












在计算机科学中,理解程序的内部工作原理是一项基础且重要的技能。本文将深入探讨C程序的内部工作方式,涉及的主题包括编译过程、执行过程和内存管理等。

一、编译过程
C程序的生命周期从编译过程开始。编译器将人类可读的源代码转换为机器可执行的指令。
C编译过程包括四个主要阶段:预处理、编译、汇编和链接。
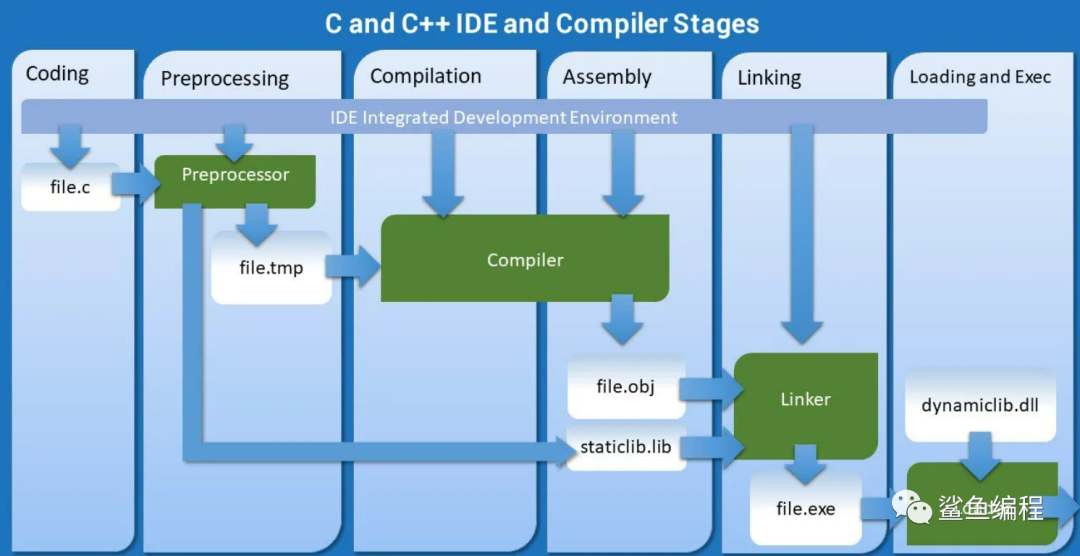
1.预处理
预处理器负责处理源代码中的预处理命令。这些指令通常以#字符开始,如#include、#define等。例如:
#include <stdio.h>
#define MAX 100在这一阶段,#include指令会被对应的文件内容替换,而#define指令则定义一个常数或宏。
2.编译
编译器将处理过的源代码转换为汇编语言。在这一阶段,编译器会进行语法和语义检查,如类型检查、语法错误检查等。
3.汇编
汇编器将编译器产生的汇编代码转换为目标代码,也就是机器语言。
4.链接
链接器将所有的目标文件和库文件链接在一起,生成一个可执行文件。
二、执行过程
C程序的执行过程主要涉及到CPU、内存和操作系统的协同工作。操作系统负责加载可执行程序到内存,并通过CPU执行。
三、内存管理
C程序在执行过程中使用内存来存储变量、函数和其他数据。内存管理是一个重要的主题,涉及到栈、堆和静态存储区等概念。
1.栈
栈是一种后进先出(LIFO)的数据结构,用于存储局部变量、函数参数和函数调用的上下文信息。栈由编译器自动管理,当函数调用结束时,栈上的内存会自动释放。
以下是一个使用栈的示例代码:
#include <stdio.h>
int factorial(int n) {
if (n <= 1) {
return 1;
} else {
return n * factorial(n - 1);
}
}
int main() {
int num = 5;
int result = factorial(num);
printf("Factorial of %d is %d\n", num, result);
return 0;
}2. 堆
堆用于动态分配内存,通常用于存储动态创建的对象和数据结构。在C中,可以使用malloc()和free()函数来进行堆内存的分配和释放。
以下是一个使用堆的示例代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
int* nums = (int*)malloc(5 * sizeof(int));
if (nums == NULL) {
printf("Memory allocation failed\n");
return 1;
}
for (int i = 0; i < 5; i++) {
nums[i] = i + 1;
}
for (int i = 0; i < 5; i++) {
printf("%d ", nums[i]);
}
free(nums);
return 0;
}3.静态存储区
静态存储区用于存储全局变量和静态变量。全局变量在程序的整个生命周期内存在,而静态变量在函数的多次调用中保持持久性。
四、函数调用
在C程序中,函数是基本的组织单位。每个函数调用都会在调用栈上创建一个新的栈帧。例如,以下代码展示了一个函数调用的例子:
void foo(int x) {
printf("%d\n", x);
}
int main() {
foo(10);
return 0;
}在这段代码中,当main函数调用foo函数时,将会在调用栈上创建一个新的栈帧,用于存储foo函数的局部变量和返回地址。
总结
C程序从编译开始,然后由操作系统加载并执行,在这个过程中,内存管理和函数调用是两个重要的部分。理解这些原理能帮助我们写出更高效、更安全的程序。














