1、自然语言理解与语言模型
1.1 自然语言处理
自然语言处理 (NLP) 是人工智能 (AI) 的一个分支。它能够使计算机理解、生成和处理人类语言,建立在机器语言和人类语言之间沟通的桥梁,以实现人机交流的目的,涉及到语言学、计算机科学以及人工智能等交叉学科。
回顾NLP的主要发展历程,可大致分为三个阶段:
- 上世纪80年代之前,人工智能萌芽阶段,主要是基于规则的语言系统;
- 80年代之后,从机器学习的兴起到神经网络的引入,带动了NLP的快速发展和商业化;
- 2017年至今,基于Attention注意力机制构建的Transformer模型开启了大语言模型时代;
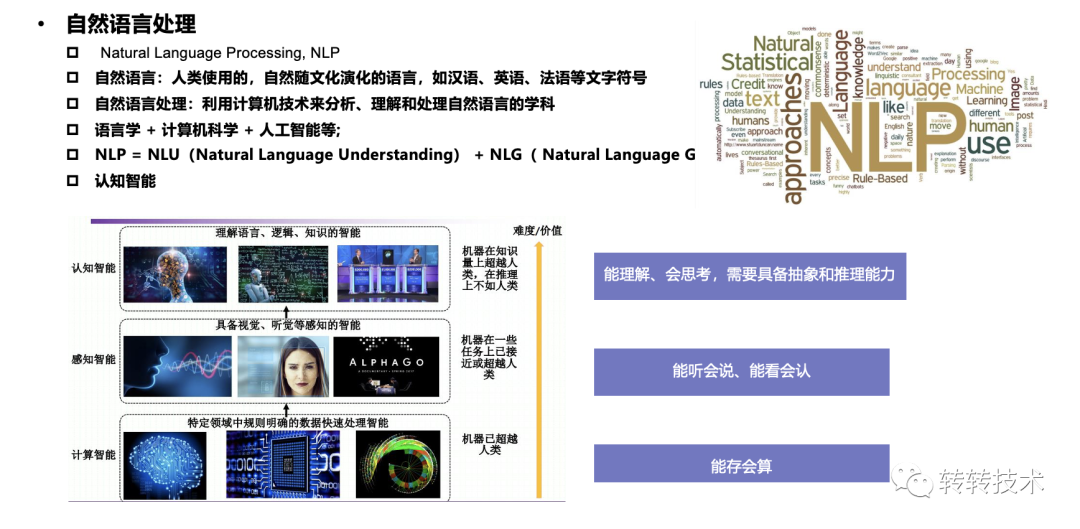
自然语言处理
NLP可分为自然语言理解(Natural Language Understanding, NLU)和自然语言生成(Natural Language Generation, NLG)两大部分。
自然语言理解(NLU)就是希望机器像人一样,具备正常人的语言理解能力,由于自然语言在理解上有很多难点(多样性、奇歧义性,知识依赖以及语言的上下文等),所以 NLU 是至今还远不如人类的表现。
自然语言生成(NLG)是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
自然语言处理是是计算机科学领域与人工智能领域中的一个重要方向,被誉为“人工智能皇冠上的明珠”。

NLP领域世界级大师
近几年自然语言处理的发展迅猛,尤其是2017年Transformer提出后,在NLP领域得到了普遍应用,都获得了不错的效果。其实,在人类尚未明了大脑是如何进行语言的模糊识别和逻辑判断的情况下,NLP要想有突破性的进展,依然还有很长的路要走。

NLP文本处理的多种困难
1.2 语言模型


2、语言模型的发展演进
语言模型的研究范式变化是从规则到统计,从统计机器学习到基于神经网络的深度学习,这同时也是自然语言处理(NLP)发展的历史。

语言模型发展演进
2.1 统计语言模型
从语言模型的链式定义公式来看,由于涉及到的参数量巨大,计算条件概率困难。随后引入Markov Assumption,解决参数空间大的问题。在词语共现的长度选择做出了让步,N-gram ML的定义为:

N较大时:
- 提供了更多的上下文信息,语境更具区分性;
- 参数多,计算代价大,需要训练语料多,参数估计不可靠;
N较小时:
- 上下文信息少,语境不具区分性;
- 参数少、计算代价小、需要训练语料少、参数预估可靠;

困惑度随着N的变化而变化,N越大,参数量级以指数级增长,而困惑度越小。
2.2 神经网络语言模型

NNLM模型结构:

神经网络语言模型结构图
- 延续了Markov Assumption,即固定长度的历史词;
- 词映射到低维空间,解决了维度灾难问题;
- 词泛化能力提升(如:相似性、类比性);
- 相似性:“movie”、“film”和“video”词语义相近;
- 类比性:“中国” + “北京” = “日本” + “东京”;
- 三层结构:Word Embedding Layer、Hidden Layer 和 Output Layer;
缺点:
- 固定长度的历史,缺失long term的依赖;
另外,NNLM的出现,直接催生了词向量化工具word2vec,从此进入词的向量化阶段。是将自然语言表示的单词转换为计算机能够理解的向量形式的技术。有了一个词的向量之后,各种基于向量的计算就可以实施,如用向量之间的相似度来度量词之间的语义相关性。其基于的分布式假设就是出现在相同上下文的词意思应该相近。Word Embedding也有其局限性,比如:难以对词组做分布式表达;无法解决多义词问题。此外,Word Embedding对于应用场景的依赖很强,所以针对特殊的应用场景可能需要重新训练,这样就会很消耗时间和资源。
word2vec的网络结构与NNML类似,在目标词和上下文的预测上,分为俩种,分别为CBOW(上下文信息-> 中间词)模型和Skip-gram(中间词-> 上下文信息)模型。
word2vec技术原理
2.3 RNN
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的网络结构。

RNN网络结构图
RNN设计上打破了神经网络语言模型的限制,认为词与词上下文信息决定了词的语义信息,而非像前馈神经网络同N-gram一样,每个词只依赖前个词,从而限制了前馈神经网络语言模型的性能;

缺点:
- 梯度消失或者爆炸(由多级偏导数连乘导致)

RNN在自然语言处理任务中,例如语音识别、语言建模、机器翻译等领域有应用,也被用于各类时间序列预报。
2.4 LSTM
长短期记忆(Long short-term memory, LSTM),顾名思义,它具有记忆长短期信息的能力的神经网络。在1997年由Hochreiter 和 Schmidhuber 提出,在深度学习在2012年兴起后,LSTM又经过了若干代大牛的迭代,形成了比较系统且完整的LSTM框架,并在很多领域得到了广泛应用。
LSTM提出的动机是为了解决上面我们提到的RNN长期依赖问题,并解决长序列训练过程中的梯度消失和梯度爆炸问题。相比普通的RNN,LSTM能够在更长的序列中有更好的表现。从RNN模型的结构看,随着词的增加,之前比较长的时间片的特征会被覆盖。因此,rnn丧失了学习连接较远的信息的能力。长期依赖产生的原因是当神经网络的节点经过许多阶段的计算后,特征信息被覆盖造成的。
例如: “小李今天上午参加了一个有趣的班级活动,在哪里有许多有趣的朋友,大家一起畅聊学习生活,共同跳舞唱歌,他觉得非常开心。”,“他“指的就是“小李”,由于词距离较远,“小李”的语义信息已衰减,因此“小李”和“他”具有长依赖问题。
LSTM的核心是单元状态(Cell State),由三个门机制来控制Cell状态,这三个门分别称为遗忘门、输入门和输出门。LSTM是通过Gate机制控制特征的流通和损失;
LSTM网络结构如下:

LSTM网络结构图
遗忘门: LSTM的第一步就是决定Cell状态需要丢弃哪些信息。这部分操作是通过一个称为遗忘门的 sigmoid 单元来处理的。它通过和信息来输出一个 0-1 之间的向量,该向量里面的 0-1 值表示单元状态中的哪些信息保留或丢弃多少。0表示不保留,1表示都保留。 遗忘门如下图所示。

LSTM-遗忘门
输入门: 用于更新单元状态。首先,将先前的隐藏状态和当前输入传递给 sigmoid 函数。这决定了通过将值转换为0到1来更新哪些值。0表示不重要,1表示重要。还将隐藏状态和当前输入传递给 tanh 函数,将它们压缩到-1和1之间以帮助调节网络。然后将 sigmoid 输出与 tanh 输出相乘。如下图所示:

LSTM-输入门
输出门: 输出门决定下一个隐藏状态是什么。隐藏状态也用于预测。首先,将先前的隐藏状态和当前输入传递给 sigmoid 函数。然后将新的单元状态传递给 tanh 函数。将 tanh 输出与 sigmoid 输出相乘,以决定隐藏状态应携带的信息。它的输出是隐藏状态。然后将新的单元状态和新的隐藏状态传递到下一个时间步。如下图所示:

LSTM-输出门
缺点:
- 超长序列时,LSTM的性能仍不理想;
- 计算效率低下;
LSTM长短期神经网络的主要应用于:
- 文本生成:训练语言模型,在给定一些前缀的情况下生成合理的文本;
- 语音识别:可以识别说话人的声音,也可以用来识别说话的语音;
- 机器翻译:seq2seq翻译模型,可以把一种语言翻译成另一种语言;
- 时间序列预测:预测时间序列数据,比如股票价格,天气预报等;
2.5 ELMo
Word Embedding的杰出代表word2vec,本质上是静态的词向量,即训练完单词的语义就固定了,不会跟着上下文场景的变化而改变。为了解决这个问题,出现了ELMO(Embedding from Language Models)的训练方案。ELMO采用了典型的两阶段过程,第一个阶段利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。通过加入双层双向的LSTM网络结构,ELMo引入上下文动态调整单词的embedding后,多义词问题得到了解决。另外,ELMo最早提出预训练机制。

ELMo模型结构图
损失函数:
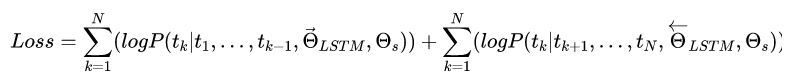
损失函数由俩部分组成,分别是前向的LSTM语言模型的损失函数 和 后向的LSTM语言模型的损失函数之和,认为词的语义信息是由词以及词的上下文信息来决定。
- 动态词向量的提出,多义词方面的得到极大改善;
例如:"我中午吃了一个苹果。” 和 “上周我买了一部苹果手机。” 中的苹果,相同的词,但具有不同的语义。 - 较早提出预训练的概念;
缺点:
- 特征抽取能力欠缺,ELMo使用了LSTM而不是Transformer(当时transformer已经被提出),Transformer提取特征的能力是要远强于LSTM;
- 训练时间长;
2.6 Transformer
Transformer是由谷歌公司提出的一种基于自注意力机制的神经网络模型,用于处理序列数据。在自然语言处理中,序列数据的输入包括一系列文本、语音信号、图像或视频等。传统的循环神经网络(RNN、LSTM)模型已经在这些任务中取得了很好的效果,但是该模型存在着两个主要问题:一是难以并行计算,需要训练时间长;二是难以捕捉长距离依赖关系。为了解决这些问题,Transformer模型应运而生。
2017年,Google机器翻译团队发表的经典之作:《Attention is All You Need》中,完全抛弃了RNN和CNN等网络结构,而仅仅采用Attention机制来进行机器翻译任务,并且取得了很好的效果,随后注意力机制也成为了研究与应用热点。

Transformer经典论文:Attention Is All Your Need
在介绍Transformer之前,我们先了解一下Attention机制、Self-Attention以及残差网络等。
2.6.1 Attention机制
2014年,Bengio团队提出Attention机制,后来被广泛应用于深度学习中的各个领域。例如在计算机视觉方向用于捕捉图像上的感受野、NLP中用于定位关键token或者特征、以及随后的Bert与GPT系列模型,都在随后的NLP任务中取得到 state-of-the-art 的效果。
Attention机制计算流程:
Attention机制的计算逻辑大致分为三步:

优势:
- 可并行计算;
- 一步到位获取全局与局部联系,不像rnn有长依赖的局限性;
- 参数少,模型复杂度低;
缺点:
- 没法捕捉位置信息,即没法学习序列中的顺序关系,为随后 position embedding 的出现埋下来伏笔;
在transformer中,采用的是Self-Attention机制。在Attention机制中,当Q=K=V时,就是Self-Attention,主要体现输入数据中的各部分的关联。
2.6.2 残差网络(ResNet)
在深度网络的学习中,网络深度越深,能够获取的信息越多,而且特征也越丰富。但是现实中随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。针对此类问题,由微软实验室中的何凯明等在2015年提出了ResNet网络,缓解了该问题,并斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。
残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。网络结构如下:

残差网络结构
- 残差网络的输出 = 直接映射部分 + 残差部分
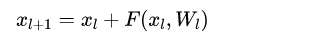
- 为什么有效?
- “宽而浅”
- “窄而深”,需要网络优化,避免梯度消失;
- 残差连接使得信息前后向传播更加顺畅,解决梯度消失问题;
- Ensemble model,降低方差;
2.6.3 Position Embedding
Transformer中的position embedding的作用是在序列模型中引入单词位置信息,以帮助模型更好地理解序列中的单词顺序和位置关系,从而提高模型的性能和准确性。


在Transformer中,使用的是Sinusoidal Position Embedding,属于绝对位置编码,优点是编码简单,不占用参数空间;缺点是限制了最大输入长度。针对绝对位置编码的缺点,在随后的引入了相对位置编码(Bert中应用) 和 旋转位置编码(RoFormer中应用)。
位置编码:
- 绝对位置编码:Sinusoidal Function(sin/cos),不随着模型参数进行学习更新;
- 相对位置编码:位置ID的embedding编码,在模型参数中,随着梯度得以训练学习;
- 旋转位置编码:RoPE等,结合了绝对位置编码 和 相对位置编码的有点;
2.6.4 Transformer原理
Transformer与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer仅使用自注意力机制(self-attention)来处理输入序列和输出序列。在模型中包含了多层encoder和decoder,每一层都由多个注意力机制模块和前馈神经网络模块组成。encoder用于将输入序列编码成一个高维特征向量表示,decoder则用于将该向量表示解码成目标序列。通过不断堆叠多个自注意力层和前馈神经网络层,可以构建出Transformer模型。在Transformer模型中,还使用了残差连接和层归一化等技术来加速模型收敛和提高模型性能。网络结构图如下:

Transformer的encoder、decoder模块

Multi-Head Attention
自注意力机制的计算过程包括三个步骤:
- 计算注意力权重:计算每个位置与其他位置之间的注意力权重,即每个位置对其他位置的重要性;
- 计算加权和:将每个位置向量与注意力权重相乘,然后将它们相加,得到加权和向量;
- 线性变换:对加权和向量进行线性变换,得到最终的输出向量;
对于Transformer模型的训练,通常采用无监督的方式进行预训练,然后再进行有监督的微调。在预训练过程中,通常采用自编码器或者掩码语言模型等方式进行训练,目标是学习输入序列的表示。在微调过程中,通常采用有监督的方式进行训练,例如在机器翻译任务中,使用平行语料进行训练,目标是学习将输入序列映射到目标序列的映射关系。
Transformer 中 Multi-Head Attention 中由多个 Self-Attention的拼接,可以捕获单词之间多种维度上的相关系数 attention score。
Transformer模型的缺点:
- 需要较大的数据集来训练;
- 计算复杂度较高,需要更多的计算资源,比如GPU等;
- 可解释性差;
在自然语言处理的任务中,Transformer模型真正改变了我们处理文本数据的方式,推动了自然语言处理发展,包括Google的BERT、OpenAI的GPT系列模型都采用Transformer来提取特征。
2.7 BERT
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。模型结构图如下:

BERT模型结构图

BERT的输入构成

- MLN 通过上文+下文 -> 中间词,重在理解;而NSP重在生成;
- 12 Layers,hidden tokens: 1024;
- ”深而窄” 比 “浅而宽” 的模型更好;
- 采用双向Transformers进行预训练,生成深层的双向语言表征,进一步挖掘上下文所带来的丰富语义;
- 预训练后,只需要对增加的输出层进行fine-tune,就可以在各种各样的下游任务中取得 state-of-the-art 表现;
- 开启了“预训练 + 参数微调”的研究范式;

值得一提的是论文发表时提及在11个NLP(Natural Language Processing,自然语言处理)任务中获得了新的state-of-the-art的结果,尤其是在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩,全部两个衡量指标上全面超越人类。
3、GPT系列模型简介
随着ChatGPT火遍圈内外,连微博热搜都出现了它的身影。突然之间,好多许久未联系的各行各业的同学好友都发来“问候”:ChatGPT 是什么? 其实,ChatGPT 的成功并非一朝一夕,而是 OpenAI长达4年多持续努力、不懈追求取得的成果。从2018年的初代GPT-1开始,到GPT-2、GPT-3、InstructGPT,GPT-4,到如今的GPT-4,每一步都是不可或缺的。所以,ChatGPT不是一次伟大创新的产物,而是许多个阶段性创新持续叠加的结果。

GPT系列模型的发展过程
3.1 GPT-1
2018年6月,OpenAI公司发布了GPT模型的初代版本,GPT-1运用了Transformer的Decoder框架中MaskSelf-attention机制。GPT-1在训练方式上仍依赖于数据标注和模型微调,同时GPT-1的语言泛化能力仍然不足,因此可以说GPT-1更接近于处理特定语言任务的专家模型,而非通用的语言模型。GPT-1的模型训练采取的是二段式的训练模式,第一阶段利用无监督学习进行预训练,使用未标记的数据生成语言模型;第二阶段则根据特定的下游任务来对模型进行人工微调,比如分类任务、自然语言推理、语义相似度、问答和常识推理等任务。因此相较于此前NLP模型,GPT-1实际上还是一个半监督式学习的语言模型。GPT-1在多种语言任务方面都有不错的效果,在自然语言推理、分类、问答、对比相似度的多种测评中均超越了之前的模型。同时,GPT-1的语言泛化能力仍然不足,无法解决通用的语言任务,且和同时代的BERT模型比较的话,GPT-1在能力上要逊色于BERT。

GPT-1的模型结构
模型结构:
- 12层 transformer decoder + 768维隐向量
- Optimizer: Adam
- Tokens:1024
损失函数:
优势:
- 特征抽取器首次使用了强大的 Transformer,能够捕捉到更长的记忆信息;
- Auto-regressive Language Model,根据当前信息生成下一刻的信息,适用于自然语言生成任务(NLG);
- 预训练(无监督)+ finetune(有监督);
- GPT为基于预训练的自然语言处理模型的发展提供了新的思路和方法;
劣势
- 模型泛化能力欠缺;
- Fine-tune 需要数据量大,耗时耗力,难快速扩展;
- GPT-1 最大的问题就是同传统的语言模型是一样是单向的;
3.2 GPT-2
2019年2月,GPT-2正式发布,相较于GPT-1,GPT-2舍弃了模型微调,直接通过大规模数据进行预训练,让模型开始具备解决多种语言任务的能力,实现一个泛化能力更强的语言模型,这也开始让模型的通用性得以充分展现。尽管此前GPT-1在特定任务上已经取得了不错的效果,但实际上这类模型都需要针对单个语言任务使用大量的标注数据和模型微调,因此也只能在解决特定语言任务时才能发挥作用。而GPT-2的泛化能力就体现在,能够让模型应用到不同的任务,而不需要做专门的训练。这也更符合人脑处理语言信息的过程,因为人脑既可以读小说,也可以看新闻,能执行不同的语言处理任务,而且这种能力是相互关联的。而人脑在获取一个语句的信息时,这个信息是通用的,因此我们所期望的一个通用的语言模型,既可用于分类任务,也可以用于问答和常识推理等任务。
GPT-1和GPT-2的网络结构对比:

GPT-1和GPT-2的网络结构对比
模型参数
- 48层transformer decoder + 1600维隐向量
- Optimizer:Adam
- 字典大小:50257
- tokens:1024
- 在每一个self-attention之后都添加了Layer Normalization
- 残差层的初始化值用1/sqrt(N)进行缩放,N为残差层个数
损失函数:
从损失函数可以看出,相比与GPT-1抛弃了对task的有监督微调损失部分,损失函数只针对语言模型的生成部分,开启了NLG的新篇章。
优势:
- 更多的训练语料;
- 通用化设计:不定义模型应该做什么任务,模型会自动识别出来需要做什么任务;
- 提出了zero-shot learning;
劣势
- 模型学习远远不够,人类学习是不需要大量样本的,且有能力做到融会贯通;
- 不支持fine-tune;
3.3 GPT-3
2020年5月,GPT-3正式发布,GPT-3在训练方式上创新性的引入了In-context学习(上下文学习),即在训练模型时,在输入的文本中加入一个或多个示例,引导模型输出相对应内容。比如:“请把以下中文翻译成英文:苹果=>apple;自然语言处理的发展历程”就是一个典型的带有一个示例的输入文本。而In-context学习包含了三种模式,分别为Zero-shotLearning(零样本学习)、One-shotLearning(单样本学习)和Few-shotLearning(少样本学习),zero-shot就是没有示例只给提示,one-shot是只给一个范例,few-shot则给多个范例,实际上zero-shot在表达方式上已经接近于人类的语言表达方式。In-context学习的优点在于,输入规范化的语言模板,从人类的例子和类比中去学习,无需进行模型微调和数据标注,特别是大量的标注数据需要很高的人工成本。引入In-context学习后,从最终实际效果来看,GPT-3在few-shot上有非常强劲的表现,但同时one-shot和zero-shot的效果还不够优秀。

GPT-3在Few-shot上有很好的表现
GPT-3参数量相较于GPT-2提升了两个数量级,达到了1750亿,数据集在处理前容量达到了45TB,成了真正意义上的超大语言模型。GPT-3在许多NLP任务上相较于GPT-2及其他语言模型有更多出色表现,特别是机器翻译、聊天问答和文本填空。同时是在海量参数和训练数据的支撑下,GPT-3的开始能够完成一些比较困难的NLP任务,比如GPT-3也可以生成新闻报道和撰写文章,并且很难将机器写的文章与人类写的辨别开来,甚至GPT-3在编写SQL查询语句,React或者JavaScript代码也有十分优异的表现。而在GPT-3强大能力的背后是对算力的巨大消耗,GPT-3的计算量达到了BERT-base的上千倍,根据OpenAI公司披露数据,GPT-3的训练费用超过1200万美元,因此到这一阶段就能看出,大语言模型逐渐成为了只有巨头才能参与的游戏。
GPT-3 网络结构图:

GPT-3模型网络结构图
损失函数为:
- 预训练(无监督) + Fine-tune;
- Meta-learning + 增加参数模型;
- Sparse attention;
- prompt learning,One-shot
- Few-shot;
- 典型代表模型:Davinci、Curie、Babbage、Ada;
- 优先使用内置模型,one-shot、few-shot提升可靠性;

Zero-shot、One-shot和Few-shot的区别
缺点:
- 生成长文本时存在自相矛盾、不合逻辑,在一些任务上没有体现理解能力;
- 模型太大,训练不高效,缺乏解释性,存在偏见;
GPT-3 应用到了更大的训练数据,参数模型更是达到了1750亿,并对GPT-3生成的多个结果进行人工标注,用强化学习将标注的结果进行再次学习,得到更加相对一致、准确的生成结果。

GPT-3引入人工标注结果

GPT-1、GPT-2和GPT-3的训练数据和参数量级对比
3.4 ChatGPT
OpenAI公司在GPT-3与ChatGPT之间发布了多个迭代版本,其中包括:2021年7月推出了Codex系列;2022年1月,引入RLHF(基于人工反馈的强化学习)得到了InstructGPT;2022下半年,推出了融合Codex和InstructGPT的ChatGPT,使用了基于人类反馈的强化学习的版本指令微调模型。ChatGPT相较于GPT-3,不仅是在文本生成等方面展现出了非常强大的能力,与人类对话的智能感大幅提升,而且海量数据和参数的支撑下,模型在逻辑推理与思维链等方面能力开始涌现。ChatGPT可以完成许多相对复杂的语言任务,可以完成包括自动文本生成、自动问答、多轮对话等,并且能够主动承认错误,质疑不正确的问题等。此外,ChatGPT还能编写和调试计算机程序。

ChatGPT训练流程

强化学习训练流程
- 来源于兄弟模型InstructGPT;
- ChatGPT核心技术HFRL(Human Feedback Reinforcement Learning),本质就是如何把机器的知识与人的知识对齐;
- 让具备丰富世界知识的大模型,学习“人类偏好”;
- 标注人员明显感觉 InstructGPT 的输出比 GPT-3 的输出更好,更可靠;
- PPO:Proximal Policy Optimization;
- Prompt模式较Fine-tune更具生命力;
缺点:
- 结果不稳定;
- 推理能力有限;
- 知识更新困难;
目前ChatGPT的应用主要包括:
- 聊天机器人,可以使用ChatGPT来自由对话,使机器人能够向用户做出自然的回应;
- 编写和调试计算机程序;
- 文学、媒体相关领域的创作,包括创作音乐、电视剧、童话故事、诗歌和歌词等;
- 教育、考试、回答测试问题;
- 通过API结构集成到其他应用中,ChatGPT在推出后仅两个月活跃用户就达到了一个亿,成为了史上用户增长速度最快的消费级应用程序;
3.5 GPT-4
GPT-4于2023年3月份发布,相较于之前版本的GPT模型,在推理、文本生成、对话等方面有了大幅提升之外,GPT-4迈出了从语言模型向多模态模型进化的第一步。GPT-4最大的变化即能够接受图像的输入,并且能够生成文本语言,并且在看图能力方面有让人惊喜的表现的。同时可以处理超过25000字长文本,以及写作能力的大幅提升,能够编歌曲、写剧本、学习用户写作风格,同时包括GRE、SAT等考试能力也有大幅提升。在基于机器学习模型设计的各项基准上评估GPT-4,GPT-4明显优于现有的大型语言模型,以及大多数SOTA模型。
GPT-4训练过程主要分为三个阶段,如下图:
- 第一阶段:构建交叉注意力架构预训练模型,收集数据并进行有监督策略精调;
GPT-4模型是基于GPT-3.5构建的,增加了视觉语言模型组件(在图形Transformer阶段完成的视觉预训练模型)。为了预训练模型在多模态领域进行初步调优,首先会在文本数据集和多模态数据集中抽取问题,由人类标注员,给出高质量答案,然后用这些人工标注好的数据来精调GPT-4初始模型。
- 第二阶段:训练奖励模型(RRM)和 基于规则的奖励模型(RBRM);
首先基于安全规则设计基于规则的奖励模型并完成验证。这一模型与传统NLP领域的规则模型设计方法一致。 然后在数据集中抽取问题,使用第一阶段生成的模型,对于每个问题,生成多个不同的回答。人类标注者对这些结果综合考虑给出排名顺序。接下来,使用这个排序结果数据来训练GPT-4的奖励模型。对多个排序结果,两两组合,形成多个训练数据对。RM模型接受一个输入,给出评价回答质量的分数。这样,对于一对训练数据,调节参数使得高质量回答的打分比低质量的打分要高。这一过程类似于教练或老师辅导。

- 第三阶段:采用PPO强化学习来优化策略;
PPO的核心思路在于将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习,这个转化过程被称之为Importance Sampling。这一阶段利用第二阶段训练好的奖励模型和基于规则的奖励模型,靠奖励打分来更新预训练模型参数。在GPT-4数据集中抽取问题,使用PPO模型生成回答,并用上一阶段训练好的RM+RBRM模型给出质量分数。把回报分数依次传递,由此产生策略梯度,通过强化学习的方式以更新PPO模型参数。
4、结语
大语言模型的出现,为我们提供了一种新的思路,即通过大规模预训练和微调技术,让模型具备更强大的语言理解能力,从而能够应用于更多的NLP任务。未来,我们可以期待更加智能、灵活、高效的语言模型的出现,它们将会给我们带来更多新的可能性和优秀的应用场景。

大语言模型发展时间轴
随着Transformer的提出,近几年大语言模型的发展迅猛,优秀代表如GPT系列模型的出现,将语言模型的发展提升到一个前所未有的高度。模型参数量级也在陡增,带来了模型效果提升的同时,也引入了其他的问题。
- 在未经大量语料训练的领域缺乏“人类常识”和一本正经的“胡说八道”;
- 无法处理复杂冗长或者专业性很强的语言结构;
- 需要大量的算力来支持其训练和预测;
- 训练成本极高,无法实时的融入新知识到大模型;
- “黑盒模型”,对其能否产生攻击性或者伤害性的表述,无法做出保证;
- 存在幻觉和推理错误;
- 泄露隐私的可能;
- 事实检索性和复杂计算性效果差,无法实现一些实时性、动态变化性的任务;
业界大佬对大模型的发展也都各持不同的观点。
5 、[1] A Neural Probabilistic Language Model
- [2] Recurrent Neural Network Regularization
- [3] Long Short-Term Memory
- [4] Deep Contextual Word Embeddings
- [5] Attention Is All Your Need
- [6] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- [7] Improving Language Understanding by Generative Pre-Training
- [8] Language Models are Unsupervised Multitask Learners
- [9] Language Models are Few-shot Learners
- [10] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- [11] Training language models to follow instructions with human feedback
- [12] Proximal Policy Optimization Algorithms
- [13] ChatGPT: Optimizing Language Models for Dialogue
- [14] Deep Residual Learning for Image Recognition