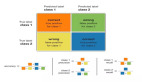
数据不平衡是机器学习中一个常见的挑战,其中一个类的数量明显超过其他类,这可能导致有偏见的模型和较差的泛化。有各种Python库来帮助有效地处理不平衡数据。在本文中,我们将介绍用于处理机器学习中不平衡数据的十大Python库,并为每个库提供代码片段和解释。

1、imbalanced-learn
imbalanced-learn是scikit-learn的扩展,提供了各种重新平衡数据集的技术。它提供过采样、欠采样和组合方法。
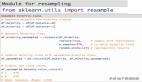
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler()
X_resampled, y_resampled = ros.fit_resample(X, y)2、SMOTE
SMOTE生成合成样本来平衡数据集。
from imblearn.over_sampling import SMOTE
smote = SMOTE()
X_resampled, y_resampled = smote.fit_resample(X, y)3、ADASYN
ADASYN根据少数样本的密度自适应生成合成样本。
from imblearn.over_sampling import ADASYN
adasyn = ADASYN()
X_resampled, y_resampled = adasyn.fit_resample(X, y)4、RandomUnderSampler
RandomUnderSampler随机从多数类中移除样本。
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler()
X_resampled, y_resampled = rus.fit_resample(X, y)5、Tomek Links
Tomek Links可以移除的不同类的最近邻居对,减少多样本的数量
from imblearn.under_sampling import TomekLinks
tl = TomekLinks()
X_resampled, y_resampled = tl.fit_resample(X, y)6、SMOTEENN (SMOTE +Edited Nearest Neighbors)
SMOTEENN结合SMOTE和Edited Nearest Neighbors。
from imblearn.combine import SMOTEENN
smoteenn = SMOTEENN()
X_resampled, y_resampled = smoteenn.fit_resample(X, y)7、SMOTETomek (SMOTE + Tomek Links)
SMOTEENN结合SMOTE和Tomek Links进行过采样和欠采样。
from imblearn.combine import SMOTETomek
smotetomek = SMOTETomek()
X_resampled, y_resampled = smotetomek.fit_resample(X, y)8、EasyEnsemble
EasyEnsemble是一种集成方法,可以创建多数类的平衡子集。
from imblearn.ensemble import EasyEnsembleClassifier
ee = EasyEnsembleClassifier()
ee.fit(X, y)9、BalancedRandomForestClassifier
BalancedRandomForestClassifier是一种将随机森林与平衡子样本相结合的集成方法。
from imblearn.ensemble import BalancedRandomForestClassifier
brf = BalancedRandomForestClassifier()
brf.fit(X, y)10、RUSBoostClassifier
RUSBoostClassifier是一种结合随机欠采样和增强的集成方法。
from imblearn.ensemble import RUSBoostClassifier
rusboost = RUSBoostClassifier()
rusboost.fit(X, y)总结
处理不平衡数据对于建立准确的机器学习模型至关重要。这些Python库提供了各种技术来应对这一问题。根据你的数据集和问题,可以选择最合适的方法来有效地平衡数据。