在Java中创建线程会产生明显的开销。创建线程消耗时间,增加请求处理的延迟,并涉及JVM和操作系统的大量工作。为了减少这些开销,线程池发挥着重要作用。
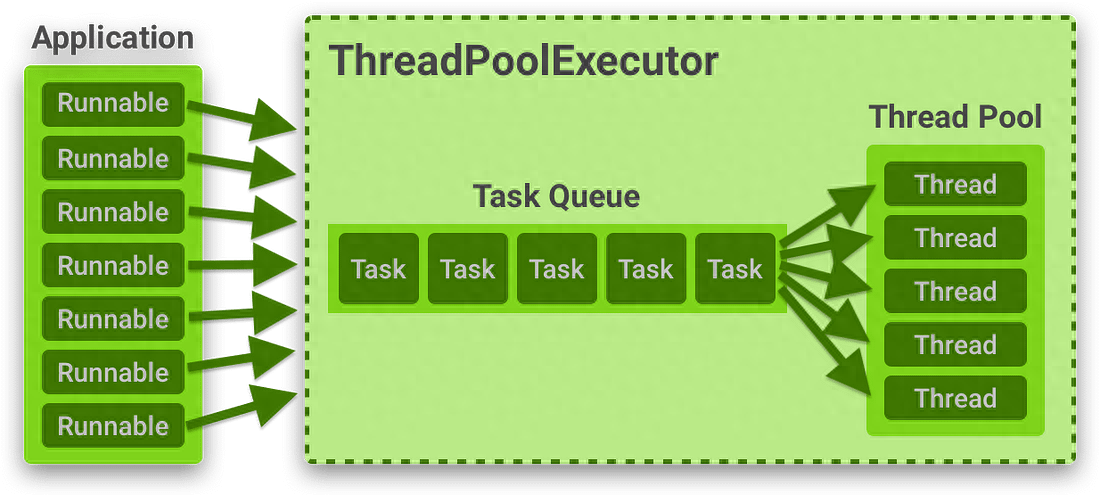
使用线程池的原因:
1. 性能:在Java中,线程的创建和销毁可能很昂贵。线程池通过创建一个可以重复使用于多个任务的线程池来减少这种开销。
2. 可扩展性:线程池可以按需扩展以满足应用程序的需求。例如,在负载较重时,可以扩展线程池以处理额外的任务。
3. 资源管理:线程池可以帮助管理线程使用的资源。例如,线程池可以限制在任何给定时间活动的线程数量,这有助于防止应用程序耗尽内存。
调整线程池大小:了解系统和资源限制
在确定线程池的大小时,了解系统的限制,包括硬件和外部依赖,非常重要。让我们通过一个例子来详细说明这个概念:
场景:
假设你正在开发一个处理HTTP请求的Web应用程序。每个请求可能需要涉及从数据库中处理数据并调用外部第三方服务。那么如何确定处理这些请求的最佳线程池大小?
需要考虑的因素:
数据库连接池:假设你正在使用像HikariCP这样的连接池来管理数据库连接。并已经将其配置为允许最多100个连接。如果创建的线程数超过可用连接数,那些额外的线程将等待可用连接,导致资源争用和潜在的性能问题。
以下是配置HikariCP数据库连接池的示例代码:
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class DatabaseConnectionExample {
public static void main(String[] args) {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/mydb");
config.setUsername("username");
config.setPassword("password");
config.setMaximumPoolSize(100); // 设置最大连接数
HikariDataSource dataSource = new HikariDataSource(config);
// 使用dataSource来获取数据库连接并执行查询操作
}
}外部服务的吞吐量
应用程序与外部服务进行交互,该服务有一定的限制。它只能同时处理几个请求,比如每次处理10个请求。同时发送更多的并发请求可能会使该服务不堪重负,导致性能下降或出现错误。
CPU核心数
确定服务器上可用的CPU核心数对于优化线程池大小非常重要。
int numOfCores = Runtime.getRuntime().availableProcessors();每个核心可以同时执行一个线程。超过CPU核心数的线程数量会导致过多的上下文切换,从而降低性能。因此,在确定线程池大小时,应考虑不超过可用CPU核心数的限制,以避免过多的上下文切换。这样可以最大程度地利用可用的计算资源,并提高系统的整体性能。
CPU密集型任务和I/O密集型任务
CPU密集型任务是那些需要大量处理能力的任务,例如执行复杂计算或运行模拟。这些任务通常受限于CPU的速度,而不是I/O设备的速度。CPU密集型场景如:
- 音频或视频文件的编码或解码
- 软件的编译和链接
- 运行复杂的模拟
- 执行机器学习或数据挖掘任务
- 玩电子游戏
优化:
- 多线程和并行性:并行处理是一种将一个较大的任务分解为较小的子任务,并将这些子任务分布到多个CPU核心或处理器上,以利用并发执行来提高整体性能的技术。
假设有一个很大的数字数组,并且希望利用多个线程并发地计算每个数字的平方,那么就可以利用并行处理的优势。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class ParallelSquareCalculator {
public static void main(String[] args) {
int[] numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 获取CPU核心数
int numThreads = Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(numThreads);
for (int number : numbers) {
executorService.submit(() -> {
int square = calculateSquare(number);
System.out.println("Square of " + number + " is " + square);
});
}
executorService.shutdown();
try {
executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
private static int calculateSquare(int number) {
// 模拟一个耗时的计算(例如数据库查询、复杂计算)
try {
Thread.sleep(1000); // 模拟 1秒 延迟
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return number * number;
}
}I/O密集型任务是与存储设备(例如读/写文件)、网络套接字(例如进行API调用)或用户输入(例如图形用户界面中的用户交互)进行交互的任务。
I/O密集型任务的例子包括:
- 读取或写入大文件到磁盘(例如保存视频文件、加载数据库)
- 在网络上下载或上传文件(例如浏览网页、观看流媒体视频)
- 发送和接收电子邮件
- 运行Web服务器或其他网络服务
- 执行数据库查询
- Web服务器处理传入请求
优化:
- 缓存:将频繁访问的数据缓存在内存中,以减少对重复I/O操作的需求。
- 负载均衡:将I/O密集型任务分布到多个线程或进程中,以有效处理并发的I/O操作。
- 使用SSD:与传统硬盘驱动器(HDD)相比,固态硬盘(SSD)可以显著加快I/O操作的速度。
- 使用高效的数据结构,例如哈希表和B树,以减少所需的I/O操作次数。
- 避免不必要的文件操作,例如多次打开和关闭文件。
CPU核心确定
在Java中,使用 Runtime.getRuntime().availableProcessors() 来确定可用的CPU核心数。
确认线程池大小有公式可以遵循吗?
一般来说可以使用如下公式:
线程数 = 可用核心数 * 目标CPU利用率 * (1 + 等待时间 / 服务时间)可用核心数:这是应用程序可用的CPU核心数量。需要注意的是,这与CPU的数量不同,因为每个CPU可能有多个核心。
目标CPU利用率:这是你希望应用程序使用的CPU时间的百分比。如果将目标CPU利用率设置得太高,应用程序可能会变得无响应。如果设置得太低,应用程序将无法充分利用可用的CPU资源。
等待时间:这是线程等待I/O操作完成的时间量。这可能包括等待网络响应、数据库查询或文件操作。
服务时间:这是线程执行计算的时间量。
阻塞系数:这是等待时间与服务时间的比值。它衡量了相对于执行计算所花费的时间,线程等待I/O操作完成的时间量。
需要注意的是,上述公式是一个基本的经验法则,并且可能需要根据应用程序和工作负载的特定情况进行调整。还应考虑任务的性质、预期的响应时间以及可用的系统资源等因素。
此外,该公式假定任务在CPU核心之间均匀分布,并且线程之间没有争用或资源竞争。在实践中,为了找到特定用例的最有效配置,确定最佳的线程池大小可能需要进行实验和基准测试。
样例
假设有一台具有4个CPU核心的服务器,并且我们希望应用程序使用可用CPU资源的50%。
应用程序有两类任务:I/O密集型任务和CPU密集型任务。
I/O密集型任务的阻塞系数为0.5,意味着需要花费50%的时间等待I/O操作完成。
线程数 = 4核 * 0.5 *(1 + 0.5)= 3个线程
CPU密集型任务的阻塞系数为0.1,意味着需要花费10%的时间等待I/O操作完成。
线程数 = 4核 * 0.5 *(1 + 0.1)= 2.2个线程
在这个例子中,需要创建两个线程池,一个用于I/O密集型任务,另一个用于CPU密集型任务。I/O密集型线程池将有3个线程,而CPU密集型线程池将有2个线程。