随着企业数字化的深入,系统上云或者国产化改造的需求也是越来越多,数据迁移作为其中的重点中的重点,绝对是不可绕开的一个关键环节。可能有人会觉得数据迁移不是很简单吗,用binlog把数据同步到新库不就完了吗?这就把问题想简单了,事实上数据迁移架构可能会非常复杂,而且每个企业可能都面临着不同的现状与历史情况。比如不是所有的系统数据库都是Mysql,像金融等大型企业的系统早期大量使用了Oracle或其它的一些商业数据库,甚至在某些限制的情况下DBA团队都不提供7*24小时的主备同步的功能。这时你的架构应该怎么设计?

一般来说系统按服务对象可以分为ToC、ToB、ToG,对于后两类系统或者规模较小的ToC类系统,通常可以有停机发布窗口,有停机窗口的系统数据迁移比无停机窗口7*24小时提供在线服务的系统相对来说会简单不少
对于小型系统来说,系统的割接可能比较简单,通常会在新系统中验证通过后观察一段时间,确认不存在回切风险后逐步下线旧系统即可。而对于大型系统来说,系统割接的时间可能持续几个月甚至数年的时间,就像在飞行的飞机上换发动机一样。对于高并发系统,数据的迁移除了数据库的迁移外还需要考虑缓存的数据迁移或预热以防止新系统在切入流量后发生缓存击穿而雪崩。下面是一些常用的策略和对限制性条件下的思考:
最简单的数据迁移策略
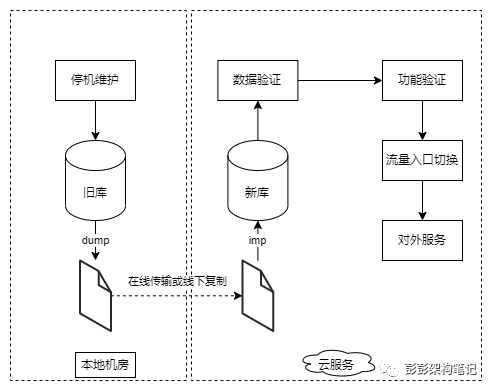
先来看一下最简单的数据迁移策略:即可停机的一次性迁移。也就是说在停机发布窗口内,完成数据迁移并完成新环境的功能验证测试,等恢复后用户访问到的系统已经更新为新系统。这种方式的优点是方案简单,缺点是当正常提供服务时间发现新环境存在重大问题时,由于新环境的数据库通常已经写入了新数据,已经没办法切回到旧环境的旧系统,所以这种策略适用于小规模系统。
具体的做法是在停机维护开始后先在旧数据库中执行mysqldump,再在新数据库中导入dump文件,这种方式甚至都不要求新旧环境之间的网络互通。在dump文件导入成功后,先进行数据验证,通过后数据迁移工作即基本完成。再对新环境的应用程序进行功能验证测试,通过后切换流量入口让新环境接替旧环境对外提供服务。见下图:
可回切的迁移策略
再来看一下稍微复杂一点的数据迁移策略:可回切的迁移策略。为了降低迁移的风险,企业通常会考虑在迁移完成并开始对外提供服务出现问题时进行回切。为了满足回切的需求,我们通常会让新旧两套数据库之间进行数据同步,新环境数据库为主库,旧环境数据库为从库,在回切时进行手工的主从倒换。这种方式也要求新旧环境间的网络是互通的。
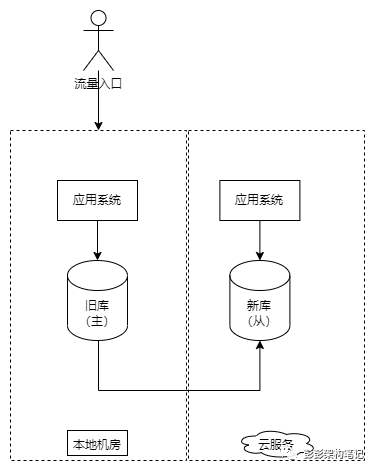
如上图,刚开始,旧环境数据库作为主库,新环境数据库作为从库。为了进一步减少数据迁移的时间,可先把新环境的应用程序部署等各类工作提前做好,先不切入流量入口即可。
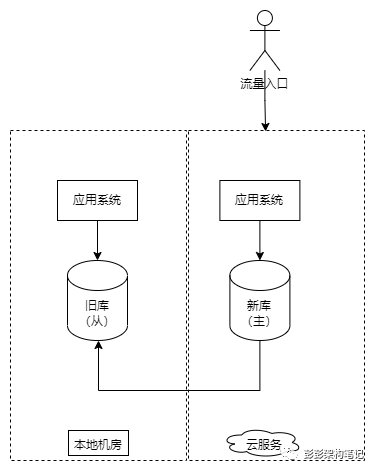
如上图,在停机发布窗口到来时,先停止旧环境流量,确认主从数据库数据同步完成后,手工执行主从倒换将旧环境数据库转换为从库,新环境数据库转换为主库。在对外提供服务后,由于写入新数据库的数据也会同步到旧数据库,只要新旧库之间的数据一致,旧服务就具备了回切的条件。
当发现新环境服务存在严重问题需要回切时,先停止新环境流量,确认数据同步完成后手工执行主从倒换并将流量入口切回旧环境。由于主从间的同步可以在数据迁移前就持续进行,真正迁移时只需要确认从库的数据追上了主库的数据后进行手工主从倒换,所以在这种方式也适用于很短停机窗口的系统。
双写的迁移策略
接下来我们来看一下更为复杂的异构数据库迁移策略:双写策略。前面介绍的两种策略都适用于同构数据库的数据迁移,但是对于异构数据库之间的数据迁移,我们应该如何设计呢?毕竟国产化改造多数情况是从一些商业数据库往国产或开源的数据库上进行迁移居多。
有一些商业的异构数据迁移工具号称可以支持7*24小时的异构数据库同步,但由于不同商业数据库拥有各自丰富的特性,很难覆盖所有方面。因此,我认为可以使用这类商业工具来进行存量数据的辅助迁移和验证,但对于实时产生的增量数据,主要还是依靠应用程序的双写机制来处理。
关于双写的实现方法,有多种选择,每种方法都有其优缺点和适用环境。根据增量数据的来源不同,主要有增量日志订阅方案和应用层双写方案。
增量日志订阅方案中,最常见的是使用开源工具Canal来订阅主库的Mysql binlog变化,并消费binlog以获取增量数据。这种方式只适用于Mysql作为源数据库的情况。虽然也有一些方案可以支持Oracle等商业数据库的数据迁移,例如愚公等工具,但它们需要额外的物化视图权限,并且可能对性能产生影响,实际应用中使用时会有一定限制。
应用层双写方案包括应用同步双写和异步双写两种方式。应用同步双写是指应用程序同时连接两个数据源,在写入数据时同时向两个数据库中写入数据。这种方式会在一定程度上降低应用程序的性能,因为现在需要同时插入两个库,而不仅仅是一个库。此外,该方式还要求应用与两个数据库必须在相同机房或者同一可用区,否则跨网络导致的时间开销会大大增加。应用异步双写方案与同步双写的不同之处在于,第二个库的写入是异步进行的。可以通过使用消息队列的方式来实现这种异步操作。由于采用了异步双写,对应用程序的性能影响非常小。
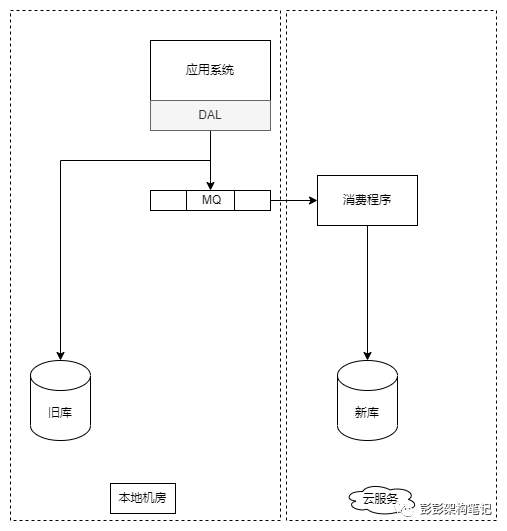
异步双写方案的具体实现如上图所示。在这种方案中,应用在写入数据时同时将数据写入消息队列。为了确保单个表的时序正确性,可以为每个表配置一个独立的消费者来处理消息队列中的数据。此外,为了进一步保证数据的一致性,还需要设计一个基于增量行的检查程序,该程序依赖于源表中的last_update_time字段,用于确保两个数据库之间的数据一致性。
对于换数据库与上云同时存在的需求,其实应该考虑分步去实施,即先完成一项再完成另一项,这样在上云的过程中可以利用同构数据库的主从同步方案,在换数据库过程中不需要考虑跨机房网络损耗问题带来的各种限制。
迭代的迁移策略
在实际情况中,数据迁移可能需要采取迭代进行的策略。例如,在云原生重构方案中,企业可以安排一部分人员对系统进行重构,同时让另一部分人员继续在旧系统中进行需求的迭代开发。支持迭代迁移的基础是前端能够灵活地支持路由策略,即前端可以同时将部分服务路由到新环境,将其他服务路由到旧环境中。前端需要支持路由策略设计见下图:
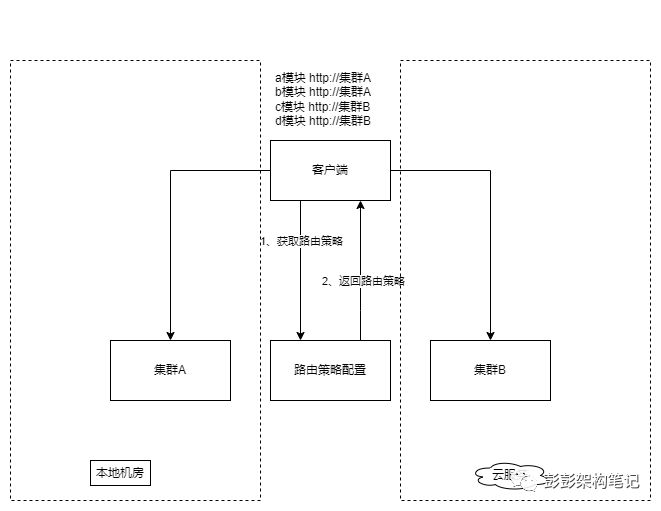
与异构数据库迁移策略相比,迭代迁移策略需要持续的周期。这种策略通常伴随着系统的重构,并且一般按照模块进行。为了更好地实施迭代迁移,对每个模块的迁移甚至可以将迁移过程分为两个步骤:非实时读业务的迁移和实时读写业务的迁移。
缓存的数据迁移策略
在进行缓存迁移时,一般不会直接迁移缓存数据,但需要考虑缓存的预热。对于中小规模的系统,也可以直接丢弃缓存数据,让新环境的系统在运行过程中逐渐生成新的缓存。然而,在高并发环境下,为了防止新环境系统在接收流量后发生缓存击穿并导致雪崩效应,我们需要进行缓存的预热。为了使预热的数据更符合实际情况,我们可以将旧环境中一定比例的写入缓存操作异步同步给新环境的缓存服务器,从而实现预热的效果。由于新缓存的更新是异步的且按比例进行,对系统性能的影响很小。

如上图,当旧环境的缓存服务发生更新时,异步地刷新环境缓存服务器的内容,这样新环境缓存服务器的数据就根据实际的数据分布提前完成了预热。