












数据分析不仅仅是冷冰冰的数字和统计结果,创造力在其中扮演着重要的角色。创造力能够为我们从数据集中提取最大化的价值。

以包含网站事件的表格为例,通过对用户ID、事件名称和时间戳等信息的分析,我们可以揭示出用户行为和趋势,进而实现诸如监测用户参与度、衡量用户增长、绘制客户旅程以及个性化用户体验等多种目标。接下来,我们深入探讨如何利用这些数据来回答关键问题,并展示数据背后的故事。
该表格由三列组成:
- user_id:显示触发事件的唯一用户
- event_name:指示触发的事件,例如查看、点击、注册、结账、购买等
- timestamp:记录事件发生的时间点

尽管数据有限,但可以用于多种目的,包括:
- 监测用户参与度
- 衡量用户增长
- 绘制客户旅程
- 个性化用户体验
具体而言,本文将演示如何使用这些数据回答以下问题:
- 整体用户会话和每个会话的事件趋势如何?
- 使用情况是由新用户还是回头用户推动的?
- 每周使用率增长率是多少?
1. 公共表达式和窗口函数
在开始之前,理解公共表达式(CTEs)和窗口函数的概念是有必要的。通过利用这些强大的功能,可以使用SQL进行更高级的分析。
CTE是一个命名的临时结果集,可以在同一查询中引用它,就像引用其他任何表一样。这有助于将复杂查询分解为较小、逻辑上的步骤。它们还可以通过减少复杂连接的需求并允许数据库引擎缓存中间结果来提高查询性能。
以下是一个简单的CTE示例,计算每个用户的网站访问次数。主查询引用了user_visits CTE来进行进一步的聚合,这次是计算返回用户的数量。
WITH user_visits AS (
SELECT user_id, COUNT(DISTINCT visit_date) AS num_visits
FROM my_table
GROUP BY user_id
)
SELECT COUNT(*) AS num_returning_users
FROM user_visits
WHERE num_visits > 1;窗口函数非常适用于执行复杂任务,例如移动平均值和滚动总和。它们通过根据一个或多个列(例如日期或user_id)将数据分组为多个子集,并独立地对每个子集执行计算来实现这一目的。
窗口函数(如LAG、LEAD、RANK和ROW_NUMBER())还需要指定数据分区的顺序。下面的窗口函数使用LAG来计算当前行与前一行之间的时间差(以秒为单位)。
SELECT
user_id,
event_name,
timestamp,
TIMESTAMPDIFF(SECOND, LAG(timestamp) OVER (PARTITION BY user_id ORDER BY timestamp), timestamp) AS time_diff
FROM my_table;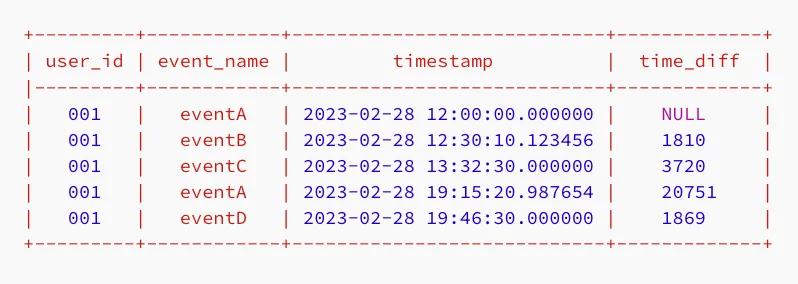
2. 监测用户参与度
企业使用参与度指标来了解用户如何与其产品和/或服务进行交互。例如,每位用户的会话数增加可能是用户满意度的积极指标。这些指标还可以洞察不同营销渠道的效果,比如从一个渠道获得的用户是否比其他渠道更活跃。
为了回答关于会话和每个会话的事件的问题,将在原始数据集中添加一个新的列。该列将显示特定用户的会话编号。
下面的查询首先使用名为sessions的CTE创建了一个名为new_session的列。使用LAG窗口函数,新会话被定义为行(事件)之间超过30分钟的差异。这个新列包含布尔值,其中1表示新会话的开始,0表示现有会话的延续。
然后,session_ids CTE使用SUM窗口函数为每个事件分配session_id,通过对每个用户的new_session值求和。
请注意,窗口函数放置在CASE语句内部。这是因为LAG需要从先前的行中检索数据。如果没有先前的行,这在由用户触发的第一个事件中是这种情况,将返回NULL值。使用CASE WHEN,NULL将被替换为值1。
WITH sessions AS (
SELECT user_id, event_name, timestamp,
CASE
-- 第一个事件总是开始一个新会话
WHEN LAG(timestamp, 1) OVER (PARTITION BY user_id ORDER BY timestamp) IS NULL THEN 1
-- 检查事件之间是否超过30分钟
WHEN timestamp - LAG(timestamp, 1) OVER (PARTITION BY user_id ORDER BY timestamp) >= INTERVAL '30 minutes' THEN 1
-- 否则,继续当前会话
ELSE 0
END AS new_session
FROM my_table
), session_ids AS (
SELECT user_id, event_name, timestamp, SUM(new_session) OVER (PARTITION BY user_id ORDER BY timestamp) AS user_session_id
FROM sessions
)
SELECT user_id, event_name, timestamp, new_session, session_id
FROM session_ids
ORDER BY user_id, timestamp;最终查询在SELECT语句中包含了new_session和user_session_id,你可以在下面看到它们作为新列:
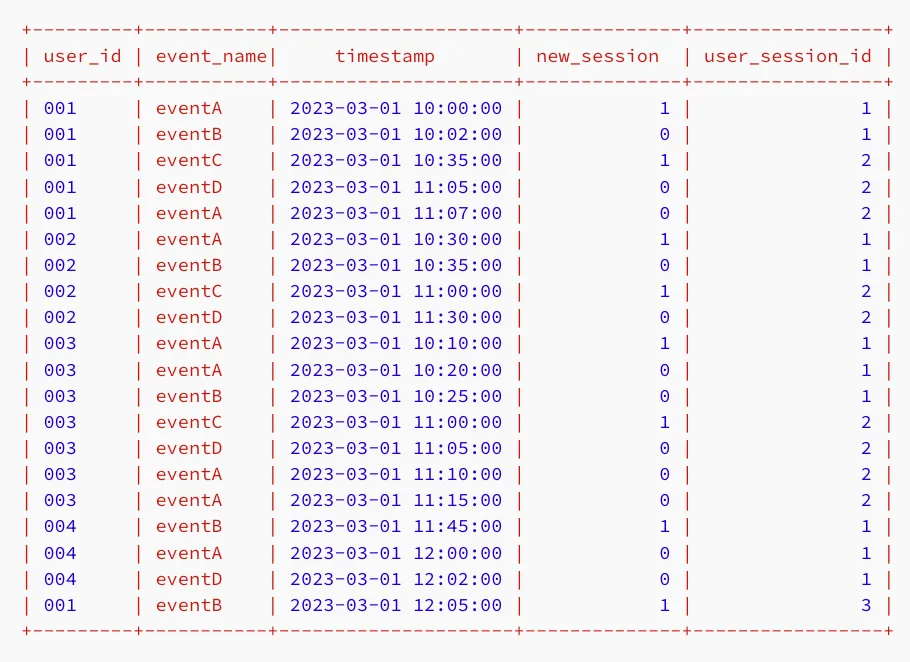
通过这个表,现在可以计算每日总会话数。首先,我们需要创建一个新的global_session_id,它将以全局而不是用户的级别区分会话。
这可以通过使用CONCAT(user_id, '-', session_id)来组合user_id和user_session_id来完成。例如,将user_id 001和user_session_id 1组合的结果将是一个新的全局session_id,即001-1。最后,通过按DATE(timestamp)分组计算不同的global_session_id的计数,可以得到每日会话的视图。
SELECT
DATE(timestamp) AS date,
-- 将user_id和user_session_id连接起来,创建一个全局会话id
COUNT(DISTINCT CONCAT(user_id, '-', user_session_id)) AS unique_sessions
FROM
my_table
GROUP BY
DATE(timestamp)利用global_session_id,我们还可以计算每个会话的事件数。在下面的查询中,user_actions CTE按global_session_id和date分组事件,然后计算唯一事件的timestamps。这样就可以得到每个日期上每个会话的事件数。
在主查询中,我们计算不同的global_session_id的数量,从而得到每日会话的总数。然后,我们SUM(session_event_count),得到每日事件的总数,然后将其除以每日会话数,得到每个会话的平均事件数。按日期分组可以得到每天每个会话的平均事件数。
WITH user_actions AS (
SELECT
CONCAT(user_id, '-', user_session_id) AS global_session_id,
DATE(timestamp) AS date,
-- 计算每个会话和日期的唯一事件数
COUNT(DISTINCT timestamp) AS session_event_count
FROM
my_table
GROUP BY
CONCAT(user_id, '-', user_session_id), DATE(timestamp)
)
SELECT
date,
-- 通过计算不同的global_session_id的数量来计算总会话数
COUNT(DISTINCT global_session_id) AS sessions,
-- 求和所有会话中的事件数
SUM(session_event_count) AS total_events,
-- 将总事件数除以总会话数
SUM(session_event_count) / COUNT(DISTINCT global_session_id) AS avg_events_per_session
FROM
user_actions
GROUP BY
date;3. 测量保留和增长
在高使用率的情况下,如果由新用户推动,可能会掩盖用户流失的问题。因此,留存率是了解用户参与度的另一个重要指标。通过分析user_session_id列,我们可以确定新用户和老用户的比例。
下面创建了两个CTE来将计算分解为连续的部分。第一个CTE计算每日唯一用户总数。第二个CTE计算每日唯一回头用户总数,使用user_session_id > 1来识别回头用户。
然后,将这些CTE使用日期列进行连接,然后计算返回比率,即每日回头用户除以每日总用户数。
WITH all_users AS (
-- 计算每日所有用户数
SELECT
COUNT(DISTINCT users_id) AS total_users,
DATE(timestamp) AS date
FROM
my_table
GROUP BY
date),
returning_users AS (
-- 计算每日回头用户数
SELECT
COUNT(DISTINCT users_id) AS returning_users,
DATE(timestamp) AS date
FROM
my_table
WHERE user_session_id > 1
GROUP BY
date)
SELECT
-- 连接CTE并将回头用户除以总用户数
all_users.date,
total_users,
returning_users,
ROUND((returning_users / all_users), 2) AS returning_ratio
FROM all_users
LEFT JOIN returning_users ON returning_users.date = all_users.date除了衡量现有用户的保留情况外,增长率对于提供用户漏斗的更广泛图景也很有用。下面的查询计算了每周的增长率,这对于评估短期营销活动是合适的,尽管相同的计算也可以在较长的时间段内进行。
首先,我们使用DATE_TRUNC函数将timestamp值提取为周的起始日期,时间间隔设置为week。接下来,我们计算DISTINCT user_id的数量,其中user_session_id = 1,表示这是用户的第一次会话。这为我们提供了weekly_new_users,我们可以在窗口函数中使用它来计算累积用户获取。这里非常关键的是,对该窗口函数按week_start进行排序,并设置范围为UNBOUNDED PRECEDING AND CURRENT ROW,这将对当前周和之前所有周的weekly_new_users值进行求和。
最后,我们通过将当前累积用户减去先前累积用户,并将结果除以先前累积用户来计算每周的增长率。
WITH weekly_new_users AS (
-- 计算每周的新用户数
SELECT
DATE_TRUNC('week', timestamp) AS week_start,
COUNT(DISTINCT user_id) AS weekly_new_users
FROM
my_table
WHERE user_session_id = 1
GROUP BY
DATE_TRUNC('week', timestamp),
weekly_cumulative AS (
-- 对每周新用户数进行累加
SELECT
week_start,
sum(weekly_new_users) OVER (ORDER BY week_start RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_users
FROM
weekly_new_users
)
-- 使用累积用户计算每周增长率
SELECT
DATE(week_start) AS week_start,
cum_users,
ROUND(((cum_users - LAG(cum_users) OVER (ORDER BY week_start))/LAG(cum_users) OVER (ORDER BY week_start)) * 100, 2) AS weekly_growth_rate,
FROM
weekly_cumulative4. 结论
虽然具体指标的相关性取决于业务模型、行业和增长阶段,但上述示例清楚地展示了SQL在提供业务洞察方面的强大和多功能性。通过将这些工具与创造性思维相结合,即使是基本的数据集也能够为各种利益相关者提供价值。














