基于大型语言模型(LLM),开发者或用户可以通过描述任务,并给出几个样例来构造自然语言提示,很轻松地就能实现指定的功能。
不过从某种程度上来说,相比传统的、面向任务开发的NLP系统,大型语言模型在计算资源需求等方面是一种极大的退步。
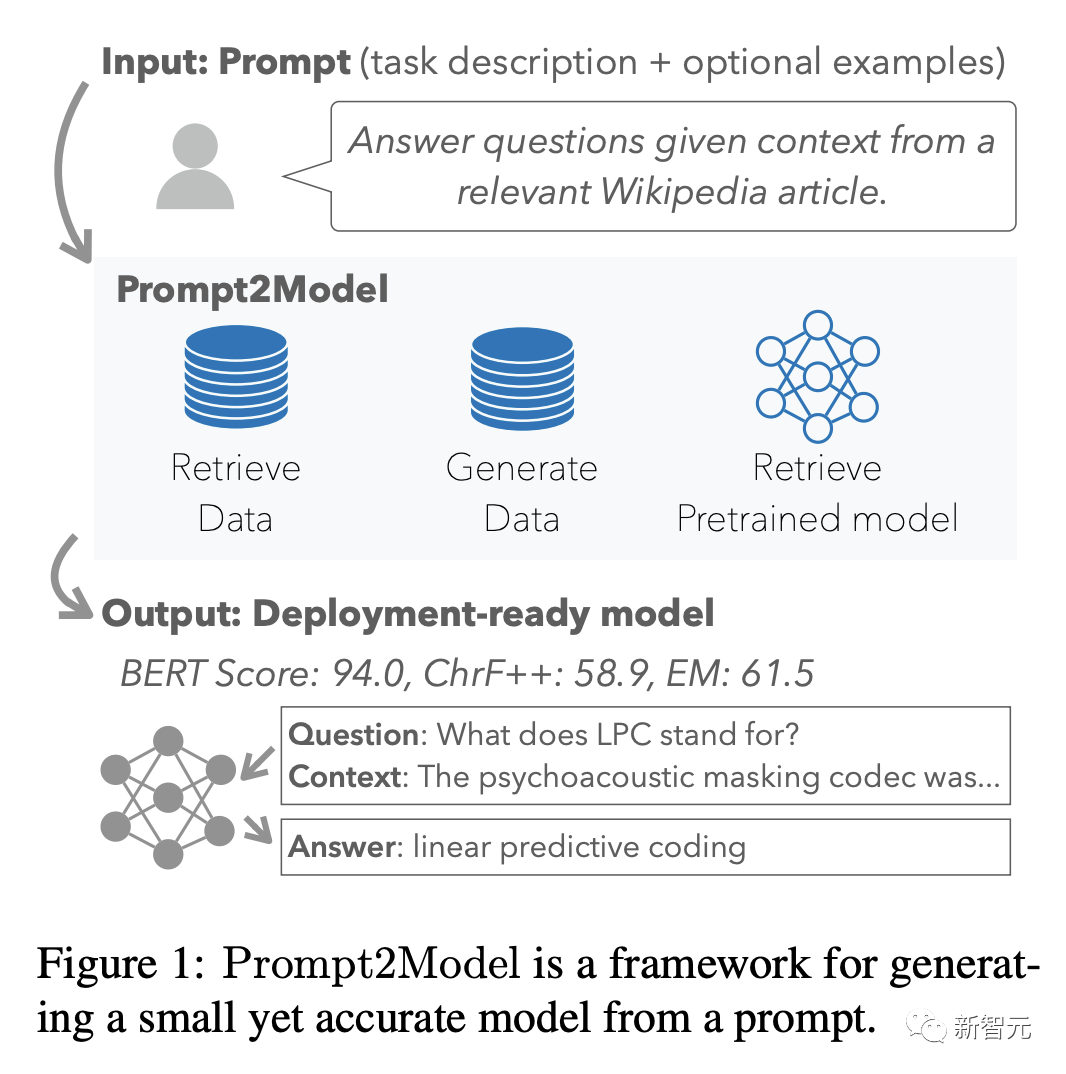
最近,卡内基梅隆大学和清华大学的研究人员提出了一种通用的模型构造方法Prompt2Model,开发者只需要构造自然语言提示,就可以训练出一个可用于指定任务的模型,并易于部署。

论文链接:https://arxiv.org/abs/2308.12261
代码链接:https://github.com/neulab/prompt2model
Prompt2Model框架包括检索现有的数据集、生成训练数据、搜索与训练模型、微调训练、自动化评估和部署等多个步骤。
三个任务的实验结果证明,给出相同的少样本提示作为输入,Prompt2Model可以训练出一个比大型语言模型更强的小模型,在参数量仅为gpt-3.5-turbo的1/700的情况下,实现了20%的性能提升。
Prompt2Model框架
Prompt2Model系统相当于一个平台,可以对机器学习管道中的组件进行自动化:包括数据收集、模型训练、评估和部署。
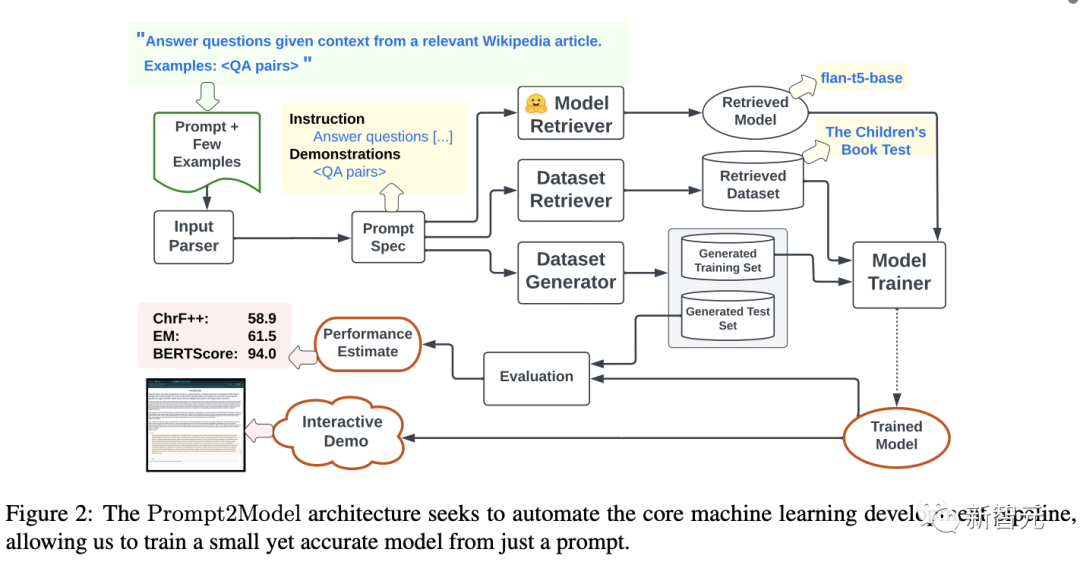
系统的核心是自动数据收集系统,利用数据集检索和基于LLM的数据集生成来获取与用户需求相关的标注数据;
然后检索预训练模型,并在收集到的训练数据上进行微调;
最后使用相同数据集下的划分测试集,对得到的模型进行评估,也可以创建一个与模型交互web UI
Prompt2Model非常通用,设计上也遵循模块化、可扩展,每个组件都可以由开发者进行重新实现或禁用。
下面介绍Prompt2Model各个组件的设计思路,以及文章作者给出的参考实现。
提示解析器(Prompt Parser)
作为系统的主要输入,用户需要提供类似LLMs使用的提示词,包括指令,或是预期回复的几个演示样例。
开放式的接口(open-ended interface)对用户来说很方便,并且端到端(end-to-end)机器学习管道也会从提示解析器中受益,例如将提示分割成指令、单独的演示样例,或是将指令翻译成英语。
参考实现:研究人员将提示解析为指令(instruction)和演示(demonstration),其中指令表示主要的任务或目标,演示代表模型的预期行为。
可以利用具有上下文学习能力的大型语言模型(OpenAI gpt-3.5-turbo-0613)对用户提示进行分割;如果用户指令被识别为非英语,则使用DeepL API.2将其翻译成英语。
数据集检索器(Dataset Retriever)
用户给出一个提示后,系统首先会进行检索,尝试发现那些符合用户描述,且已经标注好的数据集,主要包括三个决策:
1. 要搜索哪些数据集?
2. 如何对数据集索引以支持搜索?
3. 哪些数据集是用户任务所需要的,哪些应该被省略?
参考实现:研究人员先在Huggingface上,为所有的数据集提取用户描述,然后利用DataFinder的双编码检索器对数据集进行相关度排序。
然后系统会向用户展示排名靠前的k(=25)个数据集,用户可以选择相关数据集,也可以声明没有适合目标任务的数据;如果存在可用数据,用户还需要从数据集的模式中指定输入和输出列。
数据集生成器(Dataset Generator)
并不是所有的用户任务都有完美匹配的数据集,但有些数据与任务在一定程度上是相关的。
为了支持更广泛的任务,根据提示解析器得到的用户要求,可以用数据集生成器来产生「合成训练集」,主要难点在于如何降低成本、提升生成速度、生成样本多样性以及质量控制。
参考实现中,研究人员设计的策略包括:
1. 高多样性的少样本提示
使用自动化提示工程来生成多样化的数据集,用先前生成的示例的随机样本来扩充用户提供的演示示例,以促进多样性并避免生成重复的示例。
生成200个问答样本时,该策略可以将重复样本从200降低到25个。
2. 温度退火(Temperature Annealing)
根据已经生成的示例数量,将采样温度从低(输出结果更确定)调整到高(输出更随机),有助于保持输出质量,同时会促进数据多样化。
3. 自洽解码(Self-Consistency Decoding)
鉴于LLM可能为相同的输入产生非唯一或不正确的输出,研究人员使用自洽过滤(self-consistency filtering)来选择伪标签,具体来说,通过选择最频繁的答案,为每个唯一的输入创建一个一致的输出;在平局的情况下,启发式地选择最短的答案,可以提高生成数据集的准确性,同时确保样本的唯一性。
4. 异步批处理(Asynchronous Batching)
API请求使用zeno-build进行并行化,引入额外的机制,如动态批大小和节流(throttling)来优化API的用量。
模型检索器(Model Retriever)
除了训练数据外,完成任务还需要确定一个合适的模型进行微调,研究人员认为这也是一个检索问题,每个模型可以由一段「用户生成的描述」和「元数据」(如受欢迎度、支持的任务等)。
参考实现:为了用统一的模型接口支持海量任务,所以研究人员将系统限制在Huggingface上的编码器解码器架构,对于模型蒸馏来说数据效率更高。

然后使用用户指令作为查询,基于Huggingface上模型的文本描述进行搜索,不过由于模型的描述通常很少,且包含大量模式化文本,通常只有几个词能表示模型的内容。
遵照HyDE框架,先使用gpt-3.5-turbo根据用户的指示创建一个假设模型描述(hypothetical model description)作为扩展查询,然后用BM25算法计算查询模型的相似度分数。
为了确保模型易于部署,用户可以设定模型的尺寸阈值(默认3GB),并过滤掉所有超过该阈值的模型。
一般来说,高下载量的模型可能质量也更高,也可以把下载量当作参数对模型进行排序:
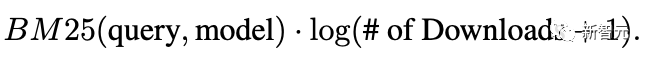
模型训练器(Model Trainer)
给定数据集和预训练模型后,就可以对模型进行训练、微调,其中所有的任务都可以当作是文本到文本的生成任务。
参考实现:在处理数据集时,研究人员会用到两个数据集,一个是生成的,另一个是检索到的,并将数据列文本化后与用户指令合并到一起添加到模型输入中。
在微调时,将两个数据集组合起来后随机打乱,然后训练学生模型。
在所有的任务中都使用相同的超参数,使用AdamW优化器,以学习率5e-5训练3个epoch,每个任务大约需要一小时。
模型评估器(Model Evaluator)
除去用作训练模型的数据后,其余数据可以用来评估模型的训练效果,主要难点在与如何在海量的目标任务中选择出合适的评估指标。
参考实现:研究人员选择三个通用的指标,即精确匹配、ChrF++和BERScore对所有任务实现自动化评估。
精确匹配(EM)可以衡量模型输出与参考答案之间完美匹配的程度;ChrF++可以平衡精确度和召回率来评估文本生成质量;BERTScore可以通过比较嵌入空间中的模型输出和引用来捕获语义相似性。

使用XLM-R作为BERTScore的编码器可以支持多语言任务的评估。
演示创建器(Demo Creator)
为了让开发者可以将模型发布给普通用户,可以在该模块中创建一个图形接口以供交互。
参考实现:研究人员使用Gradio构建了一个模型访问界面。
实验部分
实验设置
作为概念验证,研究人员测试了该系统在三项任务中学习模型的能力:
1. 机器阅读问题回答:使用SQuAD作为基准数据集来评估。
2. 日语NL-to-Code:从日语查询中生成代码是一个有难度的任务,虽然之前有相关工作,但没有可用的标注数据或与训练模型,使用MCoNaLa进行评估。
3. 时态表达式规范化(Temporal Expression Normalization):目前没有任何类型的预训练模型或训练数据集可用,使用Temporal数据集作为基准评估。
虽然Prompt2Model提供了自动模型评估的能力,在生成和检索的数据测试上,但在这里使用真实的基准数据集来衡量我们的管道训练准确模型的能力。
在基线模型的选取上,由于该工作的主要目标就是训练一个小模型可以与大型语言模型相匹配或是更强,所以研究人员选择gpt-3.5-turbo作为基准数据集的对比基线。
实验结果
在下游任务中的表现上,Prompt2Model在三个任务中的两个都实现了远超gpt-3.5-turbo的性能。
值得注意的是,检索到的SQuAD和Temporal模型是Flan-T5,仅有250M的参数量,比gpt-3.5-turbo(175B参数)小700倍。
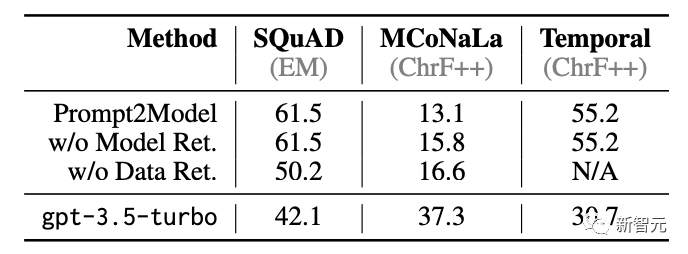
还可以观察到,Prompt2Model在MCoNaLa的日语转Python任务上的性能明显比gpt-3.5-turbo差。
可能的解释是,生成的日语查询数据集多样性相对较低:5000个样本中有45个都是「在数字列表中找到最大值」的不同说法,而在其他数据集中没有观察到这种高的冗余度,表明gpt-3.5-turbo可能很难为非英语的语言生成多样化的文本。
另一个原因可能是缺乏合适的学生模型,模型型检索器找到的模型是在多种自然语言或代码上训练的,没有都是多语言的,导致预训练模型缺乏表征日语输入、Python输出相关的参数知识。