一、爱奇艺大数据介绍
1.爱奇艺大数据应用
 图片
图片
爱奇艺大数据应用分为两个方面:
- 看过去:针对以往数据,制作天级别、小时级别或实时的报表;负责内容、会员的运营工作,基于数据分析进行决策。
- 知未来:基于数据制作用户产品,应用于实施广告、推荐搜索等方面。
2.爱奇艺大数据实时应用
爱奇艺大数据实时应用包括实时广告系统、实时推荐和搜索、实时热度,以及实时风控。下方右图是应用搜索界面,搜索推荐基于用户及其他个性化信息实时计算生成。
 图片
图片
3.爱奇艺大数据服务体系
 图片
图片
以上提及的产品通过爱奇艺大数据服务体系实现。如上图,爱奇艺大数据服务体系主要由数据采集、数据处理、数据应用等方面构成。
- 数据采集包括用户和内容数据、服务日志、监控数据、第三方数据;
- 数据处理包括大数据基础架构的存储和计算层,以及上层的数据分析引擎和平台;
- 最终通过报表、分析型查询、机器学习和监控排障功能,应用于各个业务线。
我们的集群部署模式由通用集群和少量专用集群组成,总共有1万多台机器、500PB以上的存储,每天会运行50多万个批处理任务及4000多个流计算任务。
二、爱奇艺实时计算技术演进
1.爱奇艺实时计算技术演进概览
 图片
图片
技术演进过程分为三个阶段:
第一阶段是比较原始的Hive on MapReduce。在此阶段,我们借助Hive工具实现了SQL化的分析,通过SQL在Hadoop上构建离线数仓。SQL避免用户自己写MapReduce的Java代码,解决了大数据的初步问题之一。但随着业务发展、实时性需求增加,离线分析的处理延时难以满足业务需要。
第二阶段采用基于Spark SQL分析,大大加速离线数仓的构建进程,同时也探索基于Flink的实时数据处理。这个阶段我们初步引入Flink,用户直接写Flink任务代码,相比于基于SQL的离线分析,开发和运维的难度高了不少。同时,因为需要维护离线和实时两条链路,成本较高,且存在流与批数据不一致等问题。
第三阶段主要进行两项工作:一方面是实时计算SQL化,我们引入了统一元数据,简化了Flink SQL的开发,使得撰写实时计算的逻辑与Hive SQL一样简单;另一方面,引入数据湖Iceberg,初步实现流批一体。
2.Spark SQL服务架构
爱奇艺的Spark SQL服务基于开源的Apache Kyuubi搭建,因为直接使用Spark Thrift Server服务有很多缺点,比如不支持多租户、资源隔离较难实现等。
 图片
图片
引入Kyuubi后,整体架构如上图所示。我们在Hadoop集群上层搭建了Kyuubi Server集群,再上层通过Pilot统一SQL网关(自研服务)接入,最上层是离线计算的Gear工作流调度系统和魔镜即席查询平台,分别承接定时工作流以及Ad-hoc的即席查询。
除此之外,Kyuubi Server和Spark任务引擎会注册到ZooKeeper服务发现集群中,供其调用方进行服务发现,由此实现了高可用性,去除了单点故障。
基于Kyuubi的这套体系具有以下6个好处:
- 多租户:企业内部包含各个业务线和不同的Hadoop user,只需部署一套服务即可支持不同用户的访问;
- 资源隔离:我们为每个来自定时工作流的例行化任务,启动独立的Spark引擎,各个任务间资源隔离,不会互相影响;
- 快速Ad-hoc支持:我们也为来自即席查询的任务,启动用户级别的共享Spark引擎,无需在每次查询时都花费1分钟去启动Spark,使得查询响应低至秒级;
- 高扩展性:单个Kyuubi实例支持上千个连接,且每个查询只需要花费Kyuubi实例很少的资源,因此每台Kyuubi服务器都可承担很高的工作负载;
- 高可用性:由于采用了ZooKeeper的服务注册与发现机制,单个Kyuubi实例故障不影响任务运行;
- 执行计划优化:为了加快SQL的运行速度,Kyuubi默认支持了一些查询优化规则,并且允许用户在此基础上扩展,添加新的优化规则。
爱奇艺在作为Apache Kyuubi用户的同时,也积极参与社区讨论,回馈社区,目前共有70多个patches被社区接受。
3.Spark深入优化
 图片
图片
除了通过Kyuubi建立Spark SQL的服务之外,我们也对Spark本身进行了优化,使得计算速度更快,资源更节省。
- 动态资源分配(Dynamic Resource Allocation,DRA)
由于我们平台上每天都会运行大量的任务,用户很难为每个任务配置一个合适的资源量,因此经常出现任务的并行度不足或资源浪费的问题。DRA是Spark提供的已经比较成熟的功能,开启之后能够根据并行度需求自动申请或释放资源,在避免资源浪费的同时,还能在一定程度上加快任务运行。
- 自适应查询执行(Adaptive Query Execution,AQE)
AQE的定义是根据Spark任务运行时的数据,动态修改查询计划。因此它是一个优化框架,而非特定功能,用户可以扩展各种优化规则。
社区版Spark自带的优化规则包括Shuffle分区合并、自动转换为广播Join、Join倾斜优化等。我们基于Kyuubi进行功能扩展,比如自动合并小文件、末级Stage配置隔离等。其中,末级Stage配置隔离是一个非常好用的优化规则,它允许在配置层面,为普通Stage和末级Stage分别配置处理并行度。
这样,我们可以在末级Stage上按目标文件大小设置并行度,以合并小文件;在普通Stages上配置较高的并行度,加速任务处理,达成两者兼顾的效果。
- 血缘集成Apache Atlas
爱奇艺内部使用Apache Atlas管理数据血缘,为此我们将其元数据和血缘投递的逻辑集成到了Kyuubi中,使得Kyuubi在运行Spark SQL任务时,能够自动向Atlas投递血缘。我们已将这一功能贡献给了社区(KYUUBI #4814),将在即将发布的Kyuubi V1.8版本中可用。
- Apache Uniffle:Remote Shuffle Service
在Spark中使用Remote Shuffle Service是近两年来比较流行的一个趋势。爱奇艺采用的是Apache Uniffle这个开源产品。
在引入Apache Uniffle前,存在两种问题:一个是Shuffle不稳定,比如大数据量情况下,下载数据失败,出现fetch failure的报错;另一个是存算分离的云原生架构下,计算节点容量、IO性能不足。
引入Apache Uniffle后,原有问题得到改善:
- 减小磁盘IO压力:利用内存存储数据,避免随机IO
- 增强大数据量下的稳定性:Shuffle 10TB以上不再失败,可平稳运行
- 提高Shuffle速度:1TB TeraSort 快30%+
爱奇艺作为Apache Uniffle的共同贡献者,深度参与了社区讨论和贡献。欢迎大家试用并提出反馈意见。
4.从Hive迁移Spark SQL
 图片
图片
在支持Spark SQL后,已有的大量Hive任务需要迁移过来。迁移过程会遇到两种问题:
- 运行失败:Spark SQL的语法并不是100%兼容Hive,其语法更加严格;
- 数据不一致:相比于运行失败更加麻烦,因为用户无法立即发现,且对比数据一致性的工作也更加复杂。
为了解决迁移的问题,我们基于Pilot SQL网关开发了“双跑对数”的功能,在迁移前自动预测迁移结果,运行步骤如下:
- SQL解析:输入、输出
- 创建影子表:用户模拟双跑的输出
- 模拟运行:修改SQL的输出表,指定Hive、Spark引擎分别运行
- 结果一致性校验:行数、CRC32(浮点型保留小数点后4位,避免因精度不同导致的判断错误)
使用“双跑对数”功能之后,我们在迁移的过程中发现了一些问题,其中有部分可以通过优化Spark SQL的兼容性来解决,进一步降低用户迁移的工作量:
- 支持UDAF/UDTF的私有化构造
- 允许reflect抛出异常时返回NULL
- Hive参数映射到Spark参数,如 mapreduce.job.reduces→Spark.sql.shuffle.partitions
用户在Hive中设置很多参数,比如reduce的个数,但这些参数在Spark中原本无法被识别,我们通过参数映射,将其转化为Spark的相应参数,尽可能保留用户的SQL逻辑。
最后,使用“自动降级”功能令迁移顺利进行,即首次使用Spark运行失败后,重试时降级为Hive引擎。由此,迁移分为两个阶段:第一阶段开启自动降级,用户可以放心迁移,并通过降级的记录梳理出迁移失败的任务;第二阶段,将这些失败的任务修复后,再完全切换到Spark。
目前Hive迁移的总体进度已经达成90%,对于这些迁移的任务,平均性能提升了67%,资源(包括CPU、内存使用量)也降低了近一半。
5.Flink SQL + 统一元数据中心
 图片
图片
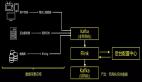
在使用Spark SQL提高实时性的同时,我们也尝试引入Flink SQL,希望能够真正做到实时计算。但原生的Flink SQL如上示左图,比Hive SQL长很多,需要定义输入输出表,字段名称和类型,以及背后的数据源配置。应如何解决使用过程繁琐的问题?
我们引入了“统一元数据中心”的概念,类似于Hive的Metastore。因为Hive具有Metastore,所以无需反复定义输入输出表,写SQL非常简单,如上图中写三行语句即可。
我们将内部的各种数据,包括流式的Kafka和RocketMQ,传统数据库MySQL、Redis、HBase,以及数据湖产品,都集成到统一元数据中心,并开发了Flink Catalog、Flink Connectors与其对接。这样依赖,我们无需在每个任务中,重新定义表的结构以及连接串等信息,做到开箱即用,有效提升开发效率。
6.SQL适合流计算开发

可能有同学会有疑问,SQL到底能否足够表达流计算?
因为传统SQL(比如Hive、MySQL),输入是一个表,输出也是一个表,从表到表的SQL究竟能否表达流式的计算逻辑?我们认为是可以的。
这个观点具有理论支撑,一位来自Google的工程师Akidau在其著作《Streaming Systems》中,提出了流和表的“相对论”。他认为流和表本质上是数据的两种表现形式。他拆解了传统SQL表到表的过程,将其拆分为表到流、流到表、流到流三种操作的组合。
以上图右边的SQL举例,输入是一组用户得分,按照团队进行聚合,计算出每个团队的总分,输出到新的表中。它的输入表由4个字段组成:用户、团队、得分和时间。
让我们来拆解这个SQL的执行逻辑(假设这是离线计算)。首先,原始表并不是一次性加载到内存的,而是通过一个SCAN算子,一条一条地读入,变成内部的流。然后经过SELECT算子,去掉无用字段,保留team和score字段,得到了一个新的流。
最后,流的数据全部到齐后,一次性计算聚合的值,即把每个team的所有分数相加得到总分,再输出到目标表。由此看出,第一个操作SCAN是表到流,第二个操作SELECT是流到流,第三个操作GROUP BY是流到表。
从上面的SQL执行逻辑拆解可以看出,将传统SQL描述为表到表的操作,黑盒地看是对的,但在微观层面是不准确的,实际上是表到流、流到表、流到流三种操作的组合,唯一不存在的是直接的流到流的操作。
流计算的过程中包括很多要素,比如Map或Filter可以认为是一个流到流的操作,分组的聚合或窗口的聚合,就是流到表的过程;而通过定时的trigger或Watermark引起的trigger,是表到流的过程。
当把上面的SQL看成流计算时,会发现其拆解过程与离线计算一模一样,都是由SCAN(表到流)、SELECT(流到流)、GROUP BY(流到表)组成的。
因此,SQL对于流计算和离线计算来说,没有本质区别,所以它非常适合流计算的开发。SQL开发优势如下:
- 开发门槛低:相较于通过Java/Scala代码开发Flink任务,SQL的开发门槛较低。引入开箱即用的元数据后,SQL就更加简洁,用户无需学习Flink的API。
- 版本升级容易:Flink SQL对齐了SQL标准,语法相对稳定,跨版本升级改动较小。
- 运行效率高:因为Flink SQL具有一些参数,控制SQL执行的计划优化,无需复杂的代码逻辑实现这些功能。
在爱奇艺的实时计算平台上,目前SQL的任务占比已经达到2/3,已经能覆盖大部分的功能,所以较推荐内部用户使用SQL进行流计算的开发。
7.Lambda到流批一体架构
 图片
图片
我们在存储侧也做了技术革新。传统方案使用Lambda架构,即离线一条通路、实时一条通路,在下游合并这两条通路。但这种架构存在明显问题:
- 离线通路时效性差,实时通路容量低
- 维护两套逻辑,开发效率低
- 两条通路数据不一致
- 维护多套服务,成本高
我们通过引入数据湖技术,可以做到流批一体架构,即使用Flink与数据湖交互,实时写入、实时更新。数据湖技术解决了两条链路、实时性、以及实时通路容量不足的问题。由于无需维护两条通路,计算成本与存储成本比之前的模式更低。
8.基于Iceberg的数据湖
 图片
图片
爱奇艺选择的数据湖产品是Apache Iceberg,其具体好处将通过案例介绍。
上图是会员订单分析的应用场景。爱奇艺的会员业务有10多年的历史,每个会员订单都对应一条记录,订单表存储在MySQL中,这些表非常大。会员团队进行用户会员运营分析时,如果直接用MySQL对这些表进行查询,速度非常慢,因为MySQL对这种OLAP分析的场景支持不佳。
最原始的方案是通路1(上图标号1和2),先用内部数据集成工具BabelX将MySQL表全量导出到Hive,再使用Hive、Spark SQL或Impala查询。这条通路的问题是,MySQL的全量导出是一个天级别的任务,数据分析的时效性很差;每次导出的数据量很大,对MySQL产生很大压力;每天都在反复导出相同的数据,效率很低。
后来会员团队和我们合作了另外一条通路2(即上图标号3和4),通过内部工具,将MySQL的变更流实时导出到Kudu,用Impala进行查询。Kudu介于HDFS和HBase之间,既有实时写入的能力,又有分析型查询能力。这条通路的问题在于:
- Impala+Kudu需要搭建单独的集群,成本比较高;
- Kudu集群的扩展性差,因为集群上线只能达到几十个节点;
- Impala+Kudu运维比较复杂,经常出现故障。
基于这些痛点,我们调研后发现Iceberg比较适合完成这种任务,我们选择了图中最下面的新通路:通过内部的RCP平台,使用Flink CDC技术实时导出到Iceberg中,在下游使用Spark SQL进行查询。
改造效果如下:
- 时延低:整体时延大幅降低,从原来的天级延迟可以降低到分钟级
- 查询快:我们对查询性能进行了优化,使其达到了接近Impala+Kudu的查询性能
- 成本低:利用现成的HDFS集群,无需独立部署
- 运维易:对MySQL压力较小,链路稳定,运维工作量也较小
在查询性能上,我们做了两处优化:
1)小文件智能合并:Iceberg表在写入过程中会产生很多小文件,积累到一定程度会严重影响查询性能;而合并小文件时,如果每次都全表合并,又会造成严重的写放大。为此我们开发了智能合并策略,基于分区下文件大小均方差,自动选择待合并的分区,最大程度地避免了写放大。
2)写Parquet文件开启BloomFilter:BloomFilter可以判断一组数据中是否不含指定数据,被Parquet等存储格式广泛使用,用来降低读取数据量。爱奇艺将这一特性集成到Iceberg中,在写Parquet文件时允许开启BloomFilter,在内部场景中取得了很好的效果。这一功能已贡献给社区(PR #4831)。
最终,查询的时间从900秒降低到10秒,达到了交互式查询的性能,很好地满足了会员运营分析的需求。
三、爱奇艺实时计算平台建设
1.平台建设与数据处理架构
 图片
图片
爱奇艺的实时计算主要又两个平台:负责通用型计算任务的RCP实时计算平台、负责特定分析型需求的RAP实时分析平台。
基于原始数据,可通过RCP进行通用分析,将结果写入新的流、数据库或Iceberg,供线上服务和数据分析直接使用。如需根据事件流,制作实时报表等特定的复杂目标,可使用RAP平台。
2.RCP实时计算平台
 图片
图片
RCP(Real-time Computing Platform,爱奇艺统一实时计算平台)的特点是:
- 流程完整:具备数据读入、计算及分发的全流程
- 支持多种开发模式:JAR/SQL/DAG,其中DAG模式是对SQL模式的进一步简化,通过图形化界面配置即可完成开发
- 集成统一元数据中心:各种类型的数据源均由平台统一注册和管理
如上图架构所示,Server层负责资源管理、任务管理、任务提交、监控报警等功能。Launcher层负责直接提交任务到运行集群,这一层包含内部的Flink版本和Spark版本,对于Flink,又包含了JAR/SQL/DAG引擎、接入统一元数据、以及各种数据源的connector。
1)接入传统数据库
 图片
图片
RCP平台能结合各个数据库的Connnector,将传统数据库接入实时计算。
上图是针对广告库存计算的实时化改造。业务需要对多个MySQL表做Join,写入Redis中,供下游的实时任务查询。
原有方案是,使用Spark批处理作业,每10分钟全量拉取这些MySQL表,在Spark任务里进行Join。这个方案的问题是,每10分钟进行全量拉表,对MySQL压力较大,且整体写入Redis的数据时效性较差,至少延迟10分钟,这会导致业务数据的准确性下降。
改造后的方案见图中绿框,我们采用Flink CDC的方案。在Flink任务中配置三个CDC的source,由此实现对MySQL全量同步以及自动转增量拉取的过程;紧接着一个Join节点,负责实时计算Join结果。如此一来,Join的输出是实时更新的结果,上游MySQL表的更新会实时地反映到Redis中。
改造效果:
- 将以上三个实时的表Join数据写入Redis后,业务准确性明显提升,达到7个9;
- 时效性方面,从20分钟左右降低到秒级,降低了MySQL的服务压力;
- 由于没有重复的数据处理,资源节省了50%,处理效率大幅提升。
RCP支持了各类CDC connector,降低了将数据库接入实时计算的门槛,主要的优势有:
- 可以实现存量+增量的无缝对接
- 对源库影响较小
- 相较其他实时同步方案,Flink方案可以实现读取和数据加工的一体性,比如无需借助Kafka实时队列,整个链路更加简单。
2)故障诊断
RCP平台支持故障诊断功能。针对单个任务,平台可自助排查故障原因,如下图所示:
- 日志分析:报错信息,比如checkpoint失败次数过多
- 指标分析:GC、流量倾斜指标等
 图片
图片
3)链路血缘
如下图所示,平台展示了该任务上游、下游的血缘关系。
 图片
图片
4)链路诊断
如果需要分析整条链路,平台也提供了一键链路诊断的功能。只需点击一下,即可对链路上的所有实时计算作业,进行健康度情况分析,获取其最近的重启次数和消费延迟等信息。
 图片
图片
3.RAP实时分析平台
 图片
图片
爱奇艺RAP(Real-time Analytics Platform)实时分析平台,提供一站式的大数据摄取、计算和分析能力,支持超大规模实时数据多维度的分析,并生成分钟级延时的可视化报表。主要特色是:
- 提供实时、多维度的聚合分析
- 配置化:通过页面配置完成大部分功能,相较实时计算平台更简单
- 实时报表:自动生成的可视化报表(内部BI平台+Grafana)
- 实时报警、数据接口
RAP的架构包含4个模块:
- 数据源接入方面,支持公司内部各流式数据源;
- 数据处理方面,通过RCP平台或Druid KIS进行;
- 两个OLAP引擎包括Druid和ClickHouse;
- 最后将可视化报表发布在Grafana或内部BI平台。
1)典型案例
 图片
图片
上图是一张直播报表,展示直播实时的卡顿比(HCDN团队)情况。
右图是直播期间每分钟的总UV值(同步在线人数),只需三个步骤就能完成该报表的配置:
- 首先选择接入数据源:此处选择一张Iceberg表(用户行为表),包含时间、设备ID、事件类型、app版本、运营商、省份等字段。
- 然后配置模型:指明时间戳字段,计算哪些指标,哪些字段是维度
- 最后报表配置:指明用户想要的报表展现方式
总体来说,只需少量的页面操作,即可配置一张实时报表,整个过程非常迅速。原先使用通用型工具开发此类报表,可能需要一周时间,但在RAP进行配置,仅需小时级别的时间,并且支持灵活的需求变更。目前,RAP平台已在爱奇艺的直播、会员监控等业务中广泛应用。
四、未来展望
下一步,爱奇艺实时计算的发展方向包括:
- 实时计算SQL化:进一步提升SQL化的比例,丰富 SQL化的配套支持,比如调试功能,增强使用SQL开发的便捷性。
- 实时化的数据集成平台:基于配置化的方式,完成同种数据源的不同集群、甚至不同种类数据源之间的数据同步。
- 流批一体新方案探索:跟进社区新动向,比如Hybrid Source和Apache Paimon等流批一体的存储和计算产品。
Q&A
Q1:实时计算平台后续演进规划是怎样的?
A1:进一步提升SQL化开发的成熟度,优化调试和诊断功能,对Flink SQL进行性能优化,流批一体。
Q2:数据服务支持实时计算的同时,能否保存所有数据?存储有期限吗?
A2:可以,Iceberg存储利用HDFS集群实现,其容量非常大。但用户仍需要配置期限,无论何种数据、何种容量,所有数据都无限保存是不实际的,成本方面也不经济。
Q3:实时计算场景有必要提升到秒级延迟吗?
A3:延迟级别由业务场景决定。比如天级别的运营报表本身具有意义,如果提升到秒级,数据量非常大,就失去了统计意义。但如果是前文分享的广告案例,数据越实时,准确性越高,业务上的效果就越好。
Q4:RCP和Apache DolphinScheduler一样吗?
A4:不一样,DolphinScheduler具有工作流调度的功能,RCP主要负责实时计算的流任务管理。
 刘骋昺
刘骋昺
- 爱奇艺 大数据团队 高级经理
- 爱奇艺大数据计算组负责人,负责爱奇艺大数据计算服务、实时计算平台、实时分析平台、机器学习平台等系统的建设工作,拥有丰富的大数据领域实战经验。