本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
OpenAI开源的数学数据集,中国厂商新成绩一举冲到最前列!
就在9月16日,国产大模型在权威推理评测集GSM8K中,首次达到了80%正确率,大幅领先GPT-3.5(57.1%)和LLaMA2-70B(56.8%)。
而且这家厂商在大模型榜单上刷新全球纪录,已经不是第一次了。
它背后的公司在风起云涌的大模型技术江湖中,也频频被提及,越来越受关注。
不卖关子,它正是天工大模型,由昆仑万维打造。
怎么做到的?具体来看。
大模型推理能力Benchmark跻身前列
天工大模型这次一战成名的,是大模型数学推理能力评测基准,GSM8K。
GSM8K由OpenAI发布,是一个涵盖8500个小学水平高质量数学题的数据集,设计原则有四:
高质量、高多样性、中等难度和自然语言解决方案。
所以这家伙现在一般被用做测试各家大模型推理能力的Benchmark。
上个月,微软和中国科学院联合发布了一项关于WizardMath的研究结果,主要在GSM8K和另一个常见数学基准上测试了市面上主流开闭源大模型的性能。
闭源模型上,拿下最高分的是GPT-4,正确率92%;GPT-3.5的正确率为57.1%。
开源模型这边,不同参数规模的LLaMA-2最高正确率56.8%,最高分则被微软的WizardMath-70B拿走,正确率81.6%。

那么,天工大模型的成绩怎么样?
正确率80%。
这个成绩,比目前最强数学垂域开源模型的WizardMath-70B低了1.6%,与ChatGPT、540B参数的PaLM-2几乎持平。
并且大幅超过GPT-3.5和各个规模的LLaMA2。
同时在小米公开的中文数学测试集Cmath上,天工大模型平均准确率为76.8%(ChatGPT 74.8%)。
为了做个验证,按照惯例,天工大模型和GPT-3.5面临了来自GSM8K测试集的英文同题考验。
Round one
问:每天,Wendi给每只鸡喂三杯混合鸡饲料,其中包括种子、黄粉虫和蔬菜,以帮助它们保持健康。她分三餐给鸡喂食。上午,她给鸡群喂15杯饲料。下午,她再给鸡喂25杯饲料。
如果Wendi有20只鸡,那么一天的最后一餐,她需要给鸡喂多少杯饲料?
天工大模型答,一天的最后一餐中要喂20杯饲料,才能确保鸡崽子们一天都吃饱。

GPT-3.5答,Wendi需要在一天的最后一餐中给鸡崽子们喂21杯饲料。

OK,这一局,GPT-3.5输了。
Round two
问:道费尔姐妹带着从动物收容所领养的7只小猫开车回家时,妈妈打来电话,告诉她们家里的两只猫刚生了小猫。妈妈说,Patchy猫猫生了三倍于被领养数量的小猫,而另一只Trixie猫猫生了12只。
现在道费尔一家一共有多少只小猫?
天工大模型答,当然是有40只小猫啦~

GPT-3.5答,道费尔一家现在共有33只小猫。
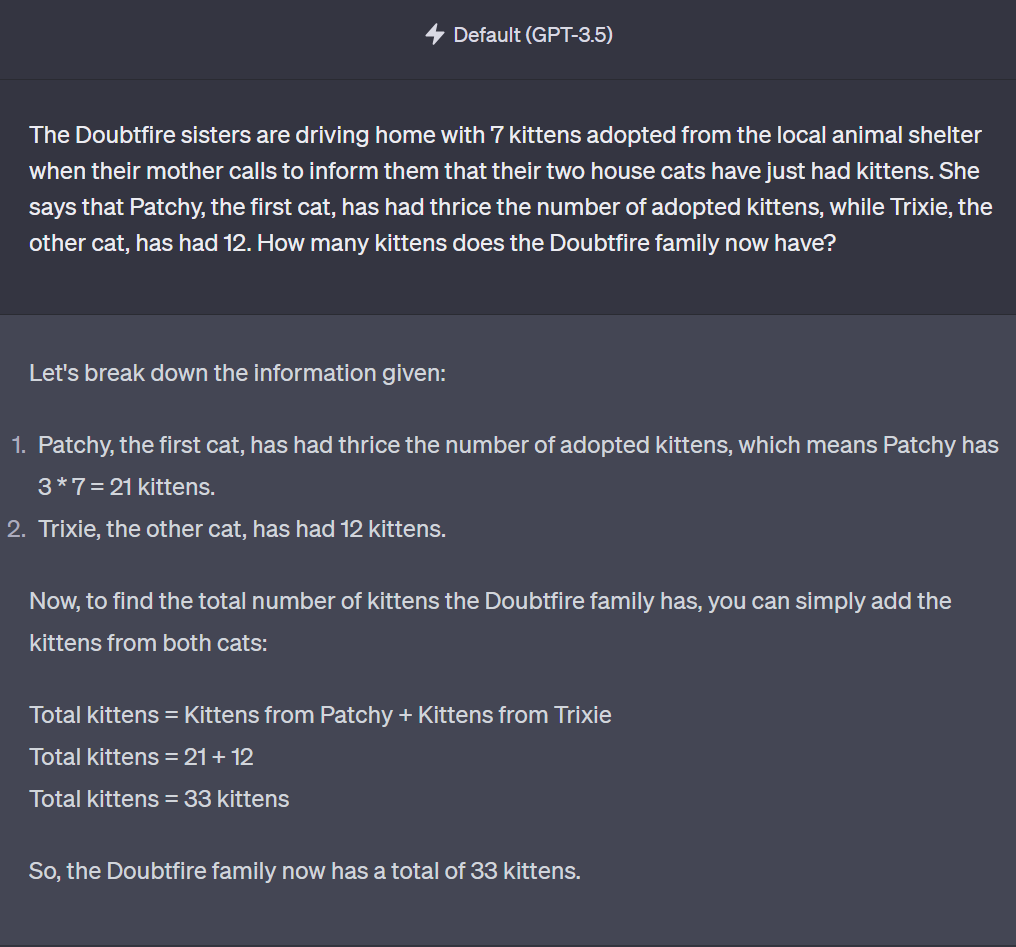
看来第二局还是天工大模型赢了。
Round 3
问:巨龙高坐在法尔博山上,向1000英尺范围内的任何东西疯狂喷火。波莉可以将压制巨龙的武器投掷400英里,但当她拿着蓝宝石时,能比不拿宝石时把标枪扔得远三倍。
如果拿着宝石,波莉能站在龙焰射程之外多远的地方,用金标枪击中龙?
天工大模型给出的解题思路如下,并且生成答案为200英尺。

GPT-3.5给出的解题思路也摆在这,最后答案也是200英尺。

这次二位打成了平局。
但是可以看到,相比GPT-3.5,天工大模型的解题思路更简单直接,解题步骤也更少更短。
一般来说,目前主流大模型们最近不太流行公开评测结果,但昆仑万维放话了:
虽然现在还是内测阶段,但天工大模型这次不仅对外公布了评测结果,还宣布后续会部署上线基座,供用户体验。
更重要的是,天工大模型允许研究人员、开发者申请API,对上述结果进行验证。
PS申请方法:
提供“姓名”“手机号”“所属机构/单位”,发送至官方邮箱neice@kunlun-inc.com进行申请。
若通过,三个工作日内将收到回复邮件,内含测试API及相关信息。
(截止时间为9月27日0点)
多个榜单跻身前列
除了GSM8K,另一个推理评测基准HumanEval,以及两个通识评测基准MMUL、C-Eval上,天工大模型也有出色表现。
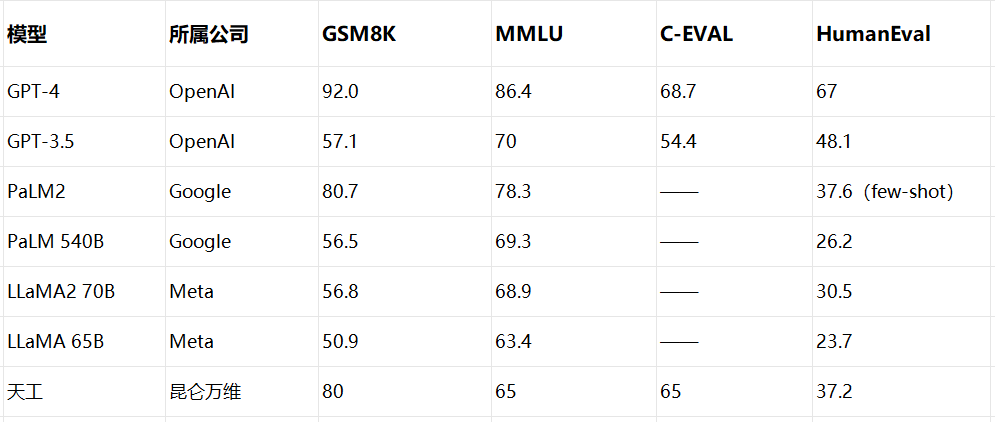
△根据公开测试数据搜集整理
HumanEval同样出自OpenAI,是OpenAI为了评估Codex模型的有效性而创建的数据集。
通过这个数据集,研究人员可以对Codex模型进行评估,并了解其在代码生成方面的准确性和效果。
在这个数据集上,天工大模型成绩是37.2%。
MMLU是UC伯克利等打造,集合了科学、工程、数学、人文、社会科学等领域的57个科目。
其主要目标,是对模型的英文跨学科专业能力进行深入测试。天工大模型的成绩是65%。
C-EVAL评测基准由上海交大、清华以及爱丁堡大学联合创建,是一个面向中文语言模型的综合考试评测集,覆盖了52个来自不同行业领域的学科。
天工大模型的得分为65,超过了GPT-3.5的54.4的成绩。
成绩亮眼的天工大模型,发布在今年4月。
其AI生成能力可满足文案创作、知识问答、代码编程、逻辑推演、数理推算等多元化需求。
4月发布,9月能取得酱紫的成绩,昆仑万维是怎么饲养天工大模型这匹黑马的?
先拿模型实力来说话。
这是一个双千亿大模型(指天工拥有千亿预训练基座模型和千亿RLHF模型。),目前版本最高支持1万字以上文本对话,实现20轮次以上用户交互。
二者的“强强联手”之下,天工大模型的优势便凸显了出来。
而模型层之外,为大模型积攒实力的无外乎算法、算力、数据三大件。
算法层方面,天工大模型也有自己的秘籍。
通常来说,市面上大模型们普遍采用Transformer架构。在此基础上,天工团队首次引入了蒙特卡洛搜索树算法(AlphaGo背后也是这算法)。

再说天工大模型背后的算力,基于中国最大的GPU集群之一。
强劲算力鼎力支持的,是天文数字版的数据量——按照借助“开源力量”的策略,天工从数十万亿的数据中,最终清洗、筛选出了近3万亿单词的数据。
现在,天工大模型在推理、通识多个榜单开花,可以想见因为背后算力、算法、数据扎实储备,天工大模型拥有的已经不是模型规模优势,技术创新和推理性能方面,也有了新突破。
国产大模型绕不过的狠角色
其实,推理能力大幅超过GPT-3.5和LLaMA2,已经不是昆仑万维携天工大模型第一次拿成绩炸场。
不久之前,天工大模型多模态团队的Skywork-MM用了大约50M的图文数据,以远小于其他大模型的数据量(>100M),登顶了多模态榜单。
 △MME感知榜第一,认知榜第二,总榜第一
△MME感知榜第一,认知榜第二,总榜第一
昆仑万维另一则引得众人瞩目的新闻,是AI大牛颜水成的加入。
他出任天工智能联席CEO、2050全球研究院院长,将在新加坡、伦敦、硅谷三地建立2050全球研究院的研究中心,并逐步开展几个领域的研究:
- 下一代Foundation Model的基础研究和研发;
- Agent的研发和智能体进化的研究;
- 生物智能等前沿技术领域的探索。

颜水成道出加盟昆仑万维的原因:
在通用人工智能领域,从研究、研发到产品是完整的链条,缺一不可,只有将三者完全打通,研究才能发挥最大价值。
在国内,能将研究、研发、产品三线合一的平台少之又少,昆仑万维布局了AI大模型、AI动漫、AI社交、AI游戏、AI搜索和AI音乐六大方向,同时昆仑万维的核心业务面向全球市场,其能力矩阵和生态系统非常具有想象空间。
大模型潮流,浩浩荡荡。
今年以来国产大模型的发展势头迅猛,吸引越来越多的人才加入其中,由此助力各家大模型不断地迭代升级,涌现出更强大的能力,适配更广泛的应用场景。
昆仑万维在大模型的变革中,战略重视,动作频频,而且也有业务场景。
可以不夸张地说一句,昆仑万维和它家的天工大模型,已经是大模型江湖中,一个绕不过去的狠角色了。