













译者 | 李睿
审校 | 重楼
近几个月来,生成式人工智能凭借其创造独特的文本、声音和图像的能力引起了人们的极大兴趣。但生成式人工智能的力量并不局限于创造新的数据。
生成式人工智能的底层技术(例如Transformer和扩散模型)可以为许多其他应用提供动力,其中包括信息的搜索和发现。特别是,生成式人工智能可以彻底改变图像搜索,使人们能够以以前不可能的方式浏览视觉信息。

以下是人们需要知道的关于生成式人工智能如何重新定义图像搜索体验的内容。
图像和文本嵌入
传统的图像搜索依赖于图像附带的文本描述、标记和其他元数据,这将用户的搜索选项限制为已经明确附加到图像中的信息。上传图像的人必须认真考虑输入的搜索查询类型,以确保他们的图像被他人发现。而在搜索图像时,查询信息的用户必须尝试想象图像上传者可能在图像中添加了什么样的描述。
俗话说,“一图胜千言”。然而对于图像的描述来说,可以编写的内容是有限的。当然,根据人们查看图像的方式,可以采用很多方式进行描述。而人们有时根据图中的物体进行搜索,有时根据风格、光线、位置等特征搜索图像。不幸的是,图像很少伴随着如此丰富的信息。很多人上传的许多图像几乎没有附带任何信息,这使得它们很难在搜索中被发现。
这就是人工智能图像搜索发挥重要作用的地方。人工智能图像搜索有不同的方法,不同的公司有自己的专有技术。然而,有些技术是这些公司所共有的。
人工智能图像搜索以及许多其他深度学习系统的核心是嵌入,嵌入是不同数据类型的数值表示。例如,512×512分辨率的图像包含大约26万个像素(或特征)。嵌入模型试图通过对数百万张图像进行训练来学习视觉数据的低维表示。图像嵌入可以有许多有用的应用,包括压缩图像、生成新图像或比较不同图像的视觉属性。
同样的机制适用于文本等其他形式。文本嵌入模型是文本摘录内容的低维表示。文本嵌入有许多应用,包括用于大型语言模型(LLM)的相似性搜索和检索增强。
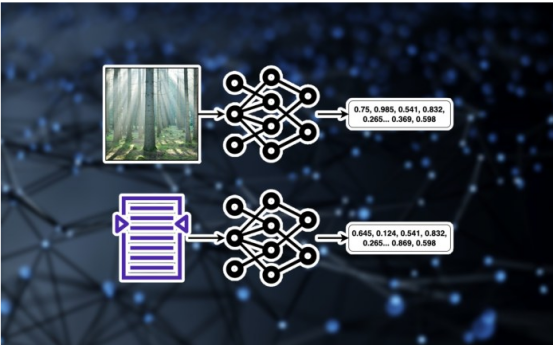
人工智能图像搜索的工作原理
但是,当图像和文本嵌入一起训练时,事情变得更加有趣。像LAION这样的开源数据集包含数以百万计的图像及其相应的文本描述。当文本和图像嵌入在这些图像/标题对进行联合训练或微调时,它们会学习视觉和文本信息之间的关联。这就是深度学习技术背后的思想,例如对比图像语言预训练(CLIP)。
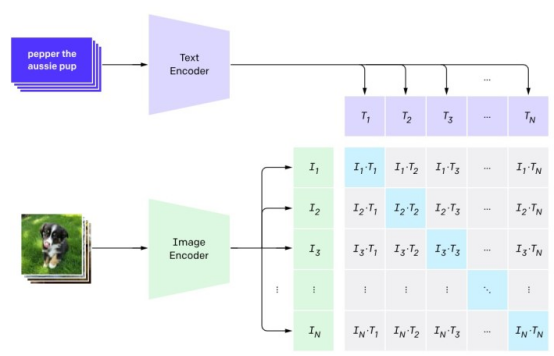 对比图像语言预训练(CLIP)模型学习文本和图像的联合嵌入
对比图像语言预训练(CLIP)模型学习文本和图像的联合嵌入
现在,有了可以从文本转换为视觉嵌入的工具。当为这个联合模型提供文本描述时,它将创建文本嵌入及其相应的图像嵌入。然后,可以将图像嵌入与数据库中的图像进行比较,并检索与它最密切相关的图像。这基本上就是人工智能图像搜索的工作原理。
这种机制的美妙之处在于,用户将能够基于图像视觉特征的文本描述检索图像,即使这一描述没有在其元数据中注册。你可以使用丰富的搜索词,这在以前是不可能实现的,例如“郁郁葱葱的森林笼罩着晨雾,灿烂的阳光透过高大的松林,草地上生长着一些蘑菇。”
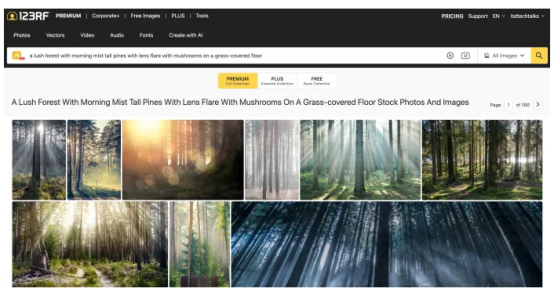
在上面的例子中,人工智能搜索返回了一组图像,其视觉特征与这个查询相匹配。其中很多的文字描述都没有包含查询的关键词。但它们的嵌入与查询的嵌入相似。如果没有人工智能图像搜索,要找到合适的图像就会困难得多。
从发现到创造
有时,人们寻找的图像并不存在,甚至通过人工智能搜索也无法找到它。在这种情况下,生成式人工智能可以通过两种方式之一帮助用户实现预期的结果。
第一种方法是根据用户的查询从头创建一个新图像。在这种情况下,文本到图像生成模型(例如Stable Diffusion或DALL-E)为用户的查询创建嵌入,并使用它创建图像。生成模型利用对比图像语言预训练(CLIP)等联合嵌入模型和其他架构(例如Transformer或扩散模型)将嵌入的数值转换为令人惊叹的图像。
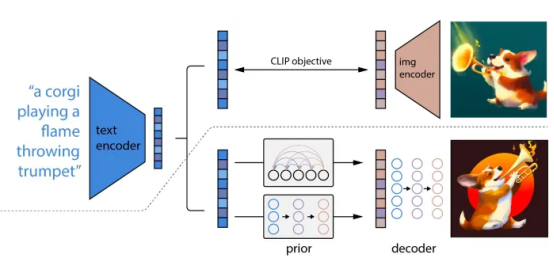 DALL-E使用对比图像语言预训练(CLIP)和扩散从文本生成图像
DALL-E使用对比图像语言预训练(CLIP)和扩散从文本生成图像
第二种方法是采用现有的图像,并使用生成模型根据自己的喜好进行编辑。例如,在返回松林的图片中,草地上的蘑菇是缺失的。用户可以使用其中一张认为合适的图像作为起点,并使用生成模型将蘑菇添加到其中。

生成式人工智能创造了一个全新的范例,模糊了发现和创造力之间的界限。而在单一界面中,用户可以查找图像、编辑图像或创建全新的图像。
原文标题:How generative AI is redefining image search,作者:Ben Dickson




























