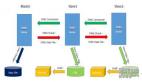
使用和配置主从复制,能使得从 Redis 服务器( slave)能精确得复制主 Redis 服务器( master)的内容。每次当 slave 和 master 之间的连接断开时, slave 会自动重连到 master 上,并且无论这期间 master 发生了什么, slave 都将尝试让自身成为 master 的精确副本。

主从复制的配置要点:
- 配从库不配主,从库配置:slaveof 主库IP 主库端口
- 查看redis的配置信息:info replication
这个系统的运行依靠三个主要的机制:
- 当一个 master 实例和一个 slave 实例连接正常时, master 会发送一连串的命令流来保持对 slave 的更新,以便于将自身数据集的改变复制给 slave :包括客户端的写入、key 的过期或被逐出等等。
- 当 master 和 slave 之间的连接断开之后,因为网络问题、或者是主从意识到连接超时, slave 重新连接上 master 并会尝试进行部分重同步:这意味着它会尝试只获取在断开连接期间内丢失的命令流。
- 当无法进行部分重同步时, slave 会请求进行全量重同步。这会涉及到一个更复杂的过程,例如 master 需要创建所有数据的快照,将之发送给 slave ,之后在数据集更改时持续发送命令流到 slave 。
主从复制的简单性质:
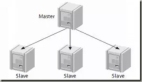
- 一个master可以有多个slave
- 每个slave只能有一个master
- 每个slave也可以有自己的多个slave
- 数据流是单向的,从master到slave
主从复制的缺点:
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave服务器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
如果master宕机了,默认情况下不会在slave节点中自动选择一个master(不能进行写操作),所以有哨兵和集群的概念。
Redis为什么需要主从复制
使用Redis主从复制的原因主要是单台Redis节点存在以下的局限性:
- Redis虽然读写的速度都很快,单节点的Redis能够支撑QPS大概在5w左右,如果上千万的用户访问,Redis就承载不了,成为了高并发的瓶颈。
- 单节点的Redis不能保证高可用,当Redis因为某些原因意外宕机时,会导致缓存不可用。
- CPU的利用率上,单台Redis实例只能利用单个核心,这单个核心在面临海量数据的存取和管理工作时压力会非常大。
Redis主从复制的策略
从总体上来说,Redis主从复制的策略就是:当主从服务器刚建立连接的时候,进行全量同步;全量复制结束后,进行增量复制。当然,如果有需要,slave 在任何时候都可以发起全量同步。
主从全量复制的流程:
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份,具体步骤如下:
- slave服务器连接到master服务器,便开始进行数据同步,发送psync命令(Redis2.8之前是sync命令)
- master服务器收到psync命令之后,开始执行bgsave命令生成RDB快照文件并使用缓存区记录此后执行的所有写命令
- -如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是每个连接都执行一次,然后再把这一份持久化的数据发送给多个并发连接的slave。如果RDB复制时间超过60秒(repl-timeout),那么slave服务器就会认为复制失败,可以适当调节大这个参数
- master服务器bgsave执行完之后,就会向所有Slava服务器发送快照文件,并在发送期间继续在缓冲区内记录被执行的写命令
- client-output-buffer-limit slave 256MB 64MB 60,如果在复制期间,内存缓冲区持续消耗超过64MB,或者一次性超过256MB,那么停止复制,复制失败
- slave服务器收到RDB快照文件后,会将接收到的数据写入磁盘,然后清空所有旧数据,在从本地磁盘载入收到的快照到内存中,同时基于旧的数据版本对外提供服务。
- slave服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
- 如果slave 节点开启了AOF,那么会立即执行BGREWRITEAOF,重写AOF

增量复制:
Redis的增量复制是指在初始化的全量复制并开始正常工作之后,master服务器将发生的写操作同步到slave服务器的过程,
增量复制的过程主要是master服务器每执行一个写命令就会向slave服务器发送相同的写命令,slave服务器接收并执行收到的写命令。
断点续传:
什么是断点续传:
slave与master能够在网络连接断开重连后,只从中断处继续进行复制,而不必重新同步,这就是所谓的断点续传。
断电续传这个新特性使用psync命令,master服务器收到slave发送的psync命令后,会根据自身的情况做出对应的处理,可能是FULLRESYNC runid offset触发全量复制,也可能是CONTINUE触发增量复制
命令格式:psync runid offset
3.2、工作原理:
(1)master服务器在内存缓冲区中给每个slave服务器都维护了一份同步备份日志(in-memory backlog),缓存最近一段时间的数据,默认大小1m,如果超过这个大小就会清理掉。
(2)同时,master 和 slave 服务器都维护了一个复制偏移量(replication offset)和 master线程ID(master run id),每个slave服务器在跟master服务器进行同步时都会携带master run id 和 最后一次同步的复制偏移量offset,通过offset可以知道主从之间的数据不一致的情况。
(3)当连接断开时,slave服务器会重新连接上master服务器,然后请求继续复制。假如主从服务器的两个master run id相同,并且指定的偏移量offset在同步备份日志中还有效,复制就会从上次中断的点开始继续。如果其中一个条件不满足,就会进行完全重新同步,因为主运行id不保存在磁盘中,如果从服务器重启的话就只能进行完全同步了。
master服务器维护的offset是存储在backlog中,msater就是根据slave发送的offset来从backlog中获取数据的。
(4)在部分同步过程中,master会将本地记录的同步备份日志中记录的指令依次发送给slave服务器从而达到数据一致。
什么是run_id
run_id是Redis 服务器的随机标识符,用于 Sentinel 和集群,服务重启后就会改变;
当slave节点复制时发现和之前的 run_id 不同时,将会对数据进行全量同步。
查看runid
redis-cli -p 6379 info server | grep run
run_id:345dda992e5064bc80e01f96ea90f729b722b2ea什么是偏移量:
通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
- 参与复制的主从节点都会维护自身的复制偏移量。主节点(master)在处理完写命令后,会把命令的字节长度做累加记录,统计信息在info replication中的master_repl_offset指标中。
- 从节点每秒上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量
- 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计在info replication中的slave_repl_offset指标中
无磁盘化复制:
在前面全量复制的过程中,master会将数据保存在磁盘的rdb文件中然后发送给slave服务器,但如果master上的磁盘空间有限或者是使用比较低速的磁盘,这种操作会给master服务器带来较大的压力,那怎么办呢?在Redis2.8之后,可以通过无盘复制来达到目的,由master直接开启一个socket,在内存中创建RDB文件,再将rdb文件发送给slave服务器,不使用磁盘作为中间存储。(无盘复制一般应用在磁盘空间有限但是网络状态良好的情况下)
repl-diskless-sync :是否开启无磁盘复制
repl-diskless-sync-delay:等待一定时长再开始复制,因为要等更多slave重新连接过来主从复制实现:
主从复制命令:
#在希望成为slave的节点中执行命令(改换门庭)
slaveof ${masterIP} ${masterPort}
#此过程会异步第将master节点中的数据全量复制到当前节点中(如果使用命令模式,只有当次生效,例:重启)
#主从复制(配从库,不配主库
repliceof ${masterIP} ${masterPort}
#在不希望作为slave的节点中执行以下命令
salveof no one
#查看当前节点是否主从
info replication
#从机访问主机的通行密码,如果master设置了登录密码
masterauth ${password}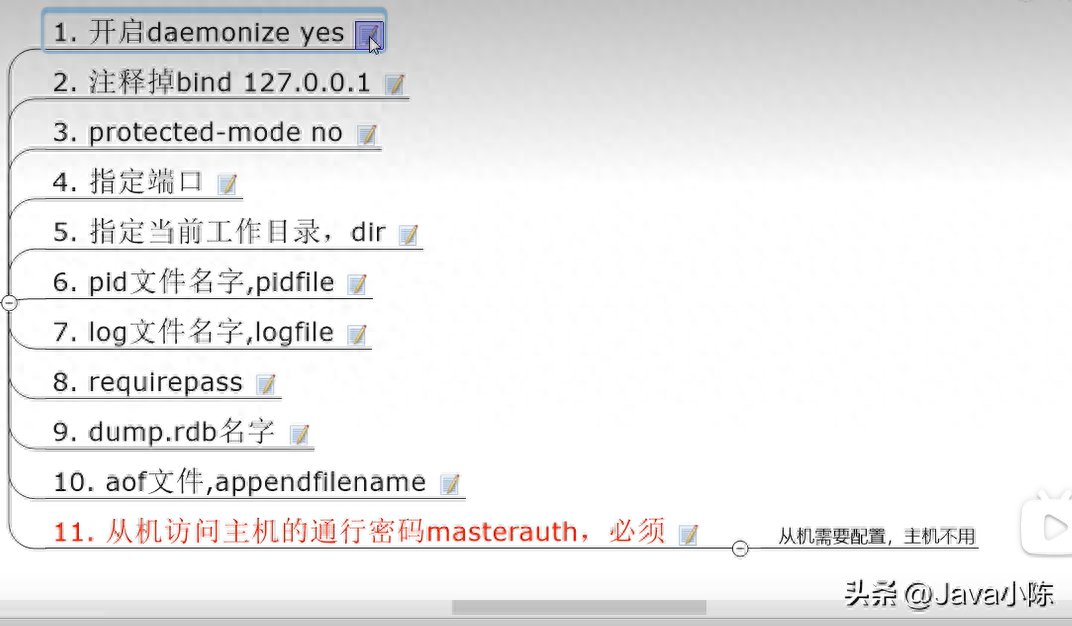
相关配置 :

master宕机故障
redis将无法执行写请求,只有slave节点能执行读请求,影响了系统的可用性
方法1:
随机找一个节点,执行slaveof no one,使其成为master节点
然后对其他slave节点执行slaveof newMatserIp newMasterPort
方法2:
马上重启master节点,它将会重新成为master
方法三:哨兵模式
Redis 复制如何处理 key 的过期
Redis 的过期机制可以限制 key 的生存时间。此功能取决于 Redis 实例计算时间的能力,但是,即使使用 Lua 脚本更改了这些 key,Redis slaves 也能正确地复制具有过期时间的 key。
为了实现这样的功能,Redis 不能依靠主从使用同步时钟,因为这是一个无法解决的并且会导致 race condition 和数据集不一致的问题,所以 Redis 使用三种主要的技术使过期的 key 的复制能够正确工作:
- slave 不会让 key 过期,而是等待 master 让 key 过期。当一个 master 让一个 key 到期(或由于 LRU 算法将之驱逐)时,它会合成一个 DEL 命令并传输到所有的 slave。
- 但是,由于这是 master 驱动的 key 过期行为,master 无法及时提供 DEL 命令,所以有时候 slave 的内存中仍然可能存在在逻辑上已经过期的 key 。为了处理这个问题,slave 使用它的逻辑时钟以报告只有在不违反数据集的一致性的读取操作(从主机的新命令到达)中才存在 key。用这种方法,slave 避免报告逻辑过期的 key 仍然存在。在实际应用中,使用 slave 程序进行缩放的 HTML 碎片缓存,将避免返回已经比期望的时间更早的数据项。
- 在Lua脚本执行期间,不执行任何 key 过期操作。当一个Lua脚本运行时,从概念上讲,master 中的时间是被冻结的,这样脚本运行的时候,一个给定的键要么存在要么不存在。这可以防止 key 在脚本中间过期,保证将相同的脚本发送到 slave ,从而在二者的数据集中产生相同的效果。
一旦一个 slave 被提升为一个 master ,它将开始独立地过期 key,而不需要任何旧 master 的帮助。