初始化了 Libuv 的数据结构 uv_tcp_t(TCPWrap 是对 Libuv uv_tcp_t 的封装)。接着看 bind。
Bind 函数的逻辑很简单,直接调用了 Libuv 函数。
uv__tcp_bind 创建了一个 TCP socket 然后把地址信息保存到该 socket 中,执行 bind 绑定了地址信息后就继续调用 listen 把 socket 变成监听状态,C++ 层代码和 Bind 的差不多,就不再分析,直接看 Libuv 的代码。
uv_tcp_listen 首先调用了 listen 函数修改 socket 状态为监听状态,这样才能接收 TCP 连接,接着保存了 C++ 层的回调,并设置 Libuv 层的回调,最后注册可读事件等待 TCP 连接的到来。这里需要注意两个回调函数的执行顺序,当有 TCP 连接到来时 Libuv 会执行 uvserver_io,在 uvserver_io 里再执行 C++ 层的回调 cb。至此,服务器就启动了。其中 uv__io_start 最终会把服务器对应的文件描述符注册到 IO多路 复用模块中。
处理连接
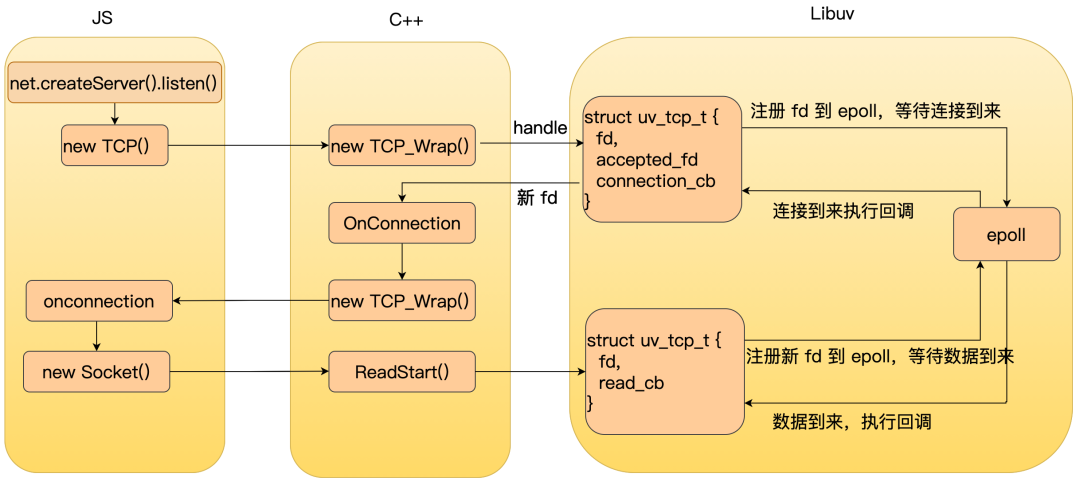
当有三次握手的连接完成时,操作系统会新建一个通信的 socket,并通知 Libuv,Libuv 会执行 uv__server_io。
uvserver_io 中通过 uvaccept 从操作系统中摘取一个完成连接的 TCP socket 并拿到一个 fd ,接着保存到 accepted_fd 中并执行 connection_cb 回调。
此外,我们需要注意 UV_HANDLE_TCP_SINGLE_ACCEPT 标记。因为可能有多个进程监听同一个端口,当多个连接到来时,多个进程可能会竞争处理这些连接(惊群问题)。这样一来,首先被调度的进程可能会直接处理所有的连接,导致负载不均衡。通过 UV_HANDLE_TCP_SINGLE_ACCEPT 标记,可以在通知进程接收连接时,每接收到一个后先睡眠一段时间,让其他进程也有机会接收连接,一定程度解决负载不均衡的问题,不过这个逻辑最近被去掉了,Libuv 维护者 bnoordhuis 的理由是,第二次调用 uvaccept 时有 99.9% 的概念会返回 EAGAIN,那就是没有更多的连接可以处理,这样额外调用 uvaccept 带来的系统调用开销是比较可观的。
接着看 connection_cb,connection_cb 对应的是 C++ 层的 OnConnection。
当建立了新连接时,操作系统会新建一个 socket。同样,在 Node.js 层,也会通过 Instantiate 函数新建一个对应的对象表示和客户端的通信。结构如下所示。
Instantiate 代码如下所示。
新建完和对端通信的对象后,接着调用 uv_accept 消费刚才保存在 accepted_fd 中的 fd,并把对应的 fd 保存到 C++ TCPWrap 对象的 uv_tcp_t 结构体中。
C++ 层拿到一个新的对象并且保存了 fd 到对象后,接着回调 JS 层的 onconnection。
在 JS 层也会封装一个 Socket 对象用于管理和客户端的通信,整体的关系如下。

接着触发 connection 事件,剩下的事情就是应用层处理了,整体流程如下。
Node.js HTTP 服务器的创建
接着看看 HTTP 服务器的实现。下面是 Node.js 中创建服务器的例子。
我们沿着 createServer 开始分析。
createServer 中创建了一个 Server 对象,来看看 Server 初始化的逻辑。
Server 中主要做了一些字段的初始化,并且监听了 connection 和 request 两个事件,当有连接到来时会触发 connection 事件,connection 事件的处理函数会调用 HTTP 解析器进行数据的解析,当解析出一个 HTTP 请求时就会触发 request 事件通知用户。
创建了 Server 对象后,接着我们调用它的 listen 函数。因为 HTTP Server 继承于 net.Server,所以执行 HTTP Server 的 listen 函数时,其实是执行了 net.Serve 的 listen 函数,net.Server 的 listen 函数前面已经分析过,就不再分析。当有请求到来时,会触发 connection 事件,从而执行 connectionListener。
上面的 connectionListenerInternal 函数中首先分配了一个 HTTP 解析器,HTTP 解析器由以下代码管理。
parsers 用于管理 HTTP 解析器,它负责分配 HTTP 解析器,并且在 HTTP 解析器不再使用时缓存起来给下次使用,而不是每次都创建一个新的解析器。分配完 HTTP 解析器后就开始等待 TCP 上数据的到来,即 HTTP 请求报文。但是这里有一个逻辑需要注意,上面代码中 Node.js 监听了 socket 的 data 事件,处理函数为 socketOnData,下面是 socketOnData 的逻辑。
socketOnData 调用 HTTP 解析器处理数据,这看起来没什么问题,但是有一个逻辑我们可能会忽略掉,看一下下面的代码。
上面代码中,如果 socket._handle.isStreamBase 为 true(TCP handle 的 isStreamBase 为 true),则会执行 parser.consume(socket._handle),这个是做什么的呢?
Consume 会注册 parser 会成为流的消费者,这个逻辑会覆盖掉刚才的 onData 函数,使得所有的数据直接由 parser 处理,看一下当数据到来时,parser 是如何处理的。
在 OnStreamRead 中会源源不断地把数据交给 HTTP 解析器处理并执行 kOnExecute 回调,并且在解析的过程中,会不断触发对应的钩子函数。比如解析到 HTTP 头部时执行 parserOnHeaders。
parserOnHeaders 会记录解析到的 HTTP 头,当解析完 HTTP 头 时会调用 parserOnHeadersComplete。
parserOnHeadersComplete 中创建了一个对象来表示收到的 HTTP 请求,接着执行 onIncoming 函数,对应的是 parserOnIncoming。
我们看到这里会触发 request 事件通知用户有新请求到来,并传入request和response作为参数,这样用户就可以处理请求了。另外 Node.js 本身是不会处理 HTTP 请求体的数据,当 Node.js 解析到请求体时会执行 kOnBody 钩子函数,对应的是 parserOnBody 函数。
parserOnBody 会把数据 push 到请求对象 request 中,接着 Node.js 会触发 data 事件,所以我们可以通过以下方式获取 body 的数据。
Node.js 的多进程服务器架构
虽然 Node.js 是单进程单线程的应用,但是我们可以创建多个进程来共同请求。在创建 HTTP 服务器时会调用 net 模块的 listen,然后调用 listenIncluster。我们从该函数开始分析。
listenIncluster 函数会调用子进程 cluster 模块的 _getServer 函数。
从上面代码中可以看到,_getServer 函数会给主进程发送一个 queryServer 的请求并设置了一个回调函数。看一下主进程是如何处理 queryServer 请求的。
queryServer 首先根据调度策略选择构造函数并创建一个对象,然后执行该对象的 add 方法并且传入一个回调。下面看看不同策略下的处理。
共享模式
首先看看共享模式的实现,共享模式对应前面分析的主进程管理子进程,多个子进程共同 accept 处理连接这种方式。
SharedHandle 是共享模式,即主进程创建好 handle,交给子进程处理,接着看它的 add 函数。
SharedHandle 的 add 把 SharedHandle 中创建的 handle 返回给子进程。接着看子进程拿到 handle 后的处理。
shared 函数把接收到的 handle 再回传到调用方,即 net 模块的 listenOnMasterHandle 函数,listenOnMasterHandle 会执行 listen 开始监听地址。
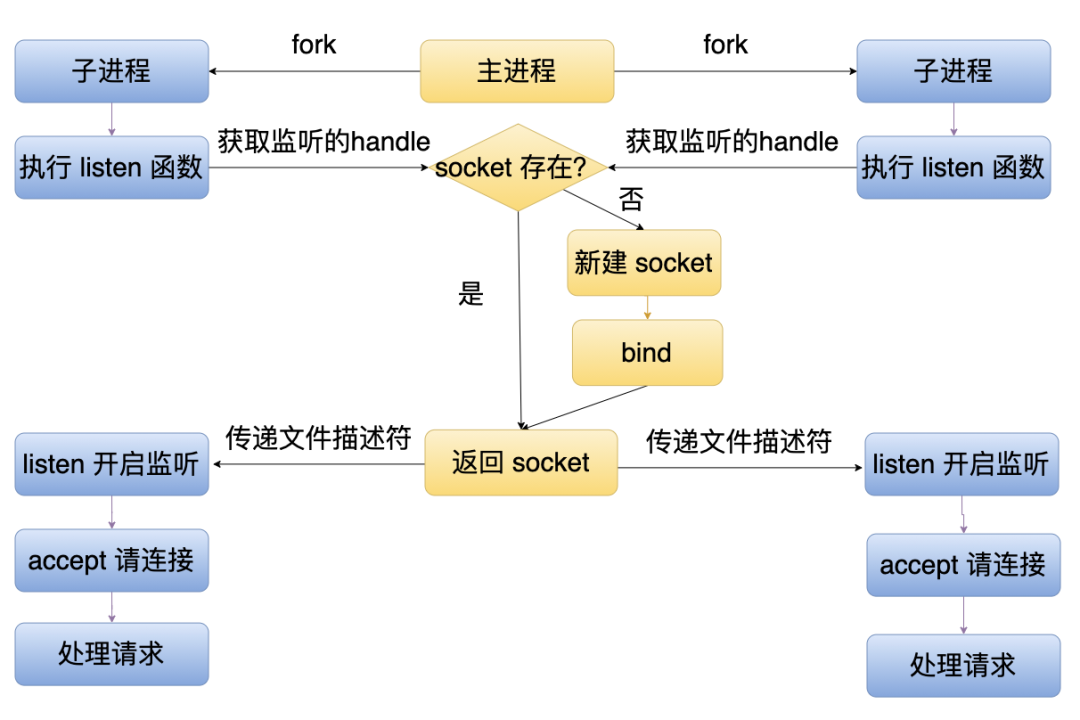
这样多个子进程就成功启动了服务器。共享模式的核心逻辑是主进程在 _createServerHandle 创建 handle 时执行 bind 绑定了地址(但没有 listen),然后通过文件描述符传递的方式传给子进程,子进程执行 listen 的时候就不会报端口已经被监听的错误了,因为端口被监听的错误是执行 bind 的时候返回的。逻辑如下图所示。
看一个共享模式的使用例子。
轮询模式
接着看轮询模式,轮询模式对应前面的主进程 accept,分发给多个子进程处理这种方式。
因为 RoundRobinHandle的 工作模式是主进程负责监听,收到连接后分发给子进程,所以 RoundRobinHandle 中直接启动了一个服务器,当收到连接时执行 this.distribute 进行分发。接着看一下RoundRobinHandle 的 add 函数。
RoundRobinHandle 会在 listen 成功后执行回调。我们回顾一下执行 add 函数时的回调。
回调函数会把 handle 等信息返回给子进程。但是在 RoundRobinHandle 和 SharedHandle 中返回的 handle 是不一样的,分别是 null 和 net.createServer 实例,因为前者不需要启动一个服务器,它只需要接收来自父进程传递的连接就行。
接着我们回到子进程的上下文,看子进程是如何处理的,刚才我们讲过,不同的调度策略,返回的 handle 是不一样的,我们看轮询模式下的处理。
round-robin 模式下,Node.js 会构造一个假的 handle 返回给 net 模块,因为调用方会调用 handle 的这些函数。当有请求到来时,round-bobin 模块会执行 distribute 分发连接给子进程。
可以看到 Node.js 没用按照严格的轮询,而是哪个进程接收连接快,就继续给它分发。接着看一下子进程是怎么处理该请求的。
最终执行 server.onconnection 进行连接的处理。逻辑如下图所示。
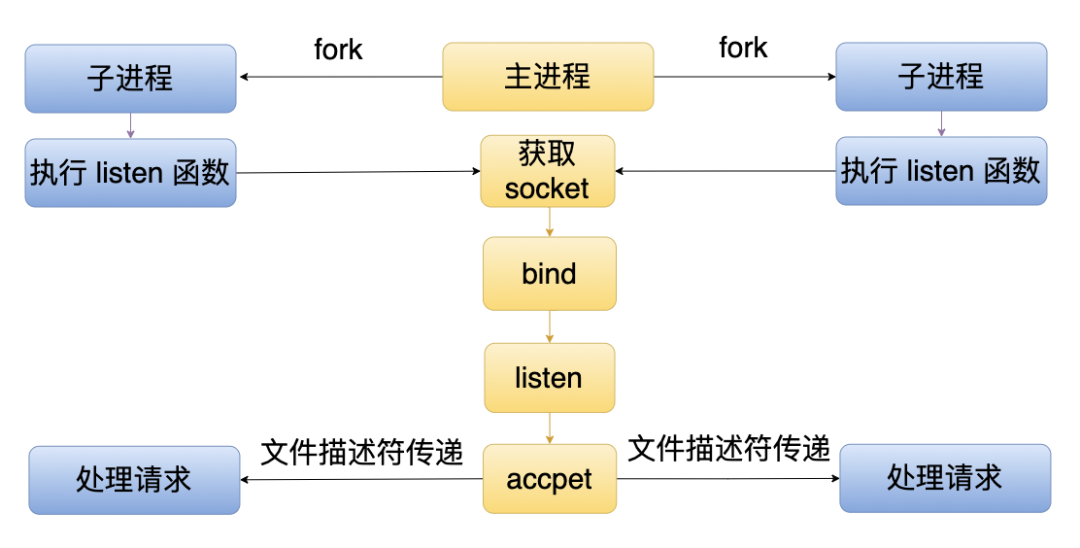
看一下轮询模式的使用例子。
实现一个高性能的服务器是非常复杂的,涉及到很多复杂的知识,但是即使不是服务器开发者,了解服务器相关的一些知识也是非常有用的。