本文经自动驾驶之心公众号授权转载,转载请联系出处。
【RenderOcc,首篇仅使用2D标签训练多视图3D占用模型的新范式】作者从多视图图像中提取NeRF风格的3D体积表示,并使用体积渲染技术来建立2D重建,从而实现从2D语义和深度标签的直接3D监督,减少了对昂贵的3D占用标注的依赖。大量实验表明,RenderOcc的性能与使用3D标签完全监督的模型相当,突显了这种方法在现实世界应用中的重要性。已开源。
题目: RenderOcc: Vision-Centric 3D Occupancy Prediction with 2DRendering Supervision
作者单位: 北京大学,小米汽车,港中文MMLAB
开源地址: GitHub - pmj110119/RenderOcc
3D占用预测在机器人感知和自动驾驶领域具有重要前景,它将3D场景量化为带有语义标签的网格单元。最近的工作主要利用3D体素空间中的完整占用标签进行监督。然而,昂贵的标注过程和有时模糊的标签严重限制了3D占用模型的可用性和可扩展性。为了解决这个问题,作者提出了RenderOcc,这是一种仅使用2D标签训练3D占用模型的新范式。具体而言,作者从多视图图像中提取NeRF风格的3D体积表示,并使用体积渲染技术来建立2D重建,从而实现从2D语义和深度标签的直接3D监督。此外,作者引入了一种辅助光线方法来解决自动驾驶场景中的稀疏视点问题,该方法利用顺序帧为每个目标构建全面的2D渲染。RenderOcc是第一次尝试仅使用2D标签来训练多视图3D占用模型,从而减少了对昂贵的3D占用标注的依赖。大量实验表明,RenderOcc的性能与使用3D标签完全监督的模型相当,突显了这种方法在现实世界应用中的重要性。
网络结构:
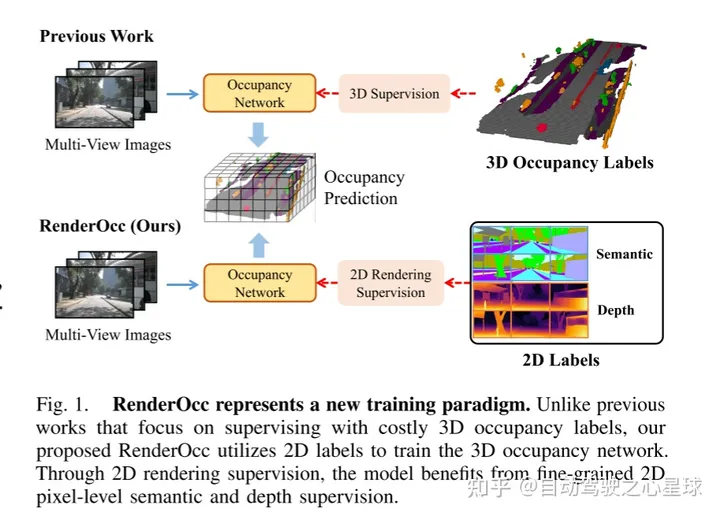
图 1.RenderOcc 代表了一种新的训练范例。与之前专注于使用昂贵的 3D 占用标签进行监督的工作不同,本文提出的 RenderOcc 利用 2D 标签来训练 3D 占用网络。通过 2D 渲染监督,该模型受益于细粒度 2D 像素级语义和深度监督。
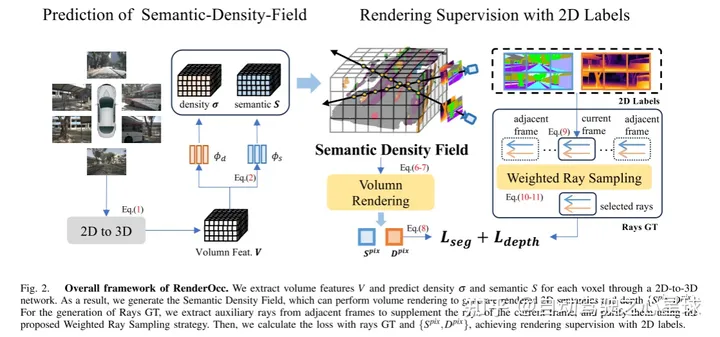
图2.RenderOcc的总体框架。本文通过 2D 到 3D 网络提取体积特征并预测每个体素的密度和语义。因此,本文生成了语义密度场(Semantic Density Field),它可以执行体积渲染来生成渲染的 2D 语义和深度。对于Rays GT的生成,本文从相邻帧中提取辅助光线来补充当前帧的光线,并使用所提出的加权光线采样策略来净化它们。然后,本文用光线 GT 和 {,} 计算损失,实现2D标签的渲染监督。
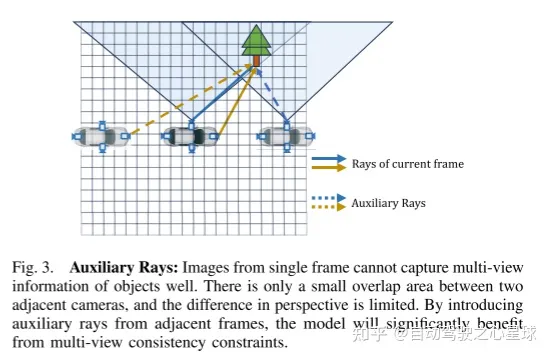
图3。辅助光线: 单帧图像不能很好地捕捉物体的多视图信息。两个相邻的相机之间只有很小的重叠区域,视角的差异是有限的。通过引入来自相邻帧的辅助光线,该模型将显著地受益于多视图一致性约束。
实验结果:
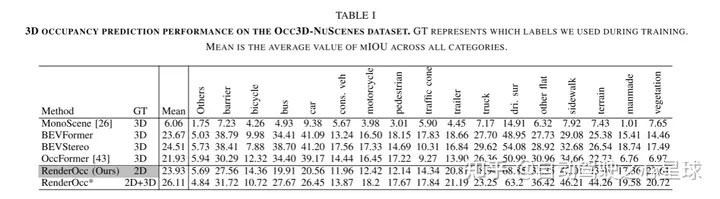
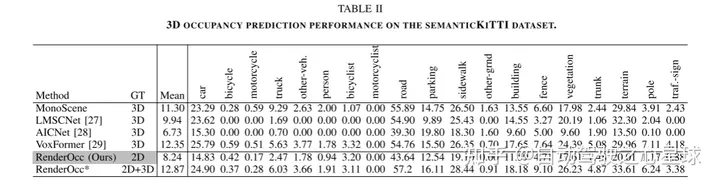
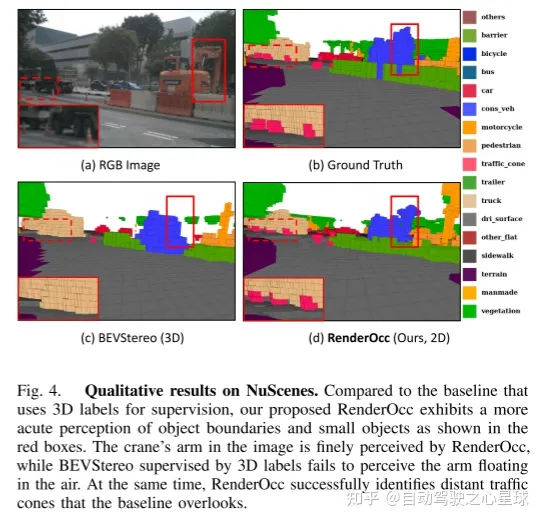
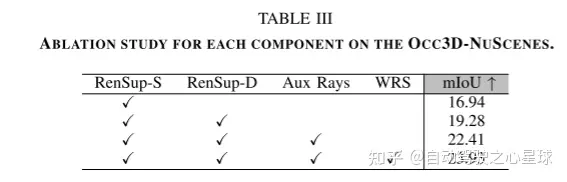
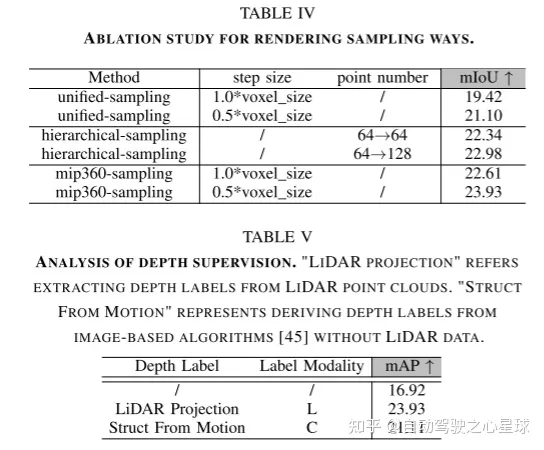
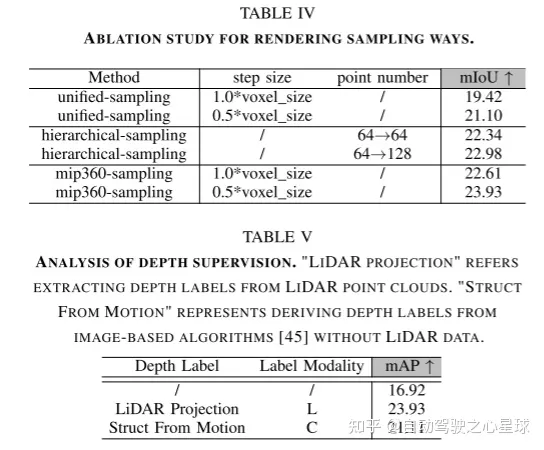
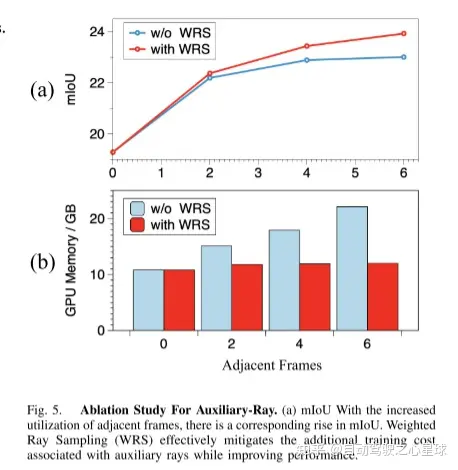

原文链接:https://mp.weixin.qq.com/s/WzI8mGoIOTOdL8irXrbSPQ