













作者 | 崔皓
审校 | 重楼
摘要
本文探讨了知识图谱与大型语言模型如何联手提升行业应用。你将了解知识图谱的开发流程,尤其是实体识别、关系抽取和图的构建三个关键环节。通过实战示例,文章将展示如何利用自然语言处理(NLP)和大型语言模型生成知识图谱。此外,文章还将介绍一个开源的知识图谱项目GraphGPT。
开篇
众所周知,知识图谱是一种以图结构组织和表示信息或知识的方式。在这样的结构中,节点表示实体(如人、地点、事物等),边则代表实体之间的各种关系。知识图谱能够帮助我们更有效地组织和检索信息,从而在搜索、推荐系统、自然语言理解和多种应用场景中发挥关键作用。随着大模型发展愈来愈快,利用大模型生成知识图谱的方式也悄然兴起。本文通过实战的方式带大家利用大语言模型生成知识图谱。
知识图谱的应用与开发
知识图谱的应用
说起知识图谱可能大家并不陌生,它在各个领域都发挥着重要的作用。
1. 医疗健康
疾病诊断与治疗: 通过分析疾病、症状、药物之间的关系,知识图谱可以帮助医生做出更准确的诊断和治疗方案。
药物研发: 知识图谱可以整合各种生物医学信息,加速新药的研发过程。
2. 金融行业
风险管理与评估: 知识图谱能够整合个人或企业的多维度信息,从而更准确地评估贷款或投资的风险。
反欺诈: 通过分析交易模式和行为,知识图谱可以有效地检测和预防欺诈活动。
3. 电商和推荐系统
个性化推荐:知识图谱可以根据用户行为和偏好,以及商品属性进行更精准的个性化推荐。
供应链优化: 通过分析供应链中各环节的数据,知识图谱可以帮助企业优化存货管理和物流。
知识图谱的开发
知识图谱通过连接庞大且复杂的数据点,为多个行业提供了高度相关和实用的洞见。这使得它成为现代信息时代不可或缺的一部分。
知识图谱开发过程也比较繁琐,需要经过如下步骤:
数据收集: 从各种来源(如文本、数据库、网站等)收集原始数据。
数据清洗: 对收集的数据进行预处理,包括去除噪声、标准化等。
实体识别: 识别文本中的重要实体(如名词或专有名词)。
关系抽取: 确定实体之间的关系(如“是”、“有”、“属于”等)。
构建图: 使用识别出的实体和关系构建知识图谱。
验证与更新: 通过人工或自动方式对知识图谱进行验证和动态更新。
三元组
虽然上述过程的每个步骤都很重要,但是“实体识别”,“关系抽取”,“构建图”这三个步骤是整个开发过程的重中之重。我们需要使用三元组的方式完成识别,抽取和构建。
在大语言模型如GPT或BERT出现之前,知识图谱主要依赖于规则匹配、词性标注、依存解析和各类机器学习方法来抽取三元组(实体1、关系、实体2)。这些传统方法各有优缺点,如需大量人工规则、标记数据或计算资源,泛化能力和准确性也有限。
例如:对下面三句话进行三元组的抽取
1. 小红是我的同学。
2. 小红是小明的邻居。
3. 小明是我的篮球队队友。
我可以使用NLP方式对其进行处理,代码如下:
这里对代码稍微做一下解释:
- 先初始化一个空的triplets列表,用于存放抽取出来的三元组。
- 然后,定义了一个sentences列表,包含三个待处理的句子。
- 使用for循环遍历这些句子。
- 使用SnowNLP对每个句子进行自然语言处理。
- 通过s.tags获取词性标注,并抽取出名词('n')和人名('nr')以及动词('v')。
- 如果一个句子中包含至少三个这样的词(两个实体和一个关系),则形成一个三元组并添加到triplets列表中。
上述代码结果如下:
通过结果可以看出自然语言处理(NLP)任务存在的问题:
1. 三元组的构造不准确:例如第一个三元组`('是', '邻居', '小明')`,其中“是”并不是一个实体,而应该是一个关系。
2. 丢失了一些关键信息:例如第三个句子"我和小明是篮球队的队友"并没有正确抽取为三元组。
这些问题揭示了一般NLP任务(尤其是基于规则或浅层NLP工具的任务)存在的一些局限性:
1. 词性标注和句法分析的不准确性:依赖于词性标注和句法分析工具的准确性,一旦工具出错,后续的信息抽取也会受到影响。
2. 缺乏深度语义理解:仅仅通过词性标注和浅层句法分析,难以准确地抽取复杂或模糊的关系。
3. 泛化能力差:对于不同类型或结构的句子,可能需要不断地调整规则或模型。
4. 对上下文信息的利用不足:这种方法通常只考虑单个句子内的信息,而忽视了上下文信息,这在复杂文本中是非常重要的。
大语言模型如何助力知识图谱
大语言模型,如GPT或BERT,是基于深度学习的自然语言处理模型,具有出色的文本理解和生成能力。它们能够理解自然语言,从而使复杂的查询和推理变得更加简单。相比于传统方法,大模型有以下几点优势:
- 文本理解能力:可以准确地抽取和理解更复杂、模糊或多义的实体和关系。
- 上下文敏感性:大模型能够理解词语在不同上下文中的不同含义,这对于精准抽取实体和关系至关重要。这种上下文敏感性让模型能够理解复杂和模糊的句子结构。
- 强大的泛化能力:由于在大量多样化数据上进行了训练,这些模型能够很好地泛化到新的、未见过的数据。这意味着即使面对具有复杂结构或不常见表达方式的文本,它们也能准确地进行实体和关系抽取。
同样的例子,我们看看大模型是如何做的。代码如下:
上面这段代码用于构建知识图谱。它用到了三个主要的模块:`OpenAI`、`GraphIndexCreator` 和 `GraphQAChain`,以及一个辅助类:`KnowledgeTriple`。主要内容包括:
- OpenAI 初始化:`llm = OpenAI(model_name="gpt-3.5-turbo")` 。初始化了 `gpt-3.5-turbo` 的大型语言模型(LLM)。
- 输入文本:`texts = '小红是我的同学。小红是小明的邻居。小明是我的篮球队队友。'` 定义要处理的文本,其中包含多个句子。
- 创建图谱索引:`index_creator = GraphIndexCreator(llm=llm)` 使用 `GraphIndexCreator` 类来创建一个图索引生成器,它会用到先前初始化的大型语言模型。
- 初始化最终图:`final_graph = f_index_creator.from_text('')` 初始化了一个空的知识图谱,用于存放最终的三元组信息。
- 文本切割和三元组生成: `for text in texts.split("."):`这个循环通过句号切割文本,然后对每一个非空句子生成三元组。
- `triples = index_creator.from_text(text)`通过 `index_creator` 的 `from_text` 方法,为每个句子生成三元组。
- 三元组存储和输出:`final_graph.add_triple(KnowledgeTriple(node1, node2,relation ))`将生成的三元组添加到 `final_graph` 知识图谱中。
下面是运行结果:
看起来是不是比上面NLP处理的结果要好些。
如果我们将texts变量进行修改:
用一个特别复杂的例子来表示,这个例子是我们虚拟的一个国家,并且描述了和这个国家相关的一些其他国家,看上去比较复杂。此时,我们加入图表的方式,通过节点和边展示这样的复杂关系。加入如下代码:
这段代码使用了`networkx`和`matplotlib.pyplot`库来可视化一个有向图(即知识图谱),其中的节点和边是从之前抽取的三元组(实体-关系-实体)中得到的。
1. 创建空的有向图: `G = nx.DiGraph()`
2. 添加边到图中:
`G.add_edges_from((source, target, {'relation': relation}) for source, relation, target in final_graph.get_triples())`
把之前从文本中抽取出的三元组添加到图`G`中作为边。每一条边都有一个起点(`source`),一个终点(`target`)以及一个表示两者关系的标签(`relation`)。
3. 设置图像大小和分辨率:
`plt.figure(figsize=(8,3), dpi=500)`
设置了图像的大小(8x3)和分辨率(500 DPI)。
4. 定义节点布局:
`pos = nx.spring_layout(G, k=3, seed=0)`
使用“spring”布局算法来确定图中每个节点的位置。`k`是一个用于设置节点间距的参数,`seed`是随机数生成器的种子。
5. 获取边标签并绘制:
`edge_labels = nx.get_edge_attributes(G, 'relation')`
`nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_size=8, font_family='simhei')`
获取了图中每一条边的标签(即`relation`)并进行了绘制。
6. 绘制图:
`nx.draw_networkx(G, font_family = 'simhei')`
绘制了整个图,其中使用了`simhei`字体以支持中文字符。
7. 关闭坐标轴显示并展示图像:
`plt.axis('off')`
`plt.show()`
关闭了坐标轴的显示,并展示了最终的图像。
看看结果如何:
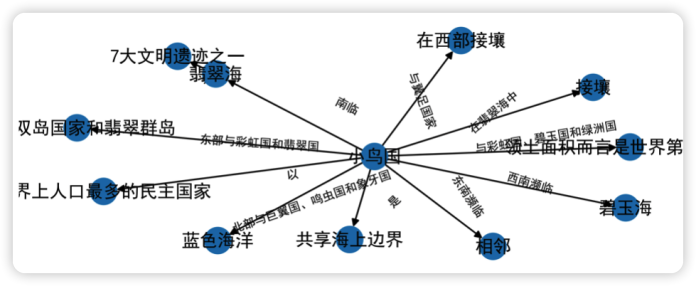
生成的知识图谱围绕着小鸟国把与之相关的地方都连接起来了。
接着针对上面的知识图谱提出问题,如下代码:
结果返回:
知识图谱通过三元组的方式告诉我们 “翡翠海”(实体1),“7大文明遗迹之一”(实体2),“是”(关系)。
开箱即用的GraphGPT
有了上面的实战经验,告诉我们利用大模型能够更好地进行知识图谱的处理,并且可以针对知识图谱的内容进行提问。如果觉得自己开发这样一套系统比较麻烦的同学,可以尝试使用Github上面开源的GraphGPT。
我把地址放在这里,https://github.com/varunshenoy/GraphGPT
GraphGPT 是一个用于将非结构化自然语言转换成知识图谱的项目。它可以接受各种类型的输入,例如电影剧情梗概、维基百科页面或视频转录,然后生成一个可视化图表来展示实体(Entities)之间的关系。GraphGPT 支持连续的查询,可以用于更新现有图谱的状态或创建全新的结构。
安装步骤
下载依赖项
运行npm install 来下载所需的依赖,当前只需要react-graph-vis。
获取OpenAI API密钥
确保您拥有一个OpenAI API密钥,这将用于在运行查询时输入。
启动项目
运行npm run start,GraphGPT应该会在新的浏览器标签页中打开。
通过这些步骤,您应该能够运行GraphGPT并开始将自然语言文本转换为知识图谱。
运行代码
根据上面的步骤运行代码之后,会在本地http://localhost:3000 打开一个网站,网站中需要输入知识图谱的文本,以及OpenAI 的Key。
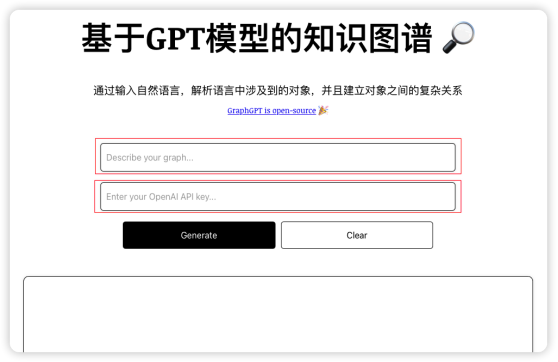
我们尝试输入要生成知识图谱的文字,然后点击“Generate”按钮,然后生成图形的关系。

代码描述
这个开源项目是通过js 实现了大模型的调用,从而生成知识图谱。从下图的代码结构上看,主要的业务逻辑在App.js 文件和prompts 目录下面。
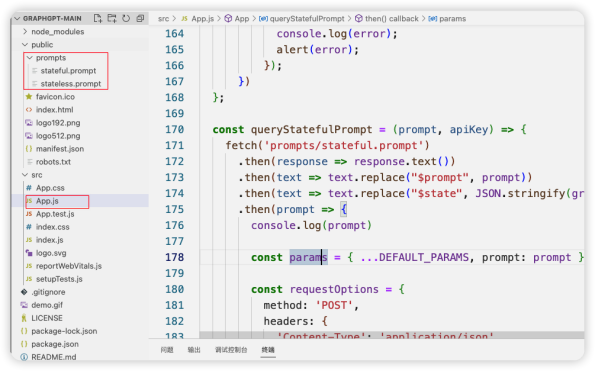
在这个React应用中,主要的目的是通过GPT模型生成一个基于输入自然语言的知识图谱。我们把主要的函数(App.js)进行解释:
- 导入依赖import './App.css'; // 导入CSS样式import Graph from "react-graph-vis"; // 导入react-graph-vis库,用于图的可视化
import React, { useState } from "react"; // 导入React和useState钩子 - 定义常量const DEFAULT_PARAMS = {...}; // GPT模型的默认参数
const SELECTED_PROMPT = "STATELESS"; // 默认使用的提示类型const options = {...}; // 图的布局和样式选项 - 主要函数组件 - Appfunction App() { const [graphState, setGraphState] = useState({...}); // 使用useState管理图的状态
const clearState = () => {...}; // 清除图的状态
const updateGraph = (updates) => {...}; // 更新图的状态
const queryStatelessPrompt = (prompt, apiKey) => {...}; // 查询无状态的提示
const queryStatefulPrompt = (prompt, apiKey) => {...}; // 查询有状态的提示
const queryPrompt = (prompt, apiKey) => {...}; // 根据选择的提示类型进行查询
const createGraph = () => {...}; // 创建图 return (<div className='container'> ... </div>); // 返回应用的JSX结构
} - 清除图的状态 - clearStateconst clearState = () => {
setGraphState({
nodes: [],
edges: []
});
};
这个函数清除图的所有节点和边。 - 更新图的状态 - updateGraphconst updateGraph = (updates) => {
var current_graph = JSON.parse(JSON.stringify(graphState)); // 深拷贝当前图的状态
// ...
setGraphState(current_graph); // 设置新的图状态
};
这个函数负责根据提供的更新信息(节点、边、颜色等)来更新图的状态。 - 与GPT API进行交互 - queryStatelessPrompt 和 queryStatefulPrompt这两个函数与GPT模型进行交互,获取模型生成的文本,并用这些信息更新图。
- 创建图 - createGraph
这个函数获取用户输入的提示和API密钥,然后调用`queryPrompt`函数生成图。
另外,又针对两种prompt状态生成两种不同的prompt文件:stateful.prompt和stateless.prompt都用于处理知识图谱中的实体和关系。stateful.prompt是状态感知的,会根据当前图的状态来添加或修改节点和边。适用于需要持续更新的场景。相对地,stateless.prompt是无状态的,只根据给定的提示生成一系列更新,与当前图的状态无关。适用于一次性或独立的更新任务。两者主要的区别在于是否需要考虑图的当前状态。
总结
文章阐述了知识图谱和大模型在现代信息处理和决策中无可替代的地位。从医疗诊断到金融风险评估,再到个性化推荐,知识图谱展示了其强大的应用潜力。同时,大型语言模型如GPT也在知识图谱的生成和查询中扮演了关键角色。借助大语言模型可以高效地创建知识图谱,还能灵活地进行实时更新和查询。本文对于任何希望将大数据和AI技术融入实际应用的人来说,都具有指导意义。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。

























