介绍
Redis通常用作缓存。当一致性要求不高时,它也可以用作存储。此外,Redis还提供消息订阅、事务、索引等功能。我们还可以使用集群功能构建分布式存储服务,并实现非强一致性的分布式锁服务。
在上述各种情况下,Redis都具有一个共同的优势,即处理速度快(高性能)。

Redis有多快?
要了解Redis有多快,您需要有一个评估工具。
幸运的是,Redis提供了这样一个工具,并提供了一些常用硬件平台的性能数据。
- Redis基准测试可用于评估Redis的性能。命令行提供了在正常/管道模式下以及在不同压力下评估特定命令性能的功能。
- Redis具有出色的性能。作为键值系统,最大负载级别为10W / s,设置和获取时间消耗级别分别为10ms和5ms。使用流水线可以提高Redis操作的性能。
脚本执行时间
默认情况下,Redis基准测试使用100,000个请求、50个客户端和3字节的负载进行测试。
Redis为何如此之快?
Redis是单线程应用程序,这意味着Redis使用单个线程来处理客户端的请求。
Redis具有高性能的原因如下:
- 内存存储:Redis使用内存(内存中)存储,没有磁盘I/O开销。
- 单线程实现:Redis使用单个线程处理请求,避免了多线程之间的线程切换和锁资源争用的成本。
- 非阻塞I/O:Redis使用多路复用I/O技术,在poll、epoll和kqueue中选择最佳的I/O实现。
- 优化的数据结构:Redis具有许多经过优化的数据结构实现,可以直接应用。应用层可以直接使用本机数据结构以提高性能。
单线程
Redis的核心网络模型由单线程实现,这在一开始时曾引起了许多人的困惑。Redis官方对此的回答是:
CPU很少成为Redis的瓶颈,因为通常Redis要么是内存绑定的,要么是网络绑定的。例如,使用管道在运行在平均Linux系统上的Redis上,每秒可以传输甚至100万个请求,因此,如果您的应用程序主要使用O(N)或O(log(N))命令,它几乎不会使用太多CPU。
单线程的好处是什么?
- 无需线程创建或线程销毁引起的消耗
- 避免线程切换引起的CPU消耗
- 避免线程之间的竞争问题,如添加锁、释放锁、死锁等
此外,单线程机制极大地降低了Redis内部实现的复杂性。哈希的延迟重哈希、Lpush等“线程不安全”命令可以在无锁的情况下执行。
I/O模型
一般来说,I/O操作分为两个步骤:
- 等待数据从网络到达,然后将其加载到内核空间缓冲区
- 将数据从内核空间缓冲区复制到用户空间缓冲区
根据这两个步骤是否阻塞线程,可以将其分为阻塞/非阻塞、同步/异步。
阻塞I/O模型
I/O最常见的模型是阻塞I/O模型,我们迄今为止在文本中使用的所有示例都使用了阻塞I/O模型。默认情况下,所有套接字都是阻塞的。
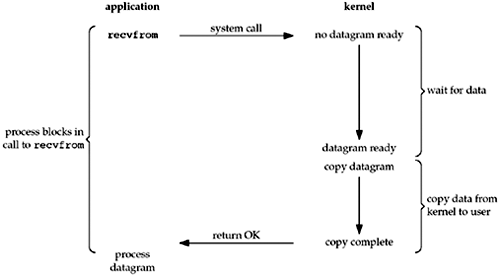
在此示例中,我们使用UDP而不是TCP,因为对于UDP,数据“准备”以供读取的概念很简单:要么接收到整个数据报,要么没有。
而对于TCP,情况会更加复杂,因为还涉及到额外的变量,如套接字的低水位标记等。
非阻塞I/O模型
当我们将套接字设置为非阻塞时,我们告诉内核“当我请求的I/O操作不能在不使进程进入休眠的情况下完成时,请不要使进程进入休眠,而是返回一个错误”。
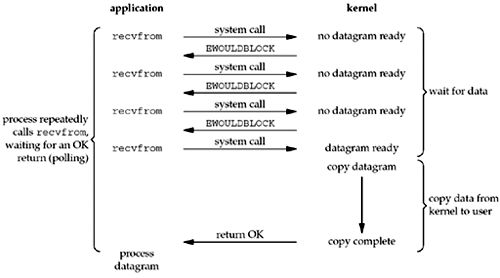
前三次调用recvfrom时,没有数据返回,因此内核立即返回EWOULDBLOCK错误。第四次调用recvfrom时,数据报准备好了,它
被复制到我们的应用程序缓冲区中,recvfrom成功返回。然后我们处理数据。
当应用程序循环调用非阻塞描述符上的recvfrom时,这称为轮询。应用程序不断轮询内核,以查看某个操作是否准备好。这通常会浪费CPU时间,但通常在专用于一项功能的系统上遇到这种模型。
多路复用I/O模型
使用I/O多路复用时,我们调用select或poll并在这两个系统调用中的一个中阻塞,而不是在实际I/O系统调用中阻塞。
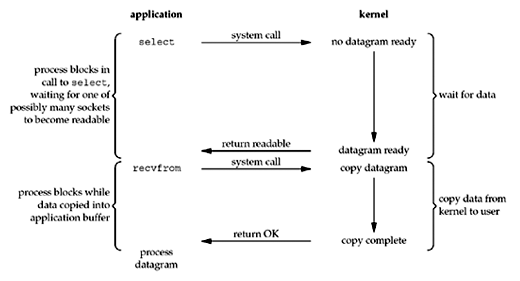
我们在调用select中阻塞,等待数据报套接字可读。当select返回套接字可读时,我们然后调用recvfrom将数据报复制到我们的应用程序缓冲区中。
与阻塞I/O相比,使用select似乎没有任何优势,实际上,由于使用select需要两个系统调用而不是一个,因此实际上存在轻微的劣势。
但使用select的优势在于,我们可以等待多个描述符准备就绪。
现在让我们看看Redis如何处理客户端连接?
通常,Redis使用反应器设计模式,封装了多个实现(select、epoll、kqueue等)以多路复用IO来处理来自客户端的请求。
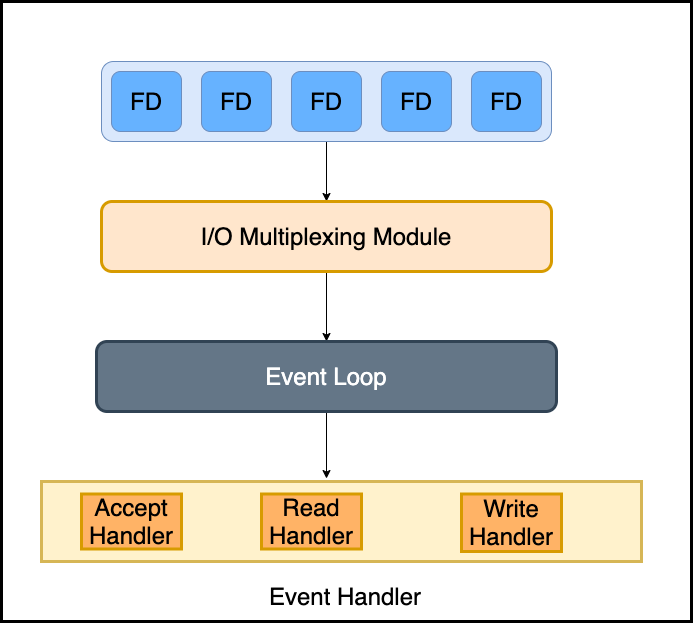
反应器设计模式通常用于实现事件驱动。此外,Redis在不同平台上封装了不同的多路复用IO库。
Redis将优先选择时间复杂度为O(1)的I/O多路复用函数作为底层实现,包括Solaris 10中的evport、Linux中的epoll和Mac OS / FreeBSD中的kqueue。
这些函数都使用内核的内部结构,并可以为数十万个文件描述符提供服务。
但是,如果当前的编译环境没有上述函数,将选择select作为备选方案。因为在使用时会扫描所有受监视的描述符,所以其时间复杂度较差O(n),同时一次只能为1024个文件描述符提供服务,因此通常不作为首选方案使用。