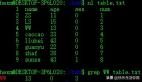
Grep作为Linux和Unix系统中的文本三剑客之一,提供了一种简单而强大的文本搜索和处理方法,能够满足各种文本操作需求,并且易于学习和使用。这使得它成为了命令行中不可或缺的工具之一,广泛应用于系统管理、软件开发和数据分析等领域。

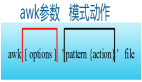
grep语法格式如下:
grep [选项] 模式 [文件...]
以下是一些 grep 的高级用法:
(1) 使用正则表达式:grep 可以与正则表达式一起使用,以进行更复杂的文本匹配。例如,查找所有以数字开头的行:
grep "^[0-9]" file.txt(2) 使用元字符:正则表达式中的元字符(如 *、+、?、.、[] 等)可以用于更灵活的匹配。例如,查找所有包含一个或多个字母的单词:
grep "[a-zA-Z]+" file.txt(3) 使用字符类:字符类可以用于匹配特定类型的字符,如数字、字母、空格等。例如,查找包含至少一个空格的行:
grep "[[:space:]]" file.txt(4) 查找整个单词:使用 -w 选项可以确保只匹配整个单词,而不是部分匹配。例如,查找包含单词 "apple" 的行:
grep -w "apple" file.txt(5) 反向匹配:使用 -v 选项可以查找不匹配模式的行。例如,查找不包含 "error" 的行:
grep -v "error" file.txt(6) 递归搜索目录:使用 -r 选项可以递归搜索目录中的文件。例如,递归搜索当前目录下所有文件中包含 "pattern" 的行:
grep -r "pattern" .(7) 显示匹配行数:使用 -n 选项可以显示匹配的行号。例如,查找包含 "search" 的行并显示行号:
grep -n "search" file.txt这些高级用法可以帮助你更灵活地使用 grep 来满足各种文本搜索和匹配需求。正则表达式是其中一个强大的功能,可以用于创建复杂的搜索模式。使用 grep 的不同选项和技巧,你可以根据具体的任务更精确地定位和提取文本数据。
总之,grep 是一个强大的文本搜索工具,可以帮助你在文件中查找所需的信息。当与 sed 和 awk 一起使用时,这些"三剑客"可以用于执行更复杂的文本处理和数据转换任务。