













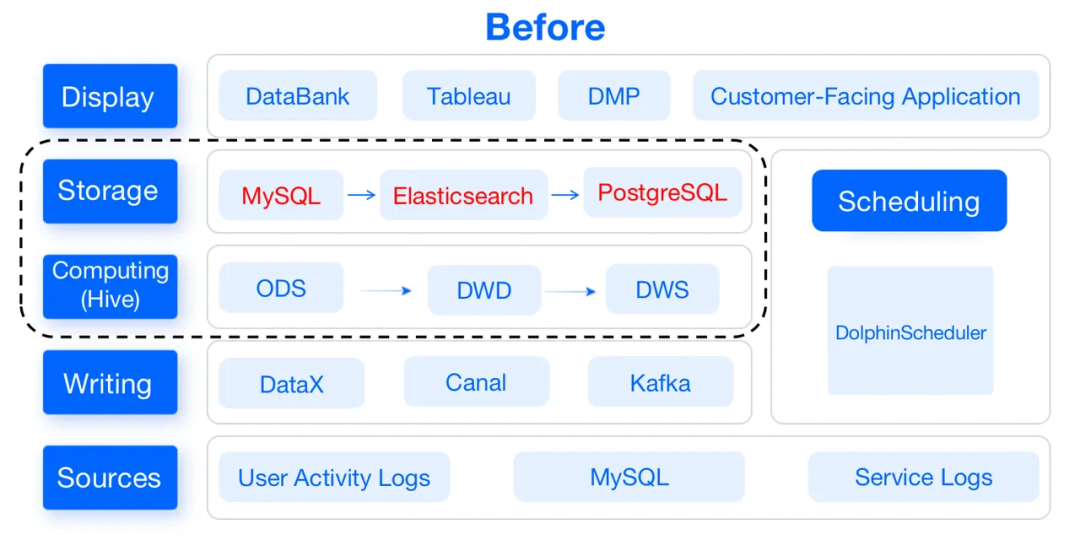
以前,数据仓库通常由Apache Hive、MySQL、Elasticsearch和PostgreSQL组成。它们支持数据仓库的数据计算和数据存储层:
- 数据计算:Apache Hive作为计算引擎。
- 数据存储:MySQL为DataBank、Tableau和我们面向客户的应用程序提供数据。Elasticsearch和PostgreSQL用于我们的DMP用户分割系统:前者存储用户分析数据,后者存储用户组数据包。
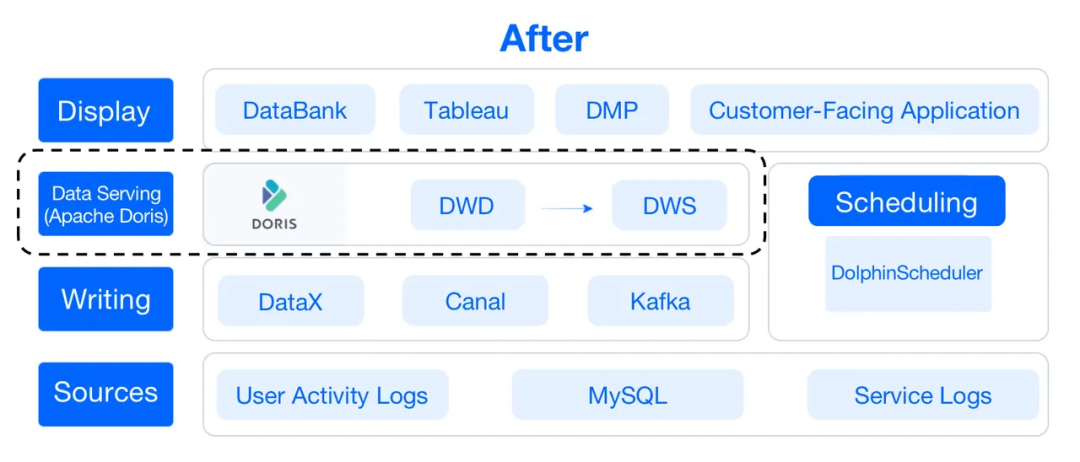
不过,这样会导致数据管道又长又复杂,需要高维护成本,并且有损于开发效率。此外,它们无法进行特定查询。因此,作为数据仓库的升级,可以用Apache Doris替换了其中大部分组件,这是一种基于MPP架构的开源分析型数据库。
1. 数据流
这是数据仓库的侧面视图,可以从中看到数据如何流动。
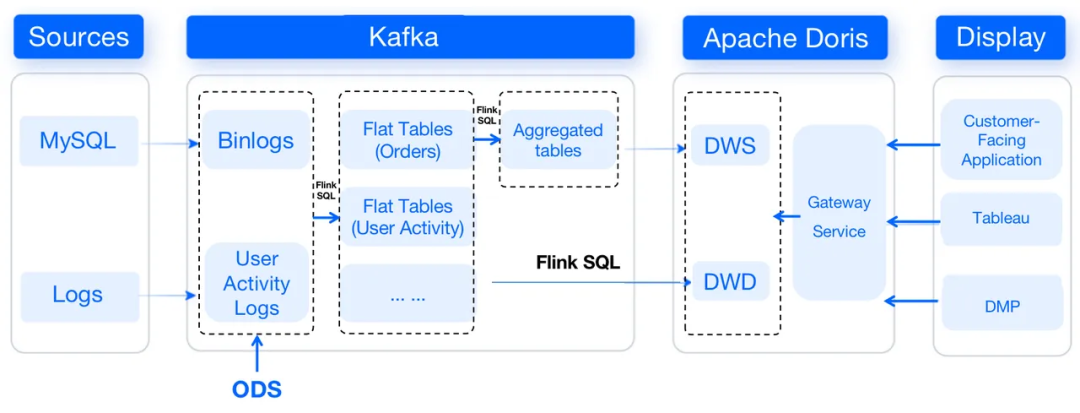
首先,MySQL的binlog将通过Canal被摄入到Kafka中,而用户活动日志将通过Apache Flume传输到Kafka中。在Kafka中,数据将被清理并组织成平面表,然后将转换为聚合表。然后,数据将从Kafka传递到Apache Doris,它充当存储和计算引擎。
我们在Apache Doris中采用不同的数据模型来处理不同的场景:来自MySQL的数据将按照Unique模型进行排列,日志数据将放在Duplicate模型中,而DWS层中的数据将合并在Aggregate模型中。
这就是Apache Doris如何取代我们数据仓库中Hive、Elasticsearch和PostgreSQL的角色。这种转变在开发和维护方面节省了我们大量的工作量。它还使特定查询成为可能,并使我们的用户分割更加高效。
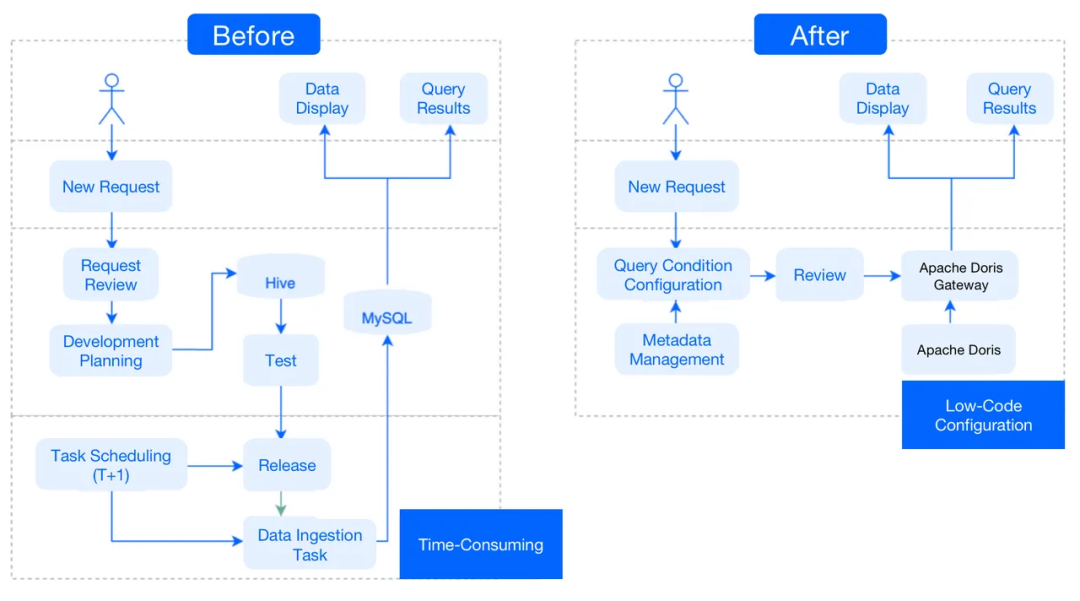
2. 临时查询
之前:每次提出新请求时,我们都会在Hive中开发和测试数据模型,并在MySQL中编写调度任务,以便我们面向客户的应用程序平台可以从MySQL读取结果。这是一个复杂的过程,需要大量时间和开发工作。
之后:由于Apache Doris拥有所有明细数据,因此每当它面临新请求时,它只需提取元数据并配置查询条件即可。然后它就可以进行特定查询了。简而言之,它只需要低代码配置即可响应新请求。
3. 用户分割
之前:基于元数据创建用户分割任务后,相关的用户ID将被写入PostgreSQL配置文件列表和MySQL任务列表中。同时,Elasticsearch将根据任务条件执行查询;在产生结果后,它将在任务列表中更新状态,并将用户组位图包写入PostgreSQL。(PostgreSQL插件能够计算位图的交集、并集和差集。)然后,PostgreSQL将为下游操作平台提供用户组数据包。
Elasticsearch和PostgreSQL中的表格无法重复使用,这使得这种架构成本效益低。此外,我们必须预定义用户标签,才能执行新类型的查询。这减慢了速度。
之后:用户ID仅会被写入MySQL任务列表中。对于第一次分割,Apache Doris将根据任务条件执行特定查询。在随后的分割任务中,Apache Doris将执行微批量滚动,并计算与先前生成的用户组数据包相比的差异集,并通知下游平台进行任何更新。(这是由Apache Doris中的位图函数实现的。)
在这个以Doris为中心的用户分割过程中,我们不必预定义新标签。相反,标签可以根据任务条件自动生成。处理管道具有灵活性,可以使我们基于用户组进行A/B测试更加容易。此外,由于明细数据和用户组数据包都在Apache Doris中,因此我们不必关注多个组件之间的读写复杂性。

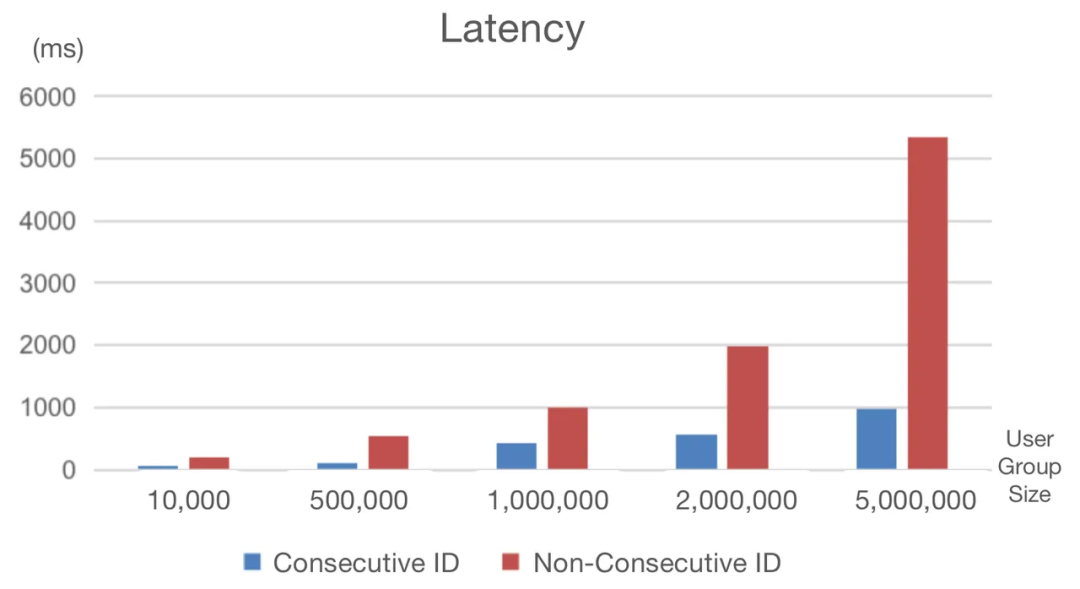
4. 提高用户分组速度的技巧,可提高70%
由于风险规避原因,随机生成user_id是许多公司的选择,但这会在用户组数据包中产生稀疏和非连续的用户ID。在用户分组中使用这些ID,我们必须忍受等待位图生成的漫长时间。
为了解决这个问题,我们为这些用户ID创建了连续和密集的映射。通过这种方式,我们将用户分组延迟降低了70%。

5. 示例
步骤1:创建用户ID映射表
我们采用唯一模型用于用户ID映射表,其中用户ID是唯一键。映射的连续ID通常从1开始严格递增。

步骤2:创建用户组表:
我们采用聚合模型用于用户组表,其中用户标签作为聚合键。

假设我们需要挑选出ID在0到2000000之间的用户。
以下代码段分别使用非连续(tyc_user_id)和连续(tyc_user_id_continuous)用户ID进行用户分组。它们的响应时间之间存在很大差距:
- 非连续用户ID:1843ms
- 连续用户ID:543ms

6. 总结
我们在Apache Doris中拥有2个容纳数十TB数据的集群,每天几乎有10亿行新数据流入。随着数据量的扩大,我们曾经目睹数据摄入速度急剧下降。但是,在使用Apache Doris升级数据仓库后,我们将数据写入效率提高了75%。此外,在结果集小于500万的用户分组中,它能够在毫秒内响应。最重要的是,我们的数据仓库对开发人员和维护人员更加简单和友好。























