在前面一篇文章中提到过对于业务主表读写缓慢的解决方案:冷热分离,有不了解的请看:业务主表读写缓慢如何优化?
冷热分离固然是一个性价比高的解决方案,但也并不是银弹,仍然有诸多限制,比如:
- 查询冷数据慢
- 业务无法修改冷数据
- 冷数据多到一定程度系统依旧扛不住
此时如果需要解决以上问题,可以采用另外一种方案:使用 查询分离 优化业务主表数据大查询缓慢的问题
什么是查询分离?
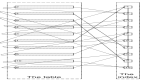
查询分离从字面上来说非常容易理解,其实就是在写数据时保存一个备份数据到另外的存储系统,在查询时直接从另外的存储系统中获取数据,如下图:
 图片
图片
查询分离
以上只是简单的架构图,其中有些细节还是需要深究,如下:
- 什么时候触发查询分离?
- 如何实现查询分离?
- 查询数据的存储系统选型?
- 查询数据如何使用?
查询分离的适用场景?
当你在实际业务中遇到以下情形,则可以考虑使用查询分离解决方案。
- 数据量大;
- 所有写数据的请求效率尚可;
- 查询数据的请求效率很低;
- 所有的数据任何时候都可能被修改;
- 业务希望我们优化查询数据的功能。
曾做过 SaaS 客服系统的架构优化,系统里有一个工单查询功能,工单表中存放了几千万条数据,且查询工单表数据时需要关联十几个子表,每个子表的数据也是超亿条。
面对如此庞大的数据量,跟前面的冷热分离一样,每次客户查询数据时几十秒才能返回结果,即便我们使用了索引、SQL 等数据库优化技巧,效果依然不明显。
工单表中有些数据是几年前的,客户说这些数据涉及诉讼问题,需要继续保持更新,因此我们无法将这些旧数据封存到别的地方,也就没法通过前面的冷热分离方案来解决。
最终我们采用了查询分离的解决方案,才得以将这个问题顺利解决:将更新的数据放在一个数据库里,而查询的数据放在另外一个系统里。因为数据的更新都是单表更新,不需要关联也没有外键,所以更新速度立马得到提升,每次客户查询数据时,500ms 内就可得到返回结果。
什么时候触发查询分离?
简单的来说就是什么时候应该保存一份数据到查询数据库中,其实也就是数据异构的过程,详细文章可以看我前面一篇文章:数据异构就该这样做,yyds~
这里介绍三种方式,如下:
- 同步建立
- 异步建立
- binlog方式
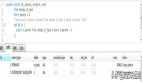
1、同步建立
修改业务代码:在写入常规数据后,同步建立查询数据。
 图片
图片
该种方案优缺点也非常明显:
优点:查询数据的一致性和实时性得到了保证
缺点:业务代码侵入比较强;减缓写操作的效率
2、异步建立
修改业务代码:写入数据后,异步建立查询数据
 图片
图片
该种方案的优缺点如下:
优点:不影响主流程
缺点:数据一致性存在问题
3、 binlog的方式
该种方案也是业界常用的一种方案,对于代码是无侵入的,通过监听数据库日志的方式建立查询数据,如下:
 图片
图片
该种方案的优缺点如下:
优点:不影响主流程;代码侵入为0
缺点:数据一致性存在问题;架构相对复杂
如何实现查询分离?
对于上述三种方案都算是比较常见的方案,对于第一种同步的方式比较简单,这里不再介绍;对于第三种binlog的方式在数据异构的文章中介绍过,详情见:数据异构就该这样做,yyds~
这篇文章来介绍一下异步的方式,异步的方式有很多,可以放在内存中进行操作,但是这有些弊端:
- 数据过多,内存有限
- 服务重启,内存数据将会丢失
因此最终我们可以选择MQ的方式,那么此时就涉及到了MQ的技术选型,这里给两个建议:
- 如果你的公司已经用了MQ,那么直接接着用即可
- 如果公司目前未引入MQ,则需要架构组考量选型了,对于MQ的选型可以看我之前文章:聊聊 MQ 技术选型
当然一旦引入了MQ还需要考虑的问题很多,如下:
1、 MQ突然宕机了怎么办?
MQ宕机意味着查询数据不能继续建立了,我们可以在写入数据的同时给该条数据加一个标志字段(已搬运、未搬运),当MQ启动后,查询所有未搬运的数据,继续建立查询数据
“
这里的方案很多,按照业务实际情况考量
”
2、消息的幂等消费
消息的幂等消费一定要保证,避免数据重复建立,比如:主数据的订单 A 更新后,我们在查询数据中插入了 A,可是此时系统出问题了,系统误以为查询数据没更新,又把订单 A 插入更新了一次。
3、消息的时序性问题
比如某个订单 A 更新了 1 次数据变成 A1,线程甲将 A1 的数据搬到查询数据中。不一会儿,后台订单 A 又更新了 1 次数据变成 A2,线程乙也启动工作,将 A2 的数据搬到查询数据中。
所谓的时序性就是如果线程甲启动比乙早,但搬运数据动作比线程乙还晚完成,就有可能出现查询数据最终变成过期的 A1
查询数据的存储系统选型?
既然为了解决表数据量大查询缓慢的问题,肯定是不能选用关系型数据库了,那么还有其他选择吗?
内存数据库虽然性能非常高,比如Redis,但是不适合海量数据,太费钱了
那么这里比较适用的有如下三种:
- MongoDB
- HBase
- Elasticsearch
这里选型还是要根据自己公司业务选择,如果已经有在用的,则直接用即可;另外就是选择自己熟悉的,比如当初我们设计架构方案时,为什么选择用 Elasticsearch,除 ES 对查询的扩展性支持外,最关键的一点是我们团队对 Elasticsearch 很熟悉。
查询数据如何使用?
查询数据很简单,每个数据库都有对应的API,直接调用查询
但是,这里有一个问题:数据查询更新完前,查询数据不一致怎么办?,给出两种方案:
- 在查询数据更新到最新前,不允许用户查询。(我们没用过这种设计,但我确实见过市面上有这样的设计。)
- 给用户提示:您目前查询到的数据可能是 1 秒前的数据,如果发现数据不准确,可以尝试刷新一下,这种提示用户一般比较容易接受。
总结
本篇文章介绍了表数据量大查询缓慢的一种解决方案:查询分离,但这也不是银弹,仍然是存在一些不足,比如表数据量大,写入缓慢怎么办?这个后面文章再介绍吧!