













数学推理问题是语言模型绕不过的痛点,在各种黑科技的加持下,开源模型的推理性能依然不够看。
最近,滑铁卢大学、俄亥俄州立大学、香港科技大学、爱丁堡大学的研究人员联合开源了一个专为「通用数学问题」定制的大模型MAmmoTH和一个指令调优数据集MathInstruct.

论文链接:https://arxiv.org/pdf/2309.05653.pdf
项目链接:https://tiger-ai-lab.github.io/MAmmoTH/
MathInstruct由13个具有中间原理的数学数据集编译而成,其中6个为新数据集,混合了思想链(CoT)和思想程序(PoT),并确保覆盖了广泛的数学领域。
CoT和PoT的混合不仅可以释放工具使用的潜力,而且还允许模型针对不同的数学问题进行不同的思维过程。
因此,MAmmoTH系列在所有尺度上的9个数学推理数据集上的表现大大优于现有的开源模型,平均准确率提高了12%至29%。
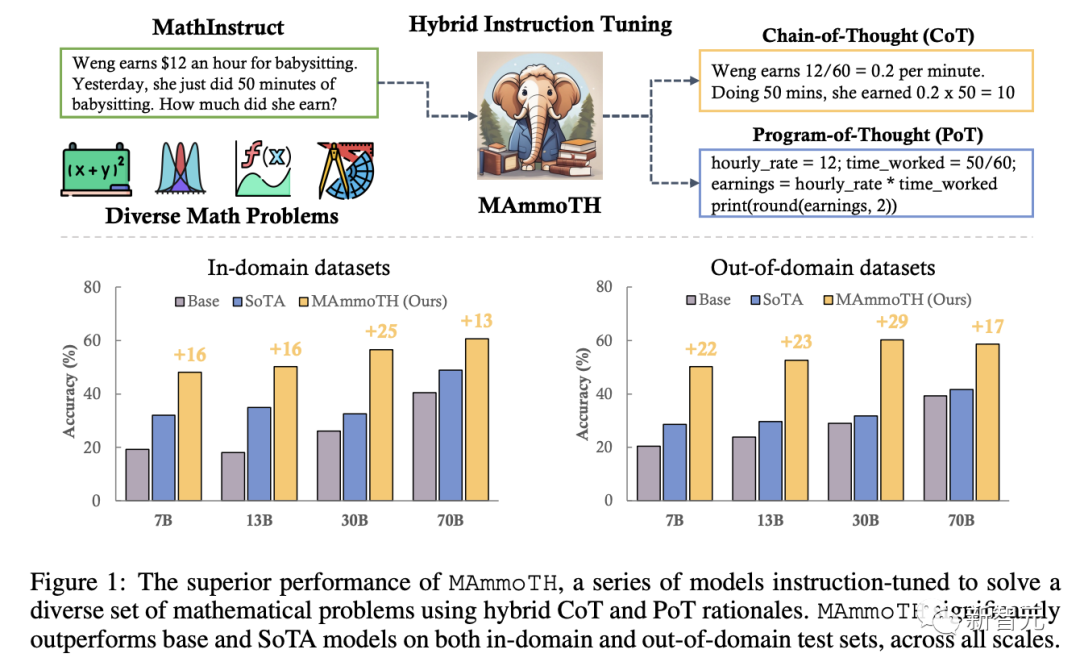
其中MAmmoTH-7B模型在MATH(竞赛级数据集)上的准确率达到了35%,超过了最好的开源7B模型(WizardMath)25%,MAmmoTH-34B模型在MATH上的准确率达到了46%,甚至超过了GPT-4的CoT结果。
数学推理领域新王:MAmmoTH
在数学推理任务上,开源和闭源的大型语言模型(LLM)之间存在巨大的性能差距,目前基准数据集上的sota仍然是GPT-4,PaLM-2和Claude等闭源模型,其他开源模型如Llama,Falcon和OPT等仍然远远落后。
为了弥补性能差距,主要的研究方法有两类:
1. 如Galactica,MINERVA等模型,继续使用数学相关的网络数据对语言模型进行训练,可以提高模型的通用科学推理能力,但计算成本会更高;
2. 如拒绝采样微调(RFT)和WizardMath等,使用特定领域数据集对模型进行微调,虽然可以提高领域内性能,但无法适用于更广泛的数学推理任务。
在解决数学问题时,现有方法通常会采用思维链(CoT)方法引导语言模型循序渐进地用自然语言描述来解决数学问题。
虽然在大多数数学主题下表现出很好的通用性,但在需要精确或复杂的数学计算、算法推理的问题下(如求解二次方程根,计算矩阵特征值)表现不佳。
相比之下,思维程序(PoT, Program-of-Thought)方法和PAL利用外部工具(即Python解释器)大大简化了数学求解过程,将计算过程卸载到外部Python解释器,以解决复杂的数学和算法推理过程(例如,用sympy求解二次方程或用numpy计算矩阵特征值)。
然而,PoT在处理更抽象的推理场景方面有所欠缺,尤其是在没有内置API的情况下,常识推理、形式逻辑和抽象代数的推理能力会更差。
方法概述
研究人员的目标是编制一个高质量、多样化的数学指令调整(instruction-tuning)数据集列表。
1. 覆盖不同数学领域和复杂度
更全面的数据集可以让模型接触到多样化的数学知识,提升模型的多功能性。
研究人员将选择范围缩小到几个被广泛采用的高质量数据集,包括GSM8K、math、AQuA、Camel和TheoremQA.
还可以注意到,现有的数据集缺乏对大学水平的数学知识的覆盖,如抽象代数和形式逻辑,所以研究人员选择使用GPT-4来合成TheoremQA问题中的思维链(CoT)原理,利用网络上找到的数个种子样例,通过自我指导(self-instruct)创建问题和CoT的数据对。

2. 混合CoT和PoT
现有的研究方法大多只关注CoT,并且数据集中也只包含有限的解题思路,导致CoT和PoT的数据量十分不均衡。
为了解决该问题,研究人员利用GPT-4来补充选定数据集的PoT解题思路,通过对比合成程序的执行结果以及人工标注的答案进行过滤,确保生成数据的高质量。
遵循上述方法,最后得到了26万条指令、回复数据对,涵盖了广泛的核心数学领域,如算术、代数、概率、微积分和几何等,混合了CoT和PoT基本原理,并提供多种语言、多个难度级别的数据,足以证明数据集的高品质和独特性。
训练步骤
研究人员统一了MathInstruct中的所有子集,将指令数据集的结构标准化为Alpaca模型的格式,使得模型无需考虑原始数据集的格式,在微调阶段统一处理数据即可。
研究人员选择开源模型Llama-2和Code Llama作为基础模型,在7B、13B、34B和70B尺寸的模型上进行微调。
实验部分
评估数据集
研究人员选择了不同数学领域下的样本,对模型的通用数学推理能力进行评估:
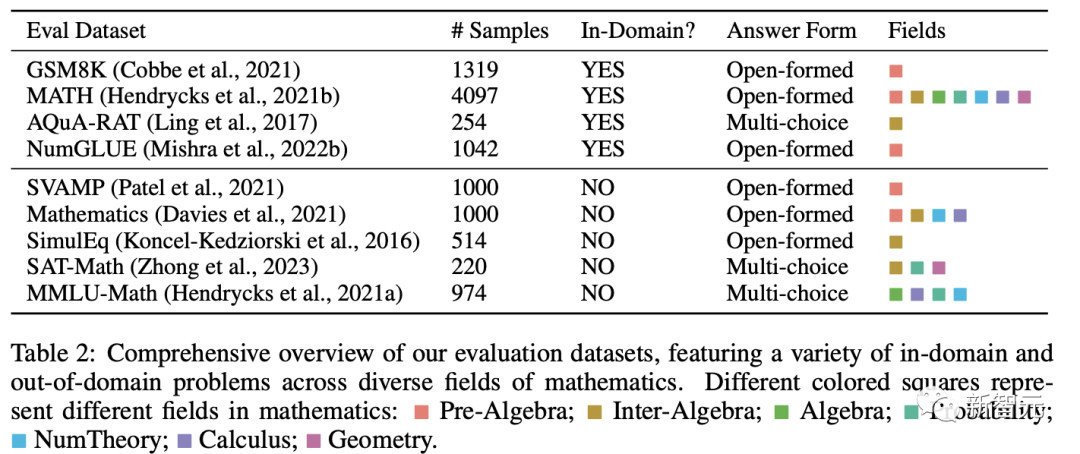
领域内数据集包括GSM8K,MATH,AQuA-RAT,NumGLUE;领域外数据集包括SVAMP,Mathematics,SimulEq,SAT-Math和SimulEq,涵盖了小学、高中和大学水平的数学问题,部分数据集甚至包括形式逻辑和常识推理。
问题类型为开放式问题和多选题,其中开放式问题(如GSM8K、数学)采用PoT解码,因为大多数问题都可以由程序解决;多项选择题(如AQuA、MMLU)采用CoT解码。
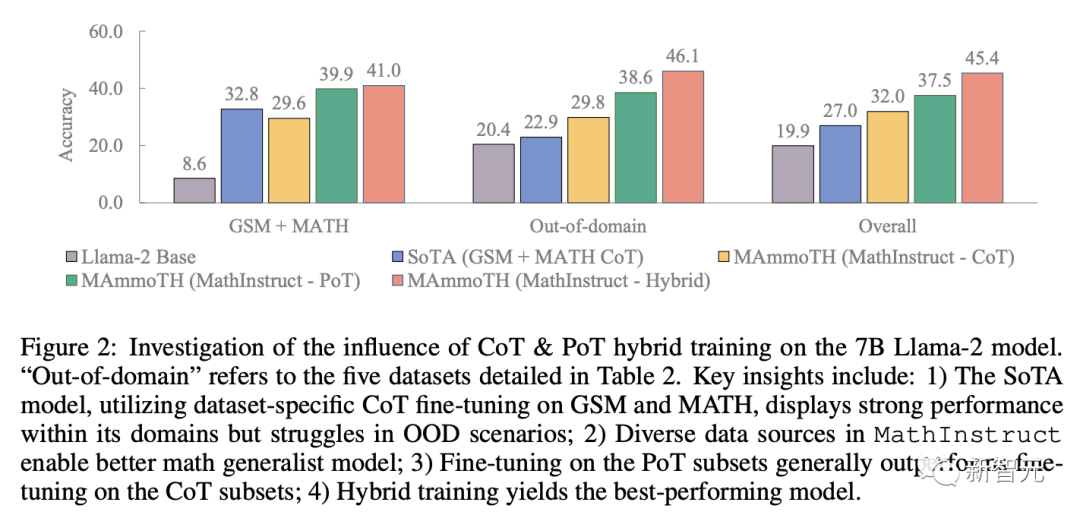
CoT解码不需要触发词,PoT需要触发短语「让我们写个程序来解决这个问题」(Let’s write a program to solve the problem)。
实验结果
总的来说,MAmmoTH和MAmmoTH-Coder在不同的模型尺寸上均优于SoTA模型,并且在领域外(OOD)数据集上的增益要显著优于领域内(IND)数据集,展现出了该模型作为数学通才模型的潜力,甚至在几个数据集上,MAmmoTH-Coder-34B和MAmmoTH-70B甚至超过了闭源模型。

在领域内数据的评估,MAmmoTH模型的主要竞争对手是WizardMath和Platypus,其中WizardMath的训练深度依赖于GSM8K和MATH数据集,Platypus在更广泛的文本和数学推理数据集上对LLM进行微调。
相比之下,MAmmoTH实现了全面的改进,并且更擅长解决复杂数学问题,相比WizardMath(MATH数据的sota)的增益最高超过了25%

在领域外数据评估中,主要竞争模型依然是Platypus,不过MAmmoTH可以实现比领域内数据更高的性能提升,展现出对未知数学问题的通用能力。
值得注意的是,MAmmoTH-7B还将WizardMath-7B在MMLU-Math上的CoT性能大幅提高了9%,其中包含大量没有在训练数据集中涵盖的主题。
不同基础模型之间的对比
可以发现,Code-Llama作为基础模型时的效果始终优于Llama-2,尤其是在领域外数据集上,二者之间的性能差异甚至达到了5%,其中MAmmoTH-Coder(34B)在领域外数据集上的平均性能实际上高于MAmmoTH(70B)
研究人员认为,MAmmoTH-Coder从Code-Llama的持续代码训练中受益匪浅,不仅增强了PoT能力,还提高了Llama的通用推理技能。































