












文本摘要,作为自然语言生成(NLG)中的一项任务,主要用来将一大段长文本压缩为简短的摘要,例如新闻文章、源代码和跨语言文本等多种内容都能用到。
随着大模型(LLM)的出现,传统的在特定数据集上进行微调的方法已经不在适用。
我们不禁会问,LLM 在生成摘要方面效果到底如何?
为了回答这一问题,来自北京大学的研究者在论文《 Summarization is (Almost) Dead 》中进行了深入的探讨。他们使用人类生成的评估数据集评估了 LLM 在各种摘要任务(单条新闻、多条新闻、对话、源代码和跨语言摘要)上的表现。
在对 LLM 生成的摘要、人工撰写的摘要和微调模型生成的摘要进行定量和定性的比较后发现,由 LLM 生成的摘要明显受到人类评估者的青睐。
接着该研究在对过去 3 年发表在 ACL、EMNLP、NAACL 和 COLING 上的 100 篇与摘要方法相关的论文进行抽样和检查后,他们发现大约 70% 的论文的主要贡献是提出了一种总结摘要方法并在标准数据集上验证了其有效性。因此,本文表示「摘要(几乎)已死( Summarization is (Almost) Dead )」。
尽管如此,研究者表示该领域仍然存在挑战,例如需要更高质量的参考数据集、改进评估方法等还需要解决。

论文地址:https://arxiv.org/pdf/2309.09558.pdf
方法及结果
该研究使用最新的数据来构建数据集,每个数据集由 50 个样本组成。
例如在执行单条新闻、多条新闻和对话摘要任务时,本文采用的方法模拟了 CNN/DailyMail 、Multi-News 使用的数据集构建方法。对于跨语言摘要任务,其策略与 Zhu 等人提出的方法一致。关于代码摘要任务,本文采用 Bahrami 等人提出的方法。
数据集构建完成之后,接下来就是方法了。具体来说,针对单条新闻任务本文采用 BART 和 T5 ;多条新闻任务采用 Pegasus 和 BART;T5 和 BART 用于对话任务;跨语言任务使用 MT5 和 MBART ;源代码任务使用 Codet5 。
实验中,该研究聘请人类评估员来比较不同摘要的整体质量。结果如图 1 所示,LLM 生成的摘要在所有任务中始终优于人工生成的摘要和微调模型生成的摘要。
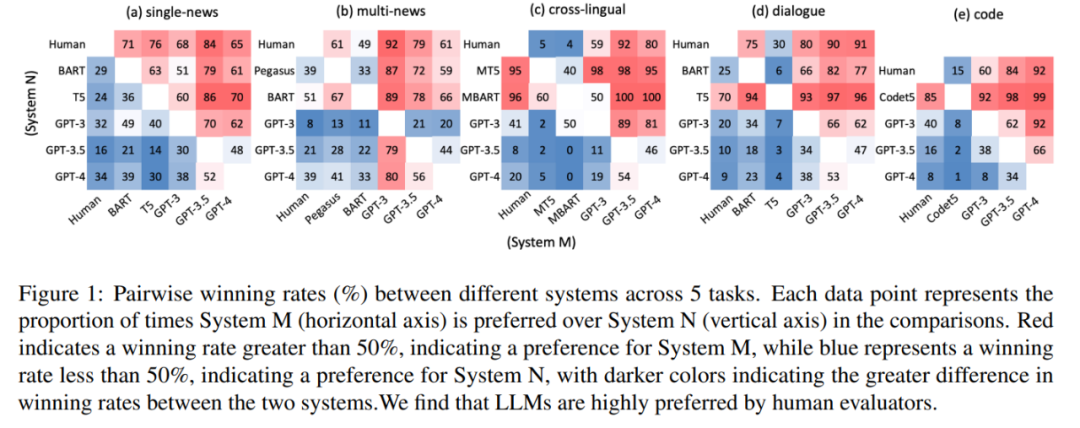
这就提出了一个问题:为什么 LLM 能够胜过人类撰写的摘要,而传统上人们认为这些摘要是完美无缺的。此外,经过初步的观察表明,LLM 生成的摘要表现出高度的流畅性和连贯性。
本文进一步招募注释者来识别人类和 LLM 生成摘要句子中的幻觉问题,结果如表 1 所示,与 GPT-4 生成的摘要相比,人工书写的摘要表现出相同或更高数量的幻觉。在多条新闻和代码摘要等特定任务中,人工编写的摘要表现出明显较差的事实一致性。

人工撰写的摘要和 GPT-4 生成摘要中出现幻觉的比例,如表 2 所示:

本文还发现人工编写的参考摘要存在这样一个问题,即缺乏流畅性。如图 2 (a) 所示,人工编写的参考摘要有时存在信息不完整的缺陷。并且在图 2 (b) 中,一些由人工编写的参考摘要会出现幻觉。

本文还发现微调模型生成的摘要往往具有固定且严格的长度,而 LLM 能够根据输入信息调整输出长度。此外,当输入包含多个主题时,微调模型生成的摘要对主题的覆盖率较低,如图 3 所示,而 LLM 在生成摘要时能够捕获所有主题:

由图 4 可得,人类对大模型的偏好分数超过 50%,表明人们对其摘要有强烈的偏好,并凸显了 LLM 在文本摘要方面的能力:































